- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
前言
- 这是一篇数据分析/机器学习很好的入门案例,对糖尿病的影响进行预测和分析
- 通过随机森林预测,平均准确率和召回率都不错
- 不足:没有对特性进行特征提取,算法没有运用多个
文章目录
- 1、导入数据
- 2、数据预处理
- 3、数据分析
- 相关性分析
- 5、模型创建
- 1、数据集划分
- 2、模型的创建
- 模型预测
- 6、模型评估
- 7、特征重要性展示
- 8、总结
1、导入数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_excel('dia.xls')
data
| 卡号 | 性别 | 年龄 | 高密度脂蛋白胆固醇 | 低密度脂蛋白胆固醇 | 极低密度脂蛋白胆固醇 | 甘油三酯 | 总胆固醇 | 脉搏 | 舒张压 | 高血压史 | 尿素氮 | 尿酸 | 肌酐 | 体重检查结果 | 是否糖尿病 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 18054421 | 0 | 38 | 1.25 | 2.99 | 1.07 | 0.64 | 5.31 | 83 | 83 | 0 | 4.99 | 243.3 | 50 | 1 | 0 |
| 1 | 18054422 | 0 | 31 | 1.15 | 1.99 | 0.84 | 0.50 | 3.98 | 85 | 63 | 0 | 4.72 | 391.0 | 47 | 1 | 0 |
| 2 | 18054423 | 0 | 27 | 1.29 | 2.21 | 0.69 | 0.60 | 4.19 | 73 | 61 | 0 | 5.87 | 325.7 | 51 | 1 | 0 |
| 3 | 18054424 | 0 | 33 | 0.93 | 2.01 | 0.66 | 0.84 | 3.60 | 83 | 60 | 0 | 2.40 | 203.2 | 40 | 2 | 0 |
| 4 | 18054425 | 0 | 36 | 1.17 | 2.83 | 0.83 | 0.73 | 4.83 | 85 | 67 | 0 | 4.09 | 236.8 | 43 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1001 | 20261182 | 1 | 86 | 1.58 | 3.81 | 1.11 | 1.67 | 6.50 | 92 | 73 | 0 | 8.60 | 406.2 | 93 | 1 | 1 |
| 1002 | 20261192 | 0 | 67 | 1.48 | 4.56 | 1.31 | 2.59 | 7.35 | 76 | 86 | 0 | 4.00 | 262.5 | 59 | 3 | 1 |
| 1003 | 20261201 | 1 | 67 | 1.30 | 2.90 | 0.84 | 1.61 | 5.04 | 103 | 75 | 0 | 4.70 | 393.6 | 98 | 3 | 1 |
| 1004 | 20261213 | 0 | 46 | 1.21 | 2.31 | 0.67 | 1.34 | 4.19 | 78 | 84 | 0 | 3.80 | 219.2 | 51 | 2 | 1 |
| 1005 | 20261237 | 0 | 36 | 1.12 | 2.80 | 1.15 | 3.59 | 5.07 | 102 | 113 | 0 | 5.70 | 462.4 | 67 | 1 | 1 |
1006 rows × 16 columns
2、数据预处理
# 查看数据信息
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1006 entries, 0 to 1005
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 卡号 1006 non-null int64
1 性别 1006 non-null int64
2 年龄 1006 non-null int64
3 高密度脂蛋白胆固醇 1006 non-null float64
4 低密度脂蛋白胆固醇 1006 non-null float64
5 极低密度脂蛋白胆固醇 1006 non-null float64
6 甘油三酯 1006 non-null float64
7 总胆固醇 1006 non-null float64
8 脉搏 1006 non-null int64
9 舒张压 1006 non-null int64
10 高血压史 1006 non-null int64
11 尿素氮 1006 non-null float64
12 尿酸 1006 non-null float64
13 肌酐 1006 non-null int64
14 体重检查结果 1006 non-null int64
15 是否糖尿病 1006 non-null int64
