Hash表查找的本质就是:在创建记录表的时候,确定记录的key与其存储地址之间的关系f,当要查找key=k的记录时,通过关系 f 就可得到相应记录的地址而获取记录,从而免去了key的比较过程

我们把这个关系 f 称为Hash 函数(或者散列函数),记为 H(key)。
目录
1、构造Hash函数的方法
(1) 保留除数法
(2) p 是一个质数的原因
2、如何选取合适的p值(如何选择Hash表的长度)
3、处理冲突的方法
(1) 开放地址法
(2) 链式存储法
1、构造Hash函数的方法
构造Hash函数的方法有很多,原则上都是尽可能将这些记录均匀分布,尽量减少冲突现象的发生。(冲突现象指的是 经过Hash函数计算得到的一个地址,但是该地址已经存了其他内容),下面是几种常用的构造方法。
- 直接地址法
- 平方取中法
- 叠加法
- 保留除数法
- 随机函数法
下面将重点了解保留除数法。
(1) 保留除数法
保留除数法,又叫做质数除余法,假设一个Hash表的长度为m,选取一个不大于 m 的最大质数p,令
H(key) = key % p
这是 key 和 H(key)最基本的关系,但是p为什么要特地选择一个质数呢?
(2) p 是一个质数的原因
假设现在有这么一组 key值的集合,key:28 35 63 77 105
=》若 p 不是一个质数,假设p = 21 = 3*7,则
H(key) = key % 21: 7 14 0 14 0
key = 35、77对应的地址都是 14,说明key = 35、77都打算存到第 14 个位置上,很显然冲突了,这是因为 p 包含了质数因子 7,key=35、77 也包含了7,两者大概率会被映射到相同单元。
=》若 p 不是一个质数,假设p = 19,则
H(key) = key % 19: 9 16 6 1 10
现在的话,H(key) 的地址分布就好很多了。
2、如何选取合适的p值(如何选择Hash表的长度)
p 是一个不大于 m 的最大质数,其中 m 是Hash表的长度。选择 p 值本质上就是选择Hash表的长度。为了让表保持一定的空闲余量来缓解冲突,一般满足下面的条件:
α = n / m
- α 是表的装填因子,一般在 0.7 ~ 0.8 之间;
- n 是表中允许存放的记录个数
- m 是Hash表的长度
假设α = 0.75,我们打算在表中存放 75个记录,此时的表长m = 75/0.75 = 100,p是一个不大于m的最大质数,因此 p = 97。
3、处理冲突的方法
从最开始的例子可以发现,两个不一样的key值,经过Hash函数计算得到的结果是一样的,也就是说,有两个key值要存放到同一个位置,这就是所谓的“冲突”。选择 p 为质数只是为了缓解冲突,但是不能避免小概率冲突的发生,处理冲突的方法主要介绍两种:
- 开放地址法:如果某个位置已经放了其他数据,那就在该位置的前后找一个空闲位置来存放

- 链式存储法:相互冲突的记录拉成一个链表,记录表里存放链第一个结点的地址。

(1) 开放地址法
开放地址法的基本思路:在原本 H(key) 的基础上获取下一个地址,使用的公式如下
Hi = ( H(key) + i ) % m,i = 1,2,3...
H(key) + i 其实就在 H(key) 后面第 i 个位置的下标,模 m的目的是保证取到的地址在 0 ~ m-1之间
现在 H(key) 的位置已经放了一个数据,但是又有其他数据要放在这个位置,于是向后探索,H(key) + 1 的位置也有其他数据了,继续向后探索,发现H(key) + 2 的位置没有放数据,此时就把数据放在这个位置。
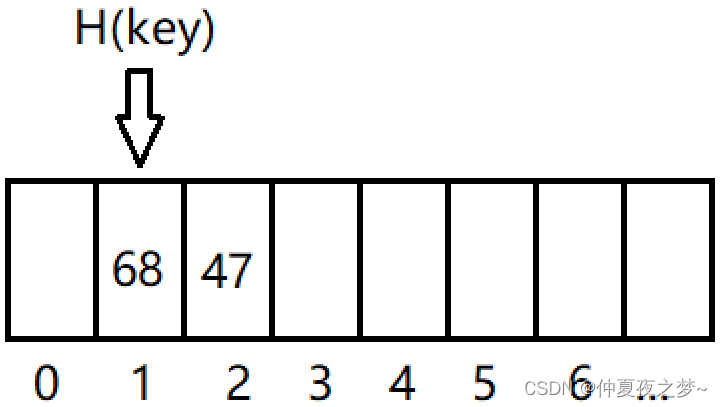
缺点:虽然解决了冲突,但是如果寻找新位置的时候,一直找不到合适的,最坏的情况是找不到新位置,这种情况称为“积聚”,严重影响了Hash表的查找效率。
(2) 链式存储法
发生冲突时,将各冲突记录链在一起,即Hash函数计算结果相同的key值存于同一链表。H(key)对应的 HPi 存放的是第一个结点的地址,如果没有结点,那就为空。
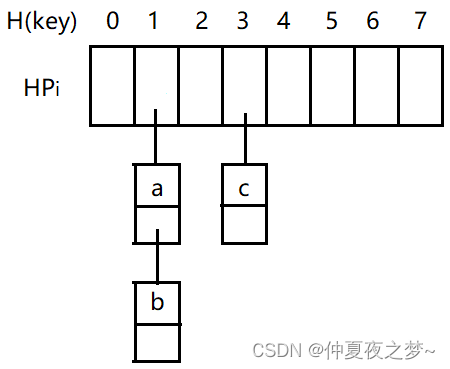
优点:无聚积现象;删除表中记录容易实现


![[一篇读懂]C语言九讲:线性表应用](https://img-blog.csdnimg.cn/0f1ccad3966d4d979c2d23b88b57256e.png#pic_center)

![[附源码]java毕业设计网络学习平台](https://img-blog.csdnimg.cn/82b4474d2d1d412b81f592f72cda1f9b.png)