目录
1.背景和问题
2.Vision Transformer(VIT)模型结构
3.Patch Embedding
4.实现效果
5.代码解析
6.资料
一、背景和问题
上一篇我们学习了Transformer的原理,主要介绍了在NLP领域上的应用,那么在CV(图像视频)领域该如何使用?
最直观的想法就是把每一个像素像NLP中一个文字一样处理,理论上可行,但是这样做有什么不足吗?
Transformer的自注意力机制的计算复杂度是O(n^2),其中n是序列长度,一张720*1280的图片就需要921600个token,这将导致巨大的计算开销,使得模型的训练和推理非常缓慢。图像不同像素之间存在很多冗余信息(编码时会进行帧内压缩),是否可以采用类似编码压缩技术中的宏块方案呐(把图像分割为固定大小的16x16、8x8、4x4的的块)。
二、VIT模型结构
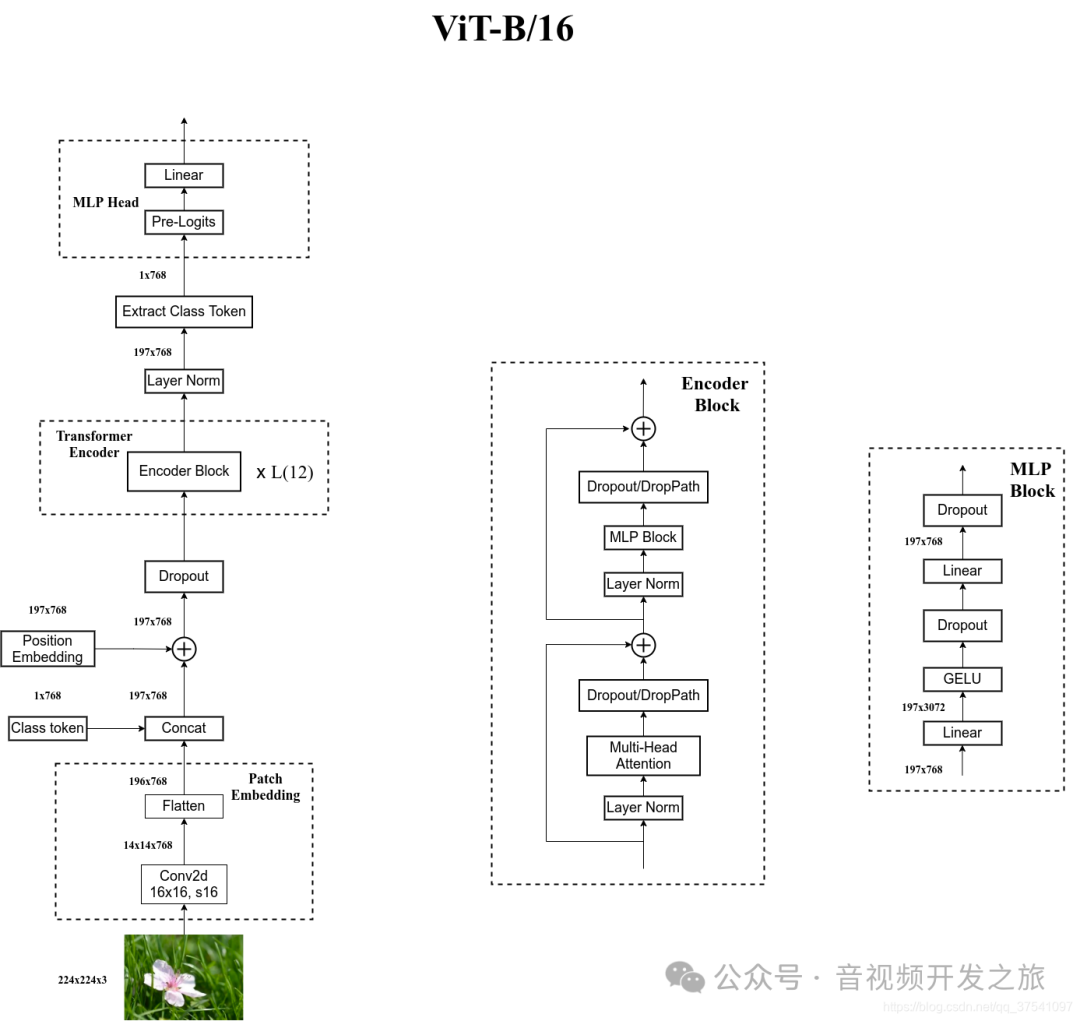
VIT的思路和视频编码的宏块思想类似,把图像分割为固定大小pathchs,然后通过线性变换得到patch embedding,将图像的patch embeddings送入transformer的Encoder进行特征提取,在根据不同任务添加不同的Head。ViT模型原理如下图所示:
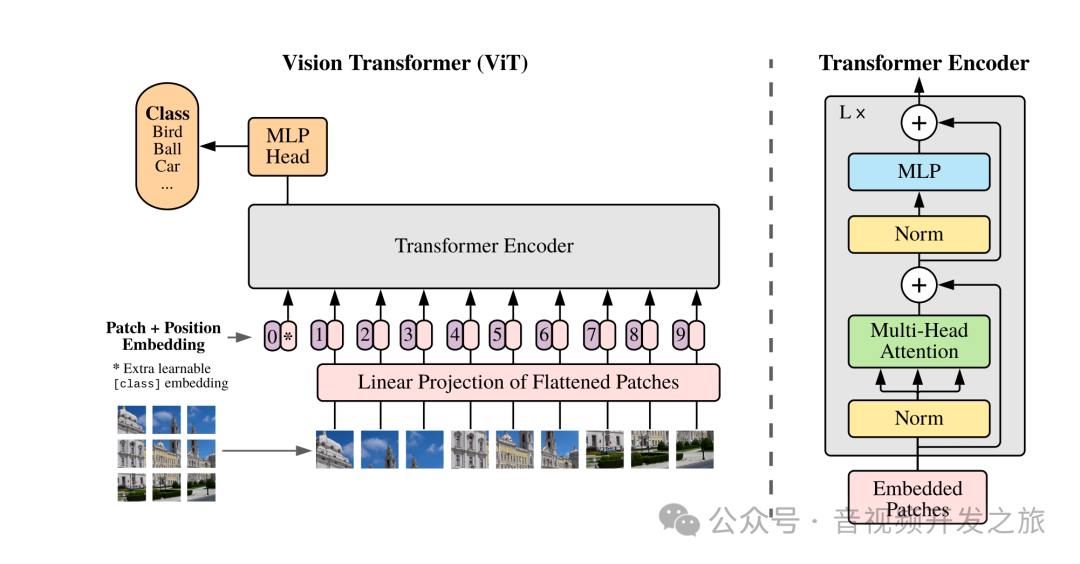
模型由三个模块组成:
-
Linear Projection of Flattened Patches(该网络的前处理,把图像分割为patch,然后进行Embedding)
-
Transformer Encoder(该网络的backbone,用于特征提取)
-
MLP Head(该网络的head,用于分类任务)
主要的公式如下:
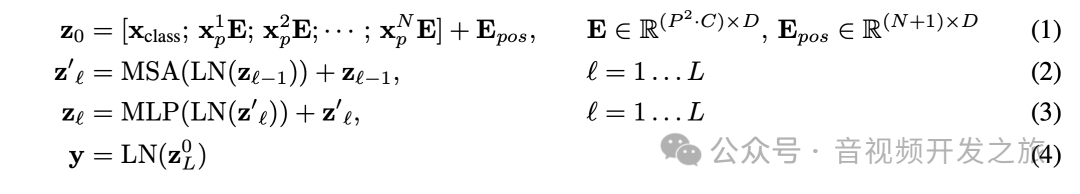

可以看到VIT只用到了Transfomer的Encoder作为backbone进行特征提取,TransfomerEncoderLayer也是使用Multi-head Attention,不同的是LayerNormalation放在了Multi-head Attention的前面。和Transfromer的结构主要区别在于Embedding的过程,如果对于注意力机制还不太清楚,建议复习下上一篇。
三、Patch Embedding
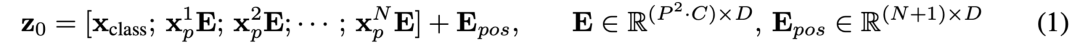
关键点包括:
-
图像被分割成固定大小的patches。
-
每个patch通过线性投影映射到嵌入空间。
-
添加一个特殊的分类token。
-
加入位置编码以保留空间信息。
将2D图像转换为一个1D序列,使得标准Transformer架构可以直接处理图像数据,允许ViT像处理文本序列一样处理图像,充分利用了Transformer的自注意力机制来捕捉图像中的全局依赖关系。
