在ultralytics框架中,提供了两种用于目标追踪的算法,分别是ByteTrack算法与Botsort算法,这两种算法都是在Sort算法的基础上改进的,今天,我们学习一下ByteTrack算法。
存在问题
首先,我们看下ByteTrack所解决的问题:
-
遮挡目标:
低置信度的检测框有时确实可以指示目标的存在,尤其是在目标被部分遮挡或者遮挡物很大时。丢弃这些低置信度的检测框可能会导致漏检目标,因为算法无法正确地识别被遮挡的目标。 -
轨迹断裂:
移除低置信度的检测框可能导致轨迹的不连续性,因为目标在一帧中被识别出来,在另一帧中却被移除了。这可能会导致跟踪算法无法正确地维持目标的标识符,从而产生碎片化的轨迹,使跟踪结果不连贯。
解决方案
因此,ByteTrack采用高低检测框进行分级匹配,从而有效的解决上述问题,此外,ByteTrack算法是一种基于目标检测的追踪算法,和其他非ReID的算法一样,仅仅使用目标追踪所得到的bbox进行追踪,因此,其与Sort算法流程一致,使用卡尔曼滤波预测边界框,然后使用匈牙利算法进行目标和轨迹间的匹配。故而,其具有以下特点:
- 没有使用
ReID特征计算外观相似度(DeepSort算法使用外观特征,因此其速度慢一些) - 非深度方法,不需要训练(同上,
DeepSort算法需要训练一个特征提取网络) - 利用高分框和低分框之间的区别和匹配,有效解决遮挡问题(这是
ByteTrack的一个创新点)
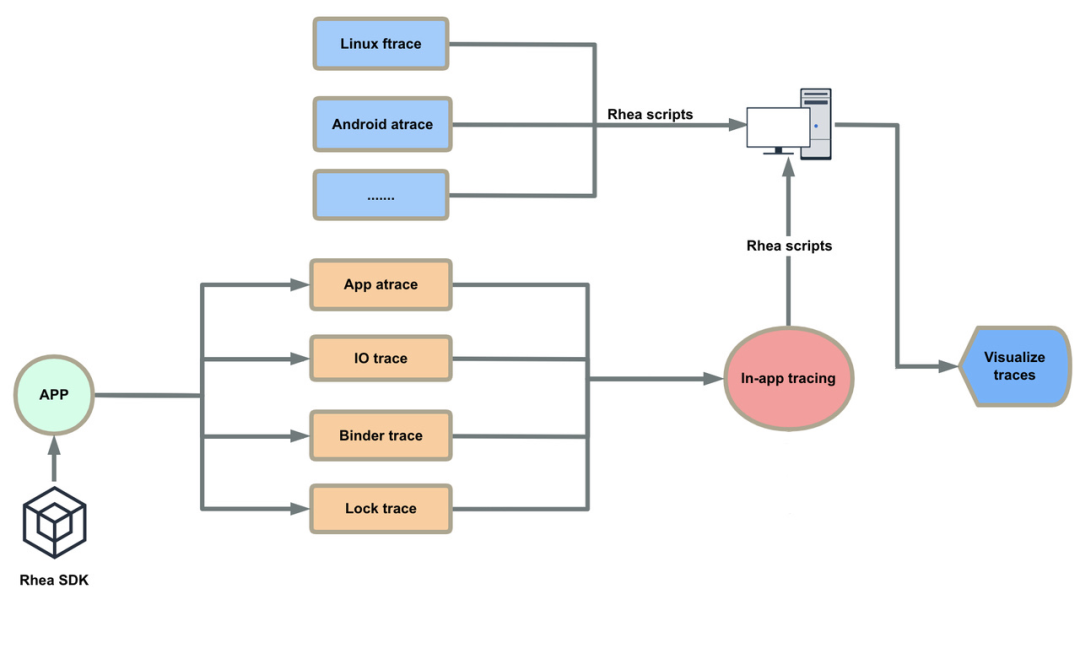
那么,其相较于Sort算法又有哪些改变呢(下图红色框部分)?
ByteTrack算法的最大创新点就是对低分框的使用,作者认为低分框可能是对物体遮挡时产生的框,直接将低分框抛弃会影响性能,所以作者使用低分框对追踪算法进行了二次匹配,有效优化了追踪过程中因为遮挡造成换id的问题:
结构流程
ByteTrack的流程图结构如下:

算法流程
ByteTrack算法框架流程如下:

DeBug流程
那么,在ultralytics框架中是如何实现的呢?我们通过DeBug的形式来看一下:
ultralytics\cfg\trackers\bytetrack.yaml
关于bytetrack的相关配置参数如下:
tracker_type: bytetrack # tracker type, ['botsort', 'bytetrack']
track_high_thresh: 0.5 # threshold for the first association
track_low_thresh: 0.1 # threshold for the second association
new_track_thresh: 0.6 # threshold for init new track if the detection does not match any tracks
track_buffer: 30 # buffer to calculate the time when to remove tracks
match_thresh: 0.8 # threshold for matching tracks
ultralytics\ultralytics\trackers\track.py的on_predict_start方法
随后,根据上述参数完成Tracker的初始化:
tracker = check_yaml(predictor.args.tracker)#读取配置文件
cfg = IterableSimpleNamespace(**yaml_load(tracker))
for _ in range(predictor.dataset.bs):
tracker = TRACKER_MAP[cfg.tracker_type](args=cfg, frame_rate=30)
trackers.append(tracker)
if predictor.dataset.mode != "stream": # only need one tracker for other modes.
break

ultralytics\engine\predictor.py的stream_inference方法
上述的过程是完成了track的初始化,将video转换为dataset,进行检测:
for self.batch in self.dataset:#将video切分,变为dataset的形式,bs=1,即一张张进行
self.run_callbacks("on_predict_batch_start")#batch内容如下:
paths, im0s, s = self.batch #video地址,每帧图像,video保存地址
# Preprocess
with profilers[0]:
im = self.preprocess(im0s)#图像前处理
# Inference
with profilers[1]:
preds = self.inference(im, *args, **kwargs)#将图像进行推理
if self.args.embed:
yield from [preds] if isinstance(preds, torch.Tensor) else preds # yield embedding tensors
continue
# Postprocess
with profilers[2]:
self.results = self.postprocess(preds, im, im0s)#结果后处理
self.run_callbacks("on_predict_postprocess_end")#执行相应的方法
# Visualize, save, write results
n = len(im0s)
for i in range(n):
self.seen += 1
self.results[i].speed = {#这里是计算相应的速度
"preprocess": profilers[0].dt * 1e3 / n,#前处理速度
"inference": profilers[1].dt * 1e3 / n,#推理速度
"postprocess": profilers[2].dt * 1e3 / n,#后处理速度
}
if self.args.verbose or self.args.save or self.args.save_txt or self.args.show:
s[i] += self.write_results(i, Path(paths[i]), im, s)#输出视频保存,不断累计输入
# Print batch results
if self.args.verbose:
LOGGER.info("\n".join(s))
self.run_callbacks("on_predict_batch_end")
yield from self.results
从转换为dataset的video中读取的batch


第一帧处理结果
图像的预测结果如下:

后处理的结果保存到self.results中

self.run_callbacks("on_predict_postprocess_end")中包含的方法如下:

第二帧处理结果
在第二帧中,检测出的结果共有16个
ultralytics\ultralytics\trackers\track.py的on_predict_postprocess_end方法
顾名思义,该方法是预测的后处理过程,其执行跟踪器的更新操作
on_predict_postprocess_end方法定义如下:
New = 0
Tracked = 1
Lost = 2
Removed = 3
def on_predict_postprocess_end(predictor: object, persist: bool = False) -> None:
path, im0s = predictor.batch[:2]#获取batch中的信息
is_obb = predictor.args.task == "obb"
is_stream = predictor.dataset.mode == "stream"
for i in range(len(im0s)):#第一帧在只有一张图像
tracker = predictor.trackers[i if is_stream else 0]
vid_path = predictor.save_dir / Path(path[i]).name
if not persist and predictor.vid_path[i if is_stream else 0] != vid_path:
tracker.reset()
predictor.vid_path[i if is_stream else 0] = vid_path
det = (predictor.results[i].obb if is_obb else predictor.results[i].boxes).cpu().numpy()#从predictor的结果中获取检测结果
if len(det) == 0:
continue
tracks = tracker.update(det, im0s[i])#更新轨迹,tracks的维度为(10,8),即10个目标,8为信息
if len(tracks) == 0:
continue
idx = tracks[:, -1].astype(int)
predictor.results[i] = predictor.results[i][idx]#更新predictor中的值,
update_args = {"obb" if is_obb else "boxes": torch.as_tensor(tracks[:, :-1])}
predictor.results[i].update(**update_args)#更新值,这个值便是存储用于展示的轨迹信息
第一帧图像轨迹结果
检测结果共有17个,其中10个为高置信度,7个位低置信度
随后,经过ByteTrack方法后,得到的tracks的值如下,其中前4位是box位置,后面依次为track_id、置信度、类别以及索引

