论文阅读与源码解析:CMX: Cross-Modal Fusion for RGB-X Semantic Segmentation with Transformers
论文地址:https://arxiv.org/pdf/2203.04838
GitHub项目地址:https://github.com/huaaaliu/RGBX_Semantic_Segmentation
源码:https://github.com/huaaaliu/RGBX_Semantic_Segmentation/blob/main/models/net_utils.py
Motivation
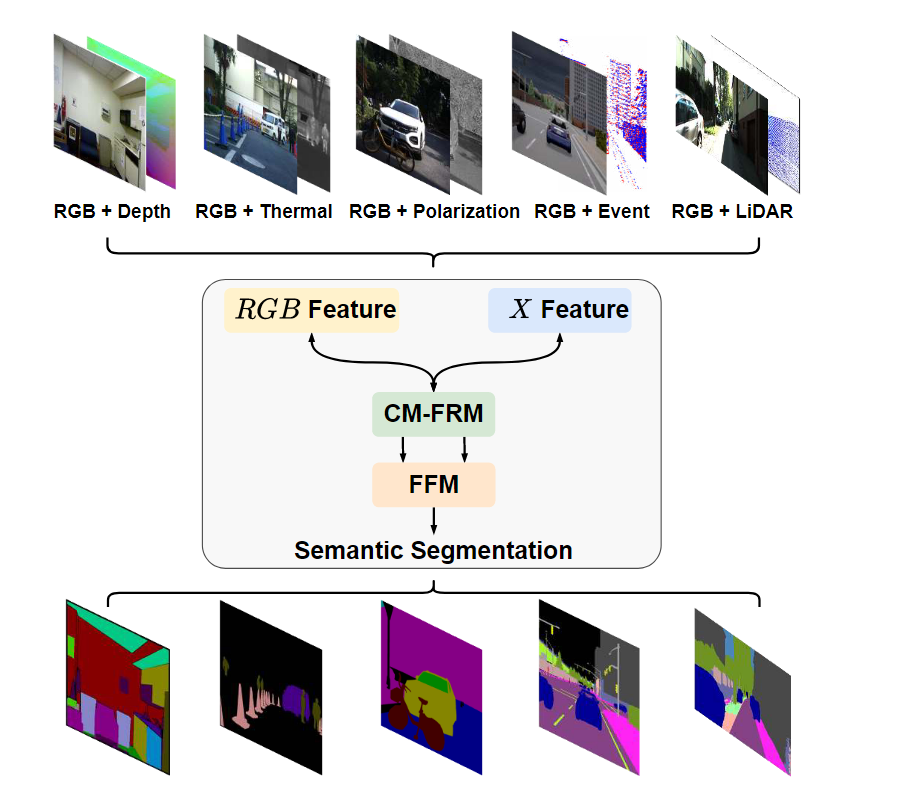
不同类型的传感器可以提供具有丰富互补信息的RGB图像。例如,深度测量可以帮助识别物体的边界,并提供密集场景元素的几何信息。热图像有助于通过特定的红外成像识别不同的物体。此外,极化和事件信息有利于镜面反射和动态真实场景的感知。激光雷达数据可以在驾驶场景中提供空间信息。
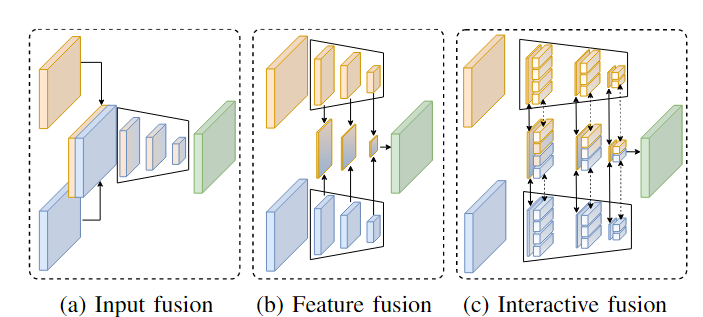
现有的多模态语义分割方法可以分为两类:(1)第一类采用单一网络从RGB和另一种模态中提取特征,融合在输入阶段(见图2a)。(2) 第二类方法部署两个主干分别从 RGB- 和另一种模态中提取特征,然后将提取的两个特征融合为一个特征以进行语义预测(见图 2b)。然而,这两种类型通常是针对单个特定模态对(例如 RGB-D 或 RGB-T)量身定制的,但很难扩展到其他模态组合进行操作。为了解决上述挑战,我们提出了 CMX,这是一种通用跨模态融合框架,用于交互式融合方式的 RGB-X 语义分割(图 2c)。具体来说,CMX 被构建为双流架构,即 RGB 和 X 模态流。设计了两个特定的模块,用于两者之间的特征交互和特征融合。
Method
作者在特征提取阶段让两种模态的特征进行交互,并且融合。
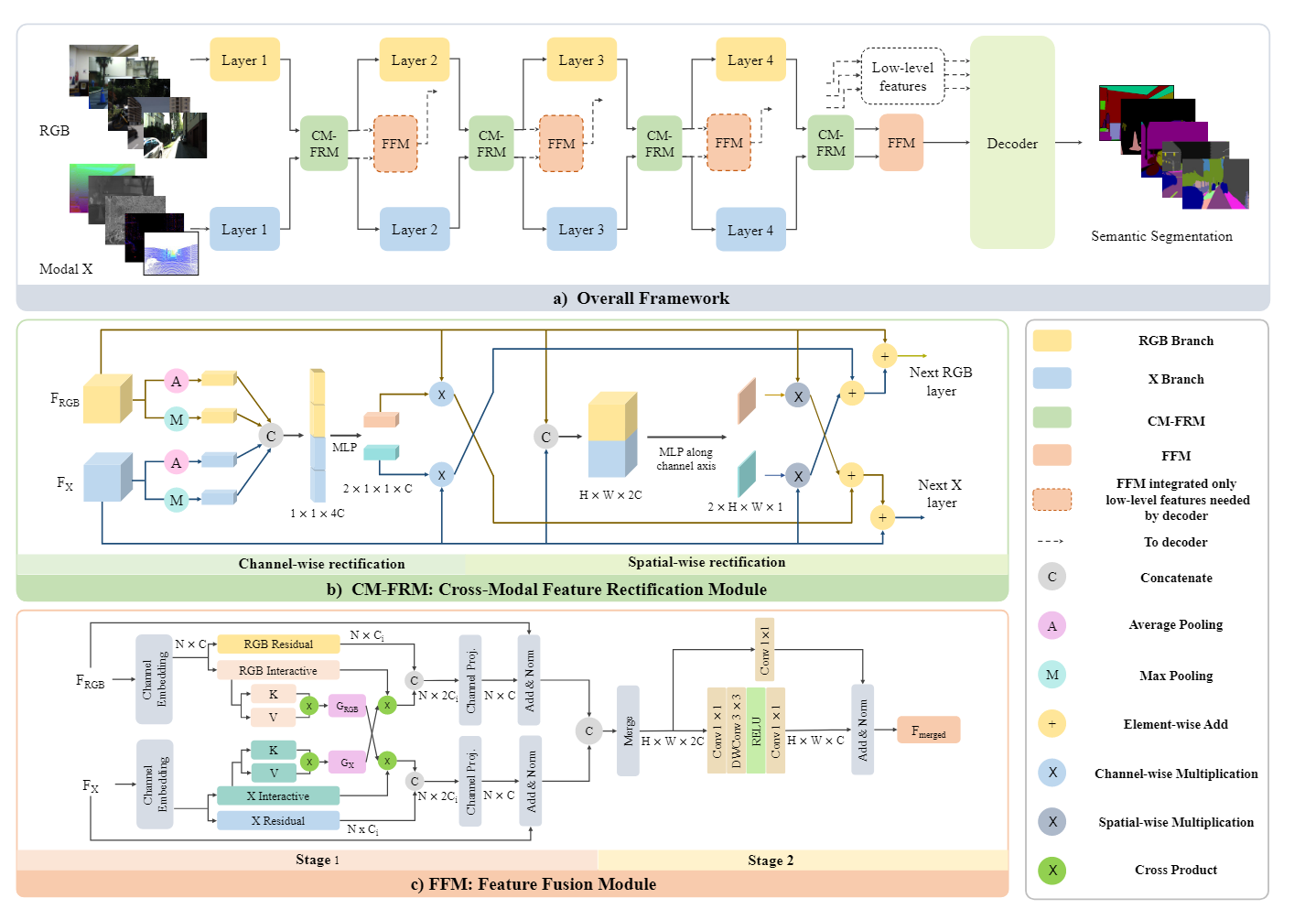
- 跨模态特征校正模块(CM-FRM),通过利用它们的空间和通道相关性来校准双模态特征,这使得两个流能够更多地关注彼此的互补信息线索,并减轻来自不同模态的不确定性和噪声测量的影响。这种特征校正解决了不同模式的不同噪声和不确定性。它支持更好的多模态特征提取和交互。
- 特征融合模块(FFM)分两个阶段构建,在合并特征之前进行充分的信息交换。受自我注意获得的大接受域的启发,在FFM的第一阶段设计了一种交叉注意机制来实现跨模态全局推理。在第二阶段,应用混合通道嵌入来产生增强的输出特征。
源码解读
- 所需要的包
import torch
import torch.nn as nn
from timm.models.layers import trunc_normal_
import math
- CM-FRM模块本质就是利用通道注意力和空间注意力时两个模态的特征进行交互,也就是将两种模态cat后计算的通道注意力和空间注意力后,在计算注意力时进行了一定的交互,然后再将对应的注意力权重乘以特征后按一定比例加到另一个模态特征中。
# Feature Rectify Module
# 计算通道注意力,这里利用了两种池化(最大池化和平均池化)
# 将两种池化的结果cat然后计算通道注意力权重
class ChannelWeights(nn.Module):
def __init__(self, dim, reduction=1):
super(ChannelWeights, self).__init__()
self.dim = dim
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.mlp = nn.Sequential(
nn.Linear(self.dim * 4, self.dim * 4 // reduction),
nn.ReLU(inplace=True),