下面我们用一个示例来说明PatchEmbedding的过程。
输入一张:256x256的rgb图像,然后把它分割为64个32x32的patchs,对patchs进行线性投影得到序列长度为64,dim为1024的Embedding,然后加上用于分类的可训练的classToken(随机初始化),最后在加上相同形状的PosEmbedding 作为TransformEncodeer的输入。
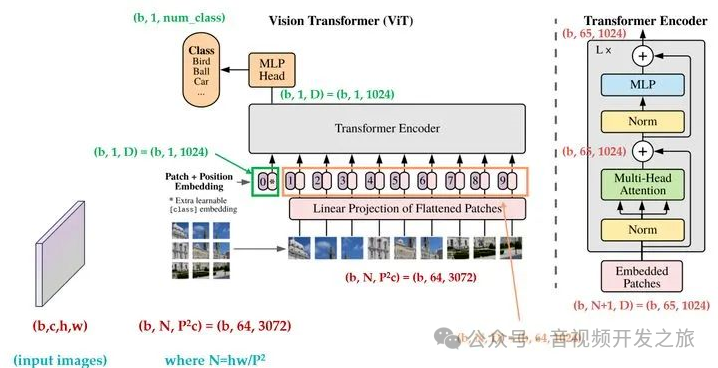
图片来自:详解 Vision Transformer

不同于Transfromer的PositionEmbedding(采用sin和cos固定编码),VIT中的PositionEmbedding采用了符合正态分布随机初始化,可训练的方案(bert也采用了类似方式)
论文中对学习到的positional embedding进行了可视化,发现相近的patchs的positional embedding比较相似,而且同行或同列的positional embedding也相近:
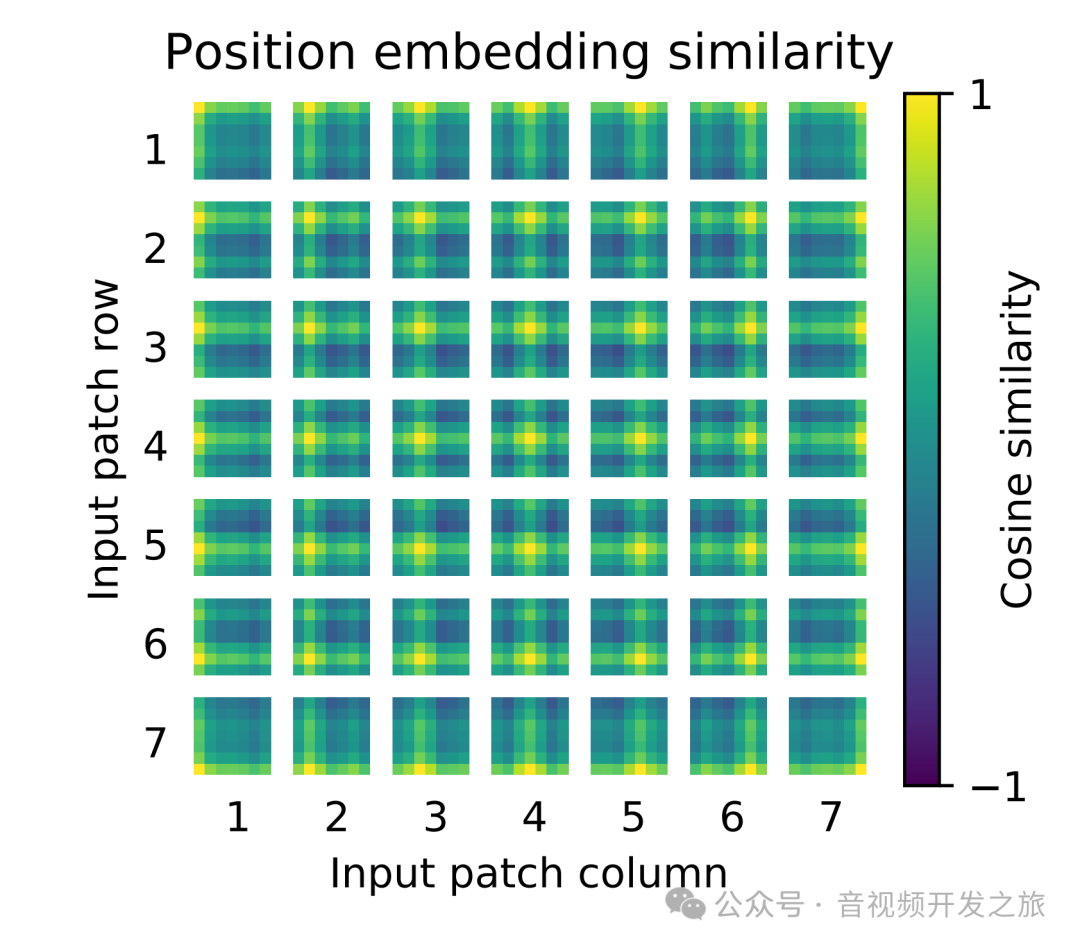
需要注意的是:如果改变图像的输入大小,ViT不会改变patchs的大小,patchs的数量会发生变化,之前学习的pos_embed就维度对不上了,通常ViT采用插值的方式来解决这个问题,但效果不好,另外一篇论文给出了说明和解决措施 https://arxiv.org/pdf/2102.10882,有兴趣可以进一步研究下。
四、实验效果
ViT的训练策略:先在大数据集上做预训练,然后在小数据集上做迁移使用。
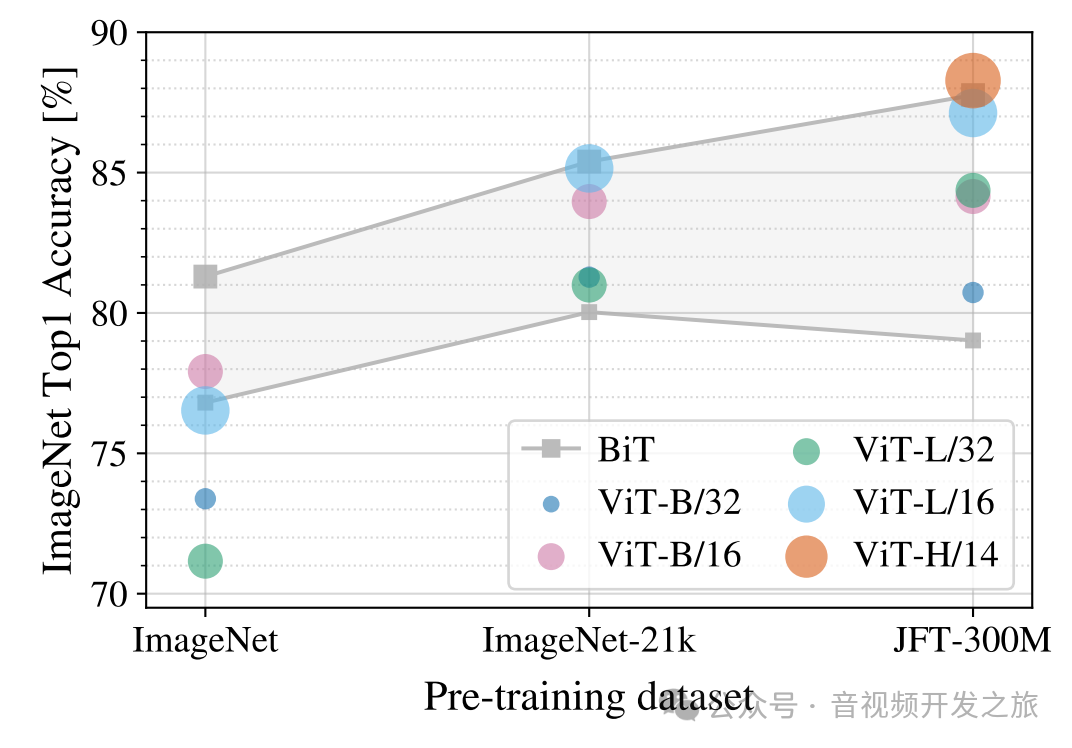
如果在小数据集ImageNet上做预训练时,VIT的模型架构效果普遍低于ResNet搭建的BiT网络;当在中等数据集ImageNet-21k上做预训练时,VIT的模型架构基本位于BiT最好和最差的之间;而当在大数据集JFT-300M上做预训练时,VIT的模型架构最好的效果已经超过了BiT。
结论:VIT模型需要在大数据集上进行预训练,在大数据集上预训练的效果会比卷积神经网络的上限高
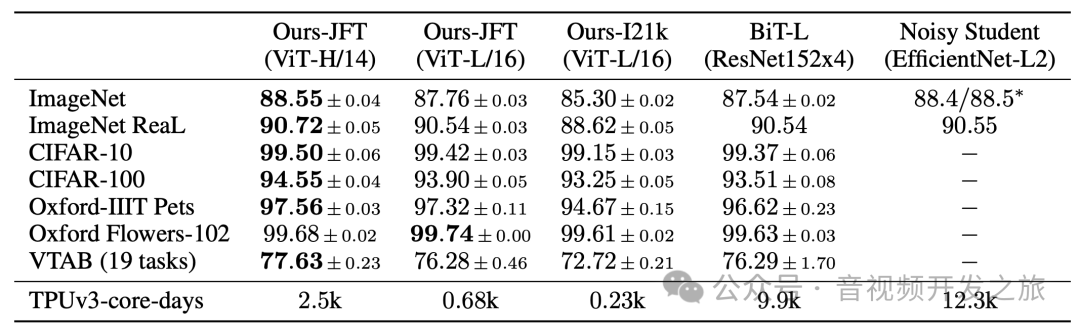
例如下图先在有3亿张图像的JFT大数据集上预训练,然后在ImageNet上进行微调,准确率达到88.55%
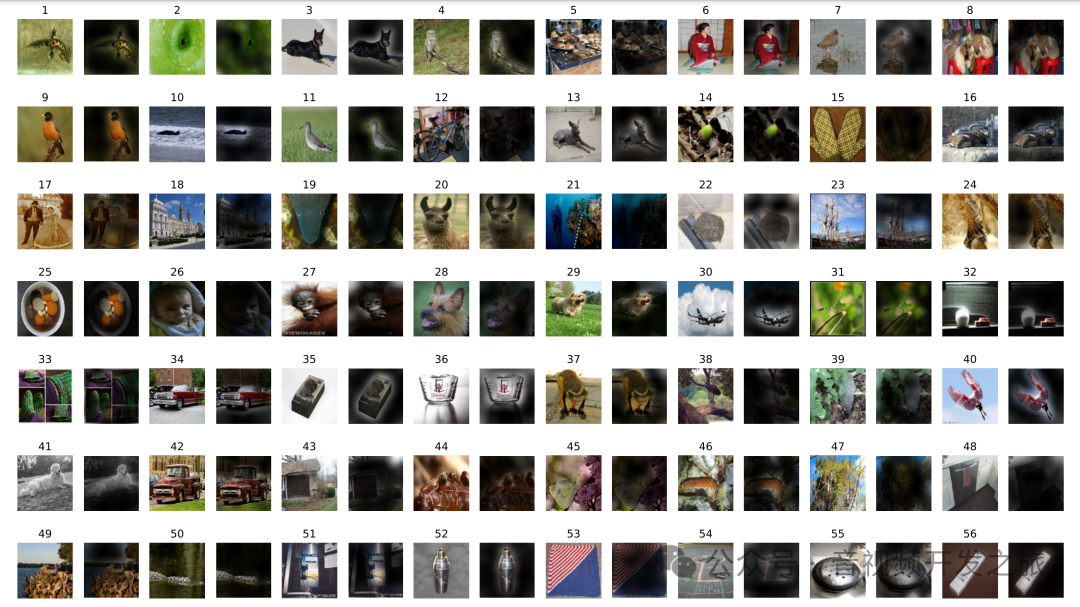
ViT 还可根据 Attention Map 来可视化,得知模型具体关注图像的哪个部分,
五、代码解析
源码地址:https://github.com/lucidrains/vit-pytorch
图片来自:Vision Transformer详解
3.1、调用
import torchfrom vit_pytorch import ViTdef test():#VIT的具体实现在vit.py中v = ViT(#原始图像尺寸image_size = 256,#切割的每个图像块的尺寸patch_size = 32,#类别数量num_classes = 1000,#Transformer隐变量维度大小dim = 1024,#Transformer Encoder层的个数depth = 6,#Multi-Head Attention 头的个数heads = 16,#mlp层 hid层的维度mlp_dim = 2048,dropout = 0.1,emb_dropout = 0.1)img = torch.randn(1, 3, 256, 256)preds = v(img)
3.2、Attention和FFN的实现
# helpers#确保t为元组def pair(t):return t if isinstance(t, tuple) else (t, t)# classes#前馈网络class FeedForward(nn.Module):def __init__(self, dim, hidden_dim, dropout = 0.):super().__init__()self.net = nn.Sequential(nn.LayerNorm(dim),nn.Linear(dim, hidden_dim),nn.GELU(),nn.Dropout(dropout),nn.Linear(hidden_dim, dim),nn.Dropout(dropout))def forward(self, x):return self.net(x)#VIT中的self-Attention实现,这里也是多头注意力机制class Attention(nn.Module):def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):super().__init__()inner_dim = dim_head * heads #多头的个数heads:16 * 每个头的维度:64 =1024project_out = not (heads == 1 and dim_head == dim)self.heads = headsself.scale = dim_head ** -0.5 # dim_head =64, scale=1/8self.norm = nn.LayerNorm(dim)self.attend = nn.Softmax(dim = -1)self.dropout = nn.Dropout(dropout)#to_qkv线性变化,将输入映射到一个三维空间,以便在多头注意力机制中生成QKV 