我们可以使用 Milvus 搭建多模态 RAG 应用,用于产品推荐系统。用户只需简单上传一张图片并输入文字描述,Google 的 MagicLens 多模态 Embedding 模型就会将图像和文本编码成一个多模态向量。然后,使用这个向量从 Milvus 向量数据库中找到最相似的亚马逊产品。
🎨🔍 Milvus 魔法:图像搜索和智能购物!
您是否曾经希望只需上传一张图片并简单描述你想要的东西就能找到对应的产品?我们现在可以帮您实现这个想法!🛍️✨
以下是我们搭建的应用示例的使用流程:
📸 拍摄一张照片并输入您想要搜索的内容
🧙♂️ Milvus 会将您的输入转换成一个特殊的"多模态向量"(很神奇吧?)
🕵️♀️ 这个输入向量将扮演超级侦探的角色,在 Milvus 向量数据库中进行相搜索
🎉 随后,系统就能够根据您的图片和描述在亚马逊上找到对应的产品
本文将展示如何使用 Milvus 搭建多模态 RAG 应用。
01.
多模态产品推荐系统使用的技术
Google DeepMind 的 MagicLens 是一个多模态 Embedding 模型,使用双编码器架构基于 CLIP(OpenAI 2021)或 CoCa(Google Research 2022)模型处理文本和图像。MagicLens 通过将训练得到的权重(weights)整合到同一个向量空间中,实现对多种检索任务的支持,包括以图搜图和以文本搜图。该模型基于 3670 万个三元训练,能够执行图像到图像、文本到图像和多模态文本-图像混合的检索任务,且相较于此前的模型显著减小了模型大小。
OpenAI GPT-4o 是一个生成式多模态大语言模型,集成了文本、图像和其他数据类型,突破了传统的语言模型。先进的 AI 技术能够更深层次地理解和处理复杂信息,提高了准确性和上下文感知能力。该模型支持自然语言处理(NLP)、计算机视觉等多种应用。
Milvus 是一款开源的分布式向量数据库,可用于存储、索引和搜索向量,十分适合生成式 AI 应用。凭借其混合搜索、元数据过滤、重排(Reranking)等功能,以及能够高效处理万亿级向量数据的能力,Milvus 是 AI 和 ML 应用的首选解决方案。您可以直接本地运行 Milvus 可以本地运行或部署集群版 Milvus,抑或是使用全托管的 Milvus 服务——Zilliz Cloud。
Streamlit 是一个开源的 Python 库,简化了创建和运行 Web 应用的过程。Streamlit 能够助力开发人员使用简单的 Python 脚本构建和部署仪表板(dashboard)、数据报告和简单的机器学习接口,免去深入学习 CSS 或 JavaScript 框架(如 Node.js)等 Web 技术的麻烦。
02.
准备数据
本文示例使用的数据来自 Amazon Reviews 2023 数据集。原始数据中包含 5400 万条用户评论,涵盖 4800 万件商品,分属于 33 个类别(如电器、美妆、服装、运动、户外以及“未知”等类别)。
我们将只使用上述数据集中的 5000 件商品数据,按类别均匀抽样。您可以通过运行 download_images.py 来下载图片。
$ python download_images.py每行产品数据包含商品元数据(如:类别名称、平均用户评分)以及产品缩略图和大图的 URL。
本文示例仅针对每个产品的大图生成向量。
03.
MagicLens 设置指南
MagicLens 是由 Google DeepMind 开发的图像检索模型。本指南介绍如何设置环境并下载 MagicLens 的模型权重。更多信息,请前往 MagicLens 的 GitHub 仓库。
环境设置:
1.使用 Conda 创建环境:
$ conda create --name magic_lens python=3.92.启动环境:
$ conda activate magic_lens3.克隆 Scenic 仓库:
$ git clone https://github.com/google-research/scenic.git4.打开 Scenic 目录:
$ cd scenic5.安装 Scenic:
$ pip install6.安装 CLIP 依赖:
$ pip install -r scenic/projects/baselines/clip/requirements.txt7.安装 Jax:
如果您使用 GPU,您还需要安装对应的 GPU 版本 Jax。更多信息,请阅读 Jax 文档。
以下为使用特定 CUDA 版本安装的示例(仅 Linux 系统):
使用 CUDA 12 安装:
$ pip install --upgrade "jax[cuda12_pip]" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html使用 CUDA 11 安装:
$ pip install --upgrade "jax[cuda11_pip]" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html本地下载模型权重
1.返回主文件夹:
$ cd .. This will take you back to the main directory where you cloned the demo.2.下载模型(可能需要填写验证信息):
$ gsutil cp -R gs://gresearch/magiclens/models ./04.
