《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
一、AI应用软件开发实战专栏【链接】
| 项目名称 | 项目名称 |
|---|---|
| 1.【人脸识别与管理系统开发】 | 2.【车牌识别与自动收费管理系统开发】 |
| 3.【手势识别系统开发】 | 4.【人脸面部活体检测系统开发】 |
| 5.【图片风格快速迁移软件开发】 | 6.【人脸表表情识别系统】 |
| 7.【YOLOv8多目标识别与自动标注软件开发】 | 8.【基于YOLOv8深度学习的行人跌倒检测系统】 |
| 9.【基于YOLOv8深度学习的PCB板缺陷检测系统】 | 10.【基于YOLOv8深度学习的生活垃圾分类目标检测系统】 |
| 11.【基于YOLOv8深度学习的安全帽目标检测系统】 | 12.【基于YOLOv8深度学习的120种犬类检测与识别系统】 |
| 13.【基于YOLOv8深度学习的路面坑洞检测系统】 | 14.【基于YOLOv8深度学习的火焰烟雾检测系统】 |
| 15.【基于YOLOv8深度学习的钢材表面缺陷检测系统】 | 16.【基于YOLOv8深度学习的舰船目标分类检测系统】 |
| 17.【基于YOLOv8深度学习的西红柿成熟度检测系统】 | 18.【基于YOLOv8深度学习的血细胞检测与计数系统】 |
| 19.【基于YOLOv8深度学习的吸烟/抽烟行为检测系统】 | 20.【基于YOLOv8深度学习的水稻害虫检测与识别系统】 |
| 21.【基于YOLOv8深度学习的高精度车辆行人检测与计数系统】 | 22.【基于YOLOv8深度学习的路面标志线检测与识别系统】 |
| 23.【基于YOLOv8深度学习的智能小麦害虫检测识别系统】 | 24.【基于YOLOv8深度学习的智能玉米害虫检测识别系统】 |
| 25.【基于YOLOv8深度学习的200种鸟类智能检测与识别系统】 | 26.【基于YOLOv8深度学习的45种交通标志智能检测与识别系统】 |
| 27.【基于YOLOv8深度学习的人脸面部表情识别系统】 | 28.【基于YOLOv8深度学习的苹果叶片病害智能诊断系统】 |
| 29.【基于YOLOv8深度学习的智能肺炎诊断系统】 | 30.【基于YOLOv8深度学习的葡萄簇目标检测系统】 |
| 31.【基于YOLOv8深度学习的100种中草药智能识别系统】 | 32.【基于YOLOv8深度学习的102种花卉智能识别系统】 |
| 33.【基于YOLOv8深度学习的100种蝴蝶智能识别系统】 | 34.【基于YOLOv8深度学习的水稻叶片病害智能诊断系统】 |
| 35.【基于YOLOv8与ByteTrack的车辆行人多目标检测与追踪系统】 | 36.【基于YOLOv8深度学习的智能草莓病害检测与分割系统】 |
| 37.【基于YOLOv8深度学习的复杂场景下船舶目标检测系统】 | 38.【基于YOLOv8深度学习的农作物幼苗与杂草检测系统】 |
| 39.【基于YOLOv8深度学习的智能道路裂缝检测与分析系统】 | 40.【基于YOLOv8深度学习的葡萄病害智能诊断与防治系统】 |
| 41.【基于YOLOv8深度学习的遥感地理空间物体检测系统】 | 42.【基于YOLOv8深度学习的无人机视角地面物体检测系统】 |
| 43.【基于YOLOv8深度学习的木薯病害智能诊断与防治系统】 | 44.【基于YOLOv8深度学习的野外火焰烟雾检测系统】 |
| 45.【基于YOLOv8深度学习的脑肿瘤智能检测系统】 | 46.【基于YOLOv8深度学习的玉米叶片病害智能诊断与防治系统】 |
| 47.【基于YOLOv8深度学习的橙子病害智能诊断与防治系统】 | 48.【车辆检测追踪与流量计数系统】 |
| 49.【行人检测追踪与双向流量计数系统】 | 50.【基于YOLOv8深度学习的反光衣检测与预警系统】 |
| 51.【危险区域人员闯入检测与报警系统】 | 52.【高密度人脸智能检测与统计系统】 |
| 53.【CT扫描图像肾结石智能检测系统】 | 54.【水果智能检测系统】 |
| 55.【水果质量好坏智能检测系统】 | 56.【蔬菜目标检测与识别系统】 |
| 57.【非机动车驾驶员头盔检测系统】 | 58.【太阳能电池板检测与分析系统】 |
| 59.【工业螺栓螺母检测】 | 60.【金属焊缝缺陷检测系统】 |
| 61.【链条缺陷检测与识别系统】 | 62.【交通信号灯检测识别】 |
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
- 1)线性回归
- 使用案例:
- 现实生活中的例子:
- 2)Logistic回归
- 使用案例:
- 现实生活中的例子:
- 3)决策树
- 示例-让我们使用scikit在iris数据集上实现决策树分类器
- 使用案例:
- 现实生活中的例子:
- 4)随机森林
- 评估指标:
- 示例-让我们实现一个随机森林分类器
- 使用案例:
- 现实生活中的例子:
- 5)K-最近邻
- 使用案例:
- 现实生活中的例子:
- 总结
本文主要介绍5个适合初学者学习的5个常用机器学习算法,包括线性回归、逻辑回归、决策树、随机森林和K近邻。每一个算法包含详细的示例供小伙伴学习参考
1)线性回归
线性回归是一种基于一个或多个输入因素预测连续结果的方法。简单地说,它通过对我们所拥有的数据拟合一条直线来帮助我们找到不同变量之间的关系。
请不要太激动,我会用更简单的方式来解释。
假设我想猜卖柠檬水能赚多少钱,这取决于我卖了多少杯。线性回归查看过去的销售额(我以前卖了多少杯,赚了多少钱),并找到最符合这些信息的直线。这条线将帮助我预测多少钱,我会在未来的基础上,我计划出售的杯子数量。“这就像用过去的经验来猜测未来。”下面是一个线性回归图的例子**-**
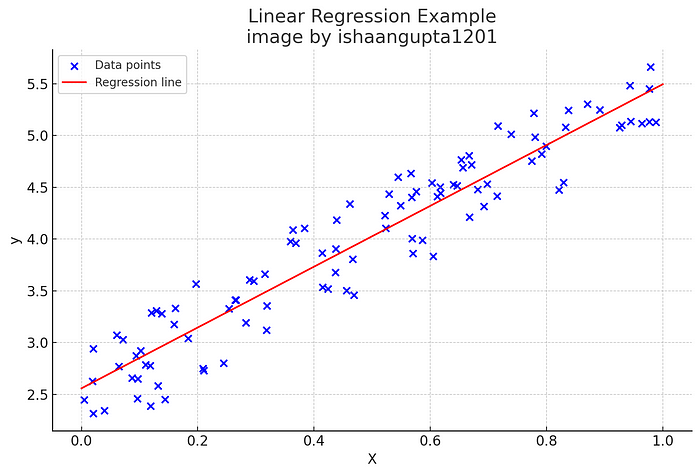
线性回归是关于找到适合一组数据点的最佳直线(回归线)。这条线由以下等式表示:
y = mx + b
其中:
- y是因变量(我们试图预测的)
- x是独立变量
- m是直线的斜率
- B是y轴截距
*对于多个自变量,我们使用多元线性回归:*
y = b0 + b1*1 + b2*2 +.+ bn*xn
b0是y轴截距,b1,b2,…,bn是每个自变量的系数。
对于上图中的图形,我已经编写了一个基本的示例代码,并在下面进行了解释。
# Importing Libraries
import numpy as np
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
# ensures that the random numbers generated are the same every time the code runs.
np.random.seed(0)
#creates an array of 100 random numbers between 0 and 1.
X = np.random.rand(100, 1)
#generates the target variable y using the linear relationship y = 2 + 3*X plus some random noise. This mimics real-world data that might not fit perfectly on a line.
y = 2 + 3 * X + np.random.rand(100, 1)
# Create and fit the model
model = LinearRegression()
# fit means it calculates the best-fitting line through the data points.
model.fit(X, y)
# Make predictions
X_test = np.array([[0], [1]]) #creates a test set with two points: 0 and 1
y_pred = model.predict(X_test) # uses the fitted model to predict the y values for X_test
# Plot the results
plt.figure(figsize=(10, 6))
plt.scatter(X, y, color='b', label='Data points')
plt.plot(X_test, y_pred, color='r', label='Regression line')
plt.legend()
plt.xlabel('X')
plt.ylabel('y')
plt.title('Linear Regression Example\nimage by ishaangupta1201')
plt.show()
print(f"Intercept: {model.intercept_[0]:.2f}")
print(f"Coefficient: {model.coef_[0][0]:.2f}")
使用案例:
- 房价预测:像上面的例子,预测房价的基础上的功能,如大小,卧室数量,位置,等.
- 销售预测:根据过去的数据预测未来的销售。
- 风险管理:根据客户的收入,信用评分等评估贷款风险。
现实生活中的例子:
在医疗保健中,线性回归用于预测患者在医院的住院时间。年龄、疾病严重程度等因素可以作为自变量来预测患者的住院时间。这有助于医院规划其资源,并确保他们有足够的床位和工作人员来照顾病人。
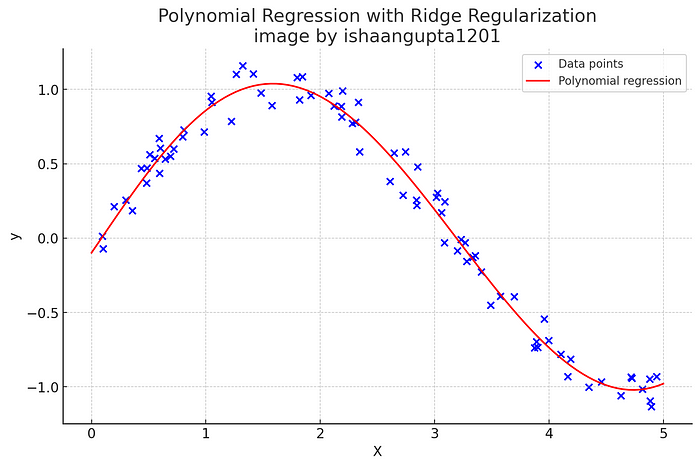
现在你一定在想,如果有"线性回归",那么一定有类似"多项式回归"的东西。是的,你猜对了,也有一种叫做多项式回归的东西。*所以当变量之间的关系不是线性的时候,我们可以用多项式回归来解决复杂的模式。*例如-
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import Ridge
np.random.seed(0)
X = np.sort(5 * np.random.rand(80, 1), axis=0)
y = np.sin(X).ravel() + np.random.normal(0, 0.1, X.shape[0])
degree = 5
model = make_pipeline(PolynomialFeatures(degree), Ridge(alpha=1e-3))
model.fit(X, y)
X_test = np.linspace(0, 5, 100)[:, np.newaxis]
y_pred = model.predict(X_test)
plt.scatter(X, y, color='b', label='Data points')
plt.plot(X_test, y_pred, color='r', label='Polynomial regression')
plt.legend()
plt.xlabel('X')
plt.ylabel('y')
plt.title('Polynomial Regression with Ridge Regularization')
plt.show()
2)Logistic回归
逻辑回归是一种分类算法,比回归算法(丫我知道名字说回归)。它用于预测给定一组自变量的二元结果***(1 / 0,是/否,真/假)***。
所以基本上把它想象成一种用来把事情分成两组的方法,比如是/否或真/假。假设你想根据今天的天气预测明天是否会下雨(是或否)。逻辑回归使用一个称为sigmoid函数的特殊公式,将任何输入转换为0和1之间的概率,表示概率。如果输出接近1,下雨的可能性更大;如果输出接近0,可能不会下雨。当概率达到0.5时,我们从预测“否”切换到“是”,这被称为决策边界。
逻辑函数(sigmoid)用于将预测值映射到概率。
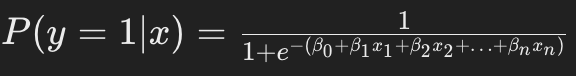
这里,*P(y=1 <$x)P(y=1| x)*是目标变量为1(正类)的概率。
好了,现在让我们为一个简单的分类任务实现它,我们将根据学生学习的小时数来预测他们是通过还是失败:
# Importing Libraries
import numpy as np
from sklearn.linear_model import LogisticRegression
# Sample data: hours studied and pass/fail outcome
hours_studied = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1)
outcome = np.array([0, 0, 0, 0, 0, 1, 1, 1, 1, 1])
# Create and train the model
model = LogisticRegression()
model.fit(hours_studied, outcome)
# This results in an array of predicted binary outcomes (0 or 1).
predicted_outcome = model.predict(hours_studied)
# This results in an array where each sub-array contains two probabilities: the probability of failing and the probability of passing.
predicted_probabilities = model.predict_proba(hours_studied)
print("Predicted Outcomes:", predicted_outcome)
print("Predicted Probabilities:", predicted_probabilities)
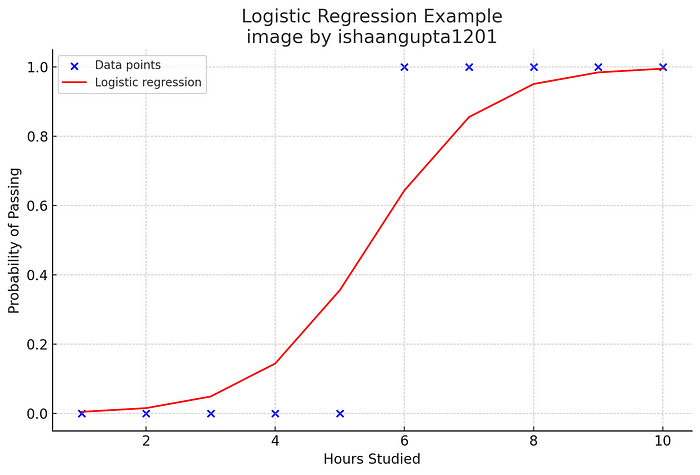
使用案例:
- **电子邮件垃圾邮件检测:**根据电子邮件的内容和其他详细信息将其分类为垃圾邮件或非垃圾邮件。
- **信用卡欺诈检测:**根据消费模式和其他交易详细信息识别欺诈交易。
- **疾病诊断:**根据症状和患者数据预测疾病的存在。
现实生活中的例子:
在金融领域,逻辑回归主要用于信用评分。银行和信用卡公司使用这种算法来评估贷款申请人的信誉。他们考虑收入、工作历史、当前债务和信用记录等因素来预测客户拖欠贷款的可能性。
3)决策树
决策树用于分类和回归任务。他们通过创建一个模型来工作,该模型基于一系列简单的决策进行预测-例如遵循树上的路径。
决策树就像一个问题游戏,你问一系列是/否的问题来猜测一些事情。你可以从一个有两种可能性的问题开始,比如“下雨了吗?”或不”。根据答案,你会问一个又一个问题,直到你把它缩小到最后的决定。在这棵树中,每个问题都是一个分支,而最终的答案是一片叶子。该树根据它给出的数据“学习”最好的问题,使其成为决策的强大工具。
示例-让我们使用scikit在iris数据集上实现决策树分类器
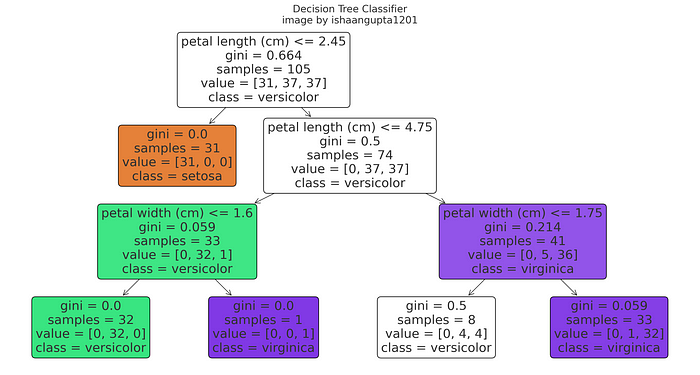
# importing libs
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
# Load the iris dataset
iris = load_iris()
X, y = iris.data, iris.target
# splits the data into training and testing sets. 30% of the data is used for testing (test_size=0.3), and the rest for training. random_state=42 ensures the split is reproducible.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# creates a decision tree classifier with a maximum depth of 3 levels and a fixed random state for reproducibility.
model = DecisionTreeClassifier(max_depth=3, random_state=42)
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Evaluate the model
accuracy = accuracy_score(y_test, y_pred) #calculates the accuracy of the model’s predictions.
print(f"Accuracy: {accuracy:.2f}")
print("\nClassification Report:")
print(classification_report(y_test, y_pred, target_names=iris.target_names))
# Visualize the tree
plt.figure(figsize=(20,10))
plot_tree(model, feature_names=iris.feature_names, class_names=iris.target_names, filled=True, rounded=True)
plt.show()
使用案例:
- **客户流失预测:**帮助公司了解客户可能离开的原因
- **医疗诊断:**根据症状和患者数据预测疾病的可能性。
- 风险评估:银行评估申请人的风险水平,帮助他们决定是否批准保单或贷款。
现实生活中的例子:
基于决策树的概念,我们有随机森林。随机森林就像一个决策树团队一起工作。随机森林不依赖于单个决策树,这有时可能会出错,而是创建许多树,然后联合收割机组合它们的预测。例如,它可以用来指导心脏病的诊断,根据年龄,血压,胆固醇水平和运动习惯等因素。树中的每个节点代表一个测试或问题,根据结果导致不同的分支,最终得出诊断或建议进行进一步的测试。
4)随机森林
随机森林是一种集成学习方法,通过构建多个决策树并结合它们的结果来帮助我们做出更准确的预测。这就像有一群朋友,每个人都给你他们对某事的意见,然后你联合收割机结合他们的答案做出最后的决定。随机森林不是只依赖一棵决策树(这可能会出错),而是创建许多树,每棵树都查看数据的不同部分。通过对回归任务的结果进行平均或对分类任务进行多数投票,随机森林减少了错误,使预测更加可靠。
评估指标:
- 分类:准确度,精确度,召回率,F1分数。
- 回归:均方误差(MSE),R平方。
想象一下,你想猜测某件事的结果,你问了一群朋友的意见,而不是一个朋友。每个朋友看问题的不同部分,并给出他们的答案。随机森林的工作原理类似于创建许多决策树,每个决策树查看数据的不同部分。然后,它将他们的答案结合起来,做出最终的预测。这种方法有助于避免我们只依赖一棵树可能发生的错误,使预测更加准确和可靠。
示例-让我们实现一个随机森林分类器
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
import seaborn as sns
# Generate a random classification dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15,
n_redundant=5, n_classes=3, random_state=42)
# Split the data into training (70%) and testing (30%) sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# random forest classifier with 100 decision trees (n_estimators=100).
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Evaluate the model
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
# Plot confusion matrix
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(10,8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
# Feature importance
importances = model.feature_importances_
indices = np.argsort(importances)[::-1]
plt.figure(figsize=(10,6))
plt.title("Feature Importances")
plt.bar(range(X.shape[1]), importances[indices])
plt.xticks(range(X.shape[1]), indices)
plt.tight_layout()
plt.show()
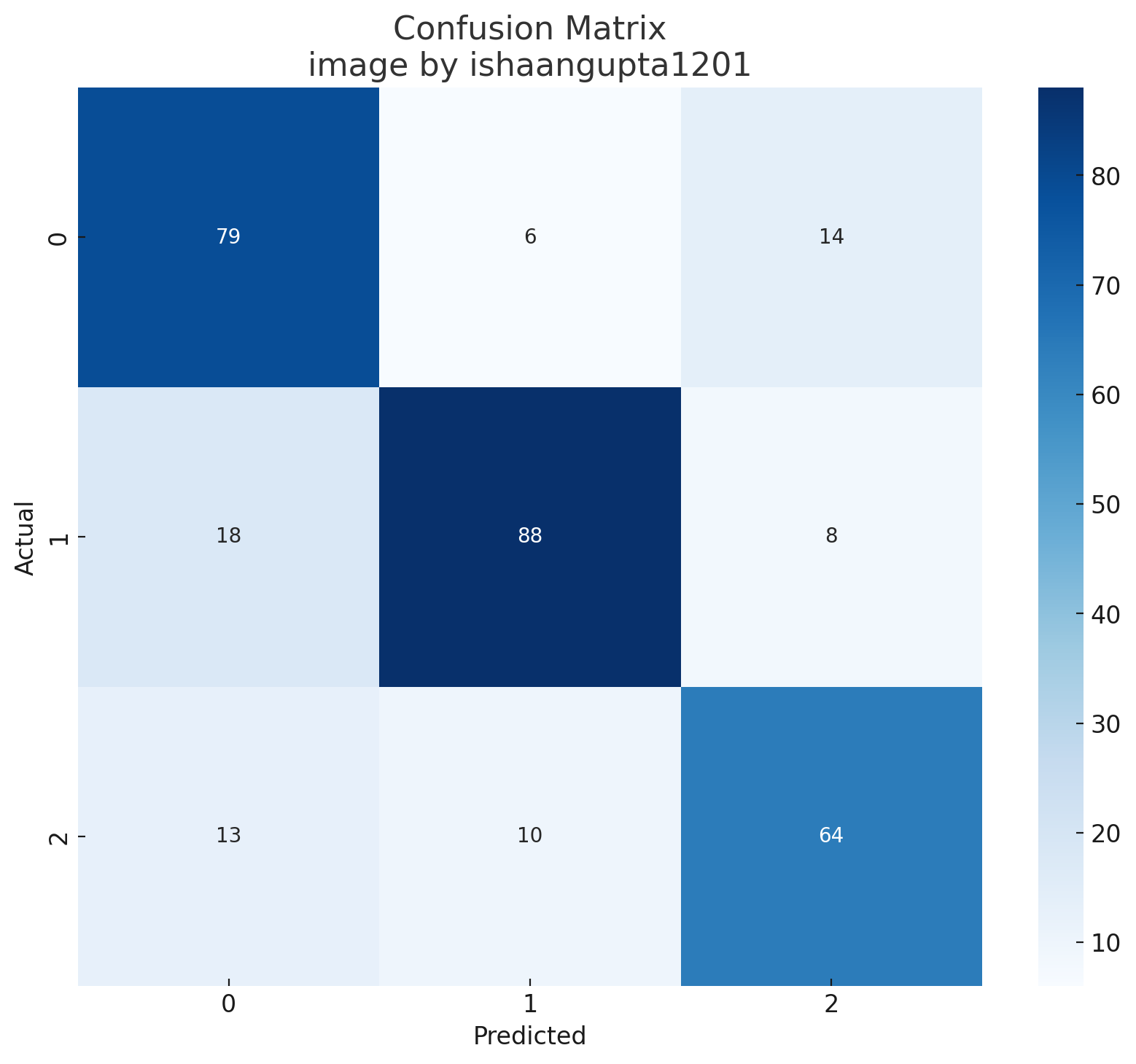
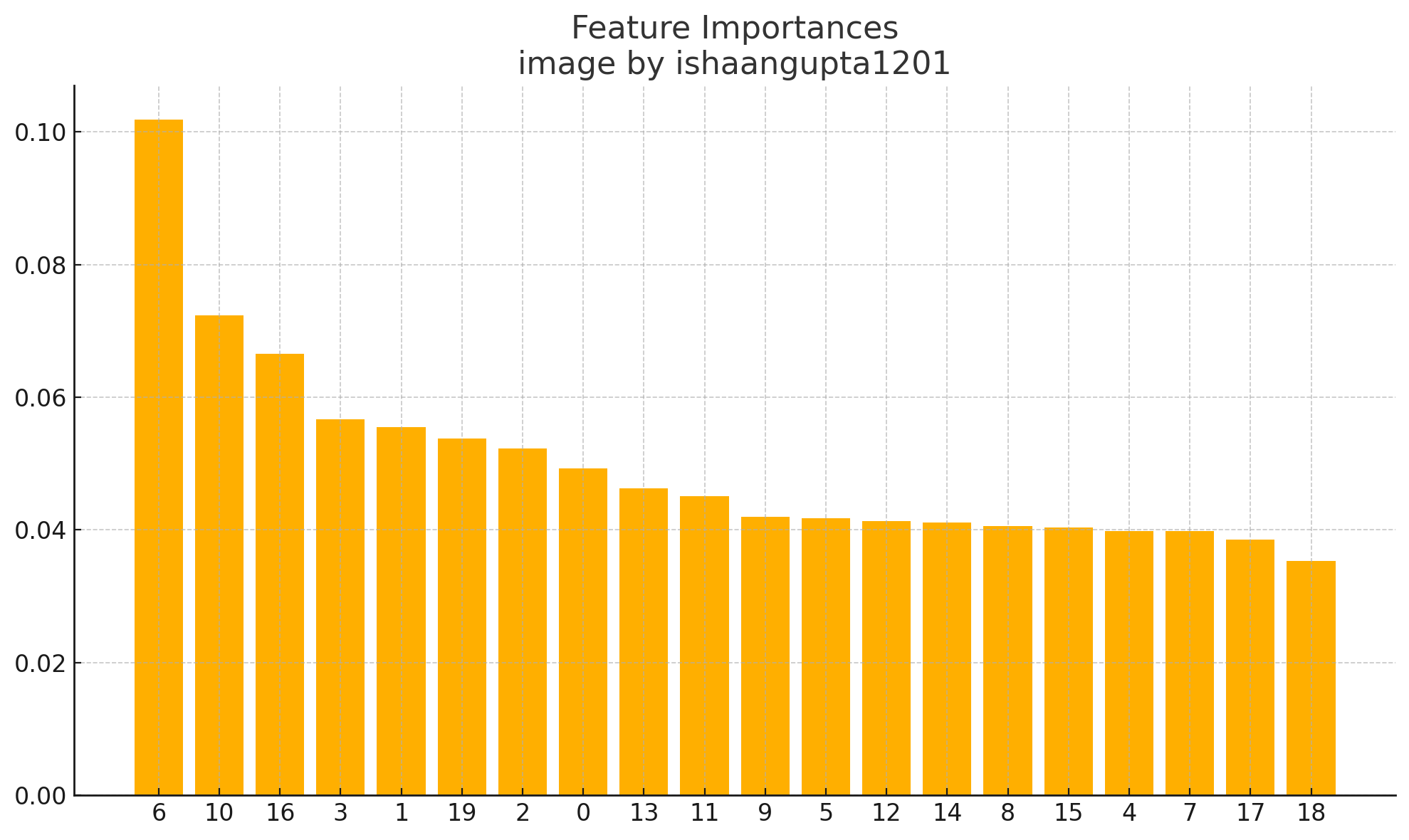
我们模型的准确性:0.77
使用案例:
- **图像分类:**识别图像中的对象或模式。
- **欺诈检测:**检测金融系统中的欺诈交易。
- 推荐系统:预测用户对产品或内容的偏好。
现实生活中的例子:
它可以用来预测物种分布通过分析环境变量(如温度,降雨量,土壤类型)预测某些物种在不同地理区域的存在或不存在。这将真正有助于保护工作,并了解气候变化如何影响生物多样性。
5)K-最近邻
K-Nearest Neighbors(KNN)是一种简单而懒惰的学习算法,用于分类和回归。它基于特征空间中k-最近邻的多数类或平均值来预测目标值。
换句话说,相似的事物彼此接近。该算法的工作原理如下:
- 首先,你决定一个数字,K,这是你想要考虑的邻居的数量。
- 接下来,算法计算您想要预测的项目与数据中所有其他项目之间的距离。
- 然后它对距离进行排序,并选择K个最近的-你的“邻居”。
- 对于分类任务,它收集最近邻居的类别
- 对于回归任务,它对这些邻居的值进行平均以预测一个数字。
基本上,它的意思是,它通过查看“邻居”或最接近的例子来预测。现在,假设你想根据某人的朋友喜欢什么来猜测他们最喜欢的零食。你选择一个数字,K*,也就是你会邀请多少朋友。你就看看那些*K*友们最喜欢吃什么零食。如果他们大多数人喜欢薯条,你就猜薯条。为了预测数字,比如一个人睡了多少小时,你取了这K个***朋友的平均时间。KNN利用相似事物彼此接近的想法来进行聪明的猜测。
示例-iris数据集上的K最近邻(KNN)分类器:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
import matplotlib.pyplot as plt
# Load the iris dataset
iris = load_iris()
X, y = iris.data, iris.target
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# creates a K-Nearest Neighbors classifier with k=3, meaning it will consider the 3 nearest neighbors for making predictions.
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Evaluate the model
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
print("\nClassification Report:")
print(classification_report(y_test, y_pred, target_names=iris.target_names))
# Visualize the decision boundary (for 2 features)
def plot_decision_boundary(X, y, model, ax=None):
h = .02 # step size in the mesh
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
if ax is None:
ax = plt.gca()
ax.contourf(xx, yy, Z, alpha=0.8, cmap=plt.cm.RdYlBu)
ax.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.RdYlBu, edgecolor='black')
ax.set_xlabel('Sepal length')
ax.set_ylabel('Sepal width')
return ax
plt.figure(figsize=(10, 8))
plot_decision_boundary(X[:, [0, 1]], y, model)
plt.title('KNN Decision Boundary (K=3)')
plt.show()
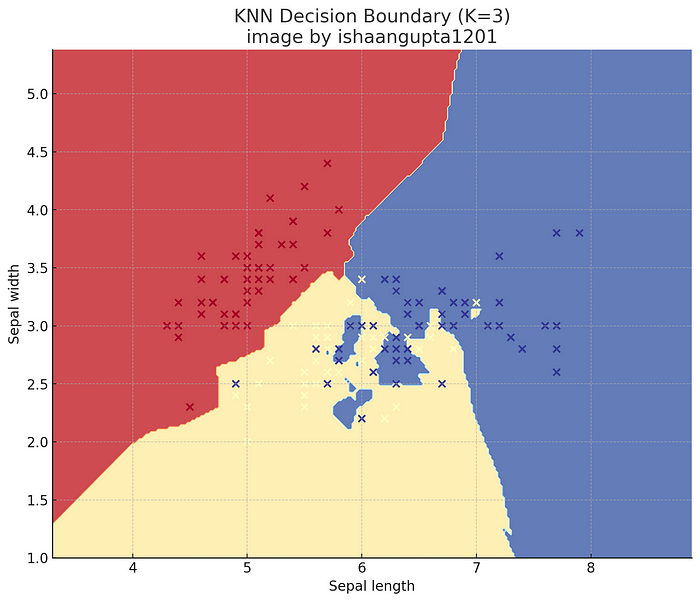
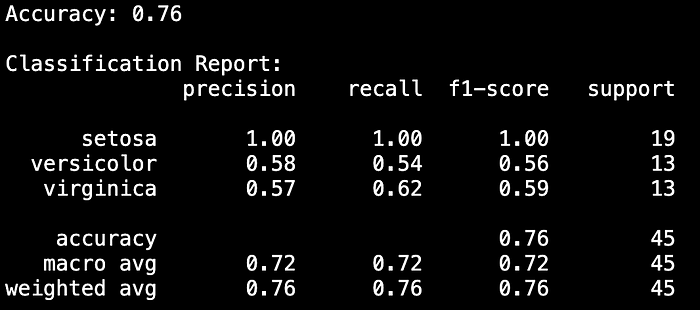
使用案例:
- 推荐系统:通过将您喜欢的内容与相似用户喜欢的内容进行比较来推荐产品。
- 异常检测:通过与正常行为进行比较来检测欺诈活动。
- 图像识别:根据像素值对图像进行分类。
现实生活中的例子:
同样,在医疗保健行业,KNN可用于诊断疾病。例如,如果我有一个包含患者症状和诊断的数据库,我可以使用KNN来预测新患者患有特定疾病的可能性,方法是根据症状找到K个最相似的患者。然后,它使用他们的诊断来预测新的病人。
总结
在本文中,我介绍了初学者必不可少的前5个ML算法。我的目标是为你提供一个坚实的基础,开始你的机器学习之旅。
我希望你能够理解这些算法中的大部分以及如何应用它们。
关注文末名片G-Z-H:【阿旭算法与机器学习】,发送【开源】可获取更多学习资源

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!