目录
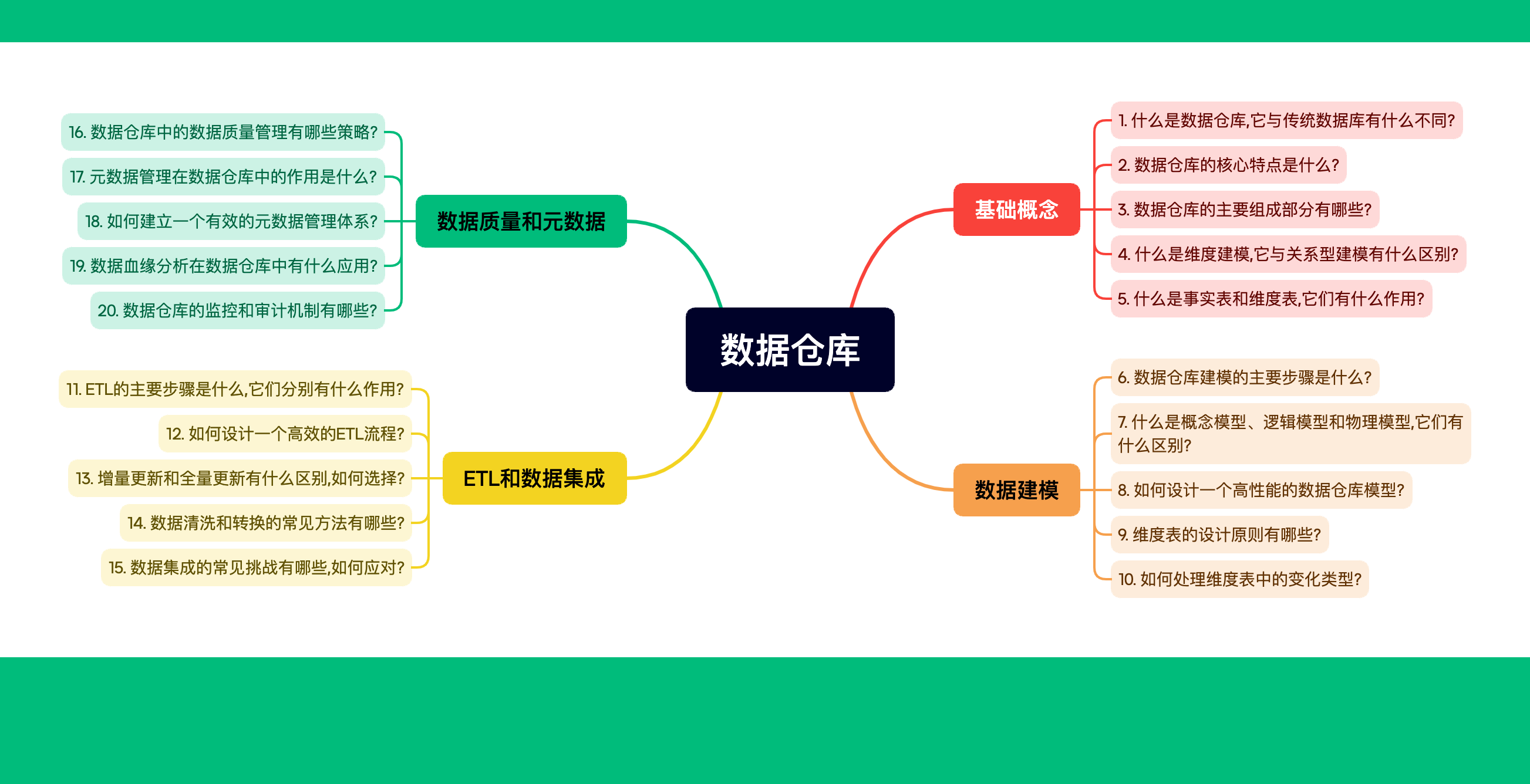
1.总体的皮尔逊相关系数
2.样本的皮尔逊相关系数
3.对于皮尔逊相关系数的认识
4.描述性统计以及corr函数
编辑 5.数据导入实际操作
6.引入假设性检验
6.1简单认识
6.2具体步骤
7.p值判断法
8.检验正态分布
8.1jb检验
8.2威尔克检验:针对于p值进行检验
9.两个求解方法的总结
1.总体的皮尔逊相关系数
我们首先要知道这个皮尔逊相关系数里面的两个概念,我们的系数的计算要使用到这两个概念,一个就是总体的均值(就是求和之后求解平均值),xy各是一组数据,我们使用这个x里面的数据减去第一组的均值乘上第二组的数值减去均值,然后做乘法求和,除以on就是这个两组数据的协方差

皮尔逊相关系数就是在协方差的基础上面,除以各自对应的标准差,这个除以标准差的过程,实际上就是进行的这个标准化的过程,这个标准化之后的协方差就是我们的皮尔逊相关系数;

2.样本的皮尔逊相关系数
我们的总体的皮尔逊相关系数是除以这个数组的个数n,但是这个样本的皮尔逊相关系数是除以这个n-1,这个就是两者在计算上面的区别;

上面的这个无论是总体的皮尔逊相关系数,还是样本的皮尔逊相关系数,都是为了让我们了解这个背后的计算方法,在实际的数学建模里面,我们是使用的相关的数学软件里面的函数直接进行这个计算的,并不会用到上面的理论知识,但是只有了解这些理论知识,当我们的结果计算出来的时候,我们才可以让这个结果结合理论对于我们的题目进行描述性说明,达到我们的建模的效果;
3.对于皮尔逊相关系数的认识

通过上面的这个图形,我们也可以看出来同样是0.816的系数,我们的散点图的绘制效果完全不同,这个就是因为我们的这个皮尔逊相关系数使用是有自己的条件的,如果我们无论是什么模型都去计算这个皮尔逊相关系数,其实是没有他的真实含义的;
实际上只有两个变量之间是线性相关,这个相关系数的求解计算才会有实际意义,因此这个就要求我们首先要进行这个可视化,做出来这个散点图,根据这个散点图去判断我们的这个两个变量之间是否满足线性相关,只有满足的情况下我们再去计算这个皮尔逊相关系数;

对于上面的这四张图片,我们进行下面的解释,就是这个皮尔逊相关系数即使是一样的,但是这个实际情况却截然不同,第一个图像上面的数据点显然不是线性相关的,但是这个皮尔逊相关系数的计算结果显示这个数据集具有很强的相关性,离散的点对于这个皮尔逊系数的影响也很大,最后一张图的那个根本就没有相关关系,但是这个计算结果却很大,实际上这个计算结果是没有实际意义的;
因此,我们进行总结,当两个变量之间满足线性相关的时候,结果大就说明两个变量的相关性强,小就是两个变量的相关性弱,但是如果这两个变量就没有相关性,这个时候即使计算结果很大也不能说明两个变量之间具有较强的相关性;

4.描述性统计以及corr函数
下面这个就是多组向量,我们可以先进行可视化的工作,然后根据这个可视化的结果去判断这个是否满足线性相关,满足的话我们就是用这个corr函数进行皮尔逊相关系数的计算;

