在数据分析过程中,groupby语句,起到对原始数据集,进行分组和聚合的作用。我们在进行数据处理的时候,经常需要对不同的数据维度,以及不同的数据切片集合,进行操作和处理。
比如说,假设我们有全国人口数据集,而我们分析数据的时候,关注的主要问题是,不同省份之间,人们的平均身高是个什么情况。
对于这样的数据分析问题,我们就需要先通过省份列,对数据集进行分组。在分组完成之后,获取每个组的身高列,然后通过计算平均值的聚合函数,对分组后的数据集进行聚合。这样,我们就能够得到,不同省份,人们的平均身高数据。
在pandas中,groupby语句遵循的是拆分,应用,组合的过程。
拆分,是按照一些业务逻辑规则,也就是我们需要分析的问题点,把数据集拆分到不同的组。
应用,则是在这些不同的组之间,独立进行操作和计算。
组合,是把操作和计算完成后的数据,重新形成一个我们所需要的结果数据集。
将对象拆分为组
我们可以按照不同的列,将原始数据集,通过groupby语句,拆分为一个需要操作的对象。
生成原始数据集
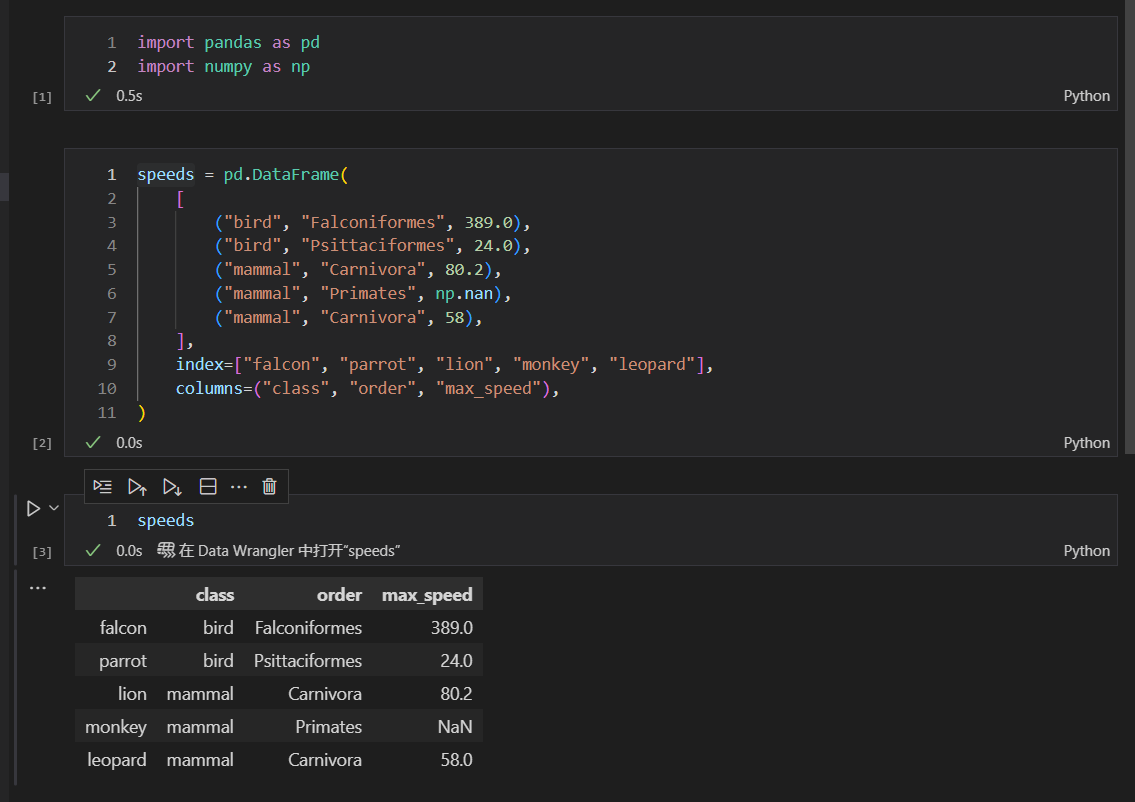
我们这里,需要通过class列,对数据集speeds进行分组。
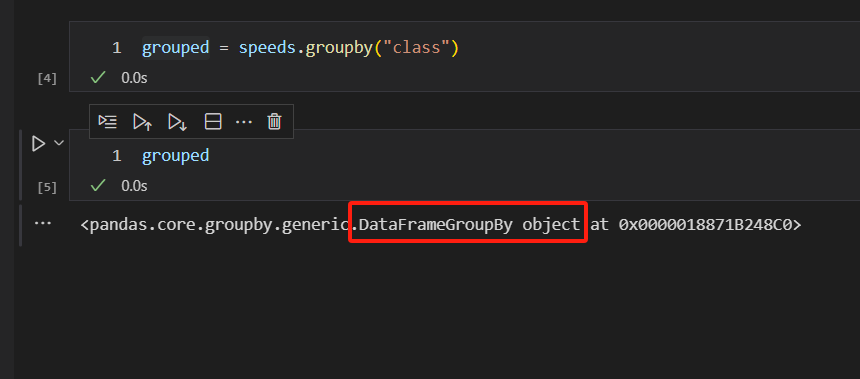
注意,分组完成后的结果,是一个GroupBy对象。
我们也可以通过不同的列,以及两个列的组合,来对数据集进行分组。
这里,重新生成一个数据集

通过A列,B列,以及AB列的组合来对数据集进行分组
通过以上操作,我们就完成了对原始数据集的拆分过程。
分组数据的排序和聚合
对数据集分组完成后,我们就需要在分组后的对象上,运用一些操作,比如说,排序和聚合操作。
我们用一个新的数据集
