先说结论
select(1)、select(*)都是基于结果集进行的行数统计,统计到NULL行
select(column)则受到索引设置的影响,默认会排除掉NULL行
在数据库查询中,SELECT语句用于从数据库表中检索数据。SELECT (1)、SELECT (*)和SELECT (column)之间的差异主要在于它们返回的数据类型和范围:
SELECT (1):这个语句返回一个单一的值,即数字1。它不从表中检索任何数据,而是直接返回一个常量。
这种查询通常用于测试数据库连接是否正常,或者在某些情况下,用于生成一个占位符或标识符。
它不依赖于表的结构,因此与表中的列数或列名无关。
SELECT (*):这个语句返回表中的所有列和所有行的数据。
使用星号(*)作为通配符,意味着选择所有列。
这种查询在需要获取表的完整快照时非常有用,但在处理大量数据时可能会影响性能,因为它需要传输更多的数据。
SELECT (column):这个语句返回表中指定列的所有行的数据。
你需要指定具体的列名,这将只返回那一列的数据。
这种查询在只需要表中特定列的数据时非常有用,可以提高查询效率,因为它只传输所需的数据。
实践案例
我们新建一个表user2,该表没有索引哦。
drop table user2;
CREATE TABLE `user2` (
`id` bigint COMMENT '主键',
`name` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT '' COMMENT '账号'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='用户表'
;继续插入有效数据和空数据
INSERT INTO user2(id, name)
values
(1, '111');
INSERT INTO user2(id, name)
values
(null, null);我们验证下sql:
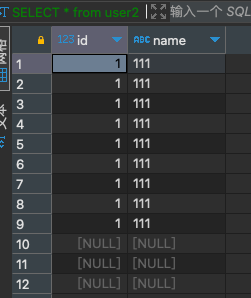
SELECT 1 from user2;
SELECT * from user2;
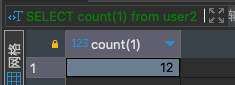
SELECT count(1) from user2;
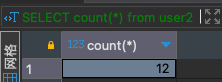
SELECT count(*) from user2;
SELECT count(id) from user2;SELECT 1 from user2;
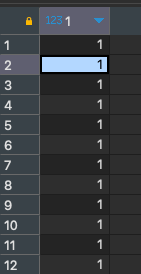
SELECT * from user2;
SELECT count(1) from user2;
SELECT count(*) from user2;
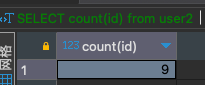
SELECT count(id) from user2;
验证
功能差异
select(1)、select(*)的效果其实一样,都是完成对全表扫描之后,再进行数据统计,甚至包括了NULL行。
SELECT count(id) 则是会过滤掉NULL行。
性能差异
select(1)、select(*)则不会走索引。

SELECT count(id) 如果id列有索引,则会走聚簇索引来统计所有行列表,并排除NULL行。
ALTER table user2
add key(`id`);
总结
在实际应用中,选择哪种类型的SELECT语句取决于你的具体需求。
如果你只需要检查数据库连接,可以使用
SELECT (1)。如果你需要表中的所有数据,使用
SELECT (*)。如果你只需要特定列的数据,那么应该使用
SELECT (column)来提高效率,并辅助索引。
此外,SELECT (1)和SELECT (*)在某些数据库系统(MyIsam)中可能会被优化以使用索引或直接从元数据中获取信息,这取决于数据库的实现和查询优化器的策略。
而SELECT (column)通常会直接访问表中的数据,除非该列上有索引;尤其是在支持多事务的InnoDB里。
在设计查询时,应该考虑到性能和资源消耗,特别是在处理大型数据库时。选择性地检索数据可以显著减少网络传输的数据量,加快查询速度,并减少对数据库服务器的压力。











![python解释器[源代码层面]](https://i-blog.csdnimg.cn/direct/d62dc9d98097442fb30bc0bb208f037a.png)