点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(正在更新!)
章节内容
上节完成了如下的内容:
- Flink YARN 模式
- YARN模式下申请资源
- YARN模式下提交任务

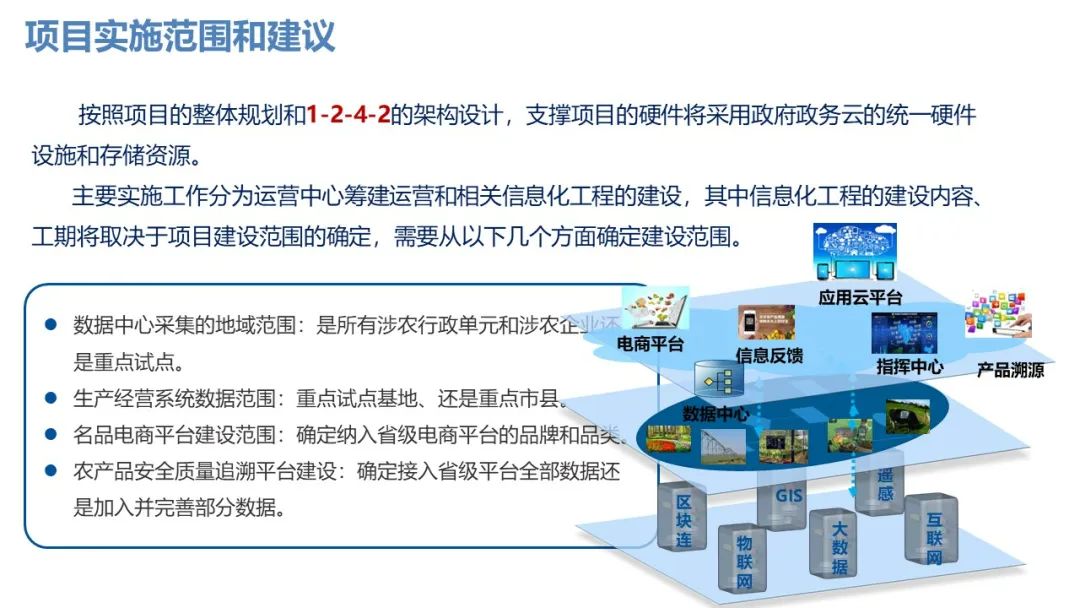
DataStream API
主要分为3块:
● DataSource:程序的数据源输入,可以通过StreamExecutionEnvironment.addSource为程序添加数据源
● Transformation:具体的操作,它对一个或者多个输入源进行计算处理,比如Map、FlatMap、Filter操作等
● Sink:程序的输出,它可以把Transformation处理之后的数据输出到指定的存储介质中
Flink针对DataStream提供了大量已经实现的DataSource(数据源接口)。
下面来进行分析。
基于文件
readTextFile(path):读取本地文件,文件遵循TextInputFormat逐行读取规则并返回
如果你是本地IDEA要读取HDFS,那你需要额外的依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hadoop-compatibility_2.11</artifactId>
<version>1.11.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.9.2</version>
</dependency>
基于Socket
socketTextStream:从Socket中读取数据,元素可以通过一个分割符号分开。
基于集合
fromCollection:通过Java的Collection集合创建一个数据流,集合中的所有元素必须是相同类型的。
如果满足一下条件,Flink将数据类型识别为POJO类型(并允许“按名称”字段引用)
- 该类是共有且独立的(没有非静态内部类)
- 该类有共有的无参构造方法
- 类(及父类)中所有的不被static、transient修饰的属性要么是公有的且不被final修饰,要么是包含公有的Getter和Setter方法,这些方法遵循JavaBean的命名规范。
编写代码
编写的代码如下:
package icu.wzk;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment;
import java.util.ArrayList;
import java.util.List;
public class StreamFromCollection {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
List<People> peopleList = new ArrayList<>();
peopleList.add(new People("wzk", 18));
peopleList.add(new People("icu", 15));
peopleList.add(new People("wzkicu", 10));
DataStreamSource<People> data = env.getJavaEnv().fromCollection(peopleList);
SingleOutputStreamOperator<People> filtered = data.filter(new FilterFunction<People>() {
@Override
public boolean filter(People value) throws Exception {
return value.getAge() > 15;
}
});
filtered.print();
env.execute("StreamFromCollection");
}
public static class People {
private String name;
private Integer age;
public People() {
}
public People(String name, Integer age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
}
}
运行结果
运行结果如下图所示:

toString
我们可以通过重写 People 的 toString() 方法,来打印内容:
@Override
public String toString() {
return "name: " + this.name + ", age: " + this.age;
}
重新运行
重新运行可以看到:

自定义输入
可以使用 StreamExecutionEnvironment.addSource()将一个数据源添加到程序中。
Flink提供了许多预先实现的源函数,但是也可以编写自己的自定义源,方法是非并行源:implements SourceFunction,或者为并行源 implements ParallelSourceFuction接口,或者 extends RichParallelSourceFunction
Flink也提供了一些内置的 Connector(连接器),如下表列了几个主要的:

Kafka连接器
添加依赖
我们需要继续添加依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.11.1</version>
</dependency>
编写代码
package icu.wzk;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.util.Properties;
public class StreamFromKafka {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 配置信息
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "h121.wzk.icu:9092");
// Kafka
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>(
"flink_test",
new SimpleStringSchema(),
properties
);
DataStreamSource<String> data = env.getJavaEnv().addSource(consumer);
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = data
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" ");
for (String word: words) {
out.collect(new Tuple2<>(word, 1));
}
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> result = wordAndOne
.keyBy(new KeySelector<Tuple2<String, Integer>, Object>() {
@Override
public Object getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
})
.sum(1);
result.print();
env.execute("StreamFromKafka");
}
}
启动Kafka
我们需要启动 Kafka 的服务来进行测试,之前章节我们已经配置和启动过Kafka了,这里就是直接启动了。
cd /opt/servers/kafka_2.12-2.7.2/bin
./kafka-server-start.sh ../config/server.properties
启动结果如下图所示:

创建主题
cd /opt/servers/kafka_2.12-2.7.2/bin/
./kafka-topics.sh --create --zookeeper h121.wzk.icu:2181 --replication-factor 1 --partition 1 --topic flink_test
生产消息
cd /opt/servers/kafka_2.12-2.7.2/bin/
./kafka-console-producer.sh --bootstrap-server h121.wzk.icu:9092 --topic flink_test
# 我们等Java程序启动后,产生几条消息
运行代码
观察控制台可以看到:
3> (hello,1)
5> (world,1)
3> (hello,2)
5> (world,2)
3> (hello,3)
3> (hello,4)
2> (hello!,1)
2> (hello!,2)
...
运行的截图如下所示: