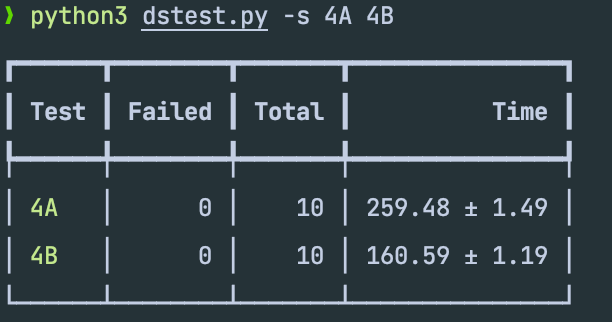
CountVectorizer 是 scikit-learn 库中的一个文本向量化工具,它将文本数据转换为词频特征矩阵。以下是 CountVectorizer 的算法原理和步骤:
原理
-
文本预处理:
- 分词:将文本分割成单词或短语(tokens)。
- 小写化:将所有单词转换为小写,以确保大小写不敏感。
- 去除停用词:可选步骤,移除常见的、意义不大的单词,如“the”、“is”等。
- 去除标点和特殊字符:可选步骤,清理文本中的非字母数字字符。
-
构建词汇表:
- 从所有文本中提取唯一的单词或短语,构建一个词汇表。
- 每个单词或短语被分配一个唯一的整数索引。
-
向量化:
- 根据词汇表,计算每个单词或短语在每个文本中的出现次数。
- 生成一个词频矩阵,其中行对应于文本,列对应于词汇表中的单词或短语。
-
n-gram 范围:
ngram_range=(1, 3)表示考虑从单个单词(1-gram)到三词短语(3-gram)的所有组合。- 这增加了模型能够捕捉的上下文信息的复杂性。
-
特征选择:
max_features=6限制了词汇表中单词或短语的最大数量,选择最常见的6个特征。- 这有助于减少特征空间的维度,提高计算效率。
算法步骤
-
初始化:
- 创建
CountVectorizer实例,设置参数如max_features和ngram_range。from sklearn.feature_extraction.text import CountVectorizer texts=['dog cat fish','dog cat cat','fisg bird','bird'] conts=[] cv=CountVectorizer(max_features=6,ngram_range=(1,3))
- 创建
-
拟合(Fit):
- 调用
fit方法,算法分析文本数据,构建词汇表。cv_fit = cv.fit(texts)
- 调用
-
转换(Transform):
- 调用
transform方法,将文本数据转换为词频矩阵。cv_fit = cv.transform(texts)
- 调用
-
输出:
get_feature_names_out()方法返回词汇表中的单词或短语。toarray()方法将稀疏矩阵转换为常规数组,便于查看和分析。print(cv.get_feature_names_out()) print(cv_fit.toarray())
-
输出结果

-
完整代码
# 导入 sklearn 库中的 CountVectorizer 类
from sklearn.feature_extraction.text import CountVectorizer
# 定义一组文本数据,每个文本是一个字符串
texts = ['dog cat fish', 'dog cat cat', 'fisg bird', 'bird']
# 初始化 CountVectorizer 对象
# max_features=6 表示最多选择6个最重要的特征(最常见的单词或短语)
# ngram_range=(1, 3) 表示考虑单词的单字(1-gram)、双字(2-gram)和三字(3-gram)组合
cv = CountVectorizer(max_features=6, ngram_range=(1, 3))
# 使用 fit 方法来学习文本数据中的词汇表
cv_fit = cv.fit(texts) # 学习词汇表
# 使用 transform 方法来转换文本数据为特征矩阵
# 这一步使用上一步中学习的词汇表来计算每个文本中单词的出现次数
cv_fit = cv.transform(texts) # 转换文本数据
# 打印转换后的稀疏矩阵
print(cv_fit)
# 打印词汇表中的单词或短语
print(cv.get_feature_names_out())
# 将稀疏矩阵转换为常规的 numpy 数组格式
print(cv_fit.toarray())