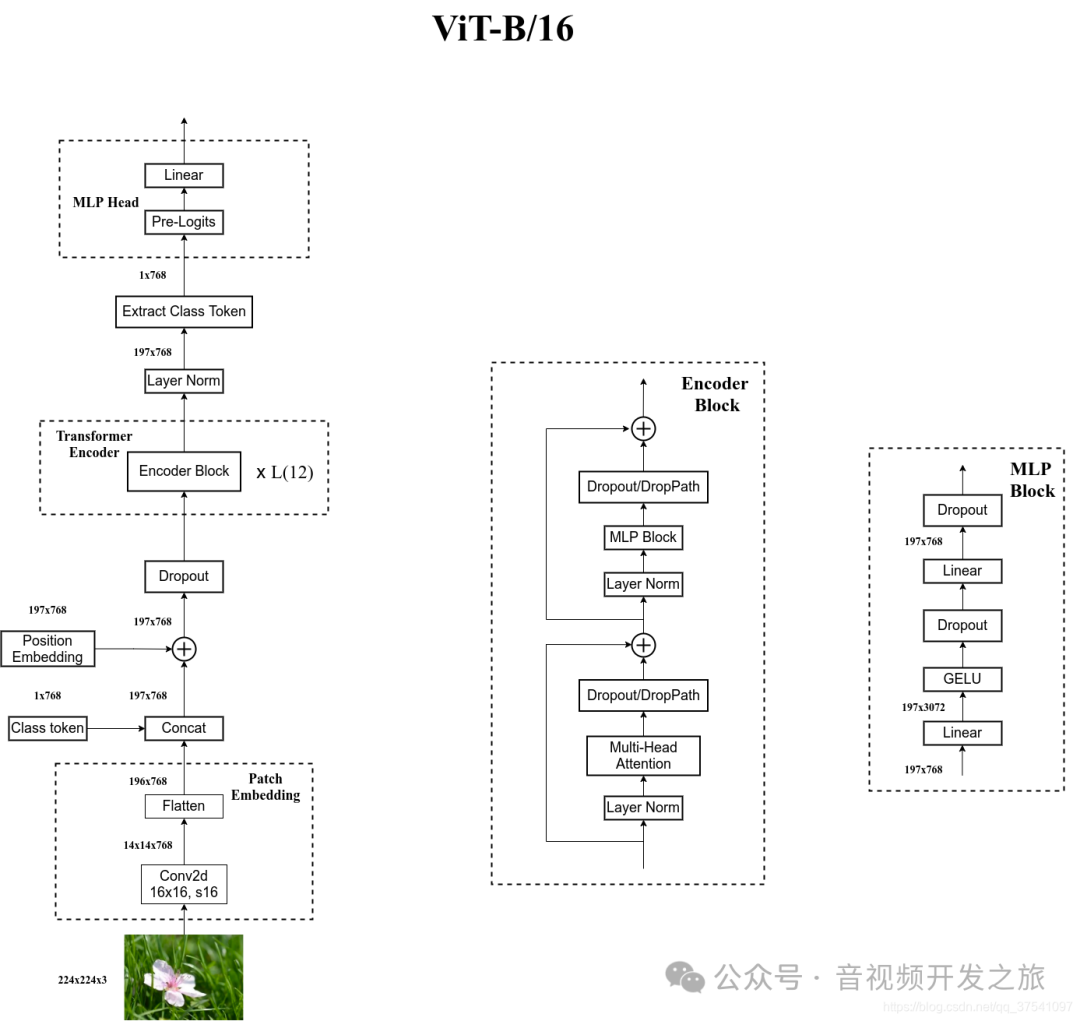
目录
Producer
Broker
Consumer
为什么Kafka没办法100%保证消息不丢失呢?
生产者
消费者
Broker
Kafka作为一个消息中间件,他需要结合消息生产者和消费者一起才能工作,一次消息发送包含以下是三个过程:
1)Producer端发送消息给Kafka Broker。
2)Kafka Broker将消息进行同步并持久化数据。
3)Consumer端从Kafka Broker将消息拉取并进行消费。
Kafka只对已提交的消息做最大限度的持久化保证不丢失,但是没办法保证100%。
为啥没办法保证100%呢?后面再说...
