YashanDB共享集群有三大关键组件,崖山集群服务(YCS)、崖山集群文件系统(YFS)、DB组件。上一篇共享集群系列文章《为何共享集群的高可用能力被频频称赞,它的机制有何不同?》深入解析了关键组件的高可用机制与核心技术,本文将深入探讨崖山集群文件系统(YFS)关键技术和特性,并阐释我们选择自主研发共享集群存储服务组件的原因。
崖山集群文件系统(YFS)是YashanDB的一个用户态存储服务组件,提供了文件系统以及磁盘组管理能力,用于管理共享磁阵。用户可通过YFS实现共享磁阵上基本的文件/文件夹的创建、删除、浏览等功能。此外,YFS还提供了管理diskgroup(磁盘组)、failuregroup(故障组)等重要特性,以支持共享集群的存储高可用。
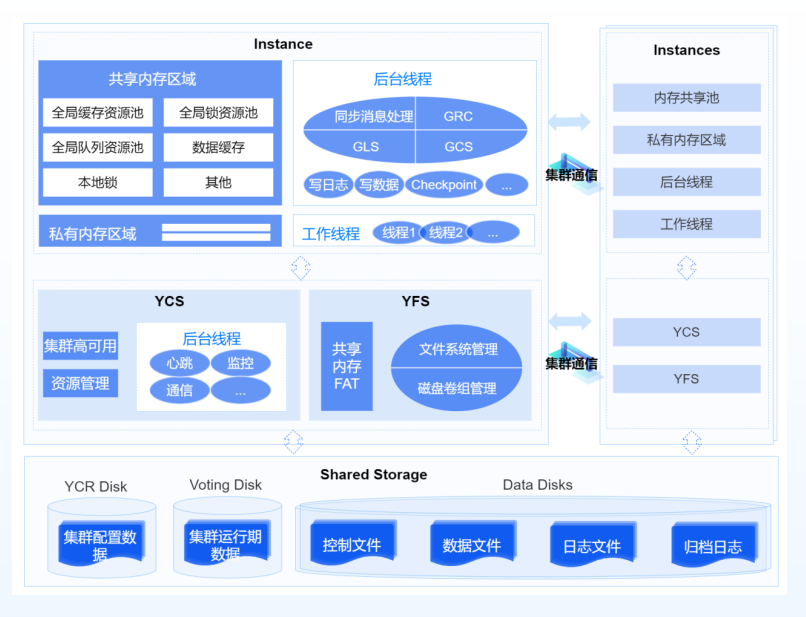
图1 YashanDB共享集群总体架构
Q.为什么选择自研YFS?
一是YashanDB共享集群作为高性能、高可用集群,对存储组件提出几大高要求:
-
高效访问共享存储。集群内多节点访问相同的存储设备,存储本身为各节点的临界资源,需要一套机制,协调各节点,高效、正确的读写共享存储资源。
-
支持Bypass操作系统缓存。YashanDB 集群集成了自研的聚合内存技术,利用集群各节点内存,共同构架了一个大容量、高效率的cache。这也意味着不再需要操作系统IO缓存,也避免了系统缓存造成的延迟,引起各节点数据不一致的可能性。
-
提升存储IO性能,最大程度发挥集群架构的优势。
-
保障集群高可用性。是DB数据到存储设备的必经之路,存储组件必须保证数据不丢失、数据服务高可用。
二是市面上现有的解决方案无法满足YashanDB共享集群以及集群高可用要求:
首先,在项目初期,优先考虑过现有系统是否可以支撑YashanDB集群需求,但Ext3/4等单机文件系统天生不支持共享存储,需要构造特定条件,把单机文件系统当作共享文件系统使用。
其次,GFS、NFS等方案性能无法满足YashanDB集群高可用要求。GFS、NFS等方案与YashanDB集群的场景匹配度不高,通用方案没法针对DB特定场景优化,额外的通信开销较多,仅能达到能用的程度。支撑YashanDB作为高性能核心交易系统,还是有一定差距的。
尝试了诸多方案后,我们决定自研崖山集群文件系统YFS,直接管理裸设备。
YFS管理裸设备的优势
优势1:源码可控,定向提升IO性能。根据DB的业务需求和业务特征,在文件系统层做定向的IO性能优化。
优势2:解决元数据同步问题。
优势3:高可用能力下沉,简化业务层逻辑。在文件系统层支持部分DB高可用能力,如解决脑裂双写、数据损坏等问题。
优势4:提供文件系统接口,抽象存储细节。在同一抽象层里,崖山集群文件系统YFS可以跟单机的文件系统具备相同的接口,如支持open、close、read、write等接口。
