混合精度训练
- 混合精度训练
- 1. 浮点表示法:[IEEE](https://zh.wikipedia.org/wiki/电气电子工程师协会)二进制浮点数算术标准(IEEE 754)
- 1.1 浮点数剖析
- 1.2 举例说明
- 例子 1:
- 例子 2:
- 1.3 浮点数比较
- 1.4 浮点数的舍入
- 2. 混合精度训练
- 2.1 为什么需要半精度
- 2.2 FP16带来的问题:[量化误差](https://zhida.zhihu.com/search?q=量化误差&zhida_source=entity&is_preview=1)
- 2.3 FP32 权重备份
- 2.4 Loss Scale
- 2.5 提高算数精度
在日常深度学习训练中,一般使用单精度浮点数(float:FP32) 来表示参数并进行相关训练任务。那么浮点数在内存中是如何存储的呢?
在正式开始介绍混合精度训练之前,让我们先对半精度(FP16)、单精度(FP32)、双精度(FP64) 相关基础知识进行介绍。
1. 浮点表示法:IEEE二进制浮点数算术标准(IEEE 754)
IEEE二进制浮点数算术标准(IEEE 754)是20世纪80年代以来最广泛使用的浮点数运算标准,为许多CPU与浮点运算器所采用。这个标准定义了表示浮点数的格式(包括负零-0)与反常值(denormal number),一些特殊数值((无穷(Inf)与非数值(NaN)),以及这些数值的“浮点数运算符”;它也指明了四种数值舍入规则和五种例外状况(包括例外发生的时机与处理方式)。
1.1 浮点数剖析
一个浮点数 (Value) 的表示其实可以这样表示:
Value=sign
×
exponent
×
fraction
1.
M
.
.
.
×
2
E
,
E
=
exponent
;
M
=
fraction
\text{Value=sign} \times \text{exponent} \times \text{fraction} \\ 1.M... \times2^E,E=\text{exponent};M=\text{fraction}
Value=sign×exponent×fraction1.M...×2E,E=exponent;M=fraction
也就是浮点数的实际值,等于符号位(sign bit)乘以指数偏移值(exponent bias)再乘以分数值(fraction)。
二进制浮点数是以符号数值表示法的格式存储——最高有效位被指定为符号位(sign bit);“指数部分”,即次高有效的e个比特,存储指数部分;最后剩下的f个低有效位的比特,存储“有效数”(significand)的小数部分。

