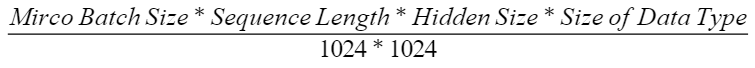人工智能咨询培训老师叶梓 转载标明出处
大模型在静态知识库的更新上存在局限,特别是在面对需要多步骤推理的多跳问题时,难以提供准确和最新的回答。为了解决这一问题,来自美国佐治亚大学、纽约大学、莱斯大学、北卡罗来纳州立大学等机构的研究人员提出了一种名为“检索增强型知识编辑(Retrieval-Augmented model Editing, RAE)”的框架。图1展示了一个例子,说明了传统的基于相似度的搜索方法在检索用于语言模型编辑的正确事实时的不足,以及如何通过更复杂的检索策略来改进这一过程。

论文链接:https://arxiv.org/pdf/2403.19631
方法
检索增强型知识编辑框架旨在提升多跳问答中的语言模型性能,主要包含两个关键步骤:(1) 检索与问题相关的编辑过的事实(edited facts);(2) 使用这些检索到的事实通过上下文学习(in-context learning)编辑语言模型。
简单的编辑方法可能会使用基于相似度的搜索来检索与目标问题相似的编辑过的事实。这些事实随后被整合到一个提示模板中,通过上下文学习进行编辑。例如,模板可以是“Given fact: {𝛿′}, {𝑞} ?”。然而,这种方法在检索需要回答𝑞的问题时编辑过的事实Δ𝑞时存在困难,因为这些事实通常包含与𝑞不同的实体,导致在大型事实库Δ中得到低相似度分数。
为了解决这个问题,研究者提出了编辑事实链提取的方法来获取![]() 。每个
。每个![]() 本质上形成了一个连接的知识图谱(KG)。这样的知识图谱可以通过从一个实体到另一个实体的迭代遍历来检索。
本质上形成了一个连接的知识图谱(KG)。这样的知识图谱可以通过从一个实体到另一个实体的迭代遍历来检索。

图2展示了检索增强型上下文模型编辑方法的总体框架。在这个框架中,可以看到从外部知识图谱到编辑记忆的步骤,然后通过互信息基于检索得到检索事实,最后通过上下文学习进行编辑。
研究者介绍了如何构建一个连接不同事实的知识图谱,并提出了给定输入问题时提取相关子图的目标:
为了有效地编辑,检索到的子图𝐺𝑆必须与问题共享相关信息。因此,定义子图检索的目标是最大化子图和需要编辑答案的问题集之间的互信息(MI)。互信息的公式化定义如下:
\text{max}_{𝐺𝑆} \𝐼(𝑄;𝐺𝑆) = 𝐻(𝑄) − 𝐻 (𝑄 | 𝐺 = 𝐺𝑆)
这里,𝐻(𝑄)是固定的问题集𝑄的香农熵,是常数。因此,最大化互信息𝐼(𝑄;𝐺𝑆)相当于最小化条件熵𝐻(𝑄 | 𝐺 = 𝐺𝑆)。
为了解决实际中计算𝑝(𝑞|𝐺 = 𝐺𝑆)的挑战,研究者提出了利用大型语言模型的下一词预测能力来计算概率。给定形成尾到头连接知识图谱的事实链,提取的子图𝐺𝑆可以表示为𝐺𝑆 =(ℎ1, 𝑟1, 𝑡1, ..., ℎ𝑛, 𝑟𝑛, 𝑡𝑛),其中ℎ𝑖和𝑡𝑖是节点,𝑟𝑖是边,𝑛是检索到的三元组的数量。
为了减少检索到的子图中可能引入的不相关信息,研究者提出了一种剪枝方法,该方法利用模型输出的不确定性来消除冗余事实。通过实验验证了这种方法的有效性,实验中使用了不同的事实子集作为模型输入,并观察到当事实子集包含问题的全部事实链时,模型输出的熵显著降低。
想要掌握如何将大模型的力量发挥到极致吗?叶老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具。9月22日晚,实战专家1小时讲解让您轻松上手,学习如何使用 Llama Factory 微调模型。
加助理微信提供直播链接:amliy007,29.9元即可参加线上直播分享,叶老师亲自指导,互动沟通,全面掌握Llama Factory,关注享粉丝福利,限时免费CSDN听直播后的录播讲解。
LLaMA Factory 支持多种预训练模型和微调算法。它提供灵活的运算精度和优化算法选择,以及丰富的实验监控工具。开源特性和社区支持使其易于使用,适合各类用户快速提升模型性能。
实验
实验回答以下问题:
- RAE在编辑LLM输出方面的效果如何?
- 他们的检索策略与其他检索方法相比表现如何?
- 他们提出的剪枝技术是否能够从检索到的事实中移除冗余信息?
- RAE是否适用于专有的LLMs?
实验涉及多种不同大小和系列的语言模型,包括GPT-2 (1.5B), GPT-J (6B), Falcon (7B), Vicuna (7B), 和 Llama2-chat (7B)。这些模型中,GPT-2, GPT-J, 和 Falcon 是未经指令调整的预训练语言模型,而Vicuna 是 Llama1 的指令调整变体,Llama2-chat 是 Llama2 的指令调整版本。包括这两种类型的模型,以验证所提方法的有效性。
三种模型编辑方法进行比较:模型权重更新方法、辅助模型方法,以及基于RAG的方法。Subgraph Retriever (SR) 作为高级知识检索方法的基准。
在MQUAKE-CF 和 MQUAKE-T 数据集上评估了编辑方法。这些数据集包含不同跳数的问题的编辑实例。利用 MQUAKE-CF-9k 数据集中的相关案例来为基线和方法制作提示模板。

为了回答第一个问题,研究者们评估了他们的模型编辑方法在不同语言模型上的表现,并与不同的基线方法进行了比较。表2 展示了在进行数千次编辑时,RAE在三个数据集上的表现均优于其他方法。这主要得益于他们新颖的基于互信息的检索目标和有效的剪枝策略。
为了回答第二个问题,研究者们评估了他们基于互信息的检索方法在多跳问答任务中的有效性。他们考虑了三种基于嵌入的方法和一种基于概率的方法作为基线。

为了回答第三个问题,研究者们验证了他们提出的剪枝策略对多跳编辑任务的益处。通过在原始问题所需的事实之外始终检索2个额外事实来进行实验。表4 报告了使用或不使用剪枝策略的RAE的编辑准确性,表明剪枝技术显著提高了模型编辑的性能。
为了回答第四个问题,研究者们将RAE应用于只能通过API访问的专有语言模型,如ChatGPT。他们使用GPT-2 (1.5B) 作为检索模型,并报告了他们方法的编辑准确性和总编辑成本。
研究者们还评估了不同编辑批次大小的编辑性能。他们发现,无论是在Vicuna还是Llama2模型中,RAE的准确性在不同编辑实例中保持稳定,而Mello的准确性随着实例的增加显著下降。

通过图6 展示了两个来自M-CF数据集的案例,以演示在知识图谱上的检索过程和检索到的事实的剪枝过程。图中的红色、黑色和虚线代表了使用束搜索的知识图谱中的最终路径、候选路径和丢弃路径,反映了检索设计中的决策过程。
通过这些详细的实验和评估,全面地展示了RAE框架在多跳问答中编辑语言模型的有效性和实用性。