大家好,我是沐子,推荐一个程序员免费学习的编程网站
我爱编程网(www.love-coding.com)
** 场景**
在高并发的数据处理场景中,接口响应时间的优化显得尤为重要。本文将分享一个真实案例,其中一个数据量达到200万+的接口的响应时间从30秒降低到了0.8秒内。
这个案例不仅展示了问题诊断的过程,也提供了一系列有效的优化措施。
交易系统中,系统需要针对每一笔交易进行拦截(每一笔支付或转账就是一笔交易),拦截时需要根据定义好的规则拦截,这次需要优化的接口是一个统计规则拦截率的接口。
问题诊断
最初,接口的延迟非常高,大约需要30秒才能完成。为了定位问题,我们首先排除了网络和服务器设备因素,并打印了关键代码的执行时间。经过分析,发现问题出在SQL执行上。
发现Sql执行时间太久,查询200万条数据的执行时间竟然达到了30s,下面是是最耗时的部分相关代码逻辑:
查询代码(其实就是使用Mybatis查询,看起来正常的很)
List<Map<String, Object>> list = transhandleFlowMapper.selectDataTransHandleFlowAdd(selectSql);
统计当天的Id号(programhandleidlist字段)
SELECT programhandleidlist FROM anti_transhandle WHERE create_time BETWEEN '2024-01-08 00:00:00.0' AND '2024-01-09 00:00:00.0';
表结构(Postgresql)
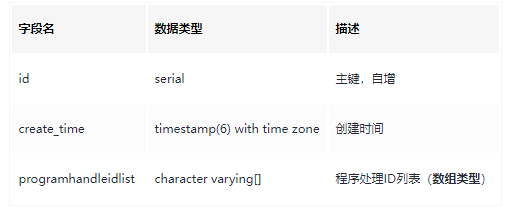
我以为是Sql写的有问题,先拿着sql执行了一边,发现只执行sql的执行时间是大约800毫秒,和30秒差距巨大。
Sql层面分析
使用EXPLAIN ANALYZE函数分析sql。
EXPLAIN ANALYZE
SELECT programhandleidlist FROM anti_transhandle WHERE create_time BETWEEN '2024-01-08 00:00:00.0' AND '2024-01-09 00:00:00.0';
分析结果

看来是代码的部分有问题。
代码层面分析
List<Map<String, Object>> list = transhandleFlowMapper.selectDataTransHandleFlowAdd(selectSql);
Map的Key是programhandleIdList,Map的value是每一行的值。


在Java层面,每条数据都创建了一个Map对象,对于200万+的数据量来说,这显然是非常耗时的操作,速度是被创建了大量的Map集合给拖垮的。。
为了解决这个问题,我们尝试了将200万行数据转换为单行返回,使用PostgreSQL的array_agg和unnest函数来优化查询。
第一次遇到Mybatis查询返回导致接口速度慢的问题。
优化措施
1. SQL优化
我的思路是将200万行转为一行返回。
要将 PostgreSQL 中查询出的 programhandleidlist 字段(假设这是一个数组类型)的所有元素拼接为一行,您可以使用数组聚合函数 array_agg 结合 unnest 函数。
这样做可以先将数组展开为多行,然后将这些行再次聚合为一个单一的数组。如果您希望最终结果是一个字符串,而不是数组,您还可以使用 string_agg 函数。
以下是相应的 SQL 语句:
SELECT array_agg(elem) AS concatenated_array
FROM (
SELECT unnest(programhandleidlist) AS elem
FROM anti_transhandle
WHERE create_time BETWEEN '2024-01-08 00:00:00.0' AND '2024-01-09 00:00:00.0'
) sub;
在这个查询中:
unnest(programhandleidlist)将programhandleidlist数组展开成多行。string_agg(elem)将这些行聚合成一个以逗号分隔的字符串。
这将返回一个包含所有元素的单一数组。
查询结果由多行,拼接为了一行。

再测试,现在是正常速度了,但是查询时间依旧很高。Sql查询时间0.8秒,代码中平均1秒8左右,还有优化的空间。

将一列数据转换为了数组类型,查看一下内存占用,这一段占用了54比特,虽然占用不大,但是不知道为什么会mybatis处理时间这么久。
- 因为mybatis不知道数组的大小,先给数组设定一个初始大小,如果超出了数组长度,因为数组不能扩容,增加长度只能再复制一份到另一块内存中,复制的次数多了也就增加了计算时间。
- 数据需要在两个设备之间传输,磁盘和网络都需要时间。

