在竞争激烈的消费金融市场中,有效利用海量数据、提升业务运营效率是赢得市场的关键。早期招联采用典型的 Lambda 架构提供业务报表、数据运营、个性推荐、风险控制等数据服务,而 Lambda 过多的技术栈也引发了数据孤岛、查询效率不足、代码复用性差以及开发运维成本高昂等诸多问题。因此,招联引入 Apache Doris 对架构进行了升级,不仅替换了冗余的技术栈,还实现了实时数仓存储和计算引擎的统一,从而大幅精简了整体架构。
如今,招联内部已有 40+ 个项目使用 Apache Doris ,拥有超百台集群节点,个别集群峰值 QPS 可达 10w+ 。通过应用 Doris ,招联金融在多场景中均有显著的收益,比如标签关联计算效率相较之前有 6 倍的提升,同等规模数据存储成本节省超 2/3,真正实现了降本提效。
存在的问题
早期架构由实时数仓和离线数仓两套组成,是较为典型的 Lambda 架构。由于历史原因,整个架构非常复杂,用到 Hbase、kafka、Clickhouse、 Spark、Impala、Hive、Kudu、Vertica 等多种技术栈。
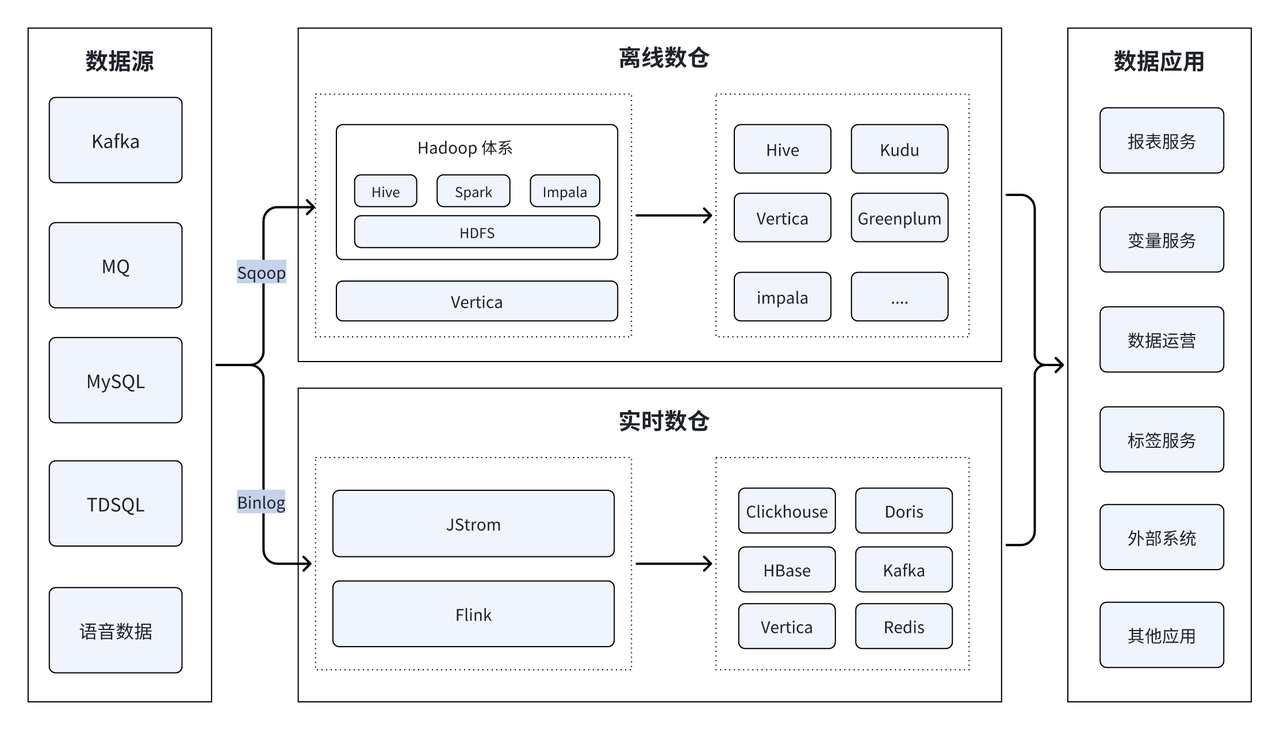
该架构虽功能完备,但由于其技术栈的复杂度及能力的局限性也带来了诸多问题:
- 运维依赖性高:Lambda 架构包含较多的技术组件,且部分组件为闭源、内部逻辑不透明,强依赖厂家技术支持。
- 资源利用率低:实时及离线两套架构间代码无法复用,这无疑增加了维护成本;且两套架构间资源无法合理共享和调度、数据无法复用,资源利用率非常低。
- 数据时效性低:组件多、数据处理链路也长,多组件数据传输影响了时效性,降低了数据查询的效率。
- 并发能力弱: Vertica、Impala 等部分查询引擎无法应对高并发场景的需求。
升级目标
基于以上待解决的问题,招联对未来即将升级的新架构提出了几点要求:
- 架构简化:精简架构,统一组件标准,解决不同架构间兼容性问题;尽量采用开源软件,底层逻辑透明化,确保平台升级迭代可控,降低运维成本及难度。
- 混合部署与弹性伸缩:需要满足在线混合部署的使用条件,支持弹性扩容,最大化资源利用率,实现降本增效。
- 实时分析:搭建高性能实时数仓能力,可支持上万超高 QPS、秒级别查询响应,实现数据分析实时化。