输入特征维度为dim (1024),输出维度为inner_dim*3 (1024*3)self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False) #dim:1024,inner_dim:1024self.to_out = nn.Sequential(nn.Linear(inner_dim, dim),nn.Dropout(dropout)) if project_out else nn.Identity()def forward(self, x):x = self.norm(x)#将输入数据x映射到三维空间,x.shape为[1,65,1024],to_qkv经过线性变换后输出维度为[1,65,1024*3]; chunk(3,-1)将最后一个维度分割为3个子张量,生成qkv元组qkv = self.to_qkv(x).chunk(3, dim = -1)q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv) #进行形状转换,生成[batchsize,heads,squcelen,dim] 值为[1,16,65,64]#经典的attention计算, 把q和K的转置相乘除以缩放系数,得到相似性系数dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale#沿最后一维度进行softmax归一化attn = self.attend(dots)attn = self.dropout(attn)#attn[1, 16, 65, 65]点乘V [1, 16, 65, 64]输出[1, 16, 65, 64]out = torch.matmul(attn, v)out = rearrange(out, 'b h n d -> b n (h d)') #对多头进行concate,得到[1, 65, 1024]return self.to_out(out)
3.3、Transfromer Encoder层的实现
#VIT中Transfromer的实现,用到了Transformer的Encoder层. 和原始的Transfromer稍微有些差异,主要是layernormalization的位置class Transformer(nn.Module):def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):#dim:1024,depth:6;heads:16;dim_head:64;mlp_dim:2048;dropout:0.1super().