🍊作者简介:秃头小苏,致力于用最通俗的语言描述问题
🍊专栏推荐:深度学习网络原理与实战
🍊近期目标:写好专栏的每一篇文章
🍊支持小苏:点赞👍🏼、收藏⭐、留言📩
深度学习语义分割篇——DeeplabV3原理详解+源码实战
写在前面
Hello,大家好,我是小苏👦🏽👦🏽👦🏽
前面两节已经为大家讲解了DeepLabV1和DeepLabV2网络,还不熟悉的点击下面链接了解详情喔。🌴🌴🌴
-
深度学习语义分割篇——DeepLabV1原理详解篇🍁🍁🍁
-
深度学习语义分割篇——DeepLabV2原理详解篇🍁🍁🍁
今天为大家带来的时Deeolab系列的最后一篇DeepLabV3,会对其原理和源码进行细致的讲解。准备好了的话,就让我们一起出发叭~~~🚖🚖🚖
论文链接:DeepLabV3论文🍵🍵🍵
DeepLabV3原理详解
在DeepLabV3的论文中提出了两种模型结构,一种是cascaded model,另一种是的ASPP model。但是阅读论文的实验会发现ASPP model的性能比cascaded model好一点,如下图所示:

并且Github上的很多代码,都是采用ASPP model写的。本文将面向源码为大家介绍DeepLabV3,所有不会再介绍cascaded model【其实也很简单,感兴趣的可以去看一下】,而是直接介绍ASPP model。🌱🌱🌱
ASPP model
ASPP???听到这个名字大家是不是很熟悉呢!!!没错,这个在DeepLabV2中就提到了,忘记了的可以去看一看。🍭🍭🍭那么V3对这个结构做了一些小改动,让我们一起来看看叭,如下图所示:

对比V2网络,你会发现DeepLabV3的ASPP结构有五个分支,分别是1个1×1的卷积,3个不同膨胀率的3×3的空洞卷积以及一个全局平均池化层,然后会将这五个分支的输出进行拼接。大家有没有觉得这个结构非常简单呢,更为详细的结构如下:

不知道大家注意到没有,上图中的3个空洞卷积的膨胀系数分别为12、24、36,和本小节第一张图的6、12、18不一样,这是训练时的小细节导致的——如果下采样率为16的话膨胀系数就使用6、12、18,下采样率为8的话,膨胀系数就使用12、24、36,大家这里注意一下就好,想要了解更多可以去翻翻论文。🥝🥝🥝
这个ASPP model就为大家介绍到这里了,哈哈哈大家是不是觉得有点太少了。🍡🍡🍡其实这篇论文的重点我感觉真的不算多,和V2感觉也差不多,接下来重点还是和大家唠唠V3的源码叭。🌷🌷🌷

哦,对了,我觉得论文中的这个获取多尺度的图大家可以借鉴一下,了解一下常见的融合多尺度的方法。图a-图d这四个方法大家是否都知道腻,这里大家好好想想叭,我就不说了,要是不明白的可以评论区见喔~~~🌼🌼🌼
DeepLabV3源码详解
DeepLabV3源码地址🍁🍁🍁 -----来自霹雳吧啦Wz
DeepLabV3属于语义分割系列,因此阅读以下内容时你最好对语义分割有一定的了解,不熟悉的可以看我的这两篇博客,带你入门语义分割:
- ①深度学习语义分割篇——FCN原理详解篇
- ②深度学习语义分割篇——FCN原理详解篇
大家可能不想看整篇文章,我也觉得没必要全都看,但有两处我觉得你务必得看看。
- 如果你对VOC语义分割的数据集不清楚,对语义分割的标注格式不明白,那么你需要读读①中附录部分的内容。🌲🌲🌲
- 如果你对语义分割中损失函数是怎么计算的,计算时怎么忽略某些特定的值的,那么你需要读读②中附录部分的内容。🌲🌲🌲
DeepLabV3模型搭建
按照正常模型训练的步骤,前面还有数据读取与加载的内容,但这部分其实是和FCN一样的,这里就不过多叙述了,不知道的去看上面的链接。🌻🌻🌻
我们直接来看DeepLabV3整个模型的框架图,如下:

