TSLiB是一个为深度学习时间序列分析量身打造的开源仓库。它提供了多种深度时间序列模型的统一实现,方便研究人员评估现有模型或开发定制模型。TSLiB涵盖了长时预测(Long-term forecasting)、短时预测(Short-term forecasting)、缺失值填补(Missing value imputation)、异常检测(Anomaly detection)和分类(Classification)等五种主流时间序列任务,是从事时间序列分析研究者的理想工具。TSLiB库官方地址见:Time-Series-Library。
文章目录
- 1 TSLiB库的使用
- 1.1 时序任务介绍
- 1.2 TSLiB库介绍
- 1.2.1 环境安装
- 1.2.2 TimesNet网络使用
- 1.3 TSLiB库支持的数据集
- 1.3.1 长时预测
- 1.3.2 短时预测
- 1.3.3 缺失值填补
- 1.3.4 分类
- 1.3.5 异常检测
- 1.4 模型训练
- 2 参考
1 TSLiB库的使用
1.1 时序任务介绍
TSLiB 支持的五种时序任务概述如下:
| 任务类型 | 定义 | 特点 | 应用场景示例 |
|---|---|---|---|
| 长时预测 | 预测时间序列在未来较长时间段内的变化趋势 | 需要考虑长期趋势和季节性因素,使用复杂的模型来捕捉长期依赖性 | 股票价格预测、长期能源需求预测等 |
| 短时预测 | 预测时间序列在近期的未来值 | 通常关注短期波动,模型需要快速响应新数据 | 短期销售预测、交通流量预测等 |
| 缺失值填补 | 填补时间序列中缺失的数据点 | 需要保持时间序列的连续性和一致性 | 时间序列预处理、历史数据补全等 |
| 异常检测 | 识别时间序列中的异常或离群点 | 需要区分正常波动和异常事件 | 网络安全监控、设备故障检测等 |
| 分类 | 将时间序列数据分为不同的类别或标签 | 通常基于时间序列的特征进行分类 | 客户行为分析、医疗诊断等 |
本文写作时,TSLiB汇集截至2024年3月,在五项不同任务表现排名前三名的模型如下:
| 任务 | 第一 | 第二 | 第三 |
|---|---|---|---|
| 长时预测-过去96步 | iTransformer | TimeMixer | TimesNet |
| 长时预测-搜索 | TimeMixer | PatchTST | DLinear |
| 短时预测 | TimesNet | Non-stationary Transformer | FEDformer |
| 缺失值填补 | TimesNet | Non-stationary Transformer | Autoformer |
| 分类 | TimesNet | FEDformer | Informer |
| 异常检测 | TimesNet | FEDformer | Autoformer |
TSLiB库中参与以上排名的深度学习时序模型如下:
- TimeMixer:TimeMixer是一种用于时间序列预测的新型架构,它通过分解多尺度混合操作来捕捉时间序列数据中的复杂模式 [ICLR 2024] [Code]。
- TSMixer:TSMixer是一种全连接多层感知器(MLP)架构,用于时间序列预测。它通过沿时间和特征维度的混合操作来有效提取信息 [arXiv 2023] [Code]。