2. 部分业务逻辑转到数据库中计算
再次优化sql,将一部分的逻辑放到Sql中处理,减少数据量。
业务上我需要统计programhandleidlist字段中id出现的次数,所以我直接在sql中做统计。
要统计每个数组中元素出现的次数,您需要首先使用 unnest 函数将数组展开为单独的行,然后使用 GROUP BY 和聚合函数(如 count)来计算每个元素的出现次数。这里是修改后的 SQL 语句:
SELECT elem, COUNT(*) AS count
FROM (
SELECT unnest(programhandleidlist) AS elem
FROM anti_transhandle
WHERE create_time BETWEEN '2024-01-08 00:00:00.0' AND '2024-01-09 00:00:00.0'
) sub
GROUP BY elem;
在这个查询中:
unnest(programhandleidlist)将每个programhandleidlist数组展开成多个行。GROUP BY elem对每个独立的元素进行分组。COUNT(*)计算每个分组(即每个元素)的出现次数。
这个查询将返回两列:一列是元素(elem),另一列是该元素在所有数组中出现的次数(count)。

这条sql在代码中执行时间是0.7秒,还是时间太长,毕竟数据库的数据量太大,搜了很多方法,已经是我能做到的最快查询了。
关系型数据库 不适合做海量数据计算查询。
“
这个业务场景牵扯到了海量数据的统计,并不适合使用关系型数据库,如果想要真正的做到毫秒级的查询,需要从设计上改变数据的存储结果。比如使用cilckhouse、hive等存储计算。
3. 引入缓存机制
减少查询数据库的次数,决定引入本地缓存机制。选择了Caffeine作为缓存框架,易于与Spring集成。
分析业务后,当天的统计数据必须查询数据库,但是查询历史日期的采用缓存的方式。如果业务中对时效性不敏感,也可以缓存当天的数据,每隔一段时间更新一次。我这里采用缓存历史日期的数据。
1.引入Caffeine依赖
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>3.1.8</version>
</dependency>
2.配置Caffeine缓存
创建一个专门的Caffeine缓存配置。使用本地缓存选择淘汰策略很重要,由于我的业务场景使根据实现来查询,所以Caffeine将按照最近最少使用(LRU)的策略来淘汰旧数据成符合业务。
import com.github.benmanes.caffeine.cache.Caffeine;
import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.cache.caffeine.CaffeineCacheManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.concurrent.TimeUnit;
@Configuration
@EnableCaching
public class CacheConfig {
@Bean
public CacheManager cacheManager() {
CaffeineCacheManager cacheManager = new CaffeineCacheManager();
cacheManager.setCaffeine(Caffeine.newBuilder()
.maximumSize(500)
.expireAfterWrite(60, TimeUnit.MINUTES));
return cacheManager;
}
}
3.修改ruleHitRate方法来使用Caffeine缓存
在计算昨天命中率的逻辑前加入缓存检查和更新的逻辑。
使用Caffeine缓存:
@Autowired
private CacheManager cacheManager; // 注入Spring的CacheManager
private static final String YESTERDAY_HIT_RATE_CACHE = "hitRateCache"; // 缓存名称
@Override
public RuleHitRateResponse ruleHitRate(LocalDate currentDate) {
// ... 其他代码 ...
// 使用缓存获取昨天的命中率
double hitRate = cacheManager.getCache(YESTERDAY_HIT_RATE_CACHE).get(currentDate.minusDays(1), () -> {
// 查询数据库
Map<String, String> hitRateList = dataTunnelClient.selectTransHandleFlowByTime(currentDate.minusDays(1));
// ... 其他代码 ...
// 返回计算后的结果
return hitRate;
});
// ... 其他代码 ...
}
总结
最后,测试接口,成功将接口从30秒降低到了0.8秒以内。
这次优化让我重新真正审视了关系型数据库的劣势。选择哪种类型的数据库,取决于具体的应用场景和需求。
- 关系型数据库(Mysql、Oracle等)适合事务性强、数据一致性和完整性要求高的应用。
- 列式数据库(HBase、ClickHouse等)则适合大数据量的分析和统计,特别是在读取性能方面有显著优势。
此次的业务场景显然更适合使用列式数据库,所以导致使用关系型数据库无论如何也不能够达到足够高的性能。
🔥免费学习编程的网站 热门推荐🔥
我爱编程网(www.love-coding.com),程序员免费学习的编程网站