图片来自霹雳吧啦Wz
首先我们来看看如何搭建resnet的backbone,如下:
backbone = resnet50(replace_stride_with_dilation=[False, True, True])
replace_stride_with_dilation=[False, True, True],我来解释以下这个参数,当这三个值都为False时,就是标准的Resnet50,设置为True会在相应层使用空洞卷积。【三个值分别对于resnet50的Layer2、Layer3、Layer4】🍋🍋🍋

当这三个值设置为[False, True, True]时,Layer3和Layer4会使用空洞卷积,并且不会再进行下采样。具体的代码大家可以调试进去看看,这里就不带大家看了,本节重点说说ASPP结构。🥗🥗🥗
我们可以看看此步结束后输出的shape,如下:

接着此步输出会作为ASPP结构的输入,ASPP结构相关代码如下:
class ASPP(nn.Module):
def __init__(self, in_channels: int, atrous_rates: List[int], out_channels: int = 256) -> None:
super(ASPP, self).__init__()
modules = [
nn.Sequential(nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU())
]
rates = tuple(atrous_rates)
for rate in rates:
modules.append(ASPPConv(in_channels, out_channels, rate))
modules.append(ASPPPooling(in_channels, out_channels))
self.convs = nn.ModuleList(modules)
self.project = nn.Sequential(
nn.Conv2d(len(self.convs) * out_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Dropout(0.5)
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
_res = []
for conv in self.convs:
_res.append(conv(x))
res = torch.cat(_res, dim=1)
return self.project(res)
注意,这里传入的atrous_rates为[12,24,36],为三个不同的膨胀系数。

其中,ASPPConv类的代码如下:
class ASPPConv(nn.Sequential):
def __init__(self, in_channels: int, out_channels: int, dilation: int) -> None:
super(ASPPConv, self).__init__(
nn.Conv2d(in_channels, out_channels, 3, padding=dilation, dilation=dilation, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
ASPPPooling类的代码如下:
class ASPPPooling(nn.Sequential):
def __init__(self, in_channels: int, out_channels: int) -> None:
super(ASPPPooling, self).__init__(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
size = x.shape[-2:]
for mod in self:
x = mod(x)
return F.interpolate(x, size=size, mode='bilinear', align_corners=False)
注意这里的最后的双线性插值上采样是写在前向传播过程当中的。🍜🍜🍜
ASPP结构结束后,同样可以看一下此时输出的shape:

接着后面会有一些卷积和BN操作,如图:

这部分结束后,shape如下:

最后会有一个双线性插值算法,如下:

此时会得到最终的输出,shape如下:

到这里DeepLabV3的模型搭建其实就介绍完啦,你可以拿最后的输出结果和GT去计算损失啦。🍊🍊🍊其实细心的朋友可能会发现模型图中还有一个FCN Head,这是一个辅助分支,使用辅助分支得到结果后可以和主分支结果相加,可以提高整体模型的表现。当然啦,这个辅助分支也可以不使用,我在代码中就关闭了这个参数。🌴🌴🌴
poly学习率策略源码详解
这里我额外介绍以下这个知识点,因为这部分代码其实在理解上还是有一点困难的。🥦🥦🥦
还记得我们在DeepLabV2中讲到的poly学习率策略嘛,性能足足提高了三个点,先让我们简单来回顾一下poly学习率策略的公式叭:
l r = l r ∗ ( 1 − i t e r m a x _ i t e r ) p o w e r lr=lr*(1-\frac{iter}{max\_iter})^{power} lr=lr∗(1−max_iteriter)power
其中,power是一个超参,默认为0.9。 l r lr lr为初始学习率, i t e r iter iter为当前迭代的step数,$m a x _ i t e r 为训练过程中总的迭代步数。 p o l y 策略的 为训练过程中总的迭代步数。poly策略的 为训练过程中总的迭代步数。poly策略的lr$变化曲线大致如下图所示:
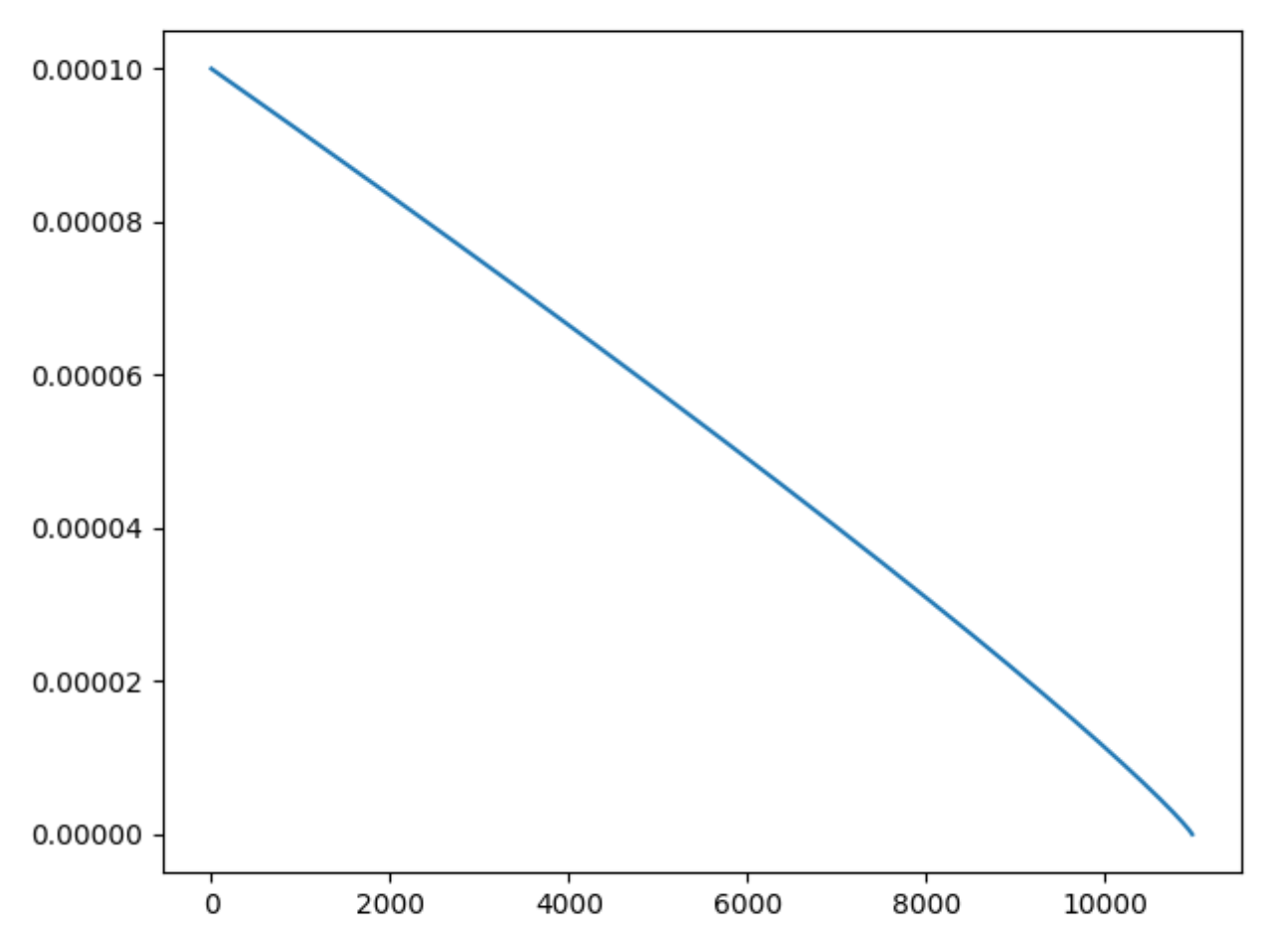
我们先来简单说说为什么采用这样递减的学习率变化策略,这是为了在训练深度神经网络时,兼顾快速收敛和稳定优化过程。在梯度下降初始阶段使用较大的学习率可以让梯度以大步前进,快速接近最优解。然而,当模型接近最优解或在最优解附近时,使用较小的学习率可以让梯度采取小步前进,避免在最优点附近震荡而无法稳定地收敛。
原理是很容易理解的,但是具体是怎么在程序中实现的呢,可能很多小伙伴就要犯糊涂了。🥗🥗🥗下面我将为大家详细的唠唠poly学习率是如何在代码中更新的。🥂🥂🥂
这里要和大家说明一点,下面的代码使用了warmup热身训练,这是在训练刚开始的时候逐渐增加学习率的优化技术,可以使模型更容易更稳定的学习和收敛。更具体的手段这里就不叙述了,网上资料很多,不清楚的大家可以去搜一搜。🍭🍭🍭那么在poly策略中加入warmup热身训练,学习率的变化曲线就会变成这样:

我们一步步来看,制定poly学习率策略要有哪些步骤。首先,我们要定义一个优化器,如下:
optimizer = torch.optim.SGD(
params_to_optimize,
lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay
)
接着,我们创建学习率更新策略,注意这里传入了optimizer参数,即学习率更新策略和优化器之间是存在交互的,大家这里留意一下就好,后面会为大家详细介绍。🍵🍵🍵
# 创建学习率更新策略,这里是每个step更新一次(不是每个epoch)
lr_scheduler = create_lr_scheduler(optimizer, len(train_loader), args.epochs, warmup=True)
讲到这里大家肯定还是一脸懵,别慌,让我们来看看create_lr_scheduler的内容:
def create_lr_scheduler(optimizer,
num_step: int,
epochs: int,
warmup=True,
warmup_epochs=1,
warmup_factor=1e-3):
assert num_step > 0 and epochs > 0
if warmup is False:
warmup_epochs = 0
def f(x):
"""
根据step数返回一个学习率倍率因子,
注意在训练开始之前,pytorch会提前调用一次lr_scheduler.step()方法
"""
if warmup is True and x <= (warmup_epochs * num_step):
alpha = float(x) / (warmup_epochs * num_step)
# warmup过程中lr倍率因子从warmup_factor -> 1
return warmup_factor * (1 - alpha) + alpha
else:
# warmup后lr倍率因子从1 -> 0
# 参考deeplab_v2: Learning rate policy
return (1 - (x - warmup_epochs * num_step) / ((epochs - warmup_epochs) * num_step)) ** 0.9
return torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=f)
对于上面的代码,我们一点点的来介绍,先来看看传入的参数代表的含义:

其中,optimizer代表优化器,num_step表示每个epoch有多少个batch的数据,其值为len(train_loader),在本代码中len(train_loader)=366;epochs在本代码中设置为30。warmup=True表示启用热身训练; warmup_epochs表示在前几个epoch启用热身训练,warmup_epochs=1表示只在第一个epoch进行热身训练;warmup_factor表示热身训练的一个倍率因子。
知道了这些参数的含义,接着我们定义了一个f(x)函数,我们先来看if条件中的代码:

先来看看什么时候满足执行条件,warmup is True成立,只要满足x <= (warmup_epochs * num_step),即x <= (1 * 366)=366即可。**【注:这个x是什么我们稍后为大家讲解,x是从0开始递增的,依次为0、1、2、3…】**当条件满足后,执行alpha = float(x) / (warmup_epochs * num_step),我们刚刚说了,x是从0开始的,我们不妨带进去计算一下alpha的值,即alpha = 0 / (1 * 366)=0。接着会return一个值,warmup_factor * (1 - alpha) + alpha=1e-3 * (1 - 0) + 0 = 1e-3。得到这步的返回值会用在哪里呢,这里我就要解释一下这个代码的流程了,如下图所示:

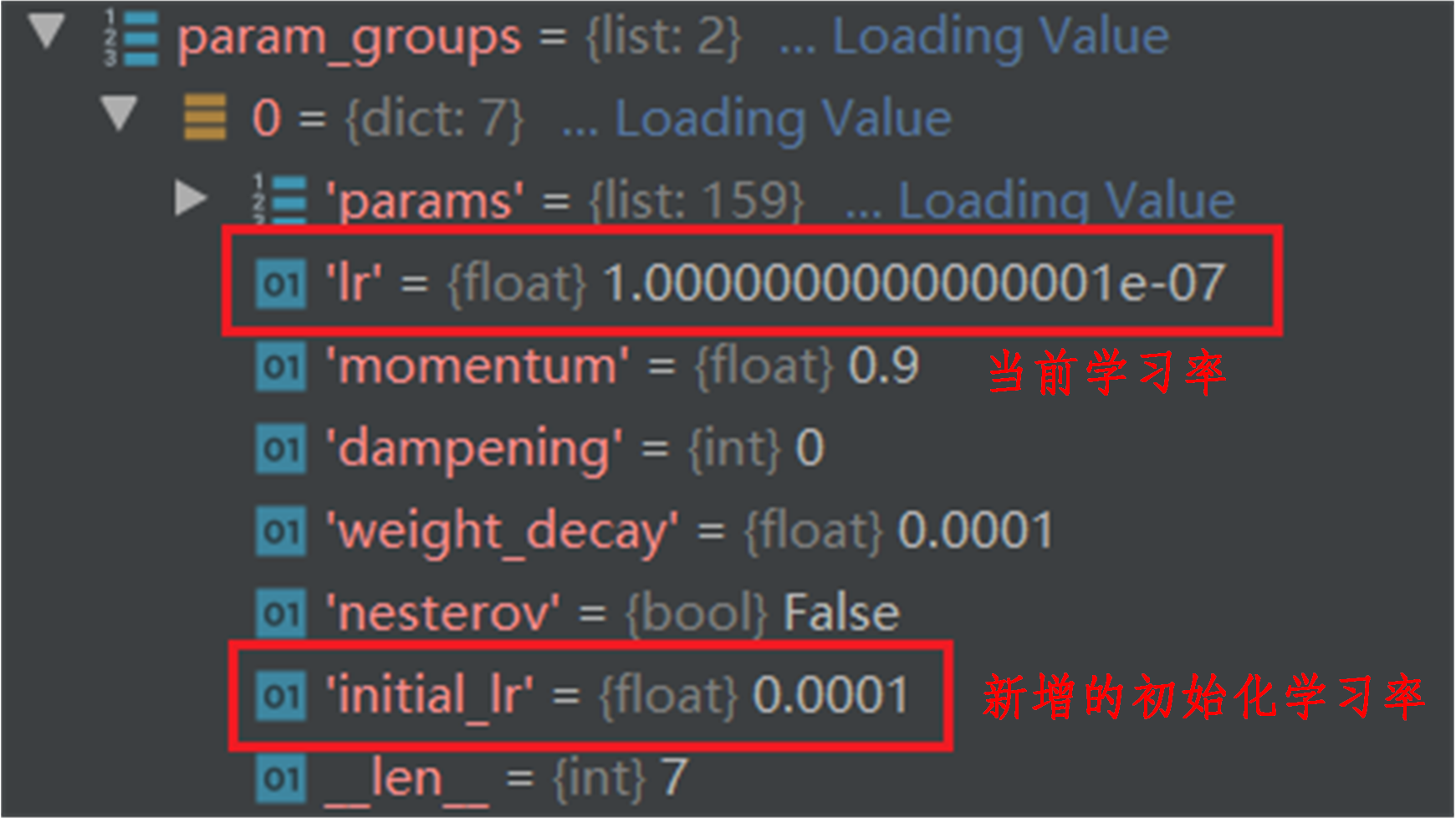
好了,通过上图我相信你以及知道了整个create_lr_scheduler函数的执行流程,那么也就知道了刚刚我们在③中计算的返回值会应用到②中,②的torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=f)是怎么计算的呢?【注:这个计算的是学习率喔】和我一起来看看叭。🥝🥝🥝首先可以看到这个LambdaLR函数有两个参数,分布为optimizer和lr_lambda=f,那么我们计算就会使用到这两个参数中的值。首先会用到optimizer中的当前学习率,我们来看看他是多少:🌽🌽🌽

可以看到,当前optimizer中的学习率为0.0001,这个当前学习率会赋值给lr_initial(初始化学习率),也即lr_initial=0.0001,这个lr_initial后面会保持不变,用于后续学习率的计算。接着来说另外一个参数,即lr_lambda=f,这个参数我想大家可能能猜出个一二,这个f就是我们刚刚说的函数f(x),那么这个参数就会利用我们刚刚求得的返回值,1e-3,这个值也叫倍率因子lr_factor。🍸🍸🍸
现在有了lr_initial=0.0001,也有了f(x)中的返回值1e-3,那么②计算当前学习率的方式即为:lr=lr_initial*lr_factor=0.0001 * 1e-3 = 1e-7。我们可以通过程序执行结果验证一下上述理论,如下图所示
通过上述的讲解,我想你对这段代码的结构和流程已经有了较为清晰的认识,但是还剩不少内容喔,大家慢慢听我叙述。在上文中,我们只执行了一步更新学习率的操作,即x=0时,这步操作是发生在创建学习率更新策略时,并没有在训练时应用。下面我们模拟训练时的代码,来看看x=1,2,3,4…后会发生什么?🌼🌼🌼
import matplotlib.pyplot as plt
lr_list = []
for _ in range(args.epochs): #args.epochs=30
for _ in range(len(train_loader)): #len(train_loader)=366
lr_scheduler.step()
lr = optimizer.param_groups[0]["lr"]
lr_list.append(lr)
plt.plot(range(len(lr_list)), lr_list)
plt.show()
这段代码首先初始化一个列表lr_list来存储学习率,接着模仿训练过程设置两个for循环,外层为epoch,内层为len(train_loader)。接着执行lr_scheduler.step(),这步是关键,会更新学习率,之前的x也会由0变成1。然后继续执行create_lr_scheduler函数,此时x <= 366依旧成立,仍然就行warmup热身训练,此时计算alpha = 1 / 366=0.0027322,warmup_factor * (1 - alpha) + alpha=0.0037295,这个值为倍率因子lr_factor,我们计算当前学习率lr=lr_initial*lr_factor=0.0001 * 0.0037295 = 3.7295e-07,程序验证如下:🌿🌿🌿