指数部分,也称为指数偏移值(exponent bias),即浮点数表示法中指数域的编码值,等于指数的实际值加上某个固定的值,IEEE 754标准规定该固定值为 2 e − 1 − 1 2^{e−1}−1 2e−1−1其中的 e e e 为存储指数的比特的长度。
以单精度浮点数为例,它的指数域是8个比特,固定偏移值是 2 8 − 1 − 1 = 128 − 1 = 127 2^{8−1}−1=128−1=127 28−1−1=128−1=127,单精度浮点数的指数部分 E E E,实际取值是从-126到127(-127和128被用作特殊值处理)
采用指数的实际值加上固定的偏移值的办法表示浮点数的指数,好处是可以用长度为 e e e 个比特的无符号整数来表示所有的指数取值,这使得两个浮点数的指数大小的比较更为容易,实际上可以按照字典次序比较两个浮点表示的大小。
这种移码表示的指数部分,中文称作阶码。
特殊值:
这里有三个特殊值需要指出:
- 如果指数是0并且尾数的小数部分是0,这个数±0(和符号位相关): s i g n × 0.0 × 2 − 127 sign \times0.0\times2^-{127} sign×0.0×2−127
- 如果指数 = 2 e − 1 = 2^{e−1} =2e−1 并且尾数的小数部分是0,这个数是±∞(同样和符号位相关): s i g n × 0.0 × 2 128 sign\times0.0\times2^{128} sign×0.0×2128
- 如果指数 = 2e−1并且尾数的小数部分非0,这个数表示为非数(NaN): s i g n × 0. x x . . . × 2 128 sign\times0.xx...\times2^{128} sign×0.xx...×2128
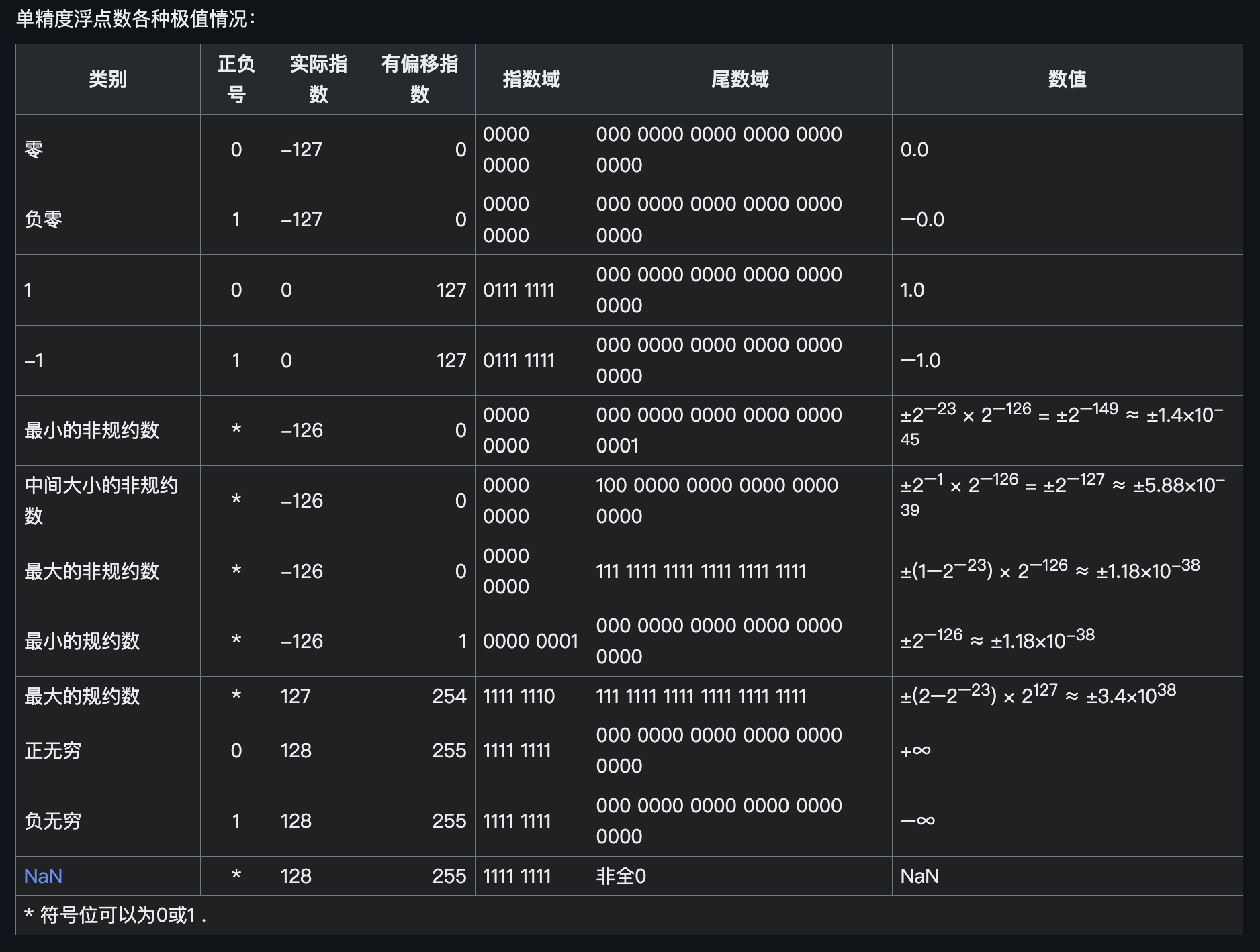
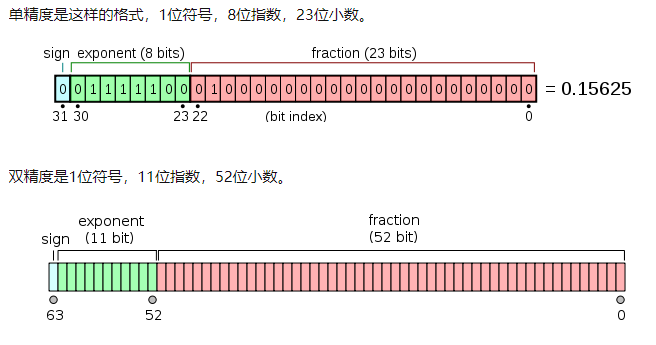
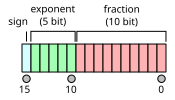
- 浮点数如何在计算机中储存,即**符号位,指数位,小数位(通常翻译为尾数)**取值范围取决于指数位,计算精度取决于小数位(尾数)。
- 小数位越多(比如双精度是52位),则能表示的数越大,那么计算精度则越高。单精度的小数位在计算机中只有23位(二进制),换算到十进制只能百分百保证6位十进制数字的精确度。不能百分百保证7位的精度运算。超过该精度(二进制23位,十进制6位)的小数运算将会被截取,造成精度损失和计算结果的不准确。同理,双精度,小数位是52位(二进制),换算为十进制则只能百分百能保证15位。