创建 Milvus Collection 并存储向量
本教程使用 Milvus Lite 以及 schema-less Milvus Client。
创建 Collection、将图片编码为向量,并运行 index.py 在 Milvus 中加载向量数据。
$ python index.py此步骤将每张图片编码为一个 768 维的向量。对于示例中的每个产品,图像向量及其相关的产品元数据将被保存到一个名为 “cir_demo_large” 的 Milvus Collection 中,并使用 AUTOINDEX (HNSW) 索引。
05.
在 Milvus 中创建索引并执行搜索
当您进行图片搜索时,Milvus 将使用 COSINE 向量距离搜索 top_k = 100 个最接近的图片向量。
Milvus 会自动将 top_k 结果按降序排列。这是因为两个向量的 COSINE 距离值越大,这两个向量越相似。
06.
运行 Streamlit Server 实现前端界面
更新本地文件 cfg.py,使用您实际的图片和模型权重路径作为路径名称。
在终端输入以下指令,运行应用;
$ streamlit run ui.py使用 Streamlit 应用:
在终端输入以下指令,运行应用
$ streamlit run ui.py3. 使用 Streamlit 应用:
上传用于产品搜索的图片。
输入文字描述。
点击 "搜索" 从 Milvus 向量数据库中查找相似产品。
点击 "Ask GPT" 获取 AI 产品推荐。
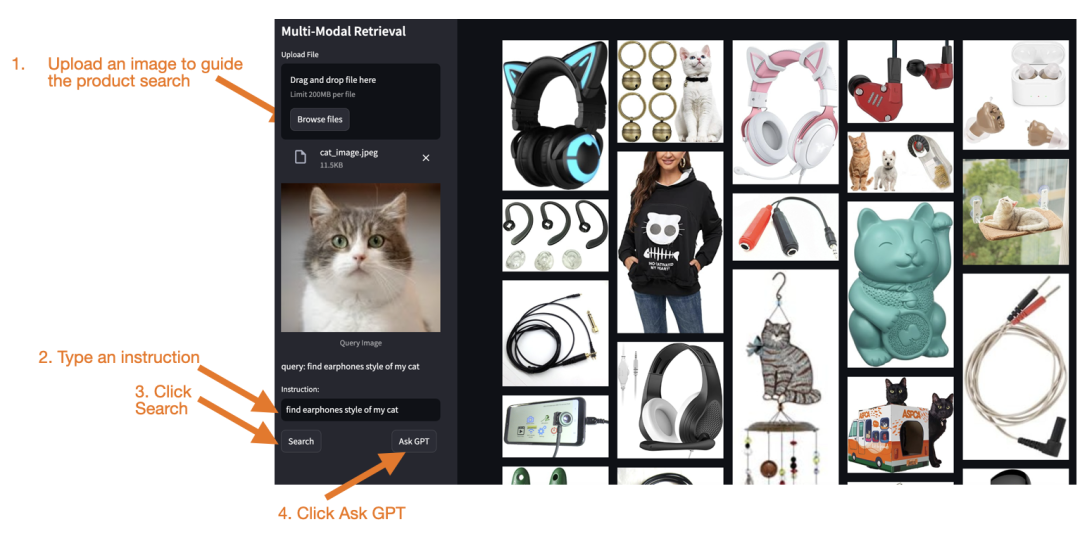
本文示例中的应用工作流程如下:
搜索功能:使用多模态 Embedding 模型 MagicLens 将您的查询图片和文本转换为向量。此时使用的模型与此前批量将产品图片转换为向量并存储在 Milvus 向量数据库中的模型相同。然后 Milvus 执行近似最近邻(ANN)搜索,查找与您输入向量最接近的 top_k 个产品图片向量。
Ask GPT 功能:调用 OpenAI 的 GPT-4o mini 多模态生成式模型,从搜索结果中取出前 25 张图片,将它们放入 Prompt 中,并传入模型。然后 GPT-4o mini 将选择最推荐的产品图片并提供推荐理由。

参考链接
(1)多模态图像检索 Bootcamp:
https://github.com/milvus-io/bootcamp/tree/master/bootcamp/tutorials/quickstart/apps/cir_with_milvus
(2)使用 Reranking 的多模态 RAG 推荐系统 Bootcamp:
https://github.com/milvus-io/bootcamp/tree/master/bootcamp/tutorials/quickstart/apps/multimodal_rag_with_milvus
(3)Google MagicLens 模型:
https://github.com/google-deepmind/magiclens
(4)介绍本示例原理的视频:
https://youtu.be/uaqlXRCvjG4?si=e83DnUsLZvVnWt-0&t=51
Source: https://zilliz.com/blog/build-multimodal-product-recommender-demo-using-milvus-and-streamlit
推荐阅读