通过观察上面x=0和x=1时,倍率因子lr_factor的值,发现其变大了,其实这个很好理解,因为倍率因子lr_factor的表达式为warmup_factor * (1 - alpha) + alpha=(1-alpha) * warmup_factor + warmup_factor,它的斜率为(1-alpha),而alpha = float(x) / (warmup_epochs * num_step)=x/366是逐渐从0->1的。【注:x在warmup里最大只能到366,当其为367时,跳入else语句】因此斜率始终大于1,故倍率因子lr_factor在warmup中是不断增大的(从1e-3->1)🥦🥦🥦
lr_scheduler.step()执行完毕,会依次执行 lr = optimizer.param_groups[0]["lr"]和 lr_list.append(lr),即将刚刚得到的当前学习率存在lr_list中。接下来就是不断在循环,直到一个epoch结束,此时当前学习率为0.0001,是最大值,x=366。

继续向下执行,x=367时,x <=366条件不满足,进入else语句,我们来看这里的返回值,代码如下:
return (1 - (x - warmup_epochs * num_step) / ((epochs - warmup_epochs) * num_step)) ** 0.9
咱们可以对比一下理论部分,这一块是不是就对应着 ( 1 − i t e r m a x _ i t e r ) p o w e r (1-\frac{iter}{max\_iter})^{power} (1−max_iteriter)power腻。🥗🥗🥗

【注1:这个返回值对应的是
(
1
−
i
t
e
r
m
a
x
_
i
t
e
r
)
p
o
w
e
r
(1-\frac{iter}{max\_iter})^{power}
(1−max_iteriter)power而不是
l
r
∗
(
1
−
i
t
e
r
m
a
x
_
i
t
e
r
)
p
o
w
e
r
lr*(1-\frac{iter}{max\_iter})^{power}
lr∗(1−max_iteriter)power,因为这个返回值计算的是倍率因子lr_factor,在最后会乘上一个初始化学习率lr_initial就是当前的学习率🌱🌱🌱】
【注2:(x - warmup_epochs * num_step)=x-366这个表示要减去warmup阶段的step进行计算,(epochs - warmup_epochs) * num_step=(30-1)*366也是同样的道理🌱🌱🌱】
我们再来看下x=367时的学习率,如下图:

很容易看出,return的返回值1-(x-366)/29×366会随着x的增大而减小,即学习率会越来越小。🍋🍋🍋
呼呼呼~~~这部分终于讲完了,小结一下就是使用了warmup的poly学习率更新策略的学习率呈现一个先增后减的趋势,如图所示:
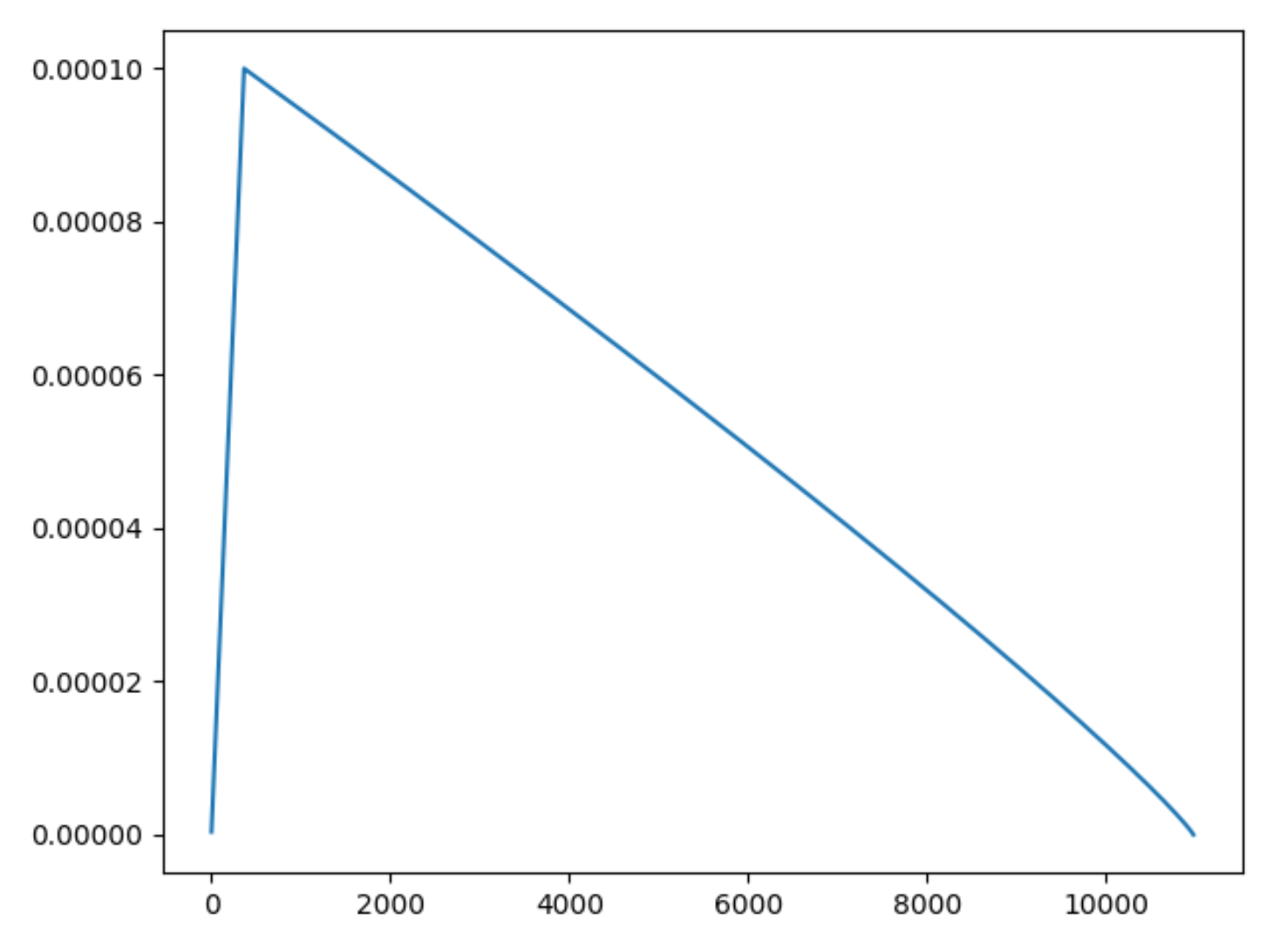
这部分讲解的算是很详细的啦,希望大家都能弄明白,加油!!!🌵🌵🌵
DeepLabV3推理结果
我从网上随便找了一张小猫咪的图片,试了试推理的效果,如下图所示:

怎么样,其实分割效果还是蛮不错滴,大家快去试试叭~~~🍂🍂🍂
总结
DeepLabV3d 原理和源码解析就为大家介绍到这里啦,整个DeepLab语义分割系列也就结束了,大家学懂了多少腻。🍀🍀🍀在后面我也会持续为大家更新内容,目前计划是先更新几个经典的分类网络,然后准备更新NLP的相关内容,从RNN到LSTM,再到Transformer[这个更新过了],BERT,最后带大家了解GPT的背后原理。🍑🍑🍑
一个人可以走的很快,一群人可以走的更远,一起加油叭!!!🌸🌸🌸
参考链接
DeepLabV3网络简析🍁🍁🍁
DeepLabV3源码地址🍁🍁🍁
如若文章对你有所帮助,那就🛴🛴🛴