YFS最终技术选型
内核态or用户态
在设计初期,我们面临两个选择:YFS应该部署在内核态还是用户态。考虑到YFS的应用场景、部署环境等因素,最终YFS是一个用户态的存储服务组件。
一是用户态服务灾备恢复速度快。内核模块异常可能引起系统crash,得益于Linux系统的进程隔离,用户态服务异常几乎不会引起系统级灾难,可以快速从异常中恢复。
二是我们希望YFS可以不依赖特定内核版本。YashanDB共享集群的部署环境较复杂,内核版本繁杂,还有一些厂商定制内核,我们希望YFS是一个便携的服务,不依赖特定的内核版本。
三是考虑到YFS的服务对象,选择用户态性价比较高。内核模块确实具备最高的系统权限,可以访问从硬件相关的底层特性,到进程资源、状态等信息,不过YFS是面向YAC这样特定业务的文件系统,服务对象简单的多,在用户态有其他方案可以实现同等效果,而且成本可控。
四是用户态进程开发、调试比内核态更便捷。YFS具备可伸缩的软件架构,用户态下更方便使用一些高级库支持,不会受制于内核的限制。

图2 内核态和用户态优劣势
架构
YFS由共享存储上的元数据和YFS服务进程构成。元数据包含文件、目录信息,YFS的一些内部状态等。YFS通过多副本技术,文件在共享存储中具备可配置的冗余。崖山集群文件系统YFS架构详见下图:
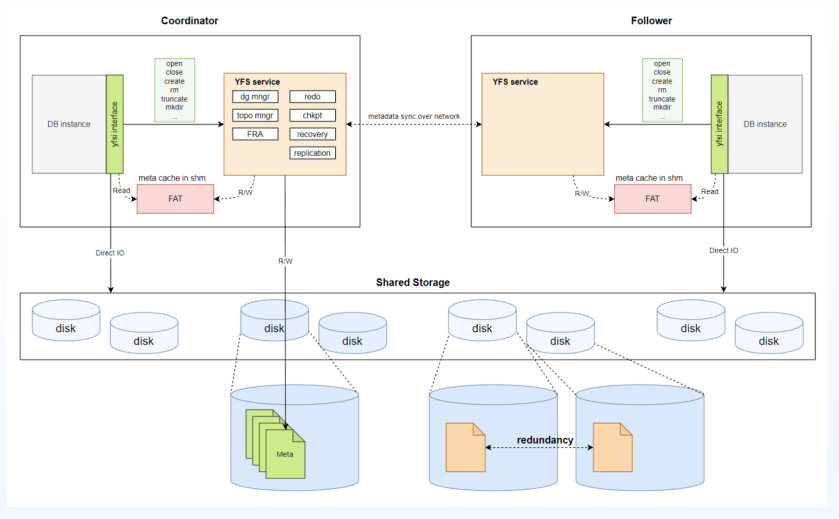
图3 YFS架构图
关键技术
下面我们介绍YFS是如何实现高性能、高可用特性。主要从物理存储结构、逻辑存储结构、逻辑对象等方面描述。
物理存储结构
YFS的磁盘空间分为3个逻辑层次,block、AU(Allocation Unit)、Extent,目前单个磁盘可以支持到PB级,能兼容市面上绝大多数存储设备。
-
block
-
是YFS的最小管理单元
-
是YFS元数据的最小管理单元,通常为4K
-
缺点:1)颗粒度较小,需要大量的管理结构;2)磁盘空间碎片化,连续IO性能不好
-
AU(Allocation Unit)
-
连续的block整合成一个AU
-
是YFS管理磁盘的最小单位,支持多种规格配置
-
优点:兼顾存储空间管理的灵活性、和效率
-
Extent
-
多个连续的AU也会组成更大的连续区域Extent
-
YFS支持变长Extent,可管理PB级的单盘
-
优点:1)可以扩大FAT的寻址能力;2)适配市面常见的存储规格
逻辑存储结构
YFS作为集群的存储组件,除了以外部磁阵实现数据高可用外,也内置一套文件级的冗余机制来实现数据的高可用。并引入故障组概念,描述YFS如何管理磁盘故障特性。
-
故障组
-
故障组描述磁盘故障相关性
-
合理配置故障组是管理员的责任,不同运维场景,分配不同
-
