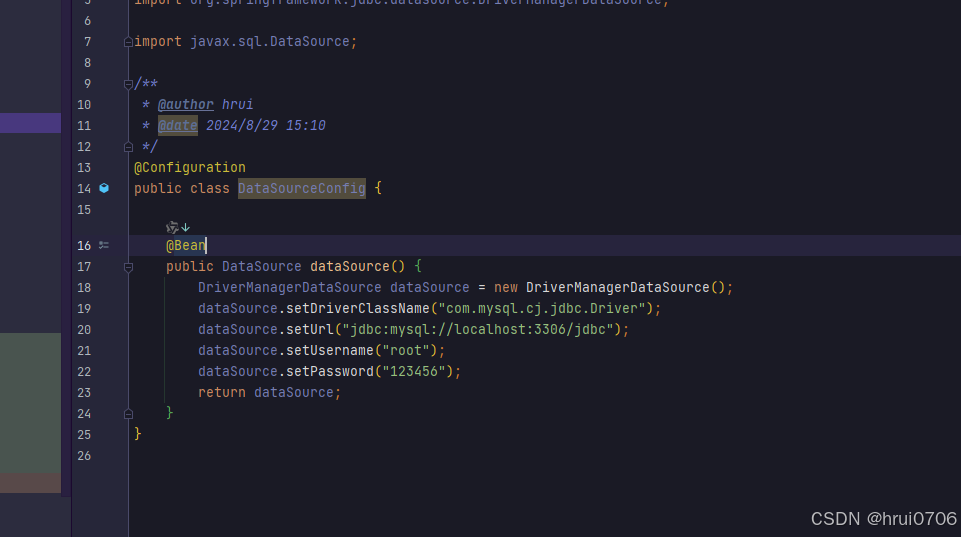
一、微调代码
from datasets import Dataset
import pandas as pd
from transformers import (AutoTokenizer,AutoModelForCausalLM,DataCollatorForSeq2Seq,TrainingArguments,
Trainer,GenerationConfig)
import torch
from peft import LoraConfig, TaskType, get_peft_model
df=pd.read_json('./QLU.json')
ds=Dataset.from_pandas(df)
tokenizer=AutoTokenizer.from_pretrained("/home/media4090/wz/model/qwen/qwen2-7b-instruct",
use_fast=False,trust_remote_code=True)
def process_func(example):
MAX_LENGTH = 384 # Llama分词器会将一个中文字切分为多个token,因此需要放开一些最大长度,保证数据的完整性
input_ids, attention_mask, labels = [], [], []
instruction = tokenizer(f"<|im_start|>system\n现在你是由Kingz训练的齐鲁工业大学AI助手,你需要回答接下来关于齐鲁工业大学的问题<|im_end|>\n<|im_start|>user\n{example['instruction']}<|im_end|>\n<|im_start|>assistant\n", add_special_tokens=False)
response = tokenizer(f"{example['output']}", add_special_tokens=False)
input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id]
attention_mask = instruction["attention_mask"] + response["attention_mask"] + [1] # 因为eos token咱们也是要关注的所以 补充为1
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id]
if len(input_ids) > MAX_LENGTH: # 做一个截断
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
tokenized_id = ds.map(process_func, remove_columns=ds.column_names)
model = AutoModelForCausalLM.from_pretrained("/home/media4090/wz/model/qwen/qwen2-7b-instruct", device_map="auto",torch_dtype=torch.bfloat16)
model.enable_input_require_grads() # 开启梯度检查点时,要执行该方法
config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
inference_mode=False, # 训练模式
r=8, # Lora 秩
lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理
lora_dropout=0.1# Dropout 比例
)
model = get_peft_model(model, config)
model.print_trainable_parameters()
args = TrainingArguments(
output_dir="/home/media4090/wz/model/qwen2-7b-instruct-QLU助手",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
logging_steps=10,
num_train_epochs=3,
save_steps=100,
learning_rate=1e-4,
save_on_each_node=True,
gradient_checkpointing=True
)
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_id,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)
trainer.train()二、数据处理脚本
import pandas as pd
import json # 导入json模块
# 读取Excel文件
def read_excel_to_json(file_path):
# 读取Excel文件,假设第一行是列名
df = pd.read_excel(file_path)
# 检查列名是否正确
expected_columns = ['问题', '回答']
actual_columns = df.columns.tolist()
missing_columns = [col for col in expected_columns if col not in actual_columns]
if missing_columns:
raise ValueError(f"Missing columns in Excel file: {', '.join(missing_columns)}")
# 初始化一个空列表来存储JSON对象
json_list = []
# 遍历DataFrame的每一行
for index, row in df.iterrows():
# 创建一个字典,其中包含所需的键和值
json_obj = {
"instruction": row['问题'],