nn.Linear(self.dim * 4 // reduction, self.dim * 2),
nn.Sigmoid())
def forward(self, x1, x2):
B, _, H, W = x1.shape
x = torch.cat((x1, x2), dim=1)
avg = self.avg_pool(x).view(B, self.dim * 2)
max = self.max_pool(x).view(B, self.dim * 2)
y = torch.cat((avg, max), dim=1) # B 4C
y = self.mlp(y).view(B, self.dim * 2, 1)
channel_weights = y.reshape(B, 2, self.dim, 1, 1).permute(1, 0, 2, 3, 4) # 2 B C 1 1
return channel_weights
# 计算空间注意力
class SpatialWeights(nn.Module):
def __init__(self, dim, reduction=1):
super(SpatialWeights, self).__init__()
self.dim = dim
self.mlp = nn.Sequential(
nn.Conv2d(self.dim * 2, self.dim // reduction, kernel_size=1),
nn.ReLU(inplace=True),
nn.Conv2d(self.dim // reduction, 2, kernel_size=1),
nn.Sigmoid())
def forward(self, x1, x2):
B, _, H, W = x1.shape
x = torch.cat((x1, x2), dim=1) # B 2C H W
spatial_weights = self.mlp(x).reshape(B, 2, 1, H, W).permute(1, 0, 2, 3, 4) # 2 B 1 H W
return spatial_weights
# FRM模块
class FeatureRectifyModule(nn.Module):
def __init__(self, dim, reduction=1, lambda_c=.5, lambda_s=.5):
super(FeatureRectifyModule, self).__init__()
self.lambda_c = lambda_c
self.lambda_s = lambda_s
self.channel_weights = ChannelWeights(dim=dim, reduction=reduction)
self.spatial_weights = SpatialWeights(dim=dim, reduction=reduction)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x1, x2):
channel_weights = self.channel_weights(x1, x2)
spatial_weights = self.spatial_weights(x1, x2)
out_x1 = x1 + self.lambda_c * channel_weights[1] * x2 + self.lambda_s * spatial_weights[1] * x2
out_x2 = x2 + self.lambda_c * channel_weights[0] * x1 + self.lambda_s * spatial_weights[0] * x1
return out_x1, out_x2