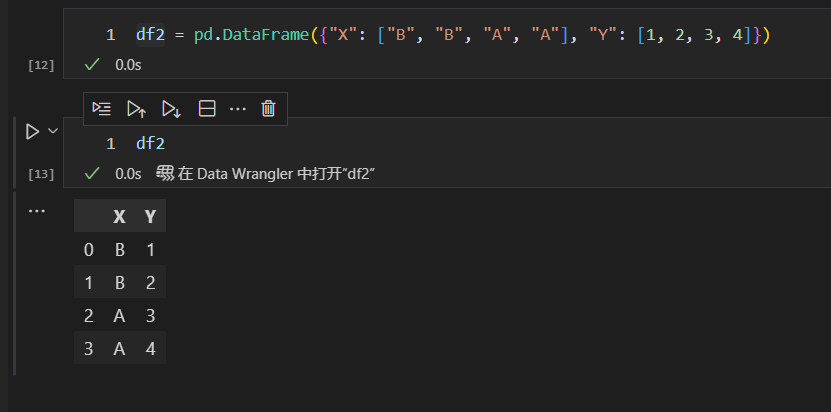
然后,通过X列进行分组,分组完成后,对数据进行求和操作。

还可以对求和后的分组数据,进行升序,或者是降序的排列操作
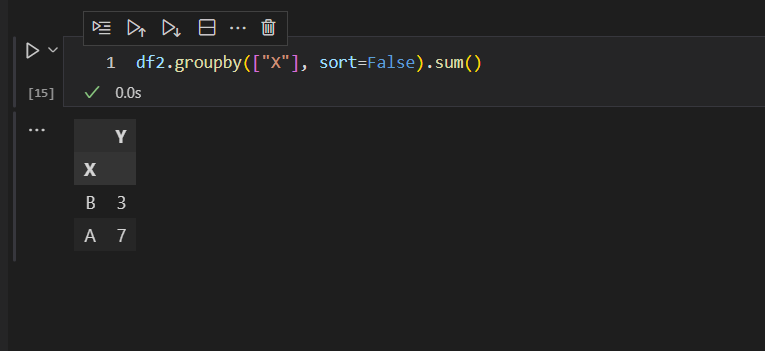
其实,上面的求和操作,就是数据的聚合操作。也就是说,按照X列分组后,得到A和B两个组,再对A和B两个组,分别进行求和,最后得到我们需要的结果集。
多数据标签的分组操作
如果我们的数据主键,也就是数据标签,是复合的多数据标签的话,分组的过程略有差异。
我们来看一个例子
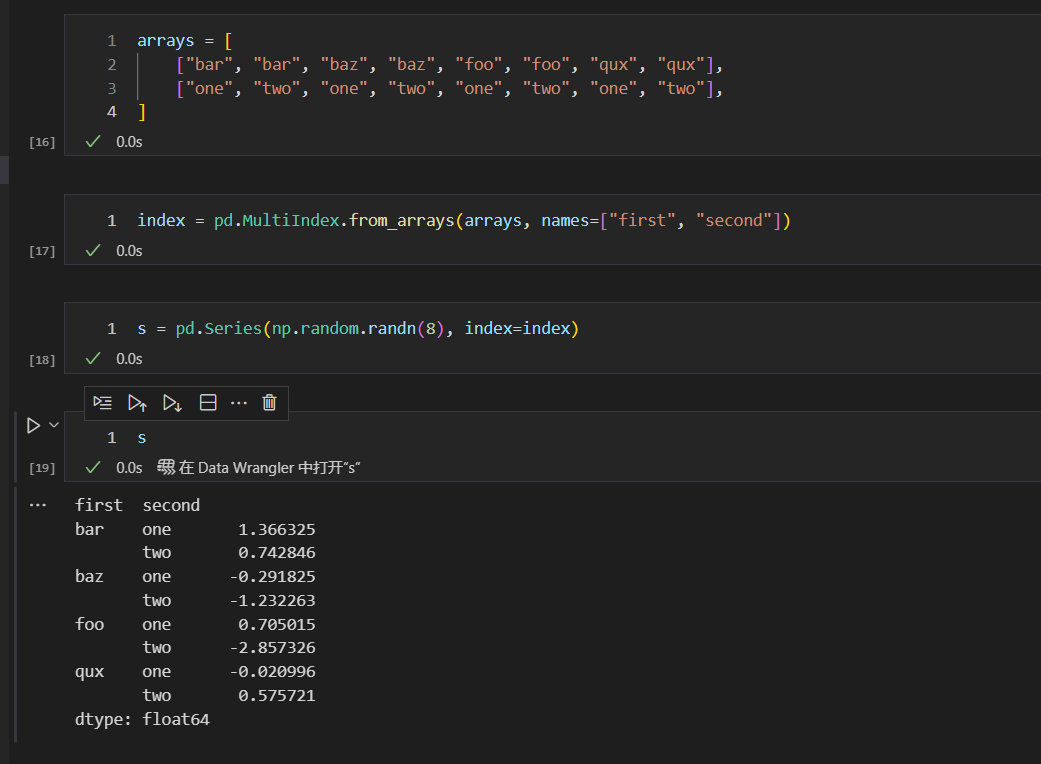
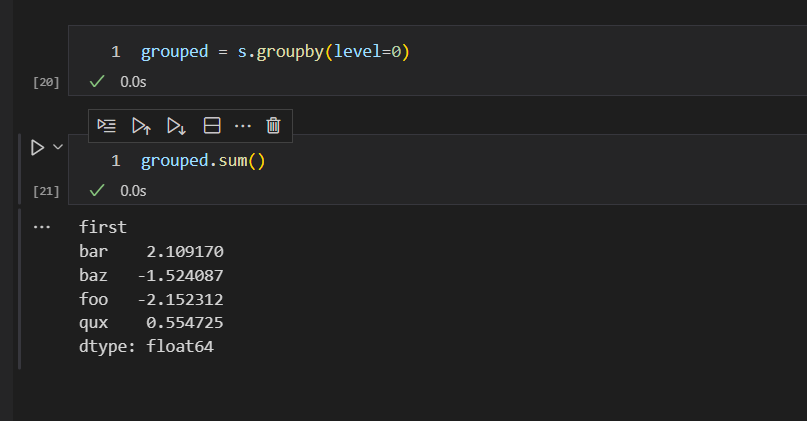
如果要通过数据标签first进行分组,并且求和的话,需要设置level=0