-
float16的精度是3-4位有效数字,取值范围为 [ − 65504 , 65504 ] [-65504,65504] [−65504,65504],占用2字节(8位)
-
float32的精度是6位有效数字,取值范围是 1 0 − 38 10^{-38} 10−38到 1 0 38 10^{38} 1038次方,float占用4字节空间(32位)
-
double的精度是15位有效数字,取值范围是 1 0 − 308 10^{-308} 10−308到 1 0 308 10^{308} 10308次方,double占用8字节空间(64位)。
1.2 举例说明
那一个小数到底要怎么换算成二进制呢?我们得拿实际例子来解释。
例子 1:
比如:把十进制小数0.875转换成二进制,具体怎么操作?
可以分几大步走:
1、以小数点为界,拆分
2、整数部分转换
整数转二进制我想大家应该都熟悉,使用:除2取余法 即可。而这里的0.875整数部分为0,无需操作。
3、小数部分转换
小数部分的转换不同于整数部分,采用的是 “乘2取整法” ,图示一下就明白了:
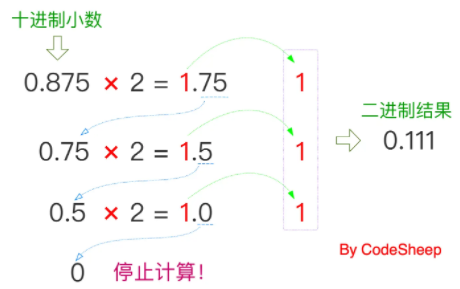
4、合并结果
整数部分 + 小数部分,最终得到二进制结果为0.111。
所以该结果按照上一节所述的尾数 + 阶码的计算机计数方式和上述公式对齐,小数点右移一位,则可以表示为:
1.11
×
2
−
1
1.11\times 2^{-1}
1.11×2−1
所以对应可得:
- 符号位:
0正数 - 阶码(E)部分:若以
float为例,固定偏移值为127,应为127 +(-1)= 126或者直接二进制相加,因此二进制表示为:01111110 - 尾数部分(M):若以
float为例,应为23位,因此尾部补齐后为11000000000000000000000。
因此最终的总结果为(以32位精度float表示):
00111111011000000000000000000000
例子 2:
再比如:把十进制小数6.36转换成二进制,具体怎么操作?
但凡能用图示,我就不想写文字,所以用一张图就可以解释得明明白白:

整数部分 + 小数部分,因此最终得到的结果二进制结果为110.01011100...。
还是按照上一节所述的尾数 + 阶码的计算机计数方式,小数点左移两位,则可以表示为:
1.1001011100...
