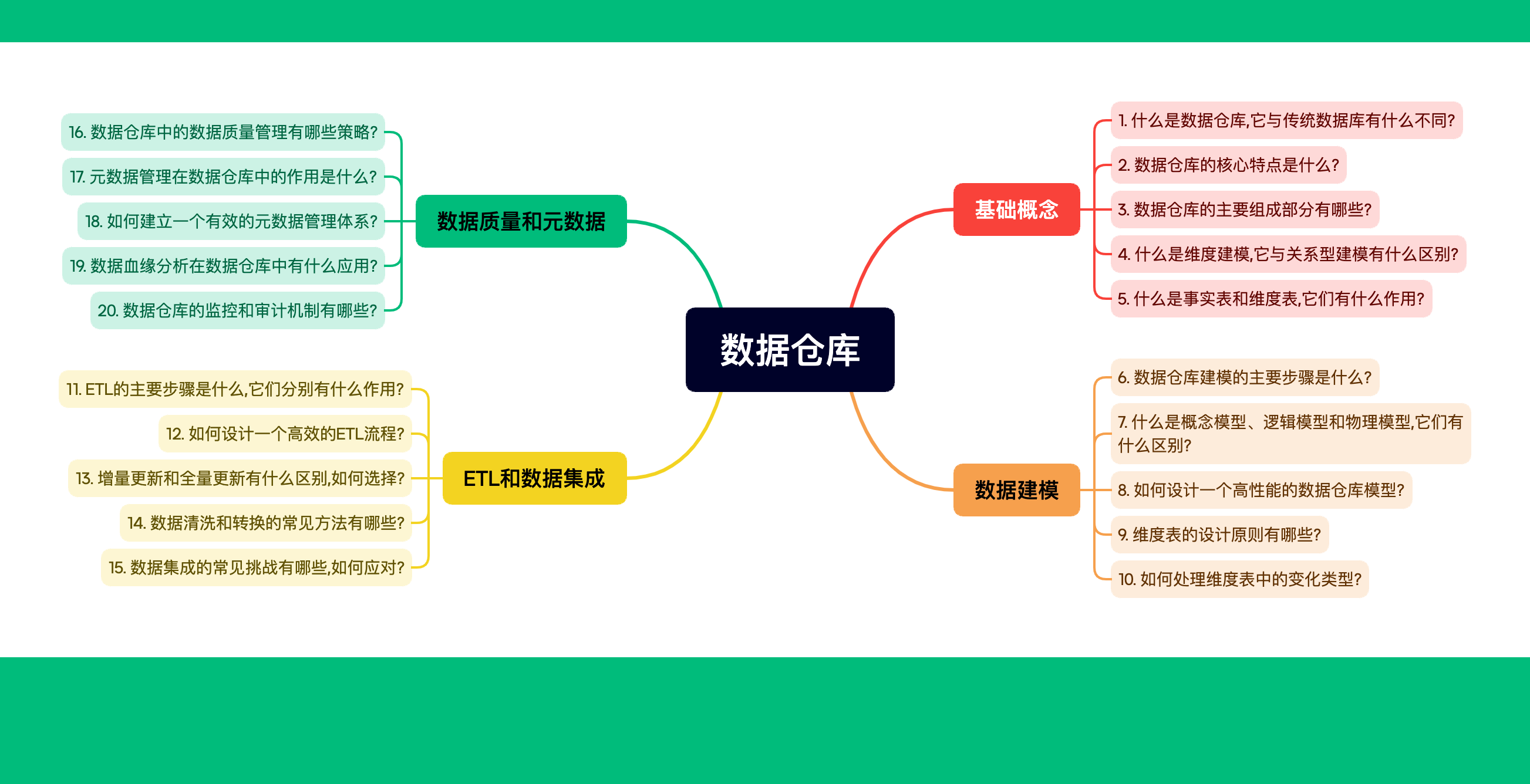
在数据分析和机器学习的领域中,数据降维是一项非常重要的技术。它旨在减少数据集中的特征数量,同时尽可能保留原始数据的重要信息。这不仅有助于减少计算复杂度和提高算法效率,还能有效避免过拟合,提升模型的泛化能力。本文将简要介绍四种常用的数据降维技术:主成分分析(PCA)、独立成分分析(ICA)、奇异值分解(SVD)和线性判别分析(LDA)。
一、主成分分析(PCA)
1.基本原理
PCA是一种无监督学习的数据降维方法,它通过线性变换将原始数据投影到一个新的坐标系统中,使得数据的任何投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依此类推。通过这种方式,PCA能够去除数据中的冗余信息,保留最重要的特征。