在上述目标驱使下,招联迅速定位到 Apache Doris 这一开源实时数据仓库 ,Doris 以其简洁的架构设计、丰富的数据接口、高效的查询性能以及低廉的运维成本深得内部认可,可为后续的升级和优化提供强有力的技术支撑。
数仓生态全新升级
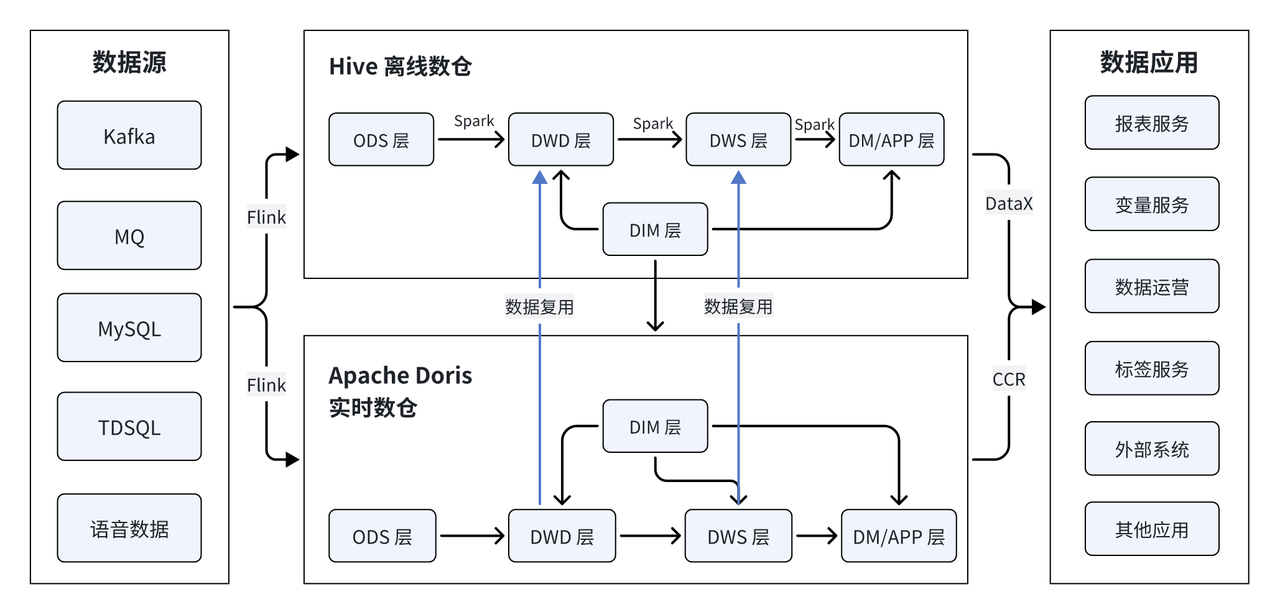
基于 Apache Doris 的数仓生态相较于旧架构实现了极大的精简。主要变动集中在实时数仓部分,使用 Doris 替代了原先 Clickhouse、Hbase、Kafka、Vertica 等复杂的技术栈。
尽管当前架构仍然保留了离线和实时两套处理链路,但在系统设计上实现了高度的代码可复用性,Doris 实时数仓所有代码均可从离线数仓 1:1 复制,以保证两套架构的逻辑一致性和维护便捷性。不仅如此,数据也最大程度在实时及离线数仓中进行了复用,当数据进入实时数仓,经过 DWD 层、DWS 层加工处理后会同时同步到离线数仓中,既提高了数据的时效性,又确保了两套架构数据的一致性。
Apache Doris 的引入,不仅大幅简化了数仓生态整体架构,硬件成本也实现约 10% 的降低(如累加开发、运维成本,将有更大比例的节约)。同时,得益于代码和数据的高复用率,架构的运维管理也变得便捷高效。
基于 Apache Doris 的实时数仓
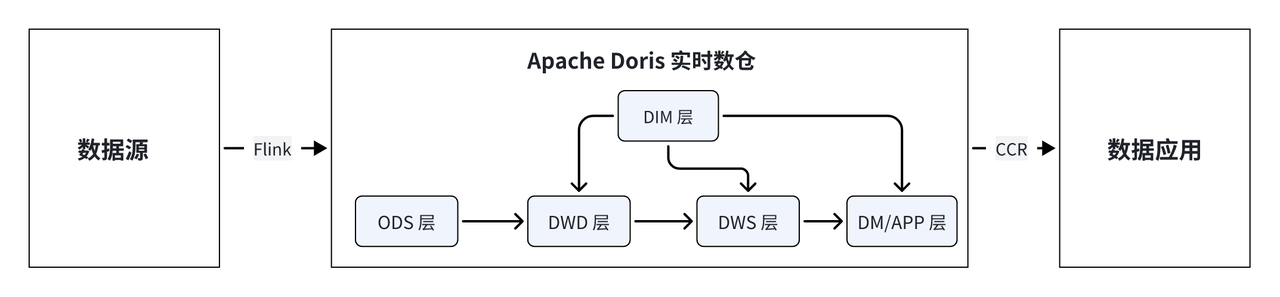
具体到实时数仓来说,原先由 Flink、 Kafka 、HBase 应对实时场景,Clickhouse 、Vertica 及部分 Doris 能力应对准实时场景。当前只保留 Flink 进行数据采集,其他组件均替换为 Doris, Flink 采集数据到 Doris 中,经由 ODS、DWD、DWS、DM/APP 层处理后,由 Doris 直接提供查询及分析服务。
此外,存储和计算引擎也都统一到 Doris,并通过 CCR 实现 Doris 集群读写分离和数据同步,避免单点压力过大导致系统性能下降,提高了数据查询效率以及系统的稳定性。
如何避免数据乱序:
- Watermark 机制:实时数仓中,Flink 负责将 ODS 中数据消费到 Doris 中,为避免该过程出现数据乱序,可利用 Watermark 机制来容忍数据迟到,确保数据的时效性和正确性。