YFS通过故障组,感知共享存储的外部环境,识别各磁盘故障率之间的相关性,安排冗余数据的存储位置
-
磁盘组
YFS管理多个磁盘组,并根据各磁盘组的差异性,对管理的存储资源分类,形成3层结构:
-
各磁盘组故障、资源、业务隔离
-
磁盘之间通过故障组描述各磁盘故障相关性
-
各故障组的磁盘共同支撑冗余机制,数据高可用
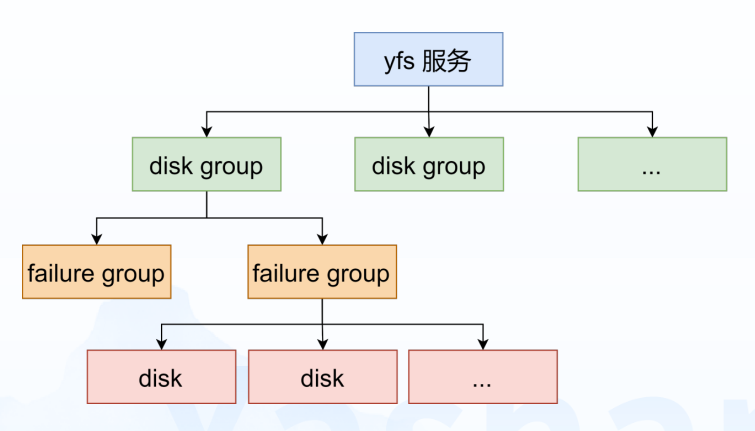
图4 YFS磁盘管理层次图
逻辑对象
YFS的设计参考了现行流行文件系统的实现,并根据YashnDB的业务特征做了很多改进。
一是YashanDB文件尺寸跨度较大,我们希望兼顾大小文件管理的便利,决定YFS采用二级索引,并用其他机制来解决二级索引可能面临的文件大小限制问题。
-
二级索引:YFS的FAT采用简化的2级索引,控制文件元数据的大小。
-
1级直接索引的前半部分slot,直接指向大小为1AU的Extent,紧凑的管理小文件。即对于小文件只需要自己的数据AU和4K的控制信息即可,管理效率较高。
-
1级索引的后半部分slot指向间接索引AU,索引AU由一组4K的间接索引block构成,其中的slot才指向数据Extent。
-
阶梯式变长Extent:YFS采用变长Extent,进一步提升对超大文件的管理能力,实现更大的文件只需要较少的间接索引slot即可管理。
-
在文件的第2万个AU处Extent扩展为4AU,第10万个AU处扩展为16个。
通过二级索引和阶梯式变长Extent,YFS最大可支持500PB的单个文件。
二是YFS奉行“一切皆文件”的Linux哲学,所有元数据均采用文件管理,根据用户是否可见分为元文件和用户文件两类。具体文件分类如下:
-
元文件,用户不可见。
-
超级文件。是YFS元数据的入口文件,记录所有文件的元信息。YFS通过超级文件完成元数据自举。
-
Dir文件。用于记录YFS的目录层次。
-
YFS Redo,实现YFS的原子操作,也是YFS高可用重要组成部分。
-
等等。
-
用户文件,由用户通过createFile创建,保存用户数据。
采用该管理方式具有两个优势,一是元数据和用户数据统一由文件管理,共用YFS文件级高可用策略;二是元数据以文件管理,无论元文件的数量还是大小,都具备无限扩展能力,使得YFS具备无限的演进可能。
特性
高可用性
YFS具备Diskgroup级(磁盘级)的资源隔离,保障YFS持续可用。
一是物理存储隔离,不存在横跨多个磁盘组的磁盘,某个故障的磁盘组不会影响其他磁盘组的数据可用性,在极端情况下,灾难性损失控制在磁盘组内;二是磁盘运行时资源隔离,可避免故障磁盘组影响其他磁盘组的业务,保证YFS业务的持续性。
YFS内置Redo,保存在元文件中,对用户不可见。