"output": row['回答']
}
# 将字典添加到列表中
json_list.append(json_obj)
# 将列表转换为JSON格式的字符串
json_str = json.dumps(json_list, indent=4, ensure_ascii=False)
return json_str
# 调用函数并打印结果
file_path = r'D:\数据集\QLU校园助手数据集.xlsx'
try:
json_result = read_excel_to_json(file_path)
print(json_result)
with open(r"D:\数据集\QLU校园助手数据集-无input.json","w",encoding='utf-8') as f:
f.write(json_result)
except Exception as e:
print(f"An error occurred: {e}")上述脚本是将excel表格中的数据转换为json格式,使用excel有两大好处:第一点就是结构直观,修改其中内容方便;第二点是为后面的RAG检索增强做铺垫,因为就目前而言,单纯的将数据喂给大模型来微调,直接使用微调后的模型来生成回答的效果是不尽人意的。因此需要辅助RAG检索增强来提高模型效果,通过给Excel的每条数据集添加相应的标签来进一步提高检索速度及准确性,将Excel表转换成向量库,让模型能直接识别像向量库内容,从而在用户输入的时候,可以先让模型来生成与用户输入有关内容,再使模型检索向量库对应内容,将改内容作为输入送给模型,模型根据向量库内容和之前生成的回答来生成最终回答。
三、遇到的问题
1、代码正确但无法执行,显示编码错误
media4090@media4090-Super-Server:~/wz/code$ python 模型微调.py
File "模型微调.py", line 14
SyntaxError: Non-ASCII character '\xe5' in file 模型微调.py on line 14, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
找了一圈也没发现代码哪里有错误,以为是数据集中文名的原因,但去掉中文名仍然报错,最后发现没有开启虚拟环境。开启对应虚拟环境就可解决。
2、代码正确但显示在构造instruction的时候运行出错
media4090@media4090-Super-Server:~/wz/code$ python 模型微调.py
File "模型微调.py", line 17
instruction = tokenizer(f"<|im_start|>system\n现在你是齐鲁工业大学智能校园助手,你需要回答关于齐鲁工业大学的问题<|im_end|>\n<|im_start|>user\n{example['instruction'] + example['input']}<|im_end|>\n<|im_start|>assistant\n", add_special_tokens=False) # add_special_tokens 不在开头加 special_tokens
^
SyntaxError: invalid syntax这部分代码本身是没有问题的,但是程序就是一直卡在这里,首先怀疑是结构问题,因为数据集的结构是如下结构:
{
"instruction": "计算机科学与技术专业属于哪个学部?",
"input": "",
"output": "计算学部"
}
我以为是因为"input"键的值一直设置为""导致的,所以先尝试修改数据集,将"input"的值全部设置为" ";再次运行代码,仍然报错;修改数据集转换代码,将“input”键直接去掉,无效;最后根据报错信息总是卡在一个点上,而这个点与数据集数量类似,由此推测是原始数据集出现问题,检查原始excel数据集发现数据集中有空行,从而导致报错。
print(exam["instruction"],type(exam["instruction"]))
print(exam["input"],type(exam["input"]))
print(exam["output"],type(exam["output"]))这段代码是用来检查报错信息为'str'+None的,看看是不是数据根本就没有被提取
3、微调完成但实际问答效果不佳
模型加载脚本:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from peft import PeftModel
model_path = '/home/media4090/wz/model/qwen/qwen2-7b-instruct'
lora_path = '/home/media4090/wz/model/QLU/checkpoint-381' # 这里改为你的 lora 输出对应 checkpoint 地址
# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# 加载模型
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True).eval()
# 加载lora权重
model = PeftModel.from_pretrained(model, model_id=lora_path)
# 将模型和分词器移到适当的设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
print("开始对话(输入 '退出' 来结束对话):")
while True:
prompt = input("你:")
if prompt == "退出":
print("对话结束。")
break
inputs = tokenizer.apply_chat_template([{"role": "user", "content": prompt}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True).to(device)