__init__()self.norm = nn.LayerNorm(dim)self.layers = nn.ModuleList([])for _ in range(depth):self.layers.append(nn.ModuleList([Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout),FeedForward(dim, mlp_dim, dropout = dropout)]))def forward(self, x):for attn, ff in self.layers:x = attn(x) + x #Attention进行残差x = ff(x) + x #MLP进行残差return self.norm(x)
3.4、ViT的实现
#入口Module,这里的posEmbedding没有使用固定编码,而是像bert一样可训练的. 把image切分成多个patch,展平进行to_patch_embedding处理class ViT(nn.Module):def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):super().__init__()image_height, image_width = pair(image_size)patch_height, patch_width = pair(patch_size)assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'# num_patches =(256//32)*(256//32)=64; patch_dim:3*32*32=3072; dim=1024num_patches = (image_height // patch_height) * (image_width // patch_width)patch_dim = channels * patch_height * patch_widthassert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'#使用einops的Rearrange优雅地处理张量维度self.to_patch_embedding = nn.Sequential(Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),#这里(h p1) (w p2)就相当于h与w变为原来的1/p1,1/p2nn.LayerNorm(patch_dim),nn.Linear(patch_dim, dim),#patch_dim3072,dim 1024 线性变换nn.LayerNorm(dim),)self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim)) # 