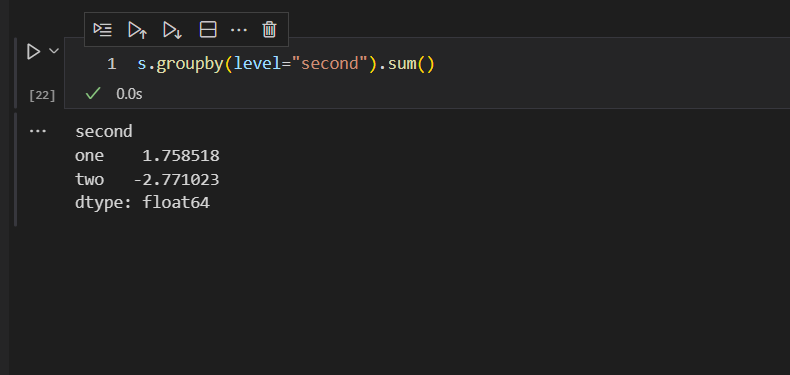
也可以用数据标签名称来实现操作
如果要对多数据标签进行分组求和的话,比如说用first和second两列来进行分组,则需要有三列数据标签。
我们先生成三列数据标签的数据集
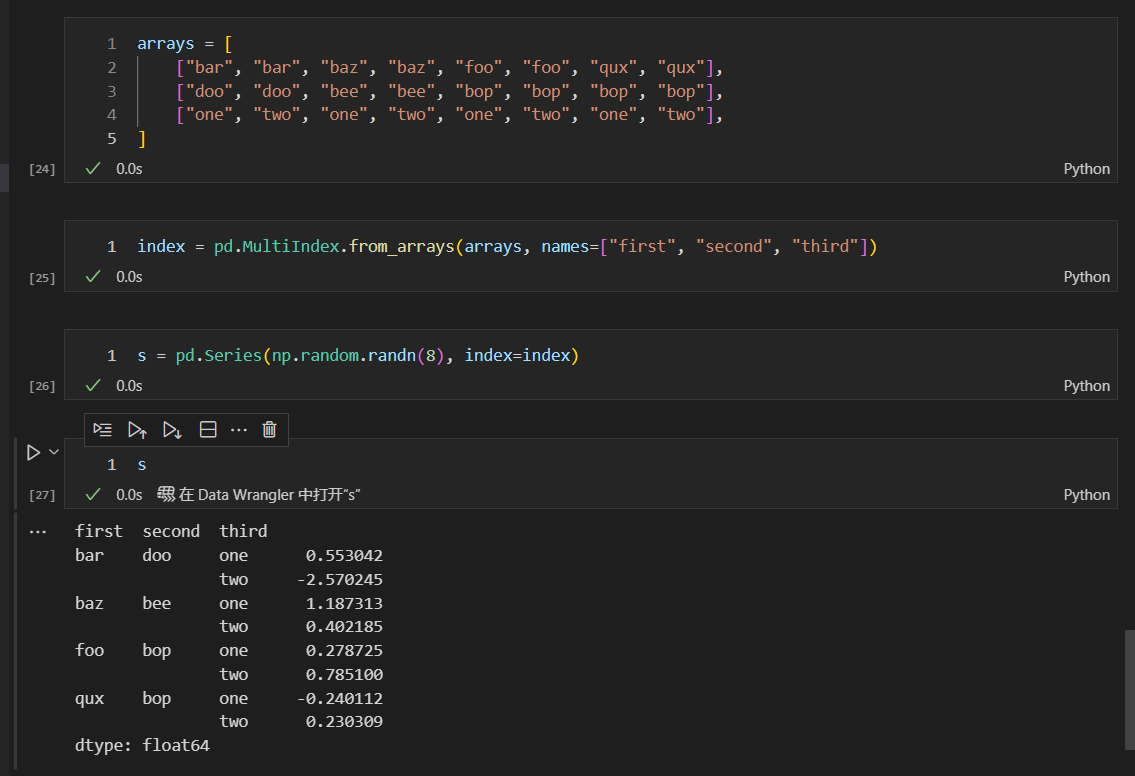
通过first和second两列分组,并且求和
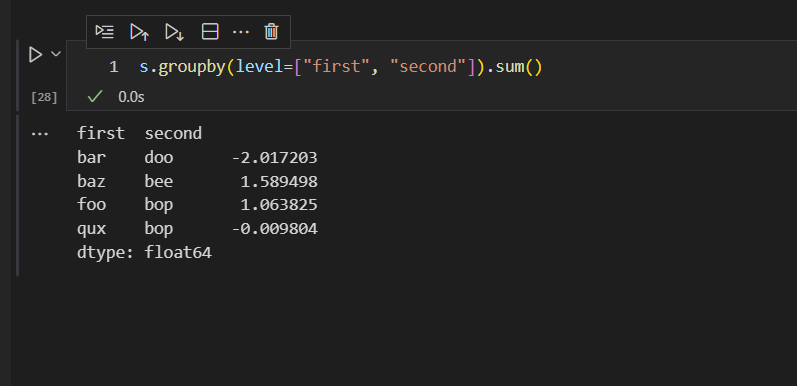
这个过程稍微有些复杂,分组是通过first和second两列进行的,求和是通过第三个数据标签,也就是third数据标签列进行求和的。
数据标签和普通列的分组操作
有些时候,我们需要同时选择一个数据标签和一个普通列进行分组操作,这个过程的实现方式如下。
生成原始数据集

选择second列和A列进行分组,并且求和