dtypes: float64(7), int64(9)
memory usage: 125.9 KB
# 查看缺失值
data.isnull().sum()
卡号 0
性别 0
年龄 0
高密度脂蛋白胆固醇 0
低密度脂蛋白胆固醇 0
极低密度脂蛋白胆固醇 0
甘油三酯 0
总胆固醇 0
脉搏 0
舒张压 0
高血压史 0
尿素氮 0
尿酸 0
肌酐 0
体重检查结果 0
是否糖尿病 0
dtype: int64
绘制纸箱图:
# 通过绘制箱型图,判断是否存在异常值
import seaborn as sns
#设置字体
from pylab import mpl
mpl.rcParams["font.sans-serif"] = ["SimHei"] # 显示中文
plt.rcParams['axes.unicode_minus'] = False # 显示负号
feature_name = {
'性别': '性别',
'年龄': '年龄',
'高密度脂蛋白胆固醇': '高密度脂蛋白胆固醇',
'低密度脂蛋白胆固醇': '低密度脂蛋白胆固醇',
'极低密度脂蛋白胆固醇': '极低密度脂蛋白胆固醇',
'甘油三酯': '甘油三酯',
'总胆固醇': '总胆固醇',
'脉搏': '脉搏',
'舒张压': '舒张压',
'高血压史': '高血压史',
'尿素氮': '尿素氮',
'肌酐': '肌酐',
'体重检查结果': '体重检查结果',
'是否糖尿病': '是否糖尿病'
}
plt.figure(figsize=(20, 20))
for i, (col, col_name) in enumerate(feature_name.items(), 1):
plt.subplot(4, 4, i)
sns.boxplot(y=data[col])
plt.title(f'{col_name}的纸箱图', fontsize=14)
plt.ylabel('数值', fontsize=12)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()

参考值(正常)
- 高密度脂蛋白胆固醇:0.83-1.96 mmol/L
- 总胆固醇(TC)或(CHOL)参考范围:3~5.2 mmol/L
- 甘油三酯(TG) 参考范围:0~1.7 mmol/L
- 低密度脂蛋白(LDL-C)参考范围:0~3.12 mmol/L
分析(查阅一点资料决定的)
- 低密度脂蛋白胆固醇,高于8的去除
- 极低密度脂蛋白胆固醇,高于8的去除
- 甘油三酯,高于40去除
- 总胆固醇,高于12的删除
- 肌酐,800(>790)的删除
- 尿素氮,>15删除
写代码运行发现:
发现全部删去了,这里假设以上情况均属于偶然,均存在,因为生病情况受到影响因素很复杂
分析:
- 影响特征的大量数均分布在中位数附件,比较平均于对称
3、数据分析
# 统计分析
data.describe()
| 卡号 | 性别 | 年龄 | 高密度脂蛋白胆固醇 | 低密度脂蛋白胆固醇 | 极低密度脂蛋白胆固醇 | 甘油三酯 | 总胆固醇 | 脉搏 | 舒张压 | 高血压史 | 尿素氮 | 尿酸 | 肌酐 | 体重检查结果 | 是否糖尿病 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 1.006000e+03 | 1006.000000 | 1006.000000 | 1006.000000 | 1006.000000 | 1006.000000 | 1006.000000 | 1006.000000 | 1006.000000 | 1006.000000 | 1006.000000 | 1006.000000 | 1006.000000 | 1006.000000 | 1006.000000 | 1006.000000 |
| mean | 1.838279e+07 | 0.598410 | 50.288270 | 1.152201 | 2.707475 | 0.998311 | 1.896720 | 4.857624 | 80.819085 | 76.886680 | 0.173956 | 5.562684 | 339.345427 | 64.106362 | 1.609344 | 0.444334 |
| std | 6.745088e+05 | 0.490464 | 16.921487 | 0.313426 | 0.848070 | 0.715891 | 2.421403 | 1.029973 | 12.542270 | 12.763173 | 0.379260 | 1.646342 | 84.569846 | 29.338437 | 0.772327 | 0.497139 |
| min | 1.805442e+07 | 0.000000 | 20.000000 | 0.420000 | 0.840000 | 0.140000 | 0.350000 | 2.410000 | 41.000000 | 45.000000 | 0.000000 | 2.210000 | 140.800000 | 30.000000 | 0.000000 | 0.000000 |