创建一个形状为 (1, 65, 1024) 的随机张量,VIT中PE和Transformer中positionEmbedding的定义不同,这里是一个可以训练的模块self.cls_token = nn.Parameter(torch.randn(1, 1, dim))#创建一个随机的张量(1,1,1024)的cls_tokenself.dropout = nn.Dropout(emb_dropout)self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)self.pool = poolself.to_latent = nn.Identity()self.mlp_head = nn.Linear(dim, num_classes)def forward(self, img):x = self.to_patch_embedding(img)b, n, _ = x.shapecls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)x = torch.cat((cls_tokens, x), dim=1)x += self.pos_embedding[:, :(n + 1)]x = self.dropout(x)#输入和输出的形状都是 torch.Size([1, 65, 1024])x = self.transformer(x)#这里的pool为cls分类,所以沿dim=1,取第1个数据x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]#这里的to_latent目前就是一个恒等变换层nn.Identity(),即输入和输出每个任何变化,可以去掉,这里起到占位的作用x = self.to_latent(x)return self.mlp_head(x)
六、资料
1.论文VIT:https://arxiv.org/pdf/2010.11929
2.源码:https://github.com/lucidrains/vit-pytorch
3.timm/models/vision_transformer.py: https://github.com/huggingface/pytorch-image-4.models/blob/main/timm/models/vision_transformer.py
5.ViT论文逐段精读【论文精读】https://www.bilibili.com/video/BV15P4y137jb
6.Vision Transformer(vit)网络详解 https://www.bilibili.com/video/BV1Jh411Y7WQ
7.李宏毅-Transformer
