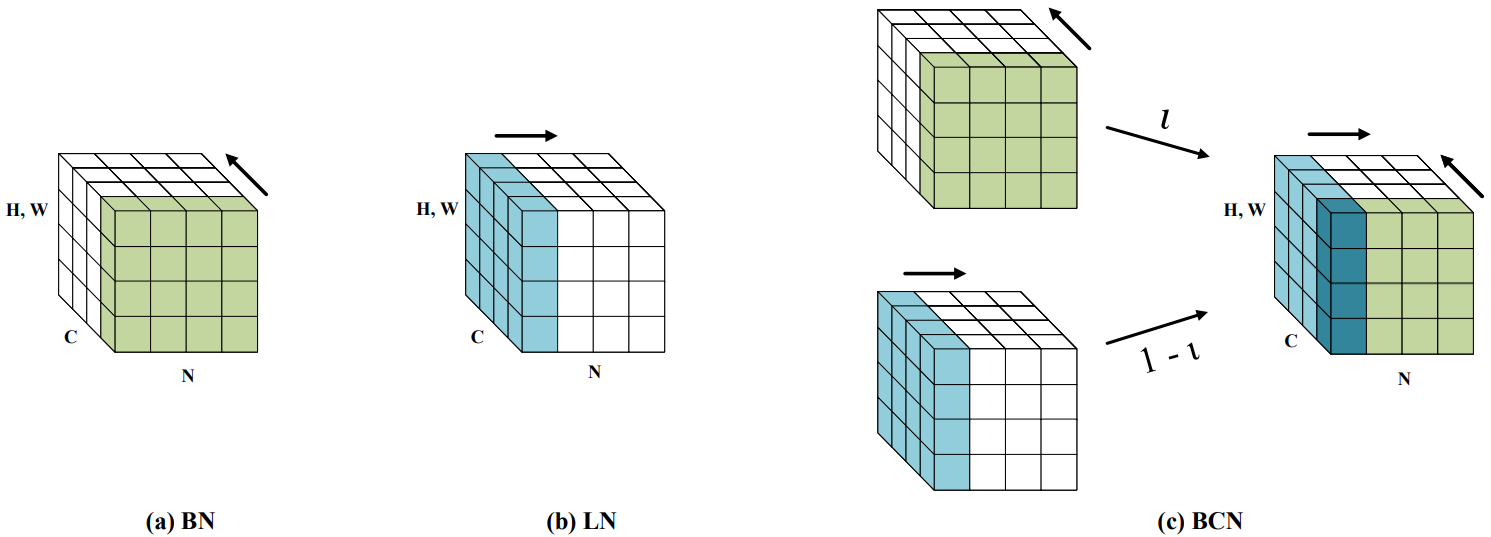
决策树原理
算法概述
从根节点开始一步步走到叶子节点(决策)
所有数据最终都会落到叶子节点,既可以做分类也可以做回归

例如上例,输入一个数据后,先判断他的年龄,然后再判断性别
在决策树中,根节点的决策效果较强——即能够明显的将数据划分(分类的效果最好)
因此,对于每个节点特征的选取,为决策树需要解决的核心内容
树的组成
根节点:第一个选择点
叶子节点:最终的决策结果
非叶子节点与分支:中间过程
决策树的训练与测试阶段
训练阶段:从给定的训练集中构造出一棵树。从根结点开始选择特征,如何进行特征切分,最终形成决策树的过程(核心部分)
测试阶段:根据构造出的树模型从上到下走一遍
熵
熵表示随机变量不确定性的度量,是一种衡量标准,通过熵来计算不同特征进行分治选择后的分类情况,从而找出来最好的那个当成根节点,以此类推
当物体内部越混乱时,即不确定性越强时,熵值越高
例如:
A集合 [ 1 , 1 , 1 , 1 , 1 , 2 , 2 ] [1, 1, 1, 1,1,2,2] [1,1,1,1,1,2,2]
B集合 [ 1 , 2 , 3 , 5 , 4 , 4 , 6 ] [1,2,3,5,4,4,6] [1,2,3,5,4,4,6]
显然A集合的熵值更低,因为A里面的种类较少,相对更稳定一点,而B中的种类较多,熵值就比较大
熵的公式
H
(
X
)
=
−
∑
i
=
1
n
p
i
log
p
i
H(X) = -\sum_{i=1}^{n} p_i \log p_i
H(X)=−i=1∑npilogpi
其中,
p
i
p_i
pi 表示第
i
i
i 中物品在集合中出现的概率
由于乘上了一个对数函数,而 p i p_i pi 的取值范围为 [ 0 , 1 ] [0,1] [0,1],因此,当出现概率越大(越接近于1)时, H ( X ) H(X) H(X)越小,即表明了,内部越稳定,熵值越低
信息增益:表示特征 X X X 使得类 Y Y Y 的不确定性减少的程度
决策树基于信息增益进行模型的构建与训练
决策树构造实例
根据数据特征数量,确定决策树节点数量