| 25% | 1.807007e+07 | 0.000000 | 37.250000 | 0.920000 | 2.100000 | 0.680000 | 0.880000 | 4.200000 | 72.000000 | 67.000000 | 0.000000 | 4.450000 | 280.850000 | 51.250000 | 1.000000 | 0.000000 |
| 50% | 1.807036e+07 | 1.000000 | 50.000000 | 1.120000 | 2.680000 | 0.850000 | 1.335000 | 4.785000 | 79.000000 | 76.000000 | 0.000000 | 5.340000 | 333.000000 | 62.000000 | 2.000000 | 0.000000 |
| 75% | 1.809726e+07 | 1.000000 | 60.000000 | 1.320000 | 3.220000 | 1.090000 | 2.087500 | 5.380000 | 88.000000 | 85.000000 | 0.000000 | 6.367500 | 394.000000 | 72.000000 | 2.000000 | 1.000000 |
| max | 2.026124e+07 | 1.000000 | 93.000000 | 2.500000 | 7.980000 | 11.260000 | 45.840000 | 12.610000 | 135.000000 | 119.000000 | 1.000000 | 18.640000 | 679.000000 | 799.000000 | 3.000000 | 1.000000 |
主要是老年人居多
相关性分析
注意:seaborn绘制热力图的时候,版本需要与matplotlib版本配对,matplotlib版本需要在3.8.0以下
# 相关性分析
import seaborn as sns
data.drop(columns=['卡号'], inplace=True)
plt.figure(figsize=(20, 15))
sns.heatmap(data.corr(),annot=True)
plt.show()

除了高密度脂蛋白胆固醇外,其他均成正相关
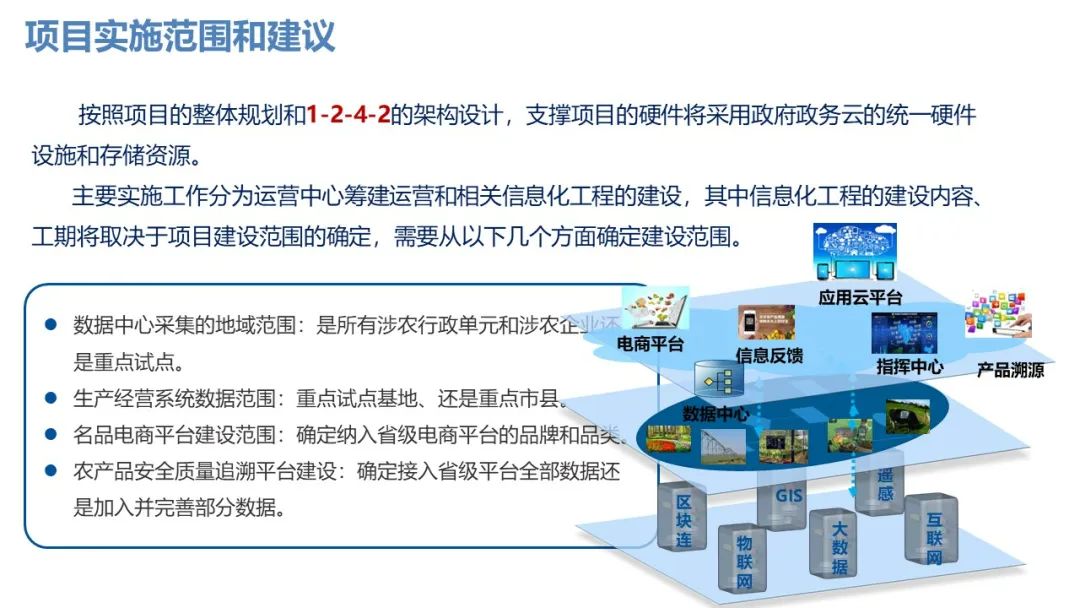
5、模型创建
1、数据集划分
from sklearn.model_selection import train_test_split
# 划分特征值和目标值
X = data.drop(['是否糖尿病', '高密度脂蛋白胆固醇'], axis=1) # 高密度脂蛋白胆固醇: 与目标值负相关
y = data['是否糖尿病']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
2、模型的创建
from sklearn.tree import DecisionTreeClassifier
# 创建模型与训练
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
模型预测
y_pred = model.predict(X_test)
6、模型评估
from sklearn.metrics import classification_report
reporter = classification_report(y_test, y_pred)
print(reporter)
precision recall f1-score support
0 0.81 0.78 0.80 120
1 0.70 0.73 0.71 82
accuracy 0.76 202
macro avg 0.75 0.76 0.76 202
weighted avg 0.76 0.76 0.76 202
准确率、召回率、f1得分很高,模型效果极好
7、特征重要性展示
feature_importances = model.feature_importances_
features_rf = pd.DataFrame({'特征': X.columns, '重要度': feature_importances})
features_rf.sort_values(by='重要度', ascending=False, inplace=True)
plt.figure(figsize=(6, 5))
sns.barplot(x='重要度', y='特征', data=features_rf)
plt.xlabel('重要度')
plt.ylabel('特征')
plt.title('随机森林特征图')
plt.show()

8、总结
- 环境:seaborn绘制热力图的时候,版本需要与matplotlib版本配对,matplotlib版本需要在3.8.0以下
- 随机森林:可以决解多重共线性问题
- 进一步熟悉了数据分析的过程
- 不足:算法的扩展性、数据特征提取没有做