一、模型介绍
interlm是一系列多语言基础模型和聊天模型。
InternLM2.5 系列,具有以下特点:
- 出色的推理能力 :数学推理性能达到世界先进水平,超越 Llama3、Gemma2-9B 等模型。
- 1M 上下文窗口 :在 1M 长上下文中几乎完美地找到大海捞针,在 LongBench 等长上下文任务上具有领先的性能。尝试使用LMDeploy进行 1M 上下文推理。更多详细信息和文件聊天演示请参见此处。
- 工具使用能力更强 :InternLM2.5 支持从 100 多个网页收集信息,相应的实现将很快在Lagent中发布。InternLM2.5 在指令跟踪、工具选择和反思方面具有更好的工具利用相关能力。参见示例。
二、部署流程
1.环境要求
- Python >= 3.8
- PyTorch >= 1.12.0 (2.0.0 and above are recommended)
- Transformers >= 4.38
2.克隆
git clone https://github.com/InternLM/InternLM.git
3.模型的用法
(1)从 Transformers 导入
要使用 Transformers 加载 InternLM2.5-7B-Chat 模型,请使用以下代码:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("internlm/internlm2_5-7b-chat", trust_remote_code=True)
# Set `torch_dtype=torch.float16` to load model in float16, otherwise it will be loaded as float32 and might cause OOM Error.
model = AutoModelForCausalLM.from_pretrained("internlm/internlm2_5-7b-chat", device_map="auto", trust_remote_code=True, torch_dtype=torch.float16)
# (Optional) If on low resource devices, you can load model in 4-bit or 8-bit to further save GPU memory via bitsandbytes.
# InternLM 7B in 4bit will cost nearly 8GB GPU memory.
# pip install -U bitsandbytes
# 8-bit: model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, load_in_8bit=True)
# 4-bit: model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, load_in_4bit=True)
model = model.eval()
response, history = model.chat(tokenizer, "hello", history=[])
print(response)
# Output: Hello? How can I help you today?
response, history = model.chat(tokenizer, "please provide three suggestions about time management", history=history)
print(response)
(2)从 ModelScope 导入
要使用 ModelScope 加载 InternLM2.5-7B-Chat 模型,请使用以下代码:
import torch
from modelscope import snapshot_download, AutoTokenizer, AutoModelForCausalLM
model_dir = snapshot_download('Shanghai_AI_Laboratory/internlm2_5-7b-chat')
tokenizer = AutoTokenizer.from_pretrained(model_dir, device_map="auto", trust_remote_code=True)
# Set `torch_dtype=torch.float16` to load model in float16, otherwise it will be loaded as float32 and might cause OOM Error.
model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, torch_dtype=torch.float16)
# (Optional) If on low resource devices, you can load model in 4-bit or 8-bit to further save GPU memory via bitsandbytes.
# InternLM 7B in 4bit will cost nearly 8GB GPU memory.
# pip install -U bitsandbytes
# 8-bit: model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, load_in_8bit=True)
# 4-bit: model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, load_in_4bit=True)
model = model.eval()
response, history = model.chat(tokenizer, "hello", history=[])
print(response)
response, history = model.chat(tokenizer, "please provide three suggestions about time management", history=history)
print(response)
三、对话
您可以通过运行以下代码通过前端界面与 InternLM Chat 7B 模型进行交互
pip install streamlit
pip install transformers>=4.38
streamlit run ./chat/web_demo.py
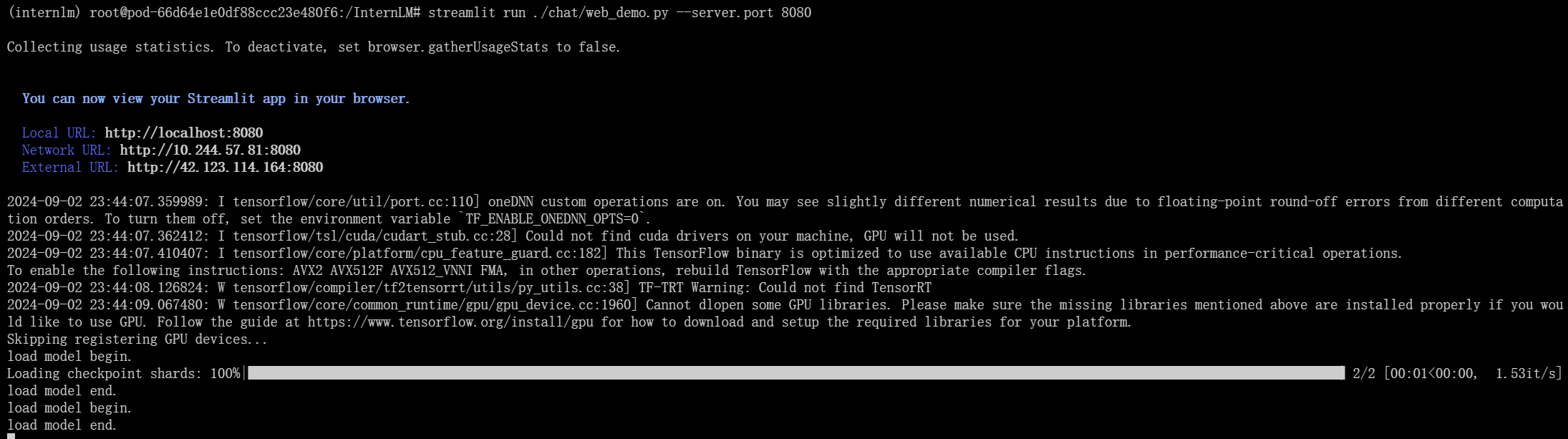
四、网页演示