- iTransformer:iTransformer提出了一种反转的Transformer架构,用于时间序列预测。它通过在反转的维度上应用注意力和前馈网络来捕获多变量相关性,并学习非线性表示 [ICLR 2024] [Code]。
- PatchTST:PatchTST是一种基于Transformer的时间序列长时预测模型,它将时间序列视为由多个变量组成的64个token [ICLR 2023] [Code]。
- TimesNet:TimesNet是一种用于通用时间序列分析的模型,它通过建模时间序列中的二维变化来进行预测 [ICLR 2023] [Code]。
- DLinear:DLinear是一种线性时间序列预测模型,它探讨了Transformer在时间序列预测中的有效性 [AAAI 2023] [Code]。
- LightTS:LightTS是一种快速的多变量时间序列预测模型,它采用了轻量级的采样导向的MLP结构 [arXiv 2022] [Code]。
- ETSformer:ETSformer是一种结合了指数平滑和Transformer的时间序列预测模型 [arXiv 2022] [Code]。
- Non-stationary Transformer:Non-stationary Transformer是一种探索时间序列预测中非平稳性的模型 [NeurIPS 2022] [Code]。
- FEDformer:FEDformer是一种用于长时序列预测的频率增强分解Transformer模型 [ICML 2022] [Code]。
- Pyraformer:Pyraformer是一种用于长时时间序列建模和预测的低复杂度金字塔注意力模型 [ICLR 2022] [Code]。
- Autoformer:Autoformer是一种具有自相关分解的Transformer模型,用于长时序列预测 [NeurIPS 2021] [Code]。
- Informer:Informer是一种用于长时序列时间序列预测的经典模型 [AAAI 2021] [Code]。
- Reformer:Reformer是一种高效的Transformer模型,通过使用局部敏感哈希来减少计算复杂度 [ICLR 2020] [Code]。
- Transformer:Transformer是一种基于自注意力机制的模型,它在自然语言处理等多个领域取得了巨大成功 [NeurIPS 2017] [Code]。
还有一些深度学习时序模型包含在TSLiB库中,但是尚未参与TSLiB库的性能排行榜。可以关注TSLiB的官方链接 ,查询最新结果:
- Mamba:Mamba是一种基于选择性状态空间的线性时间序列模型。Mamba模型在处理长序列数据时表现出色,并且在多种模态上达到了最先进的性能 [arXiv 2023] [Code]。
- SegRNN:即Segment Recurrent Neural Network,是一种用于长时预测的循环神经网络 [arXiv 2023] [Code]。
- Koopa:Koopa模型利用Koopman预测器学习非平稳时间序列动态 [NeurIPS 2023] [Code]。
- FreTS: 一种在频域中应用多层感知器(MLPs)进行时间序列预测的模型 [NeurIPS 2023] [Code]。
- TiDE:即Time-series Dense Encoder,是一种用于长时序列预测的多层感知器(MLP)基础编解码模型 [arXiv 2023] [Code]。
