本来没有架构,写的组件多了,就有了架构。
前言
早期,我为了抓取mp3和一些网站文章,随意写了些零零星星的代码。后来,使用了scrapy和webmagic等爬虫框架,算是走上了正轨。又后来,东一个组件,西一个库,东拼西凑,软件又慢慢脱离正轨。到了现在,终于活成了自己的模样,变成了四不像。
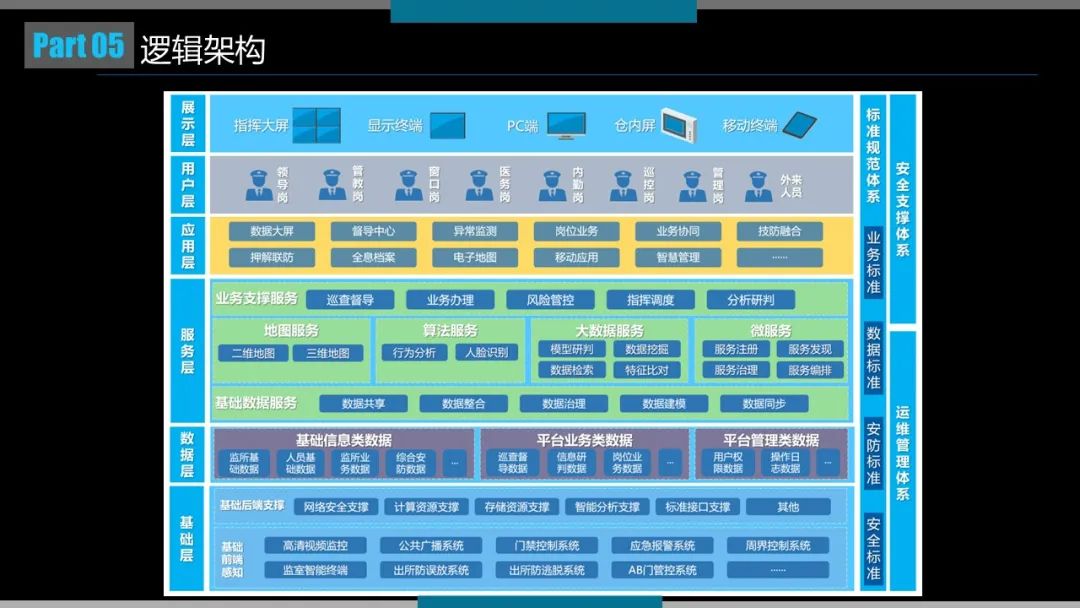
整体架构

基本逻辑如下:
- 通过web端管理爬虫平台,通过手机做一些内容管理,搜索
- API网关统一接收请求,然后扔到消息队列
- robot server接收到消息后,远程调用chrome,打开相应页面
- chrome中内容被mitmproxy截获,mitmproxy再交给一个个Processor处理
- Processor获得匹配到的内容,完成入库