2.应用场景
数据可视化、噪声和冗余数据去除和压缩数据以加快学习算法的速度。
3.实现步骤
(1)数据标准化
(2)计算协方差矩阵
(3)计算协方差矩阵的特征值和特征向量
(4)选择最重要的特征向量(主成分)
(5)将数据投影到这些特征向量上
4.代码实现
# PCA降维
pca = PCA(n_components=25)
P_train = torch.tensor(pca.fit_transform(P_train), dtype=torch.float64)
P_test = torch.tensor(pca.transform(P_test), dtype=torch.float64)
二、独立成分分析(ICA)
1.基本原理
ICA是一种计算方法,用于从多元信号中分离出统计上尽可能独立的非高斯信号源。与PCA不同,ICA不仅最大化数据的方差,还寻求数据的非高斯性最大化,以提取统计独立的成分。

2.应用场景
盲源分离(如音频信号处理)和特征提取
3.实现步骤
(1)数据预处理(如白化)
(2)迭代优化算法(如FastICA)来寻找独立成分
4.代码实现
# ICA降维
n_components = 25
ica = FastICA(n_components=n_components,tol=0.01, max_iter=1000, random_state=0)
P_train = ica.fit_transform(P_train)
P_test = ica.transform(P_test)
三、奇异值分解(SVD)
1.基本原理
SVD是一种矩阵分解方法,它将任意矩阵分解为三个特定类型的矩阵的乘积:一个正交矩阵、一个对角矩阵(奇异值矩阵)和另一个正交矩阵的转置。SVD在数据降维中通常用于找到数据中的主要特征方向。

2.应用场景
噪声减少、数据压缩和近似矩阵计算
3.实现步骤
(1)对数据矩阵进行SVD分解
(2)选择最大的几个奇异值及其对应的奇异向量
(3)使用这些奇异向量重构数据以进行降维
4.代码实现
# SVD降维
U_train, s_train, Vt_train = svd(P_train, full_matrices=False)
U_test, s_test, Vt_test = svd(P_test, full_matrices=False)
# 选择保留的特征数量
n_components = 25
# 计算降维后的特征
P_train = U_train[:, :n_components] @ np.diag(s_train[:n_components])
P_test = U_test[:, :n_components] @ np.diag(s_test[:n_components])
四、线性判别分析(LDA)
1.基本原理
LDA是一种有监督学习的降维技术,旨在找到一个线性组合,使得类内方差最小,类间方差最大。这有助于区分不同类别的数据。

2.应用场景
分类任务中的特征提取和数据可视化
3.实现步骤
(1)计算类内散度矩阵和类间散度矩阵
(2)计算最优投影方向(最大化类间散度与类内散度的比值)
(3)将数据投影到这些最优方向上
4.代码实现
# LDA降维
n_features = P_train.shape[1]
n_classes = len(torch.unique(T_train))
# 确定 n_components 的最大值
n_components = min(n_features, n_classes - 1)
lda = LDA(n_components=n_components)
X_reduced_train = lda.fit_transform(P_train, T_train)
X_reduced_test = lda.transform(P_test)
五、总结
数据降维是处理高维数据的有效手段,PCA、ICA、SVD和LDA各有其独特的优势和应用场景。PCA适用于无监督学习中的数据压缩和可视化;ICA则更擅长于信号的盲源分离;SVD在数据压缩和噪声减少方面表现出色;而LDA则特别适用于有监督学习中的特征提取和分类任务。了解并合理应用这些技术,将有助于提高数据处理的效率和准确性。