- FiLM: 即Frequency improved Legendre Memory Model,它结合了傅里叶变换和Legendre多项式来改进模型对时间序列频率特性的捕捉能力 [NeurIPS 2022][Code]。
- MICN:即Multi-scale Local and Global Context Modeling,它通过多尺度局部和全局上下文建模来捕捉时间序列的复杂动态 [ICLR 2023][Code]。
- Crossformer: Crossformer是一种利用跨维度依赖性的Transformer模型,用于多变量时间序列预测,它通过跨维度自注意力机制来捕捉不同时间序列之间的复杂关系 [ICLR 2023][Code]。
- TFT: 即Temporal Fusion Transformers,是一种用于可解释多目标时间序列预测的模型 [arXiv 2019][Code]。
1.2 TSLiB库介绍
1.2.1 环境安装
整个项目的结构说明如下图所示:

安装代码如下:
git clone https://github.com/thuml/Time-Series-Library
pip install -r requirements.txt
本文主要基于TimesNet模型来介绍TSLiB库的使用。TimesNet模型支持长时预测、短时预测、缺失值填补、异常检测和分类,同时也是TSLiB作者团队提出的模型。TimesNet具体介绍如下:TimesNet: 时序基础模型,预测、填补、分类等五大任务领先。TSLiB库基于TimesNet网络的使用教程见:TimesNet_tutorial.ipynb。
1.2.2 TimesNet网络使用
TimesNet是一个通用的时间序列神经网络,可处理各种不同的时间序列任务。从TimesNet的相关库加载可以看到,其关键组件包括实现快速傅里叶变换的fft函数和Inception特征提取主干网络。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.fft
from layers.Embed import DataEmbedding
from layers.Conv_Blocks import Inception_Block_V1
基于快速傅里叶变换的数据转换
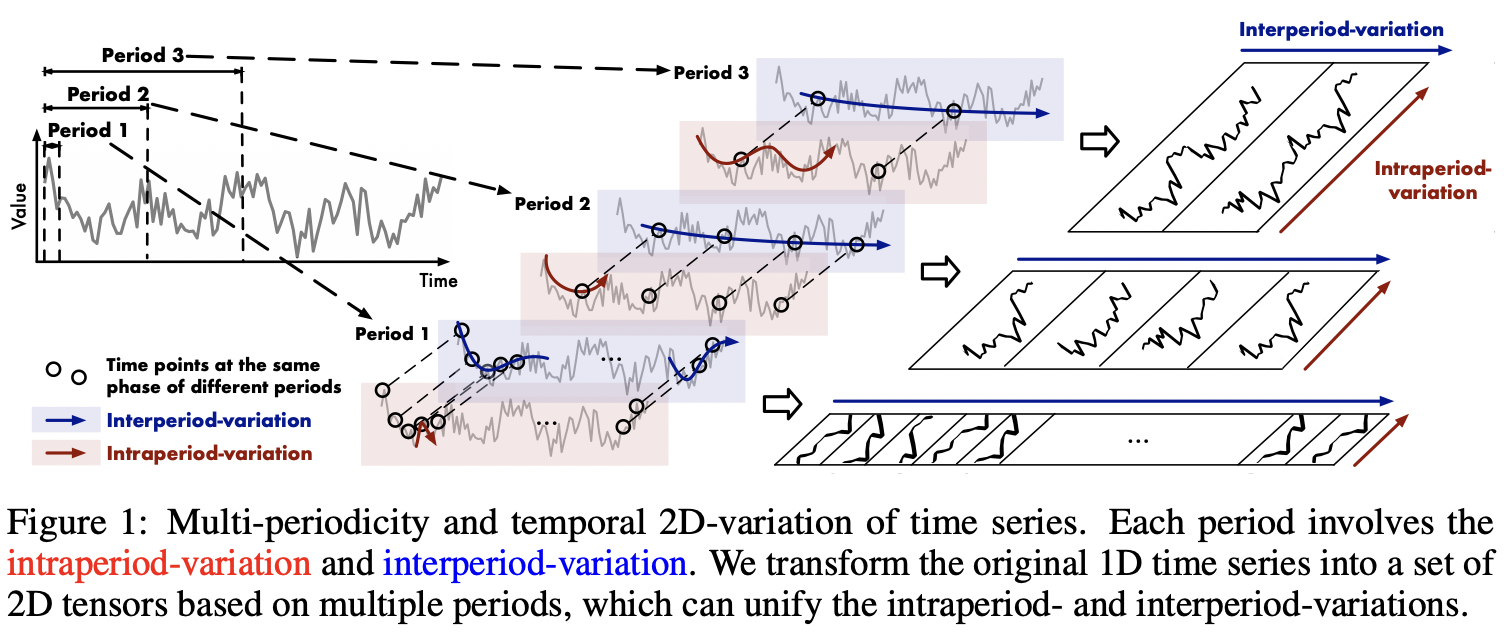
TimesNet的核心理念在于实现从一维数据到二维数据的转化。当下,多数现存方法主要聚焦于时间序列的时间维度以获取时序依赖性。原始的一维序列,恰似直线上依次排布的点,其主要呈现的是相邻时间点间的直接变动。例如,昨日的数据为0,今日的数据为12,仅能察觉出简易的增长或减少。然而,事实上,现实世界中的时间序列通常具备多重周期性,诸如每日周期、每周周期、每月周期等;并且,每个周期内部的时间点存在依赖关系(如今天10点与12点),不同相邻周期内的时间点同样存在依赖关系(如今天10点与明天10点)。以气温变化的时间序列为例,每天不同时刻的气温变动形成每日周期,每周的平均气温变化构建每周周期。将时间维度转化为二维,有利于更精确地把控气温的变化规律与趋势。
由此,作者提出TimesBlock模块来实现相关功能,它通过以下步骤来处理时间序列数据:
- 基础频率提取:通过快速傅里叶变换(Fast Fourier Transform, FFT)对时间序列数据进行频域分析,从而获取数据的基本频率成分。