https://www.bilibili.com/video/av56239558
8.详解VisionTransformer
https://blog.csdn.net/qq_39478403/article/details/118704747
9.Vision Transformer详解 https://blog.csdn.net/qq_37541097/article/details/118242600
10.ViT代码超详细解读 https://blog.csdn.net/weixin_43334693/article/details/131836233
11.ViT PyTorch代码全解析(附图解)
https://blog.csdn.net/weixin_44966641/article/details/118733341
12.Vision Transformer(VIT)代码分析 https://blog.csdn.net/qq_38683460/article/details/127346916
13.ViT:视觉Transformer backbone网络ViT论文与代码详解 https://mp.weixin.qq.com/s/Nok5UQ2nzex94GXyrltiBg
14.可视化VIT中的注意力 https://mp.weixin.qq.com/s/O-56hxVa6Fgiz2YpjXTodQ
15."未来"的经典之作 ViT:transformer is all you need! https://www.cvmart.net/community/detail/4461
16.搞懂 Vision Transformer 原理和代码 https://mp.weixin.qq.com/s/ozUHHGMqIC0-FRWoNGhVYQ
17.3W字长文带你轻松入门视觉transformer https://zhuanlan.zhihu.com/p/308301901
18.Vision Transformer, LLM, Diffusion Model 超详细解读 (原理分析+代码解读) https://zhuanlan.zhihu.com/p/348593638
19.einops.repeat, rearrange, reduce优雅地处理张量维度 https://blog.csdn.net/qq_37297763/article/details/120348764
感谢你的阅读
接下来我们继续学习输出AI相关内容,欢迎关注公众号“音视频开发之旅”,一起学习成长。
欢迎交流














![[知识分享]华为铁三角工作法](https://img-blog.csdnimg.cn/img_convert/dc1000105906abf8f24e79a8ced414ec.png)