一是保证元数据操作的原子性,不因个别节点故障而使YFS集群状态不确定;二是实现集群状态一致性。YFS集群会选举协调节点,管理集群元数据变更业务,通过日志复制同步实现集群状态一致性;三是协调节点故障时,YFS集群会选举新的协调节点,利用YFS Redo文件恢复元数据状态。
YFS提供实时数据修复能力,自动切换故障副本,切换过程对DB透明,业务无感知。
在读取数据时,会乱序读取副本数据,并校验数据,如果发现数据损坏,则自动切换副本继续读取,直到读到完整数据。有助于YFS承载YashanDB部分高可用能力。
YFS通过快速恢复区技术作为单副本时的补充,对YFS元数据提供额外的保护。
快速恢复区记录YFS元数据变更的历史数据,当发现YFS元数据故障时,会尝试从快速恢复区找到最近的历史数据,恢复YFS元数据。
扩缩容能力
YFS支持集群横向扩容和对空间扩缩容。在横向扩容中,允许在线加入或移除节点,集群管理模块会自动识别到新节点;同时YFS支持在线增减盘,支持在线创建磁盘组、向已有磁盘组增加故障组、向已有故障组增加磁盘三种。
用户可以根据实际的运维场景,随着业务增长,按需扩充YFS管理的存储空间。
高性能IO
YFS具备极好的性能指标,支撑YashanDB集群取得行业领先的性能测试成绩。YFS采用多种技术和架构,突破传统文件系统的性能瓶颈。
一是YFS直接管理裸设备,在大批量读写操作时,有效发挥集群多节点的并发IO优势,实现系统总体吞吐效率最大化。
二是YFS借助元数据缓存,各节点IO过程完全独立,**除数据读写操作外,不会引入额外的通信开销,**不会因为更多的节点发起而导致整体IO性能下降。
三是YFS实现了AU级条带化。当读取数据时,YFS会将IO请求离散到不同的磁盘,系统总体IO带宽可以超过单个磁盘的带宽。
四是YFS支持可定制的AU size,根据业务的IO特征,选择匹配的AU size,在顺序IO时获得最佳性能。

图5 YFS建表删表性能参考图
支持多种常见API
YFS支持大多数常用文件语义接口,文件的增删改查、读写等,目录的基本操作等,满足YashanDB的业务需要。

图6 YFS适用的文件语义接口
YFS是用户态文件服务,我们开发了专用的管理客户端,方便管理员登陆YFS执行日常管理,兼容常见的Linux shell指令。

图7 YFS适用的文件管理命令
YFS作为YashanDB共享集群的存储组件,为了满足集群高可用性而研发,提升了集群存储的IO性能、解决集群元数据同步问题、承载集群部分高可用能力。未来YFS将持续迭代,提供更多强大易用的功能,助力用户实现更稳定、更灵活的集群存储管理。





![[数据集][目标检测]汽油检泄漏检测数据集VOC+YOLO格式237张2类别](https://i-blog.csdnimg.cn/direct/c94b917c554b499692e34ba541bd7e44.png)