×
2
2
1.1001011100...\times2^{2}
1.1001011100...×22
所以对应可得:
- 符号位:
0 - 阶码(E)部分:若以
float为例,应为127 +(2)= 129,因此二进制表示为:10000001 - 尾数部分(M):
1001011100...,其实它本身无限不循环,但若以float型精度来截取23位,则可以表示为10010111000010100011111
因此最终的总结果为(以32位精度float表示):
01000000110010111000010100011111
所以像这种无限位数的尾数情况,用计算机存储产生截取是必然的,必定会有一定的精度损失!所以这也从根本上解释了为什么float或者double这种类型数据使用时的风险性,因此必须要结合实际业务理性考量。
1.3 浮点数比较
浮点数基本上可以按照符号位、指数域、尾数域的顺序作字典比较。显然,所有正数大于负数;正负号相同时,指数的二进制表示法更大的其浮点数值更大。
1.4 浮点数的舍入
任何有效数上的运算结果,通常都存放在较长的寄存器中,当结果被放回浮点格式时,必须将多出来的比特丢弃。 有多种方法可以用来执行舍入作业,实际上IEEE标准列出4种不同的方法:
- 舍入到最接近:舍入到最接近,在一样接近的情况下偶数优先(Ties To Even,这是默认的舍入方式):会将结果舍入为最接近且可以表示的值,但是当存在两个数一样接近的时候,则取其中的偶数(在二进制中是以0结尾的)。
- 朝+∞方向舍入:会将结果朝正无限大的方向舍入。
- 朝-∞方向舍入:会将结果朝负无限大的方向舍入。
- 朝0方向舍入:会将结果朝0的方向舍入。
2. 混合精度训练
该篇内容摘自:https://zhuanlan.zhihu.com/p/103685761
在这里的混合精度训练,指代的是单精度 float和半精度 float16 混合。比较经典的就是这篇ICLR2018,百度和Nvidia联合推出的论文 MIXED PRECISION TRAINING。 因此,这里也以这篇论文作为引子,对混合精度进行讲解。
2.1 为什么需要半精度
float16和float的优势,总结下来就是两个方面:内存占用更少,计算更快。
-
内存占用更少: 这个是显然可见的,通用的模型 fp16 占用的内存只需原来的一半。memory-bandwidth 减半所带来的好处:
-
- 模型占用的内存更小,训练的时候可以用更大的batchsize。
- 模型训练时,通信量(特别是多卡,或者多机多卡)大幅减少,大幅减少等待时间,加快数据的流通。
-
计算更快:
-
- 目前的不少GPU都有针对 fp16 的计算进行优化。论文指出:在近期的GPU中,半精度的计算吞吐量可以是单精度的 2-8 倍;