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("模型:", response)加载微调后的模型进行对话,整体效果是驴唇不对马嘴,模型没有正确回答一个问题。即使后面我增加了lora的秩r=16、lora_alpha=64,lora_dropout=0.05以及epoch从3增加到30再到100来提高拟合性,但是感觉模型仍然没有拟合上,即使最后微调的loss是0.17左右

这是epoch是30的时候,但此时没有修改r、lora_alpha、lora_dropout都没有修改
![]()
这是epoch是100的时候,训练了一晚上,r、lora_alpha、lora_dropout的值也都修改过了
四、使用官方提供的微调方式
1、使用官方微调方式
经过咨询,决定使用Qwen2官方微调脚本来试一下:
Qwen2官方链接:https://qwen.readthedocs.io/zh-cn/latest/training/SFT/llama_factory.html
LLaMA-Factory链接:https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md
因为是单卡,所以没有使用DeepSpeed,同时因为flash-attn一直安装不了,所以也没有使用,开始微调命令如下:
python src/train.py \
--do_train \
--use_fast_tokenizer \
--model_name_or_path /home/media4090/wz/model/qwen/qwen2-7b-instruct \
--dataset /home/media4090/wz/code/QLU-alpaca.json \
--template qwen \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--output_dir /home/media4090/wz/model/QLU \
--overwrite_cache \
--overwrite_output_dir \
--warmup_steps 100 \
--weight_decay 0.1 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--ddp_timeout 9000 \
--learning_rate 5e-6 \
--lr_scheduler_type cosine \
--logging_steps 1 \
--cutoff_len 4096 \
--save_steps 1000 \
--plot_loss \
--num_train_epochs 3 \
--bf16 \注意:执行该命令需要在LLaMA-Factory这个目录中

2、数据结构
{
"instruction": "解释一下新生户口迁移事项?",
"input": "",
"output": "新生可自主选择是否办理户口迁移手续。如需要办理迁移,请注意以下事项:户口迁往地址:济南市长清区大学路3501号",
"system": "你是齐鲁工业大学AI助手,你需要回答接下来关于齐鲁工业大学的问题"
},3、官方微调结果
使用官方微调方式的最终结果的如下:

loss曲线
具体参数如下:
"epoch": 2.988235294117647,
"total_flos": 3.974381667095347e+16,
"train_loss": 2.130159845815243,
"train_runtime": 427.3876,
"train_samples_per_second": 14.313,
"train_steps_per_second": 0.891
4、与官方不同之处
DISTRIBUTED_ARGS="
--nproc_per_node $NPROC_PER_NODE \
--nnodes $NNODES \
--node_rank $NODE_RANK \
--master_addr $MASTER_ADDR \
--master_port $MASTER_PORT
"
torchrun $DISTRIBUTED_ARGS src/train.py \
--deepspeed $DS_CONFIG_PATH \
--stage sft \
--do_train \
--use_fast_tokenizer \
--flash_attn \
--model_name_or_path $MODEL_PATH \
--dataset your_dataset \
--template qwen \
--finetuning_type lora \
--lora_target q_proj,v_proj\
--output_dir $OUTPUT_PATH \
--overwrite_cache \
--overwrite_output_dir \
--warmup_steps 100 \
--weight_decay 0.1 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--ddp_timeout 9000 \
--learning_rate 5e-6 \
--lr_scheduler_type cosine \
--logging_steps 1 \
--cutoff_len 4096 \
--save_steps 1000 \
--plot_loss \
--num_train_epochs 3 \
--bf16这是官方的微调命令
去掉关于多卡的内容,直接运行的话会一直报错,报错信息如下:
[2024-08-29 10:38:30,111] [INFO] [real_accelerator.py:203:get_accelerator] Setting ds_accelerator to cuda (auto detect)
usage: train.py [-h] --model_name_or_path MODEL_NAME_OR_PATH [--adapter_name_or_path ADAPTER_NAME_OR_PATH] [--adapter_folder ADAPTER_FOLDER] [--cache_dir CACHE_DIR]