# Stage 1
# 利用的是线性注意力公式,也就是先将kv相乘,然后再与q相乘, 这样可以减少计算量
# 交叉注意力也就是一种模态的q去另一种模态生成的kv图里面去查询
class CrossAttention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None):
super(CrossAttention, self).__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.kv1 = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.kv2 = nn.Linear(dim, dim * 2, bias=qkv_bias)
def forward(self, x1, x2):
B, N, C = x1.shape
q1 = x1.reshape(B, -1, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3).contiguous()
q2 = x2.reshape(B, -1, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3).contiguous()
k1, v1 = self.kv1(x1).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4).contiguous()
k2, v2 = self.kv2(x2).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4).contiguous()
ctx1 = (k1.transpose(-2, -1) @ v1) * self.scale
ctx1 = ctx1.softmax(dim=-2)
ctx2 = (k2.transpose(-2, -1) @ v2) * self.scale
ctx2 = ctx2.softmax(dim=-2)
x1 = (q1 @ ctx2).permute(0, 2, 1, 3).reshape(B, N, C).contiguous()
x2 = (q2 @ ctx1).permute(0, 2, 1, 3).reshape(B, N, C).contiguous()
return x1, x2
class CrossPath(nn.Module):
def __init__(self, dim, reduction=1, num_heads=None, norm_layer=nn.LayerNorm):
super().__init__()
self.channel_proj1 = nn.Linear(dim, dim // reduction * 2)
self.channel_proj2 = nn.Linear(dim, dim // reduction * 2)
self.act1 = nn.ReLU(inplace=True)
self.act2 = nn.ReLU(inplace=True)
self.cross_attn = CrossAttention(dim // reduction, num_heads=num_heads)
self.end_proj1 = nn.Linear(dim // reduction * 2, dim)
self.end_proj2 = nn.Linear(dim // reduction * 2, dim)
self.norm1 = norm_layer(dim)
self.norm2 = norm_layer(dim)
def forward(self, x1, x2):
y1, u1 = self.act1(self.channel_proj1(x1)).chunk(2, dim=-1)
y2, u2 = self.act2(self.channel_proj2(x2)).chunk(2, dim=-1)
v1, v2 = self.cross_attn(u1, u2)