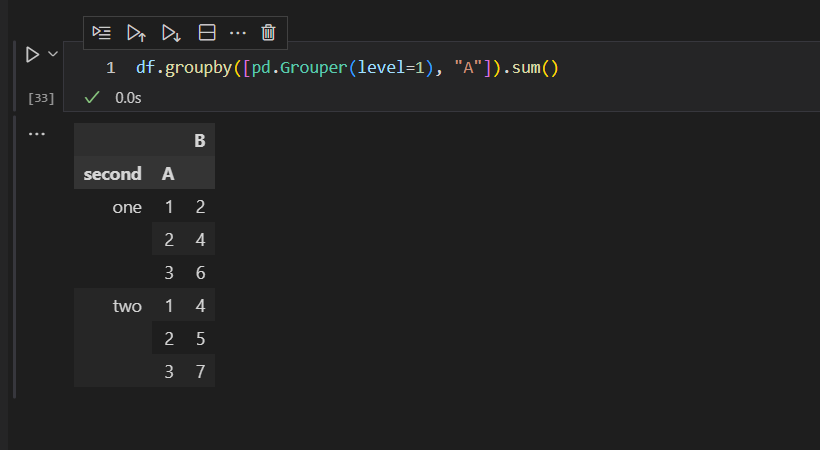
也可以通过数据标签列名来实现
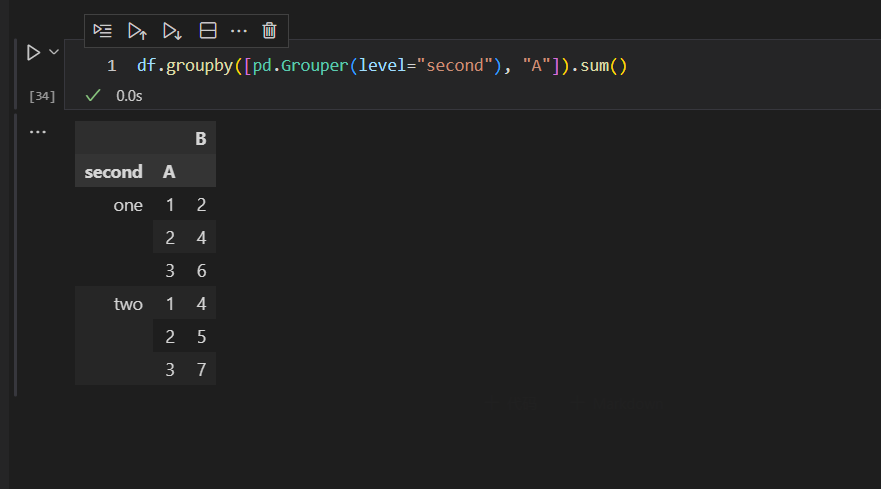
这里要注意,主键的数据标签列,是用level属性来定义,普通列,则是通过双引号来定义。
如果嫌麻烦的话,则可以通过一个列表来定义需要参与分组的组合列。
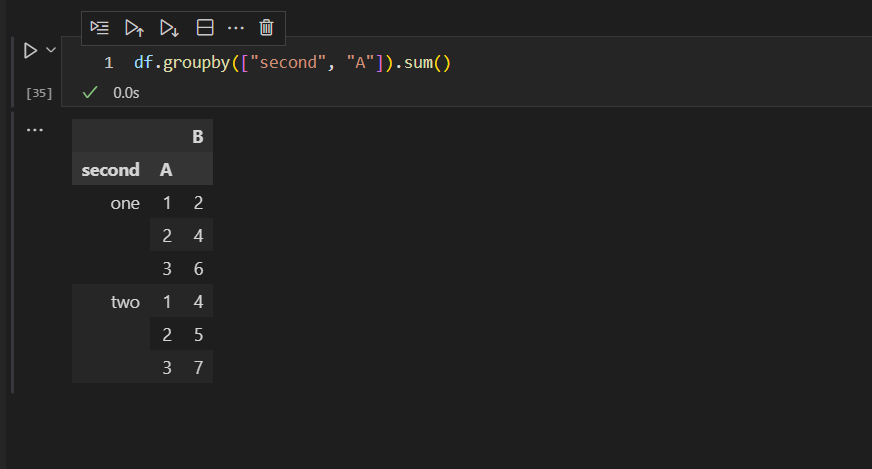
上面三种方式,大家可以在实践中,灵活选择一种就行。
以上就是我们的第一部分内容,下一篇文章,我们继续讲解第二部分内容。








![鸢尾花书实践和知识记录[数学要素3-1万物皆数]](https://i-blog.csdnimg.cn/direct/f7ca3cfc6444481a890ec05bf174c77a.png)