- 任务串行: 为确保数据的连续性,在调度系统中实现了多批次任务串行机制,上一批次任务未完成时,下一批次就不会开始。同时引入动态窗口机制,每当发起任务时,会自动获取上一批次最新业务节点到此刻时间节点之间的数据,既能保证了批次之间的相互独立,又确保了数据处理的连续性和时效性。
01 客群筛选场景
在市场营销、风险控制等精细化数据运营中,客群筛选是确认目标人群、制定营销策略的重要手段。
在客群筛选过程中,通常需要对集市中多张标签表进行关联计算,大约需要处理 2.4 亿条数据。之前使用 Vertica 计算引擎进行处理时,耗时 30-60 分钟;替换为 Doris 之后,仅用时 5-10 分钟即可完成,相较之前有 6 倍的性能提升。除了显著的性能提升外,Doris 作为一款开源的数据库,无需支付任何许可费用,这与商业化产品 Vertica 相比有着显著的成本优势。
02 高频点查场景
对于某场景需求,招联需确保系统的 QPS(每秒查询次数)达到 10万次,同时,单次接口响应时间不能超过 60 ms。这意味着,除去网络传输与程序逻辑处理的耗时后,数据查询耗时需控制在 15 ms 内,对系统的性能要求十分严苛。此外,系统还承载着每日庞大的数据更新任务,最大更新量高达 20 亿条,这要求系统不仅能应对高并发,还要确保在高负载下依然能够稳定运行。
之前招联使用 Redis 来应对高并发需求,其并发能力和稳定性基本可以满足要求。但 Redis 的核心问题在于使用成本非常高昂。相比之下,Doris 不仅能够支持单节点上万 QPS 的超高并发,也具备大规模数据的快速写入能力,2000 万数据仅需 4 分钟即可写入完成。最为关键的是,Doris 在成本方面展现出非常显著的优势。
在处理同等规模的数据量时,Doris 仅需 Redis 1/3 的内存,实现存储成本的大幅降低与效率的显著提升,真正做到了降本增效。
数据传输场景
从前文可知,依托于 Doris 跨集群数据复制(CCR)能力,已实现 Doris 集群读写分离;另外,因招联内部业务已大范围应用 Doris, CCR 也成为数据库间数据传输的必然选择。