但是,Kafka还是提供了很多机制来保证消息不丢失的。要想知道Kafka如何保证消息不丢失,需要从生产者、消费者以及Kafka集群三个方面来分析。

Producer
消息的生产者端,最怕的就是消息发送给Kafka集群的过程中失败,所以,我们需要有机制来确保消息能够发送成功,但是,因为存在网络问题,所以基本没有什么办法可以保证一次消息一定能成功。
所以,就需要有一个确认机制来告诉生产者这个消息是否有发送成功,如果没成功,需要重新发送直到成功。
我们通常使用Kafka发送消息的时候,通常使用的 producer.send(msg) 其实是一种异步发送,发送消息的时候,方法会立即返回,但是并不代表消息一定能发送成功。(producer.send(msg).get() 是同步等待返回的。)
那么,为了保证消息不丢失,通常会建议使用 producer.send(msg, callback) 方法,这个方法支持传入一个callback,我们可以在消息发送时进行重试。
同时,我们也可以通过设置一些参数来提升发送成功率:
acks=-1 // 表示 Leader 和 Follower 都接收成功时确认;可以最大限度保证消息不丢失,但是吞吐量低。
retries=3 // 生产端的重试次数
retry.backoff.ms = 300 //消息发送超时或失败后,间隔的重试时间acks = 0: 表示Producer请求立即返回,不需要等待Leader的任何确认。这种方案有最高的吞吐率,但是不保证消息消息是否真的发送成功。
acks = -1: 表示分区Leader必须等待消息被成功写入到所有的ISR副本(同步副本)中才认为Producer请求成功。这种方案提供最高的消息持久性保证,但是理论上吞吐率也是最差的。
acks = 1: 表示Leader副本必须应答Producer请求并写入消息到本地日志,之后Producer请求被认为成功。如果此时Leader副本应答请求之后挂掉了,消息会丢失。这个方案,提供了不错的持久性保证和吞吐。
Broker
Kafka的集群有一些机制来保证消息的不丢失,比如复制机制、持久化存储机制以及ISR机制。
-
持久化存储:Kafka使用持久化存储来存储消息。这意味着消息在写入Kafka时将被写入磁盘,这种方式可以防止消息因为节点宕机而丢失。
-
ISR复制机制:Kafka使用ISR机制来确保消息不会丢失,Kafka使用复制机制来保证数据的可靠性。每个分区都有多个副本,副本可以分布在不同的节点上。当一个节点宕机时,其他节点上的副本仍然可以提供服务,保证消息不丢失。
Consumer
作为Kafka的消费者端,只需要确保投递过来的消息能正常消费,并且不会胡乱的提交偏移量就行了。
Kafka消费者会跟踪每个分区的偏移量,消费者每次消费消息时,都会将偏移量向后移动。当消费者宕机或者不可用时,Kafka会将该消费者所消费的分区的偏移量保存下来,下次该消费者重新启动时,可以从上一次的偏移量开始消费消息。
另外,Kafka消费者还可以组成消费者组,每个消费者组可以同时消费多个分区。当一个消费者组中的消费者宕机或者不可用时,其他消费者仍然可以消费该组的分区,保证消息不丢失。
为了保证消息不丢失,建议使用手动提交偏移量的方式,避免拉取了消息以后,业务逻辑没处理完,提交偏移量后但是消费者挂掉的问题:
enable.auto.commit=false
为什么Kafka没办法100%保证消息不丢失呢?
Kafka提供的Producer和Consumer之间的消息传递保证语义有三种,所谓消息传递语义,其实就是Kafka的消息交付可靠保障,主要有以下三种:
- At most once—消息可能会丢,但绝不会重复传递;
- At least once—消息绝不会丢,但可能会重复传递;
- Exactly once—每条消息只会被精确地传递一次,既不会多,也不会少;
目前,Kafka默认提供的交付可靠性保障是第二种,即At least once,但是,其实依靠Kafka自身,是没有办法100%保证可靠性的。
我们来整体分析下。
生产者
Kafka允许生产者以异步方式发送消息,这意味着生产者在发送消息后不会等待确认。当然,我们可以注册一个回调等待消息的成功回调。
但是,如果生产者在发送消息之后,Kafka的集群发生故障或崩溃,而消息尚未被完全写入Kafka的日志中,那么这些消息可能会丢失。虽然后续有可能会重试,但是,如果重试也失败了呢?如果这个过程中刚好生产者也崩溃了呢?那就可能会导致没有人知道这个消息失败了,就导致不会重试了。
消费者
消费者来说比较简单,只要保证在消息成功时,才提交偏移量就行了,这样就不会导致消息丢失了。
Broker
Kafka使用日志来做消息的持久化的,日志文件是存储在磁盘之上的,但是如果Broker在消息尚未完全写入日志之前崩溃,那么这些消息就可能会丢失了。
而且,操作系统在写磁盘之前,会先把数据写入Page Cache中,然后再由操作系统自己决定什么时候同步到磁盘当中,而在这个过程,如果还没有写及同步到磁盘中,就崩掉了,那么消息也就丢了。
当然,也可以通过配置log.flush.interval.messages=1,来实现类似于同步刷盘的功能,但是又回到了前面说的情况,还没来得及做持久化,就宕机了。
即使Kafka中引入了副本机制来提升消息的可靠性,但是如果发生同步延迟,还没来及同步,主副本就挂掉了,那么消息就可能会发生丢失。
这种情况下,只从Broker的角度分析,Broker自身是没办法保证消息不丢失的,但是只要Combine Producer,再配合request.required.acks=-1这种ACK策略,可以确保消息持久化成功之后,才会ACK给Producer,那么,如果我们的Producer在一定时间内,没有收到ACK,是可以重新发送的。
但是,这种重新发送,就又回到了我们前面介绍生产者的时候的问题,生产者也有可能挂掉,重新发送也有可能没发送接收到,导致消息最终丢失。
所以,我们说,只靠Kafka自身,其实是没有办法保证极端情况下的消息100%不丢失的。
但是,我们也可以在做一些机制来保证,比如引入分布式事务,或者引入本地消息表等,保证在Kafka Broker没有保存消息成功时,可以重新投递消息。这样才行。