💖🔥作者主页:毕设木哥
精彩专栏推荐订阅:在 下方专栏👇🏻👇🏻👇🏻👇🏻实战项目
文章目录
- 实战项目
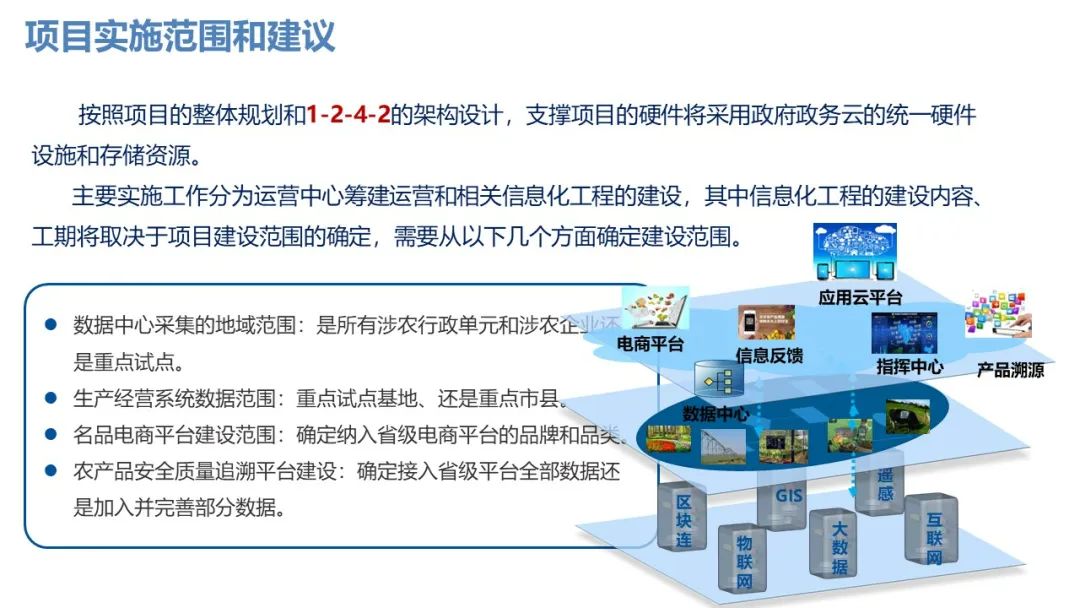
- 一、基于python的电子图书馆数据可视化分析-项目介绍
- 二、基于python的电子图书馆数据可视化分析-视频展示
- 三、基于python的电子图书馆数据可视化分析-开发环境
- 四、基于python的电子图书馆数据可视化分析-项目展示
- 五、基于python的电子图书馆数据可视化分析-代码展示
- 六、基于python的电子图书馆数据可视化分析-项目文档展示
- 七、基于python的电子图书馆数据可视化分析-项目总结
- </font > <font color=#fe2c24 >大家点赞、收藏、关注、有问题都可留言交流👇🏻👇🏻👇🏻
一、基于python的电子图书馆数据可视化分析-项目介绍
在数字化时代,信息的获取和处理变得尤为重要。电子图书馆作为知识信息的重要载体,其数据量庞大且更新迅速,涵盖了丰富的文献资源和用户行为数据。随着大数据技术的发展,如何有效管理和分析这些数据,以提供更加精准的信息服务,成为了一个迫切需要解决的问题。基于Python的电子图书馆数据可视化分析,正是在这样的背景下应运而生。Python作为一种强大的编程语言,以其丰富的数据处理库和灵活的可视化工具,为电子图书馆的数据管理提供了新的可能性。本课题旨在通过Python技术,实现电子图书馆数据的高效处理与可视化展示,以提升信息检索的效率和用户体验,这对于促进知识的传播和利用具有重要的现实意义。
尽管现有的电子图书馆系统在数据存储和检索方面取得了一定的进展,但在数据的深入分析和可视化展示方面仍存在不足。许多系统缺乏有效的数据挖掘和分析工具,难以从海量数据中提取有价值的信息。此外,现有的数据可视化方法往往过于复杂,不易于用户理解和操作,这限制了用户对数据的深入探索和知识的获取。这些问题不仅影响了电子图书馆服务的质量和效率,也制约了用户对资源的充分利用。因此,开发一种基于Python的电子图书馆数据可视化分析工具,以解决现有系统的局限性,显得尤为必要。
本课题的研究目的在于开发一套基于Python的电子图书馆数据可视化分析系统,该系统能够实现数据的自动化处理、智能分析和直观展示。通过该系统,用户可以快速获取所需信息,同时系统管理员也能够更好地监控和优化图书馆资源的使用情况。课题的研究将围绕以下几个方面展开:首先是数据预处理和清洗,确保数据的质量和可用性;其次是数据挖掘和分析,提取有价值的信息和知识;最后是数据可视化,通过图形化的方式展示分析结果,提高信息的可理解性和吸引力。通过本课题的研究,不仅能够提升电子图书馆的服务水平,还能够推动图书馆信息化建设的进程,对于促进知识资源的共享和利用具有重要的理论和实践价值。
二、基于python的电子图书馆数据可视化分析-视频展示
计算机毕业设计推荐-基于python的电子图书馆数据可视化分析
三、基于python的电子图书馆数据可视化分析-开发环境
- 开发语言:Python
- 数据库:MySQL
- 系统架构:B/S
- 后端:Django
- 前端:vue
- 工具:PyCharm
四、基于python的电子图书馆数据可视化分析-项目展示
登录模块:

首页模块:



管理模块:



五、基于python的电子图书馆数据可视化分析-代码展示
from django.shortcuts import render, get_object_or_404
from django.http import HttpResponse, HttpResponseRedirect
from .models import Book # 假设我们有一个Book模型来存储书籍信息
def book_list(request):
# 获取所有书籍的列表
books = Book.objects.all()
return render(request, 'library/book_list.html', {'books': books})
def book_detail(request, book_id):
# 根据书籍ID获取书籍详情
book = get_object_or_404(Book, pk=book_id)
return render(request, 'library/book_detail.html', {'book': book})
def search_books(request):
# 处理书籍搜索请求
query = request.GET.get('q', '')
if query:
books = Book.objects.filter(title__icontains=query) # 假设我们根据书名搜索
return render(request, 'library/search_results.html', {'books': books, 'query': query})
else:
return HttpResponseRedirect('/book_list/') # 如果没有搜索词,重定向到书籍列表页面
def add_book(request):
# 处理添加书籍的请求
if request.method == 'POST':
# 这里可以添加表单验证和书籍数据的保存逻辑
form = BookForm(request.POST)
if form.is_valid():
form.save()
return HttpResponseRedirect('/book_list/')
else:
form = BookForm()
return render(request, 'library/add_book.html', {'form': form})
六、基于python的电子图书馆数据可视化分析-项目文档展示

七、基于python的电子图书馆数据可视化分析-项目总结
本课题通过开发基于Python的电子图书馆数据可视化分析系统,成功地解决了电子图书馆在数据管理和用户服务方面的一系列问题。研究结果表明,利用Python的数据处理和可视化库,能够有效地对电子图书馆的海量数据进行清洗、挖掘和直观展示,从而提高了信息检索的效率和用户体验。这一研究不仅在理论上验证了Python在数据可视化领域的应用潜力,而且在实际应用中也展现了其强大的数据处理能力。开发思想上,本课题强调了用户友好性和系统可扩展性,确保了系统的易用性和未来的升级空间。具体而言,系统通过自动化的数据预处理流程,确保了数据的准确性和一致性;通过智能分析算法,提取了用户行为和资源使用的关键指标;通过直观的可视化界面,使得复杂的数据分析结果变得易于理解和操作。
展望未来,本课题的研究工作还将继续深入。一方面,随着数据量的不断增长和用户需求的多样化,系统需要进一步优化数据处理算法,以适应更大规模的数据集和更复杂的分析需求。另一方面,系统的用户界面和交互设计也将不断改进,以提供更加个性化和智能化的服务。此外,本课题还将探索如何将机器学习和人工智能技术融入到系统中,以实现更加精准的数据分析和预测。尽管本课题在数据可视化分析方面取得了一定的成果,但仍存在一些遗留问题,如数据安全和隐私保护问题,以及如何更好地整合多源异构数据等。这些问题的解决,需要进一步的研究和实践探索,包括但不限于加强数据加密技术、完善用户隐私政策,以及开发更加高效的数据融合算法。通过这些努力,我们期待能够进一步提升电子图书馆的数据服务水平,为知识的传播和利用做出更大的贡献。