- 时间序列重塑:将时间序列数据根据主基础频率重新组织成二维变化形式。这通常意味着将时间序列分解成多个频率分量,并将其表示为二维矩阵。
- 二维卷积:对这些二维矩阵执行二维卷积操作,这有助于捕捉时间序列数据中的局部模式和结构。
- 输出重构:将卷积操作的输出重新组织,并与相应的权重相加,形成最终的输出结果。
如下所示的图中,时间序列展现出三个周期性阶段(Period 1、Period 2、Period 3)。其中,红色代表周期内的变化(类似于环比,比如昨天与今天的变化情况),蓝色则表示周期间的变化(类似于同比的概念,例如今天10点和明天10点的对比)。此时间序列被转换为三种不同的二维数据。在每个二维数据中,每一列用于表征周期内的变化情况,而每一行则用于体现周期间的变化状况:
那么,应如何确定时间序列里的周期性呢?可运用快速傅里叶变换这一方法。对时间序列实施快速傅里叶变换操作后,其主要的周期将会呈现出相应具有高幅值的频率分量。设定一个超参数k,接着仅选取幅值最大的topk个频率分量,如此便能获取到k个主要的周期。具体操作如下图,假设设定k为3,经过快速傅里叶变换后,发现频率分量幅值最大的三个频率分别为 10Hz、20Hz 和 30Hz ,那么这三个频率所对应的周期就是主要周期。然后将1D时间序列按照这三个周期进行重塑,再用2D卷积处理并聚合结果,就能有效地捕捉到多周期的时序变化特征:
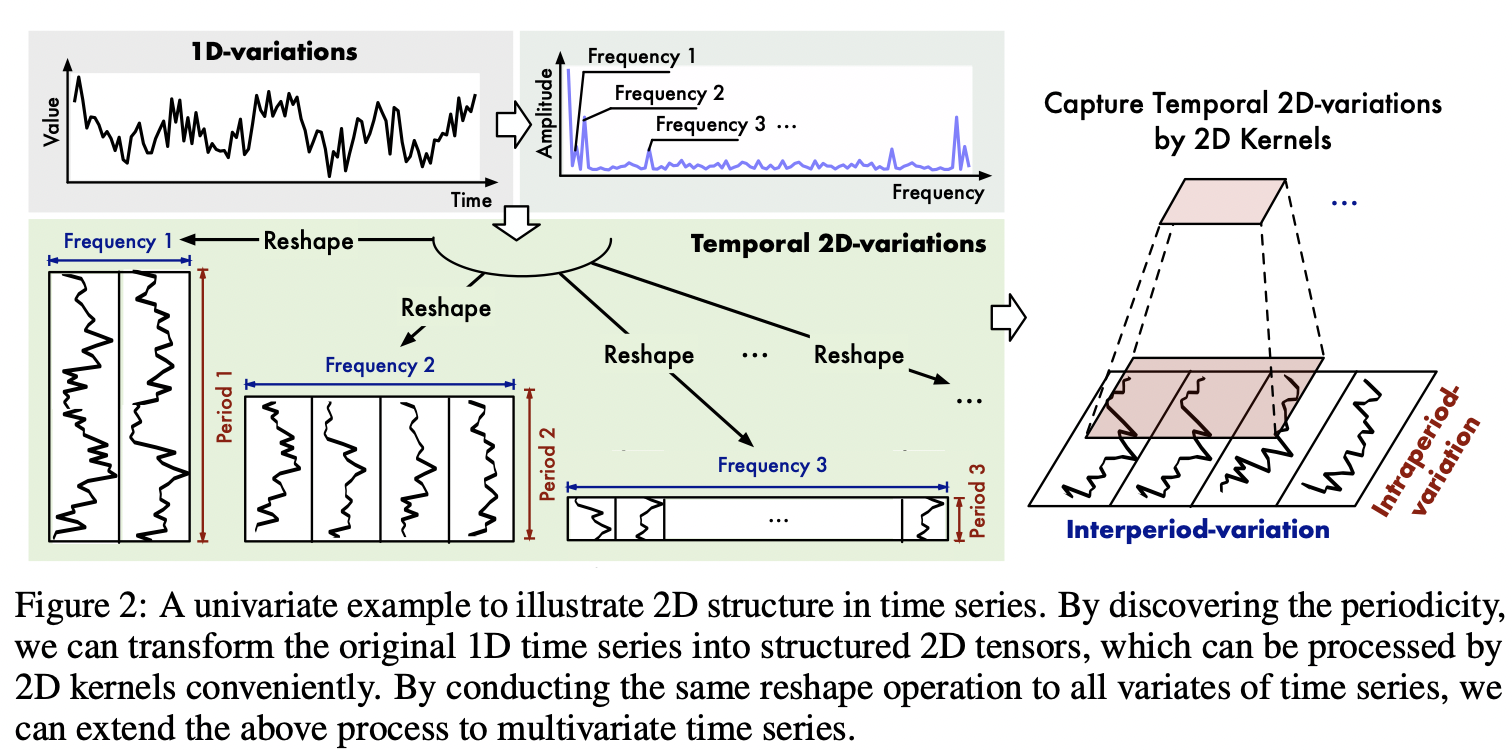
TimesBlock模块
TimesBlock实现了对时序变化特征进一步特征提取的功能,代码的实现位于models文件下的TimesNet.py文件:TimesBlock类。TimesBlock类定义如下:
class TimesBlock(nn.Module):
def __init__(self, configs):
super(TimesBlock, self).__init__()
pass
def forward(self, x):
pass
基于TimesBlock模块,可以构建适应于各类时序序列任务的TimesNet模型。相关代码位于models文件下的TimesNet.py文件:TimesNet类。实现TimesNet模型的Model类定义如下:
class Model(nn.Module):
def __init__(self, configs):
super(Model, self).__init__()
self.configs = configs
self.task_name = configs.task_name
pass
# 长时预测和短时预测
def forecast(self, x_enc, x_mark_enc, x_dec, x_mark_dec):
...
# 缺失值填补
def imputation(self, x_enc, x_mark_enc, x_dec, x_mark_dec, mask):
pass
# 异常检测
def anomaly_detection(self, x_enc):
pass
# 分类
def classification(self, x_enc, x_mark_enc):
pass
# 推理
def forward(self, x_enc, x_mark_enc, x_dec, x_mark_dec, mask=None):