Apache Doris 跨集群数据复制 CCR 能够在库/表级别将源集群的数据变更同步到目标集群,可用于提升在线服务的数据可用性、隔离在离线负载、建设两地三中心等。详情可参考往期技术解析博客:跨集群复制功能 CCR
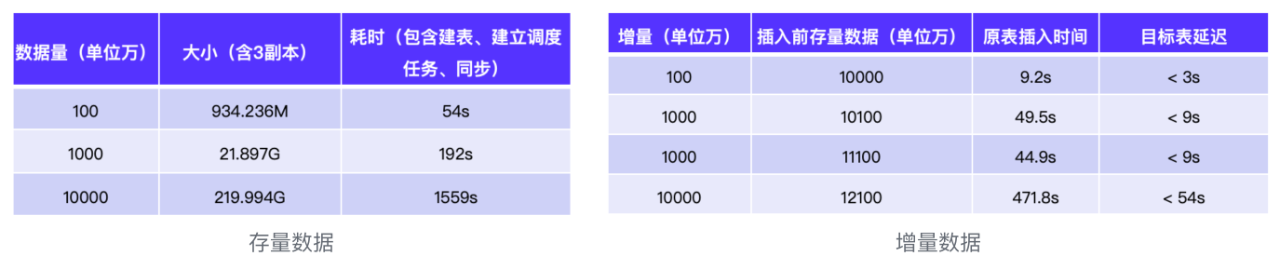
从测试数据来可知 CCR 传输效果:
-
存量数据:对于千万级数据,可在几分钟内完成同步;对于亿级别的数据,也可在预期范围内完成,比如 1 亿数据约为 220G,使用 CCR 仅耗时 1500+ 秒(25分钟)。
-
增量数据:增量数据的同步性能则更加优异,千万级增量数据同步 1 分钟内即可完成,亿级别数据同步仅需不到 8分钟。
经验分享
1. CCR 超时: (TRollbackTxnResult_({Status:TStatus({StatusCode:OK ErrorMsgs:[l}) MasterAdd ress:<nil>}) )
网络波动存在丢包导致 RPC 超时,为确保网络稳定,可升级 CCR 版本至 2.1.4 版本可支持设置 RPC 超时时间。
2. Create table as 语法导致的 slot 一系列问题:
2.0 版本在处理 create table as 语句时,采用的是旧执行优化器,而因旧执行优化器为列字段裁剪,普遍存在 slot 相关问题。升级为 2.1 以上版本后,slot 相关问题得以解决;可以创建临时表 xxx,执行 set enable_nereids_dml = ‘true’来规避该问题。
结束语
截止当前,招联金融内部已有 40+ 个项目接入 Apache Doris ,总集群数近十个,集群节点超百个,某集群峰值 QPS 可达 10w+ 。未来,招联还将持续推广 Apache Doris 在内部的使用范围,并将对存算分离、数据湖能力进行探索及应用:
-
存算分离架构:正在探索推进中,未来将尝试基于 Apache Doris 3.0 新版本进行整体架构升级演进,以支持更灵活的弹性部署、降低运维成本。
-
数据湖分析:未来希望借助 Doris 数据湖的能力,统一开发管理工具,满足多源异构数据的存储和分析需求;统一数据访问接口,提升异构数据访问效率;基于丰富数据管理能力,提升数据质量;并将利用 Doris 特性加速数据湖上查询效率。