例如该数据,共有四种特征,因此需要四种划分方式,即:
- 基于天气的划分
- 基于温度的划分
- 基于湿度的划分
- 基于有风的划分
然后,分别计算每种划分的信息增益(划分后的熵值减去划分前的熵值)
例如,对于天气的划分,如下:

计算三种熵值:
sunny,熵值为0.971overcast,熵值为0rainy,熵值为0.971
然后,由于三种取值的概率不一样,因此需要对三种熵值进行线性加权,最终得到天气划分的熵值为0.693
而划分之前数据的熵值为0.940,最终得到信息增益为 0.940 − 0.693 = 0.247 0.940 - 0.693 = 0.247 0.940−0.693=0.247
运用同样方法,对特征进行遍历,依次算出其他划分情况的信息增益,选择最大的信息增益,作为根节点。
在选取完根节点的情况下,再对特征进行遍历计算信息增益,选择下一节点 … \dots …
信息增益率
如果我们存在类似于 id 的特征,即每个样本的该特征都是独一无二的,对于该特征的划分,划分之后数据的熵为0。如果使用信息增益的话,会把 id 作为根节点,但实际情况中,当种类很多时,这种类似 id 的特征对我们最后的任务没有很大的作用。因此,使用信息增益的话就会出现很大的问题,即信息增益不适合解决具有非常稀疏的特征的样本集
为了解决该问题,可以使用信息增益率,即考虑自身熵
GINI系数
GINI系数和熵类似,都是一种衡量标准,但计算方式不同
GINI系数公式
G
i
n
i
(
p
)
=
∑
k
=
1
K
p
k
(
1
−
p
k
)
=
1
−
∑
k
−
1
K
p
k
2
Gini(p) = \sum _{k=1}^{K}p_k(1-p_k) = 1- \sum _{k-1}^{K}p_k^2
Gini(p)=k=1∑Kpk(1−pk)=1−k−1∑Kpk2
其中,
p
k
p_k
pk 代表出现的概率
剪枝策略
决策树过拟合风险很大,因为理论上决策树可以做的无限的庞大,可以完全分得开数据,因此需要对建立的决策树进行剪枝操作,防止过拟合
预剪枝
边建立决策树边进行剪枝,是最实用的方法
预剪枝方法:
- 限制决策树深度
- 限制叶子节点个数
- 规定叶子节点样本最低数目
- 规定信息增益最低值
即,在建立决策树的同时,设置一些参数,防止决策树过于庞大,但这些参数还需要根据实际情况具体设定(实验交叉验证观察哪个参数值效果好)
后剪枝
当建立完决策树后再进行剪枝操作
后剪枝方法
通过一定的衡量标准去指定后剪枝方法:
C
α
(
T
)
=
C
(
T
)
+
α
∣
T
l
e
a
f
∣
C_{\alpha}(T) = C(T) + \alpha |T_{leaf}|
Cα(T)=C(T)+α∣Tleaf∣
其中,
C
(
T
)
C(T)
C(T) 为当前节点的信息熵值,
T
l
e
a
f
T_{leaf}
Tleaf是叶子节点个数
上述公式表明,叶子节点越多,损失越大
决策树代码实现(基于sklearn)
决策树算法整体流程:
- 构建数据集
- 选取根节点
- 依次向下选取其他节点——分支(递归方法创建)
导入相应的包
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
matplotlib.pyplot用于画图,可视化数据datasets用于下载sklearn里自带的数据集(这里使用鸢尾花数据)DecisionTreeClassifier为sklearn中决策树模块plot_tree用于最后树模型可视化
数据集
基于sklearn中的鸢尾花数据集
iris = datasets.load_iris()
# print(iris.data)
X = iris.data[:, 2:]
y = iris.target
通过打印y的信息,发现最终的分类只有三类,将数据可视化,观察其空间分布,如下:
plt.scatter(X[y == 0, 0], X[y == 0, 1])
plt.scatter(X[y == 1, 0], X[y == 1, 1])
plt.scatter(X[y == 2, 0], X[y == 2, 1])
plt.show()

由此,我们可以大致确定决策树的层次为二层
决策树模型建立
sklearn中决策树模型
DecisionTreeClassifier主要用于分类DecisionTreeRegression主要用于回归
在这里我们采用分类树
模型建立
tree = DecisionTreeClassifier(max_depth=2, criterion='entropy')
max_depth指定树的深度criterion指定损失函数
模型训练
tree.fit(X, y)
树模型可视化
plot_tree(tree, filled=True)
plt.show()