if self.task_name == 'long_term_forecast' or self.task_name == 'short_term_forecast':
dec_out = self.forecast(x_enc, x_mark_enc, x_dec, x_mark_dec)
pass
if self.task_name == 'imputation':
dec_out = self.imputation(
x_enc, x_mark_enc, x_dec, x_mark_dec, mask)
pass
if self.task_name == 'anomaly_detection':
dec_out = self.anomaly_detection(x_enc)
pass
if self.task_name == 'classification':
dec_out = self.classification(x_enc, x_mark_enc)
pass
Model类在初始化函数中通过接收configs参数,并根据其中的task_name来决定执行哪个任务的处理逻辑。这使得模型可以通过修改配置来切换模型执行的任务,而无需对代码结构进行大的改动。同时从以上代码可以看到,如果未来需要添加一个新的任务,比如回归,可以轻松地添加一个新的方法regression来处理相关逻辑,大大增加了代码的灵活性。
模型训练
TimesNet网络的训练、验证和测试的相关代码是在exp目录下实现的。以长时预测为例,用于长时预测任务的模型训练过程可以简要地分为几个部分,包括数据准备、创建保存路径、初始化、优化器和损失函数选择、使用混合精度训练、训练循环、验证和提前停止、学习率调整、加载最佳模型。相关代码位于exp/exp_long_term_forecasting.py文件。
- 模型训练,支持自动混合精度(AMP):源码位于exp/exp_long_term_forecasting.py。
- 早停(EarlyStopping):源码位于utils/tools.py。
- 优化器和损失计算,使用Adam优化器和MSEloss来衡量实际数据和预测数据之间的损失:源码位于exp/exp_long_term_forecasting.py
- 验证和测试:源码位于exp/exp_long_term_forecasting.py。
- 数据集选择,提供工厂函数支持不同数据集读取:源码位于data_provider/data_factory.py。
- 数据读入,根据选择的数据集和数据集加载的配置来读取和划分数据集:源码位于data_provider/data_loader.py。
数据集支持
TSLiB的官方仓库提供了常见时序预测数据集的下载:谷歌云和百度云,然后将下载后的数据集放入dataset目录即可。
1.3 TSLiB库支持的数据集
本节主要介绍TSLiB所使用的时序数据集。这些数据集在时序列分析领域中已被前人研究,并经过精心清洗以符合统一的格式标准。鉴于时序列分析领域的相对不成熟,现有的数据集多依赖于网络爬虫技术获取,或与现实应用场景存在一定差距。这些数据集的具体介绍可以查看TimesNet的论文:TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis。
更多时序数据集的介绍见:时间序列论文标准数据集和TimesNet复现结果。
1.3.1 长时预测