更新完predictor的值后为10个

第二帧图像轨迹结果
检测结果有16个,其中高置信度为11个目标

第三帧图像轨迹结果
检测结果共有20个,最终的轨迹如下:

ultralytics\trackers\byte_tracker.py的update方法
ByteTrack的具体更新方法如下:
def update(self, results, img=None):
"""Updates object tracker with new detections and returns tracked object bounding boxes."""
self.frame_id += 1
activated_stracks = []
refind_stracks = []
lost_stracks = []
removed_stracks = []
scores = results.conf
bboxes = results.xywhr if hasattr(results, "xywhr") else results.xywh
# Add index
bboxes = np.concatenate([bboxes, np.arange(len(bboxes)).reshape(-1, 1)], axis=-1)
cls = results.cls
#根据置信度划分高低
remain_inds = scores >= self.args.track_high_thresh#保留的boxid,即高置信度
inds_low = scores > self.args.track_low_thresh
inds_high = scores < self.args.track_high_thresh
#按照high和low来划分box
inds_second = inds_low & inds_high#低置信度id,其值位True&False列表
#对应的box,score以及cls
dets_second = bboxes[inds_second]
dets = bboxes[remain_inds]
scores_keep = scores[remain_inds]
scores_second = scores[inds_second]
cls_keep = cls[remain_inds]
cls_second = cls[inds_second]
#初始化track
detections = self.init_track(dets, scores_keep, cls_keep, img)
# Add newly detected tracklets to tracked_stracks 添加新的检测目标放到轨迹中
unconfirmed = []
tracked_stracks = [] # type: list[STrack] 第一帧不执行
for track in self.tracked_stracks:#事实上是上一帧的目标
if not track.is_activated:
unconfirmed.append(track)
else:
tracked_stracks.append(track)
# Step 2: First association, with high score detection boxes 利用high进行首次匹配
strack_pool = self.joint_stracks(tracked_stracks, self.lost_stracks) #strack_pool的值来源于tracked_stracks,即上一帧
# Predict the current location with KF 利用KF进行预测,其与Sort方法是一致的
self.multi_predict(strack_pool) #更新strack_pool中的mean和covariance
if hasattr(self, "gmc") and img is not None:#不执行
warp = self.gmc.apply(img, dets)
STrack.multi_gmc(strack_pool, warp)
STrack.multi_gmc(unconfirmed, warp)
dists = self.get_dists(strack_pool, detections)#创建代价矩阵 特征维度(10,11)
matches, u_track, u_detection = matching.linear_assignment(dists, thresh=self.args.match_thresh)#计算目标与轨迹的匹配,这里的轨迹与Sort中一样,也是使用的预测完的轨迹
for itracked, idet in matches:#根据匹配结果进行修正更新track
track = strack_pool[itracked]
det = detections[idet]
if track.state == TrackState.Tracked:
track.update(det, self.frame_id)#修改track
activated_stracks.append(track)#激活的track
else:
track.re_activate(det, self.frame_id, new_id=False)
refind_stracks.append(track)#重新找到的目标
# Step 3: Second association, with low score detection boxes association the untrack to the low score detections
detections_second = self.init_track(dets_second, scores_second, cls_second, img)#第二次匹配的检测结果初始化
r_tracked_stracks = [strack_pool[i] for i in u_track if strack_pool[i].state == TrackState.Tracked]#未匹配上的轨迹重新匹配,此处没有未匹配上的,故为 【】
# TODO
dists = matching.iou_distance(r_tracked_stracks, detections_second)#构造代价矩阵,未匹配轨迹与低置信度目标故维度 为[0,5]
matches, u_track, u_detection_second = matching.linear_assignment(dists, thresh=0.5)
for itracked, idet in matches:#更新第二次匹配成果的结果
track = r_tracked_stracks[itracked]
det = detections_second[idet]
if track.state == TrackState.Tracked:
track.update(det, self.frame_id)#修改轨迹
activated_stracks.append(track)
else:
track.re_activate(det, self.frame_id, new_id=False)
refind_stracks.append(track)
for it in u_track:#没有匹配的轨迹(目标消失了)
track = r_tracked_stracks[it]
if track.state != TrackState.Lost:
track.mark_lost()
lost_stracks.append(track)
# Deal with unconfirmed tracks, usually tracks with only one beginning frame
detections = [detections[i] for i in u_detection]#没有匹配的目标
dists = self.get_dists(unconfirmed, detections)#创建代价矩阵 ,没有确定态的轨迹和未匹配的目标
matches, u_unconfirmed, u_detection = matching.linear_assignment(dists, thresh=0.7)#匹配结果,未匹配态轨迹以及未匹配检测框
for itracked, idet in matches:#匹配成果更正修改轨迹
unconfirmed[itracked].update(detections[idet], self.frame_id)
activated_stracks.append(unconfirmed[itracked])
for it in u_unconfirmed:#未确认态
track = unconfirmed[it]
track.mark_removed()
removed_stracks.append(track)
# Step 4: Init new stracks
for inew in u_detection:#未匹配的检测框
track = detections[inew]
if track.score < self.args.new_track_thresh:
continue
track.activate(self.kalman_filter, self.frame_id)
activated_stracks.append(track)
# Step 5: Update state
for track in self.lost_stracks:
if self.frame_id - track.end_frame > self.max_time_lost:
track.mark_removed()
removed_stracks.append(track)
self.tracked_stracks = [t for t in self.tracked_stracks if t.state == TrackState.Tracked]#用于显示的 track
self.tracked_stracks = self.joint_stracks(self.tracked_stracks, activated_stracks)
self.tracked_stracks = self.joint_stracks(self.tracked_stracks, refind_stracks)
self.lost_stracks = self.sub_stracks(self.lost_stracks, self.tracked_stracks)
self.lost_stracks.extend(lost_stracks)
self.lost_stracks = self.sub_stracks(self.lost_stracks, self.removed_stracks)
self.tracked_stracks, self.lost_stracks = self.remove_duplicate_stracks(self.tracked_stracks, self.lost_stracks)
self.removed_stracks.extend(removed_stracks)
if len(self.removed_stracks) > 1000:
self.removed_stracks = self.removed_stracks[-999:] # clip remove stracks to 1000 maximum
return np.asarray([x.result for x in self.tracked_stracks if x.is_activated], dtype=np.float32)
第一帧轨迹更新结果
第一帧预测的目标的box:

高置信度与低置信度目标

按照high和low来划分box,第二次匹配的box

这里我们看到detection的值如下,这个OT_0之类的 代表什么意思呢,我们通过init_track方法可知其到底是如何做的:
detections = self.init_track(dets, scores_keep, cls_keep, img)
def init_track(self, dets, scores, cls, img=None):
"""Initialize object tracking with detections and scores using STrack algorithm."""
return [STrack(xyxy, s, c) for (xyxy, s, c) in zip(dets, scores, cls)] if len(dets) else []
class STrack(BaseTrack):
"""
Attributes:
shared_kalman (KalmanFilterXYAH): Shared Kalman filter that is used across all STrack instances for prediction.
_tlwh (np.ndarray): Private attribute to store top-left corner coordinates and width and height of bounding box.
kalman_filter (KalmanFilterXYAH): Instance of Kalman filter used for this particular object track.
mean (np.ndarray): Mean state estimate vector.
covariance (np.ndarray): Covariance of state estimate.
is_activated (bool): Boolean flag indicating if the track has been activated.
score (float): Confidence score of the track.
tracklet_len (int): Length of the tracklet.
cls (any): Class label for the object.
idx (int): Index or identifier for the object.
frame_id (int): Current frame ID.
start_frame (int): Frame where the object was first detected.
"""
shared_kalman = KalmanFilterXYAH()
def __init__(self, xywh, score, cls):
"""Initialize new STrack instance."""
super().__init__()
# xywh+idx or xywha+idx
assert len(xywh) in {5, 6}, f"expected 5 or 6 values but got {len(xywh)}"
self._tlwh = np.asarray(xywh2ltwh(xywh[:4]), dtype=np.float32)
self.kalman_filter = None
self.mean, self.covariance = None, None
self.is_activated = False
self.score = score
self.tracklet_len = 0
self.cls = cls
self.idx = xywh[-1]
self.angle = xywh[4] if len(xywh) == 6 else None


由于是第一帧,因此大多数都是空。
第二帧轨迹跟踪结果
高置信度匹配结果
检测结果共有16个,其中高置信度的有11个,在上一帧中,目标有17个,高置信度的有10个
根据匹配结果,得到第一帧轨迹与第二帧目标的匹配结果如下:

没有匹配上的检测目标是9号

经过更新后的track中的值,可以看到mean后面的四位不再是0了,这与Sort算法是一样的

跟踪上的track

算法流程
算法的主要思路就是创建追踪的轨迹,然后利用追踪的轨迹对每一帧的目标进行匹配,逐帧来匹配目标,从而形成完整的轨迹。
首先,我们需要先理清关键的两个单元,第一个是追踪的轨迹,是代码从第一帧开始创建,包含了持续追踪和中断追踪的一切轨迹;第二个是当前帧的边界框,当前帧的边界框是仅从当前帧中获取到的边界框,不包含任何以往帧的信息。
激活状态:激活追踪了两帧以上的目标框(包括第一帧时目标框新建的轨迹)
未激活状态:在视频中间出现的新轨迹,并且暂未匹配到轨迹的第二点
新轨迹:新生成的轨迹
已追踪轨迹:在前一帧成功追踪的轨迹
失追轨迹:在前n帧失去追踪的轨迹(n<=30)
已删除轨迹:在前n帧失去追踪的轨迹(n>30)
当开始扫描第一帧时,此时还没有任何的轨迹出现:算法会将所有的目标框都创建轨迹对象,并储存起来。
注意:此时所有创建的轨迹都会被标注为已追踪轨迹。
从第二帧开始,算法就会逐步构建轨迹,步骤如下:
一、 对追踪轨迹和边界框进行分类
对所有的追踪轨迹分为激活和未激活两类(激活追踪了两帧以上的目标框(包括第一帧时目标框新建的轨迹))
对所有的当前帧边界框分为高分和低分两类(按照边界框的得分阈值进行分类(官方是0.5))
二、对轨迹进行第一次追踪(仅针对激活状态的轨迹的高分匹配)
1.将所有的已追踪轨迹和失追轨迹合并,称为初步追踪轨迹
2.预测初步追踪轨迹的下一帧边界框可能的位置和大小(使用卡尔曼滤波预测边界框,在上一篇文章中已介绍,这里就不再赘述了)
3.计算初步追踪轨迹预测的下一帧边界框与当前帧高分边界框之间的IoU(交并比)值,获取一个两两之间IoU的关系损失矩阵(IoU越小表示关联程度越大,IoU最大值为1,代表边界框间没有交集)
4.根据IoU损失矩阵,使用匈牙利算法对初步追踪轨迹和当前帧高分边界框进行匹配,获得三个结果:已匹配的轨迹与边界框,未成功匹配的轨迹,未成功匹配的当前帧边界框。(匈牙利算法可以根据损失矩阵对两两之间进行一对一的匹配,返回匹配成功和不成功的结果)
使用已成功匹配的当前帧边界框更新初步追踪轨迹(把初步追踪轨迹中的框改为当前帧边界框,id还是原来的id)
三、对轨迹进行第二次追踪(仅针对激活状态的轨迹的低分匹配)
找出第一次匹配中没匹配到的轨迹,筛选出其中的已追踪轨迹(因为低分匹配不匹配那些已经失追的轨迹,可能作者认为这样比较合理)
因为这些轨迹之前也已经预测过下一帧的边界框了,所以这里不用预测
计算上述轨迹和当前帧的低分边界框之间的IoU
使用匈牙利算法对上述追踪轨迹和当前帧低分边界框进行匹配
使用已成功匹配的当前帧边界框更新上述追踪轨迹
将此时还未成功追踪的轨迹标记为失追轨迹(扔给下一帧去追踪了)
四、对未激活状态的轨迹进行追踪
个人理解:我觉得这一步存在的意义可能是作者认为在视频中间突然出现的目标可信度可能不太高(可能出现重复轨迹什么的),所以对中间才新出现的轨迹比较谨慎处理
1.找出第一步中未成功匹配的当前帧边界框(没有成功匹配的高分边界框),并且找出未激活的轨迹
2.计算上述轨迹和当前帧的边界框之间的IoU
3.使用匈牙利算法对上述追踪轨迹和边界框进行匹配
4.使用已成功匹配的当前帧边界框更新上述追踪轨迹
5.此时将未成功追踪的未激活轨迹直接标记为已删除轨迹
五、新建轨迹
如果到现在还没有成功匹配的高分边界框,就能认为是新出现的东西了,会给它分配一个新的轨迹以及新的id(低分框就之间当成误判扔掉了,不会生成新轨迹)。
注意:此时不是第一帧了,新增的轨迹都是未激活状态,如果下一帧不能成功匹配的话就会被无情删除了
六、返回结果
此时就可以放回所有已追踪的轨迹了(当然不包含失追轨迹和删除轨迹),所有轨迹都有一个唯一的id,这个结果就可以拿去作为每一帧追踪的结果了!







![爬楼梯[简单]](https://i-blog.csdnimg.cn/direct/5ab3dce210dd47669c14e174b7e8d4a6.png)