[--use_fast_tokenizer [USE_FAST_TOKENIZER]] [--no_use_fast_tokenizer] [--resize_vocab [RESIZE_VOCAB]] [--split_special_tokens [SPLIT_SPECIAL_TOKENS]]
[--new_special_tokens NEW_SPECIAL_TOKENS] [--model_revision MODEL_REVISION] [--low_cpu_mem_usage [LOW_CPU_MEM_USAGE]] [--no_low_cpu_mem_usage]
[--quantization_method {bitsandbytes,hqq,eetq}] [--quantization_bit QUANTIZATION_BIT] [--quantization_type {fp4,nf4}]
[--double_quantization [DOUBLE_QUANTIZATION]] [--no_double_quantization] [--quantization_device_map {auto}] [--rope_scaling {linear,dynamic}]
[--flash_attn {auto,disabled,sdpa,fa2}] [--shift_attn [SHIFT_ATTN]] [--mixture_of_depths {convert,load}] [--use_unsloth [USE_UNSLOTH]]
[--use_liger_kernel [USE_LIGER_KERNEL]] [--visual_inputs [VISUAL_INPUTS]] [--moe_aux_loss_coef MOE_AUX_LOSS_COEF]
[--disable_gradient_checkpointing [DISABLE_GRADIENT_CHECKPOINTING]] [--upcast_layernorm [UPCAST_LAYERNORM]] [--upcast_lmhead_output [UPCAST_LMHEAD_OUTPUT]]
[--train_from_scratch [TRAIN_FROM_SCRATCH]] [--infer_backend {huggingface,vllm}] [--vllm_maxlen VLLM_MAXLEN] [--vllm_gpu_util VLLM_GPU_UTIL]
[--vllm_enforce_eager [VLLM_ENFORCE_EAGER]] [--vllm_max_lora_rank VLLM_MAX_LORA_RANK] [--offload_folder OFFLOAD_FOLDER] [--use_cache [USE_CACHE]]
[--no_use_cache] [--infer_dtype {auto,float16,bfloat16,float32}] [--hf_hub_token HF_HUB_TOKEN] [--ms_hub_token MS_HUB_TOKEN] [--export_dir EXPORT_DIR]
[--export_size EXPORT_SIZE] [--export_device {cpu,auto}] [--export_quantization_bit EXPORT_QUANTIZATION_BIT]
[--export_quantization_dataset EXPORT_QUANTIZATION_DATASET] [--export_quantization_nsamples EXPORT_QUANTIZATION_NSAMPLES]
[--export_quantization_maxlen EXPORT_QUANTIZATION_MAXLEN] [--export_legacy_format [EXPORT_LEGACY_FORMAT]] [--export_hub_model_id EXPORT_HUB_MODEL_ID]
[--print_param_status [PRINT_PARAM_STATUS]] [--template TEMPLATE] [--dataset DATASET] [--eval_dataset EVAL_DATASET] [--dataset_dir DATASET_DIR]
[--cutoff_len CUTOFF_LEN] [--train_on_prompt [TRAIN_ON_PROMPT]] [--mask_history [MASK_HISTORY]] [--streaming [STREAMING]] [--buffer_size BUFFER_SIZE]
[--mix_strategy {concat,interleave_under,interleave_over}] [--interleave_probs INTERLEAVE_PROBS] [--overwrite_cache [OVERWRITE_CACHE]]
[--preprocessing_num_workers PREPROCESSING_NUM_WORKERS] [--max_samples MAX_SAMPLES] [--eval_num_beams EVAL_NUM_BEAMS]
[--ignore_pad_token_for_loss [IGNORE_PAD_TOKEN_FOR_LOSS]] [--no_ignore_pad_token_for_loss] [--val_size VAL_SIZE] [--packing PACKING]
[--neat_packing [NEAT_PACKING]] [--tool_format TOOL_FORMAT] [--tokenized_path TOKENIZED_PATH] --output_dir OUTPUT_DIR
[--overwrite_output_dir [OVERWRITE_OUTPUT_DIR]] [--do_train [DO_TRAIN]] [--do_eval [DO_EVAL]] [--do_predict [DO_PREDICT]] [--eval_strategy {no,steps,epoch}]