y1 = torch.cat((y1, v1), dim=-1)
y2 = torch.cat((y2, v2), dim=-1)
out_x1 = self.norm1(x1 + self.end_proj1(y1))
out_x2 = self.norm2(x2 + self.end_proj2(y2))
return out_x1, out_x2
# Stage 2
class ChannelEmbed(nn.Module):
def __init__(self, in_channels, out_channels, reduction=1, norm_layer=nn.BatchNorm2d):
super(ChannelEmbed, self).__init__()
self.out_channels = out_channels
self.residual = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
self.channel_embed = nn.Sequential(
nn.Conv2d(in_channels, out_channels//reduction, kernel_size=1, bias=True),
nn.Conv2d(out_channels//reduction, out_channels//reduction, kernel_size=3, stride=1, padding=1, bias=True, groups=out_channels//reduction),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels//reduction, out_channels, kernel_size=1, bias=True),
norm_layer(out_channels)
)
self.norm = norm_layer(out_channels)
def forward(self, x, H, W):
B, N, _C = x.shape
x = x.permute(0, 2, 1).reshape(B, _C, H, W).contiguous()
residual = self.residual(x)
x = self.channel_embed(x)
out = self.norm(residual + x)
return out
# FFM模块,先进行Attention交互特征,然后利用卷积和线性层融合双模态特征
class FeatureFusionModule(nn.Module):
def __init__(self, dim, reduction=1, num_heads=None, norm_layer=nn.BatchNorm2d):
super().__init__()
self.cross = CrossPath(dim=dim, reduction=reduction, num_heads=num_heads)
self.channel_emb = ChannelEmbed(in_channels=dim*2, out_channels=dim, reduction=reduction, norm_layer=norm_layer)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x1, x2):
B, C, H, W = x1.shape
x1 = x1.flatten(2).transpose(1, 2)
x2 = x2.flatten(2).transpose(1, 2)
x1, x2 = self.cross(x1, x2)
merge = torch.cat((x1, x2), dim=-1)
merge = self.channel_emb(merge, H, W)
return merge


