但是对于这样的数据类赛题,我们拿到这个数据之后最好是进行一下这个数据的描述性分析,就是计算这个数据的平均值,方差之类的,获得这个数据的数字特征,利于我们后续的分析;
我们使用下面的这个基本的计算方差,均值,标准差之类的函数对于这个数据的数字特征进行计算和说明,这个是我们的准备工作;然后我们就可以去调用这个corrcoef函数你进行这个相关系数的计算,这个计算结果就是一个6*6的矩阵,表示这6个变量之间一一对应的相关系数,因为这个1和2,2和1的这个相关系数应该是一样的,因此使用这个函数输出的这个矩阵也是一个对称矩阵,只需要看一半就可以知道任意两组数据之间的相关关系;
 5.数据导入实际操作
5.数据导入实际操作
在这个数学建模的时候,很多的情况下我们都需要导入数据,这个时候我们就需要去学习导入数据的方法以及使用数据的代码:
选择我们想要导入的数据:不要复制这个表头,例如这个x,y之类的,我们只需要复制这个数据,因为这个就算我们把这个x,y复制过去,这个也是被视为0的,因为这个xy不是数值型数据;

首先就是右键,点击新建,然后新建一个变量,把我们的这个数据粘贴进去即可,这个时候的变量就导入进去了,我们可以创建一个x一个y进行演示;


我们再右键工作区保存两个数据xy,这个时候命名这个数据集合是data.mat,这个后缀是我们的系统自动加上的,我们只需要进行这个名字的修改即可;
这个时候,如果我们在这个编程的过程中需要使用到上面的数据,这个时候我们的代码里面就可以使用load+文件的名字,这个时候我们需要的数据就导入了进来,这个就是导入数据的方法;

6.引入假设性检验
6.1简单认识
假设性检验的前提就是我们需要有原假设:下面的这个例子,就是一个班级上面的30名同学。我们假设这个班级的平均成绩在80分左右,这个就是一个原假设;

接下来,我们需要认识一下两个概念:
置信水平β:表示我们的原来假设成立的概率,这个数值一般都会比较大;
显著性水平α:表示我们的原来的假设不成立的概率,这个概率一般都会比较小;
我们假设这个符合正态分布,那么这个70,90就是两个临界值,如果我们取出一个同学的成绩在这个区间里面,那么这个就可以说明我们的原假设成立,如果不在这个区间里面,就说明我们的原假设不成立,这个不成立的时候就是第一类错误,因为这个不成立的概率很小,我们却遇到了;
6.2具体步骤
首先就是有一个原假设,这个里面涉及到了这个概率密度函数和累积密度函数,统计量等诸多的数学概念,我们如果没学过就只需要知道这个具体的比较,至于这个相关的函数以及具体的计算,我就不在赘述了;
就是我们的这个标准化后的检验值是不是在这个接受域里面,如果是,我们就接受原假设,否则就拒绝原假设,这个接受域的计算和我们的置信水平有关,置信水平越高,我们接受原假设的概率越大,大概就是这个样子的;

7.p值判断法
为什么会有这个p值判断法,就是这个皮尔逊相关系数的检验方法太复杂,我们使用这个p值来简化这个流程,且这个运用我们的累计密度函数;
下面的一个验证正态分布的方法就是基于p值进行的,就是通过打印这个p值来判断是否满足我们的正态分布;

8.检验正态分布
想要对于这个皮尔逊相关系数进行假设性检验,首先这个数据需要满足我们的正态分布,小样本数据我们可以使用威克尔检验查看这个数据之间是否在满足正态分布,大样本的数据需要使用JB检验查看是否满足正态分布;
8.1jb检验
使用这个JB检验需要调用这个jbtest函数,这个函数的第一个参数就是需要进行检验的向量,第二个参数就是我们的自由度,下面这个实例里面的自由度就是2;
我们这个输出结果里面实际上是有0有1的,这个时候输出结果是0的表示的就是这个对应的行和列代表的变量之间拒绝原假设

8.2威尔克检验:针对于p值进行检验
我们的这个威尔克检验是在这个spss上面进行的;

输出的结果示例:

同时使用两个相关系数进行分析,出现的这个右上角的型号表示的是这个相关性的显著程度:

9.两个求解方法的总结
因为这个皮尔逊相关系数基本上进行假设检验的时候是很难满足我们的正态分布的,因此我们大部分情况下使用的都是这个斯皮尔曼相关系数来进行这个求解问题