2.2 FP16带来的问题:量化误差
那么使用FP16的时候有没有什么问题呢?当然有。FP16带来的问题主要有两个:
- 溢出错误;
- 舍入误差。
- 溢出错误(Grad Overflow / Underflow) 由于FP16的动态范围( 6×10−8∼65504 )比FP32的动态范围( 1.4×10−45∼1.7×1038 )要狭窄很多,因此在计算过程中很容易出现上溢出(Overflow, g>65504 )和下溢出(Underflow, g<6×10−8 )的错误,溢出之后就会出现“Nan”的问题。在深度学习中,由于激活函数的的梯度往往要比权重梯度小,更易出现下溢出的情况。

2. 舍入误差(Rounding Error) 舍入误差指的是当梯度过小,小于当前区间内的最小间隔时,该次梯度更新可能会失败,用一张图清晰地表示:

这是因为FP16的最小间隔是一个比较玄乎的事,在wikipedia的引用上有这么一张图: 描述了 fp16 各个区间的最小gap。

2.3 FP32 权重备份
这种方法主要是用于解决舍入误差的问题。其主要思路,可以概括为:weights, activations, gradients 等数据在训练中都利用FP16来存储,同时拷贝一份FP32的weights,用于更新。 在这里,我直接贴一张论文[1]的图片来阐述:
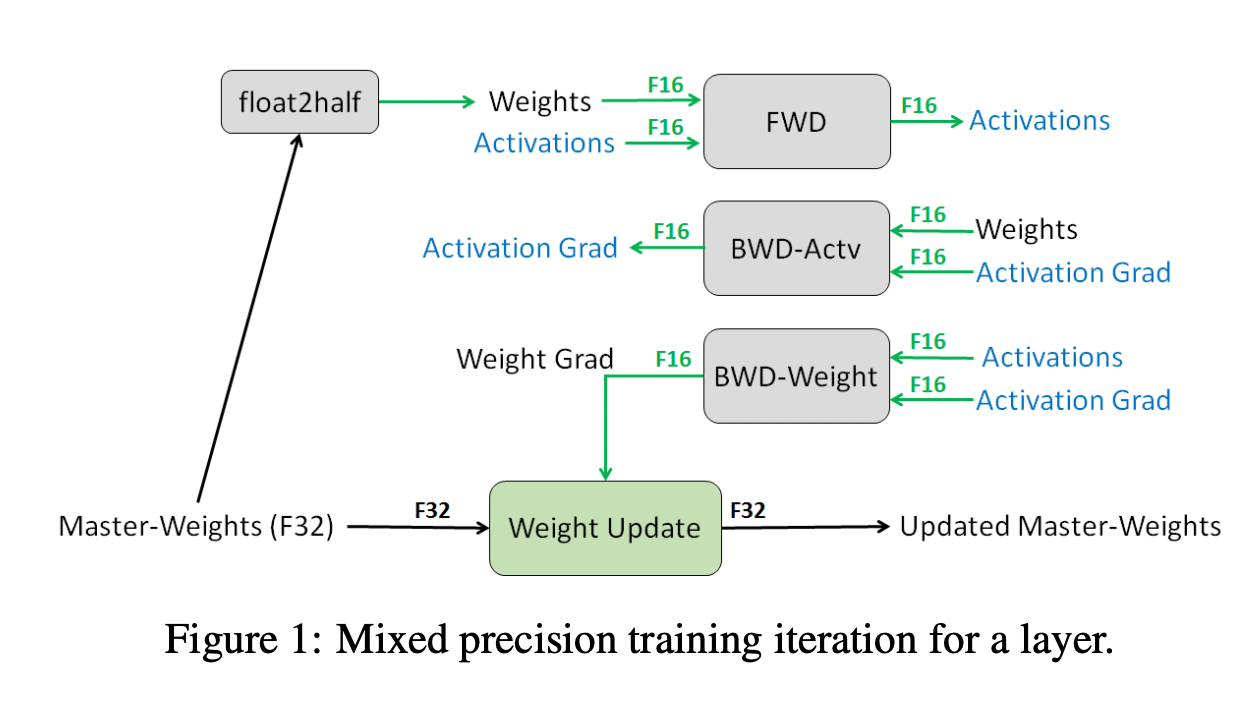
可以看到,其他所有值(weights,activations, gradients)均使用 fp16 来存储,而唯独权重weights需要用 fp32 的格式额外备份一次。 这主要是因为,在更新权重的时候,往往公式: 权重 = 旧权重 + lr * 梯度,而在深度模型中,lr * 梯度 这个值往往是非常小的,如果利用 fp16 来进行相加的话, 则很可能会出现上面所说的『舍入误差』的这个问题,导致更新无效。因此上图中,通过将weights拷贝成 fp32 格式,并且确保整个更新(update)过程是在 fp32 格式下进行的。
看到这里,可能有人提出这种 fp32 拷贝weight的方式,那岂不是使得内存占用反而更高了呢?是的, fp32 额外拷贝一份 weight 的确新增加了训练时候存储的占用。 但是实际上,在训练过程中,内存中占据大部分的基本都是 activations 的值。特别是在batchsize 很大的情况下, activations 更是特别占据空间。 保存 activiations 主要是为了在 back-propogation 的时候进行计算。因此,只要 activation 的值基本都是使用 fp16 来进行存储的话,则最终模型与 fp32 相比起来,内存占用也基本能够减半。
此时所存储的参数为;
FP16: weights,activations,gradients
FP32: weights,gradients
2.4 Loss Scale
Loss Scale 主要是为了解决 fp16 underflow 的问题。刚才提到,训练到了后期,梯度(特别是激活函数平滑段的梯度)会特别小,fp16 表示容易产生 underflow 现象。 下图展示了 SSD 模型在训练过程中,激活函数梯度的分布情况:可以看到,有67%的梯度小于 2−24 ,如果用 fp16 来表示,则这些梯度都会变成0。
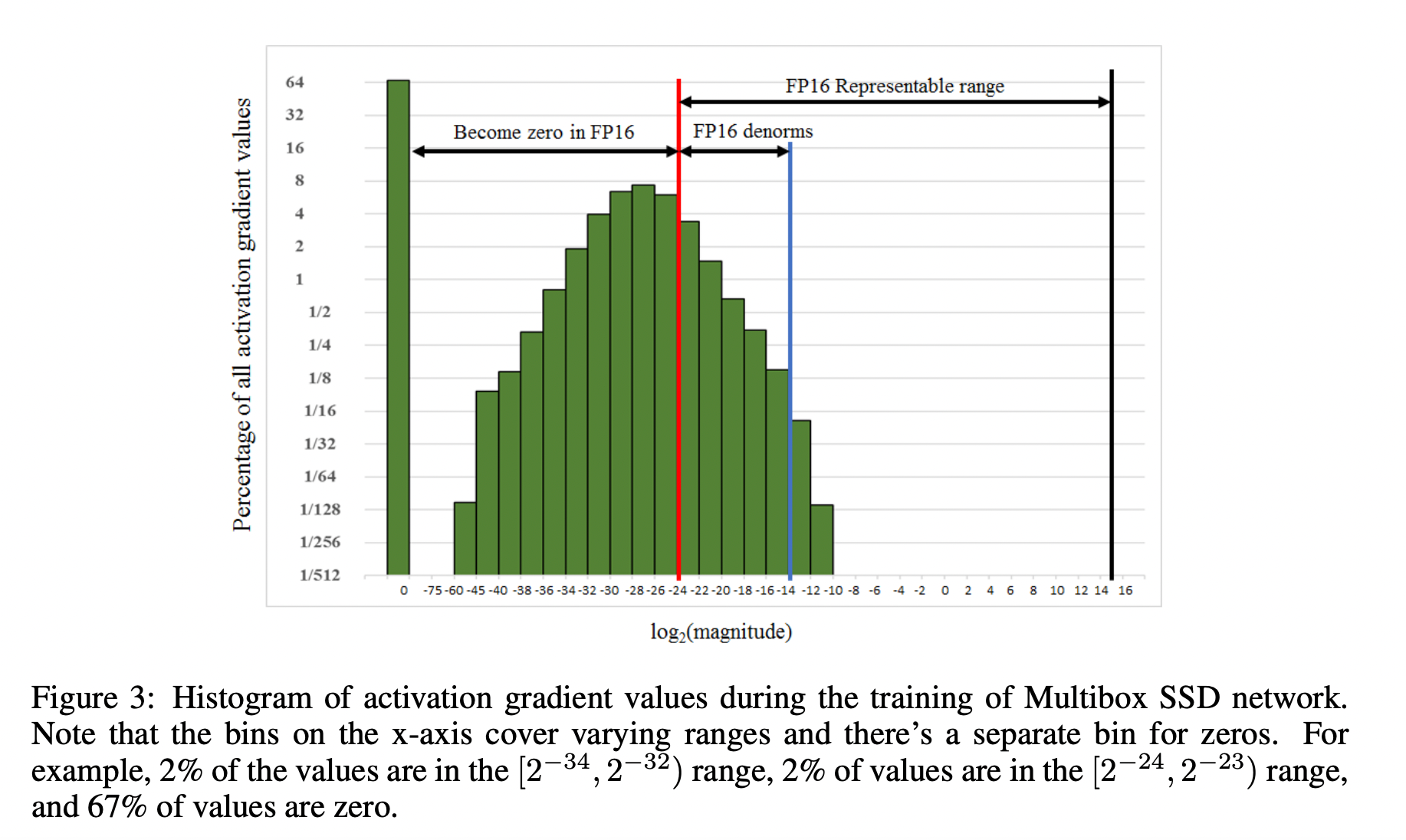
为了解决梯度过小的问题,论文中对计算出来的loss值进行scale,由于链式法则的存在,loss上的scale会作用也会作用在梯度上。这样比起对每个梯度进行scale更加划算。 scaled 过后的梯度,就会平移到 fp16 有效的展示范围内。
这样,scaled-gradient 就可以一直使用 fp16 进行存储了。只有在进行更新的时候,才会将 scaled-gradient 转化为 fp32,同时将scale抹去。论文指出, scale 并非对于所有网络而言都是必须的。而scale的取值为也会特别大,论文给出在 8 - 32k 之间皆可。
2.5 提高算数精度
在论文中还提到一个『计算精度』的问题:在某些模型中,fp16矩阵乘法的过程中,需要利用 fp32 来进行矩阵乘法中间的累加(accumulated),然后再将 fp32 的值转化为 fp16 进行存储。 换句不太严谨的话来说,也就是利用 利用fp16进行乘法和存储,利用fp32来进行加法计算。 这么做的原因主要是为了减少加法过程中的舍入误差,保证精度不损失。
在这里也就引出了,为什么网上大家都说,只有 Nvidia Volta 结构的 拥有 TensorCore 的CPU(例如V100),才能利用 fp16 混合精度来进行加速。 那是因为 TensorCore 能够保证 fp16 的矩阵相乘,利用 fp16 or fp32 来进行累加。在累加阶段能够使用 FP32 大幅减少混合精度训练的精度损失。而其他的GPU 只能支持 fp16 的 multiply-add operation。这里直接贴出原文句子:
Whereas previous GPUs supported only FP16 multiply-add operation, NVIDIA Volta GPUs introduce Tensor Cores that multiply FP16 input matrices andaccumulate products into either FP16 or FP32 outputs