[--prediction_loss_only [PREDICTION_LOSS_ONLY]] [--per_device_train_batch_size PER_DEVICE_TRAIN_BATCH_SIZE]
[--per_device_eval_batch_size PER_DEVICE_EVAL_BATCH_SIZE] [--per_gpu_train_batch_size PER_GPU_TRAIN_BATCH_SIZE]
[--per_gpu_eval_batch_size PER_GPU_EVAL_BATCH_SIZE] [--gradient_accumulation_steps GRADIENT_ACCUMULATION_STEPS]
[--eval_accumulation_steps EVAL_ACCUMULATION_STEPS] [--eval_delay EVAL_DELAY] [--torch_empty_cache_steps TORCH_EMPTY_CACHE_STEPS]
[--learning_rate LEARNING_RATE] [--weight_decay WEIGHT_DECAY] [--adam_beta1 ADAM_BETA1] [--adam_beta2 ADAM_BETA2] [--adam_epsilon ADAM_EPSILON]
[--max_grad_norm MAX_GRAD_NORM] [--num_train_epochs NUM_TRAIN_EPOCHS] [--max_steps MAX_STEPS]
[--lr_scheduler_type {linear,cosine,cosine_with_restarts,polynomial,constant,constant_with_warmup,inverse_sqrt,reduce_lr_on_plateau,cosine_with_min_lr,warmup_stable_decay}]
[--lr_scheduler_kwargs LR_SCHEDULER_KWARGS] [--warmup_ratio WARMUP_RATIO] [--warmup_steps WARMUP_STEPS]
[--log_level {detail,debug,info,warning,error,critical,passive}] [--log_level_replica {detail,debug,info,warning,error,critical,passive}]
[--log_on_each_node [LOG_ON_EACH_NODE]] [--no_log_on_each_node] [--logging_dir LOGGING_DIR] [--logging_strategy {no,steps,epoch}]
[--logging_first_step [LOGGING_FIRST_STEP]] [--logging_steps LOGGING_STEPS] [--logging_nan_inf_filter [LOGGING_NAN_INF_FILTER]] [--no_logging_nan_inf_filter]
[--save_strategy {no,steps,epoch}] [--save_steps SAVE_STEPS] [--save_total_limit SAVE_TOTAL_LIMIT] [--save_safetensors [SAVE_SAFETENSORS]]
[--no_save_safetensors] [--save_on_each_node [SAVE_ON_EACH_NODE]] [--save_only_model [SAVE_ONLY_MODEL]]
[--restore_callback_states_from_checkpoint [RESTORE_CALLBACK_STATES_FROM_CHECKPOINT]] [--no_cuda [NO_CUDA]] [--use_cpu [USE_CPU]]
[--use_mps_device [USE_MPS_DEVICE]] [--seed SEED] [--data_seed DATA_SEED] [--jit_mode_eval [JIT_MODE_EVAL]] [--use_ipex [USE_IPEX]] [--bf16 [BF16]]
[--fp16 [FP16]] [--fp16_opt_level FP16_OPT_LEVEL] [--half_precision_backend {auto,apex,cpu_amp}] [--bf16_full_eval [BF16_FULL_EVAL]]
[--fp16_full_eval [FP16_FULL_EVAL]] [--tf32 TF32] [--local_rank LOCAL_RANK] [--ddp_backend {nccl,gloo,mpi,ccl,hccl,cncl}] [--tpu_num_cores TPU_NUM_CORES]
[--tpu_metrics_debug [TPU_METRICS_DEBUG]] [--debug DEBUG [DEBUG ...]] [--dataloader_drop_last [DATALOADER_DROP_LAST]] [--eval_steps EVAL_STEPS]
[--dataloader_num_workers DATALOADER_NUM_WORKERS] [--dataloader_prefetch_factor DATALOADER_PREFETCH_FACTOR] [--past_index PAST_INDEX] [--run_name RUN_NAME]
[--disable_tqdm DISABLE_TQDM] [--remove_unused_columns [REMOVE_UNUSED_COLUMNS]] [--no_remove_unused_columns] [--label_names LABEL_NAMES [LABEL_NAMES ...]]
[--load_best_model_at_end [LOAD_BEST_MODEL_AT_END]] [--metric_for_best_model METRIC_FOR_BEST_MODEL] [--greater_is_better GREATER_IS_BETTER]
[--ignore_data_skip [IGNORE_DATA_SKIP]] [--fsdp FSDP] [--fsdp_min_num_params FSDP_MIN_NUM_PARAMS] [--fsdp_config FSDP_CONFIG]
[--fsdp_transformer_layer_cls_to_wrap FSDP_TRANSFORMER_LAYER_CLS_TO_WRAP] [--accelerator_config ACCELERATOR_CONFIG] [--deepspeed DEEPSPEED]
[--label_smoothing_factor LABEL_SMOOTHING_FACTOR]
[--optim {adamw_hf,adamw_torch,adamw_torch_fused,adamw_torch_xla,adamw_torch_npu_fused,adamw_apex_fused,adafactor,adamw_anyprecision,sgd,adagrad,adamw_bnb_8bit,adamw_8bit,lion_8bit,lion_32bit,paged_adamw_32bit,paged_adamw_8bit,paged_lion_32bit,paged_lion_8bit,rmsprop,rmsprop_bnb,rmsprop_bnb_8bit,rmsprop_bnb_32bit,galore_adamw,galore_adamw_8bit,galore_adafactor,galore_adamw_layerwise,galore_adamw_8bit_layerwise,galore_adafactor_layerwise,lomo,adalomo}]
[--optim_args OPTIM_ARGS] [--adafactor [ADAFACTOR]] [--group_by_length [GROUP_BY_LENGTH]] [--length_column_name LENGTH_COLUMN_NAME] [--report_to REPORT_TO]
[--ddp_find_unused_parameters DDP_FIND_UNUSED_PARAMETERS] [--ddp_bucket_cap_mb DDP_BUCKET_CAP_MB] [--ddp_broadcast_buffers DDP_BROADCAST_BUFFERS]
[--dataloader_pin_memory [DATALOADER_PIN_MEMORY]] [--no_dataloader_pin_memory] [--dataloader_persistent_workers [DATALOADER_PERSISTENT_WORKERS]]
[--skip_memory_metrics [SKIP_MEMORY_METRICS]] [--no_skip_memory_metrics] [--use_legacy_prediction_loop [USE_LEGACY_PREDICTION_LOOP]]
[--push_to_hub [PUSH_TO_HUB]] [--resume_from_checkpoint RESUME_FROM_CHECKPOINT] [--hub_model_id HUB_MODEL_ID]
[--hub_strategy {end,every_save,checkpoint,all_checkpoints}] [--hub_token HUB_TOKEN] [--hub_private_repo [HUB_PRIVATE_REPO]]
[--hub_always_push [HUB_ALWAYS_PUSH]] [--gradient_checkpointing [GRADIENT_CHECKPOINTING]] [--gradient_checkpointing_kwargs GRADIENT_CHECKPOINTING_KWARGS]
[--include_inputs_for_metrics [INCLUDE_INPUTS_FOR_METRICS]] [--eval_do_concat_batches [EVAL_DO_CONCAT_BATCHES]] [--no_eval_do_concat_batches]
[--fp16_backend {auto,apex,cpu_amp}] [--evaluation_strategy {no,steps,epoch}] [--push_to_hub_model_id PUSH_TO_HUB_MODEL_ID]
[--push_to_hub_organization PUSH_TO_HUB_ORGANIZATION] [--push_to_hub_token PUSH_TO_HUB_TOKEN] [--mp_parameters MP_PARAMETERS]
[--auto_find_batch_size [AUTO_FIND_BATCH_SIZE]] [--full_determinism [FULL_DETERMINISM]] [--torchdynamo TORCHDYNAMO] [--ray_scope RAY_SCOPE]
[--ddp_timeout DDP_TIMEOUT] [--torch_compile [TORCH_COMPILE]] [--torch_compile_backend TORCH_COMPILE_BACKEND] [--torch_compile_mode TORCH_COMPILE_MODE]
[--dispatch_batches DISPATCH_BATCHES] [--split_batches SPLIT_BATCHES] [--include_tokens_per_second [INCLUDE_TOKENS_PER_SECOND]]
[--include_num_input_tokens_seen [INCLUDE_NUM_INPUT_TOKENS_SEEN]] [--neftune_noise_alpha NEFTUNE_NOISE_ALPHA] [--optim_target_modules OPTIM_TARGET_MODULES]
[--batch_eval_metrics [BATCH_EVAL_METRICS]] [--eval_on_start [EVAL_ON_START]] [--eval_use_gather_object [EVAL_USE_GATHER_OBJECT]]
[--sortish_sampler [SORTISH_SAMPLER]] [--predict_with_generate [PREDICT_WITH_GENERATE]] [--generation_max_length GENERATION_MAX_LENGTH]
[--generation_num_beams GENERATION_NUM_BEAMS] [--generation_config GENERATION_CONFIG] [--use_badam [USE_BADAM]] [--badam_mode {layer,ratio}]
[--badam_start_block BADAM_START_BLOCK] [--badam_switch_mode {ascending,descending,random,fixed}] [--badam_switch_interval BADAM_SWITCH_INTERVAL]
[--badam_update_ratio BADAM_UPDATE_RATIO] [--badam_mask_mode {adjacent,scatter}] [--badam_verbose BADAM_VERBOSE] [--use_galore [USE_GALORE]]
[--galore_target GALORE_TARGET] [--galore_rank GALORE_RANK] [--galore_update_interval GALORE_UPDATE_INTERVAL] [--galore_scale GALORE_SCALE]
[--galore_proj_type {std,reverse_std,right,left,full}] [--galore_layerwise [GALORE_LAYERWISE]] [--pref_beta PREF_BETA] [--pref_ftx PREF_FTX]
[--pref_loss {sigmoid,hinge,ipo,kto_pair,orpo,simpo}] [--dpo_label_smoothing DPO_LABEL_SMOOTHING] [--kto_chosen_weight KTO_CHOSEN_WEIGHT]
[--kto_rejected_weight KTO_REJECTED_WEIGHT] [--simpo_gamma SIMPO_GAMMA] [--ppo_buffer_size PPO_BUFFER_SIZE] [--ppo_epochs PPO_EPOCHS]
[--ppo_score_norm [PPO_SCORE_NORM]] [--ppo_target PPO_TARGET] [--ppo_whiten_rewards [PPO_WHITEN_REWARDS]] [--ref_model REF_MODEL]
[--ref_model_adapters REF_MODEL_ADAPTERS] [--ref_model_quantization_bit REF_MODEL_QUANTIZATION_BIT] [--reward_model REWARD_MODEL]
[--reward_model_adapters REWARD_MODEL_ADAPTERS] [--reward_model_quantization_bit REWARD_MODEL_QUANTIZATION_BIT] [--reward_model_type {lora,full,api}]
[--additional_target ADDITIONAL_TARGET] [--lora_alpha LORA_ALPHA] [--lora_dropout LORA_DROPOUT] [--lora_rank LORA_RANK] [--lora_target LORA_TARGET]
[--loraplus_lr_ratio LORAPLUS_LR_RATIO] [--loraplus_lr_embedding LORAPLUS_LR_EMBEDDING] [--use_rslora [USE_RSLORA]] [--use_dora [USE_DORA]]
[--pissa_init [PISSA_INIT]] [--pissa_iter PISSA_ITER] [--pissa_convert [PISSA_CONVERT]] [--create_new_adapter [CREATE_NEW_ADAPTER]]
[--freeze_trainable_layers FREEZE_TRAINABLE_LAYERS] [--freeze_trainable_modules FREEZE_TRAINABLE_MODULES] [--freeze_extra_modules FREEZE_EXTRA_MODULES]
[--pure_bf16 [PURE_BF16]] [--stage {pt,sft,rm,ppo,dpo,kto}] [--finetuning_type {lora,freeze,full}] [--use_llama_pro [USE_LLAMA_PRO]]
[--use_adam_mini [USE_ADAM_MINI]] [--freeze_vision_tower [FREEZE_VISION_TOWER]] [--no_freeze_vision_tower] [--train_mm_proj_only [TRAIN_MM_PROJ_ONLY]]
[--compute_accuracy [COMPUTE_ACCURACY]] [--plot_loss [PLOT_LOSS]] [--do_sample [DO_SAMPLE]] [--no_do_sample] [--temperature TEMPERATURE] [--top_p TOP_P]
[--top_k TOP_K] [--num_beams NUM_BEAMS] [--max_length MAX_LENGTH] [--max_new_tokens MAX_NEW_TOKENS] [--repetition_penalty REPETITION_PENALTY]
[--length_penalty LENGTH_PENALTY] [--default_system DEFAULT_SYSTEM]
train.py: error: the following arguments are required: --model_name_or_path, --output_dir
(wz) media4090@media4090-Super-Server:~/wz/LLaMA-Factory$ --stage sft \
> --do_train \
> --use_fast_tokenizer \
> --model_name_or_path /home/media4090/wz/model/qwen/qwen2-7b-instruct \
> --dataset /home/media4090/wz/code/QLU-alpaca.json \
> --template qwen \
> --finetuning_type lora \
> --lora_target q_proj,v_proj\
> --output_dir /home/media4090/wz/model/QLU-AI \
> --overwrite_cache \
> --overwrite_output_dir \
> --warmup_steps 100 \
> --weight_decay 0.1 \
> --per_device_train_batch_size 4 \
> --gradient_accumulation_steps 4 \
> --ddp_timeout 9000 \
> --learning_rate 5e-6 \
> --lr_scheduler_type cosine \
> --logging_steps 1 \
> --cutoff_len 4096 \
> --save_steps 1000 \
> --plot_loss \
> --num_train_epochs 3 \
> --bf16 \
--stage:未找到命令官方命令中--stage sft \这个参数不能被识别,具体作用尚不得知
五、官方微调出现问题及解决
1、加载数据集的时候直接加载
根据上文,在微调命令中已经添加了数据集路径,但是仍然报错
报错信息:
ValueError: Undefined dataset /home/media4090/wz/code/QLU-alpaca.json in dataset_info.json.这个报错信息提示在dataset_info.json中没有找到数据集的信息,由此可以判断出LLaMA-Factory读取数据集是从这个文件读取的
解决方法:
在LLaMA/data目录下的dataset_info.json文件中添加上数据集,如图

因为刚接触LLaMA-Factory,所以并不知道具体数据集该怎么添加,这里只是保证不报错
2、使用原模型加载脚本效果仍然不佳
如图:

模型对话仍然是驴唇不对马嘴
3、使用官方整合模型命令时报错
CUDA_VISIBLE_DEVICES=0 llamafactory-cli export \
--model_name_or_path path_to_base_model \
--adapter_name_or_path path_to_adapter \
--template qwen \
--finetuning_type lora \
--export_dir path_to_export \
--export_size 2 \
--export_legacy_format False官方命令
CUDA_VISIBLE_DEVICES=0 llamafactory-cli export \
--model_name_or_path /home/media4090/wz/model/qwen/qwen2-7b-instruct \
--adapter_name_or_path /home/media4090/wz/model/QLU/checkpoint-381 \
--template qwen \
--finetuning_type lora \
--export_dir /home/media4090/wz/model/AI-QLU \
--export_size 2 \
--export_legacy_format False修改后的命令
报错信息如下:
Traceback (most recent call last):
File "/home/media4090/.conda/envs/wz/bin/llamafactory-cli", line 5, in <module>
from llamafactory.cli import main
ModuleNotFoundError: No module named 'llamafactory'
上述报错表示识别不到llamafactory,但是pip install llamafactory显示已经安装
解决方法:重新下载llamafactory
六、加载整合后的模型
目前尚未完成

![[动态规划]---背包问题](https://i-blog.csdnimg.cn/direct/2347d7b53bb245daad63ca352abac3ac.png)