长时预测是各大时序模型主要支持的任务。在长时预测中,TSLiB库基于均方误差(MSEloss)损失来训练模型。注意特征数不包含时间特征,但包含预测目标特征。这是因为TSLiB中集成的长时预测模型会在训练过程中将预测变量作为输入特征的一部分进行学习。
| 数据集 | 数据输入特征数 | 样本长度 | 时间粒度 |
|---|---|---|---|
| ECL | 321 | 26304 | 1小时 |
| ETTh1/ETTh2 | 7 | 17420 | 1小时 |
| ETTm1/ETTm2 | 7 | 69680 | 15分钟 |
| Exchange_rate | 8 | 7588 | 1天 |
| ILI | 7 | 966 | 1周 |
| Traffic | 862 | 17544 | 1小时 |
| Weather | 21 | 52696 | 10分钟 |
注意数据集的预测目标列都被命名为”OT“。这一命名为了构建一个标准化的长时预测数据集,将所有预测目标列的命名统一为与ETT数据集列名相一致的形式。
ECL
ECL(electricity)数据集涵盖了321位客户在四年期间的每小时用电记录,旨在预测不同区域的电力需求。鉴于数据中存在缺失值,数据集中的最后一列被作为预测目标。在TSLiB中基于Dataset_Custom类来读取数据集。
ETT
ETT-small电力变压器温度(Electricity Transformer Temperature)数据集,主要应用于电力系统时间预测的相关研究。此数据集涵盖了中国两个不同地区为期两年的数据,由两个小时级数据集(ETTh1、ETTh2)以及两个15分钟级数据集(ETTm1、ETTm2)共同构成。每个数据点均包含2016年7月至2018年7月这段时间内的目标值“油温度”以及6个电力负载特征。在TSLiB中基于Dataset_ETT_hour和Dataset_ETT_minute类来读取数据集。各列描述如下:
- date: 记录的日期;
- HUFL: High Use Full Load;
- HULL: High Use Less Load;
- MUFL: Middle Use Full Load;
- MULL: Middle Use Less Load;
- LUFL: Low Use Full Load;
- LULL: Low Use Less Load;
- OT: 油温度(Oil Temperature),预测的目标值。
Exchange_rate
Exchange_rate数据集包括澳大利亚、英国、加拿大、瑞士、中国、日本、新西兰和新加坡八个国家的每日汇率数据,时间跨度从1990年到2016年。在TSLiB中基于Dataset_Custom类来读取数据集。
ILI
ILI(illness)数据集包括了从2002年到2020年间美国疾控中心的各周流感数据。在TSLiB中基于Dataset_Custom类来读取数据集。各特征列描述如下:
- date: 记录的日期;
- %WEIGHTED ILI:国家层面的加权比例;
- %UNWEIGHTED ILI:州层面的加权比例;
- AGE 0-4: 4岁以下患者数;
- AGE 5-24: 5到24岁患者数;
- ILITOTAL:具有流感样症状的患者总数;
- NUM.OF PROVIDERS:报告数据的医疗提供者的数量;
- OT:TOTAL PATIENTS,访问医疗提供者的患者总数。
Traffic
Traffic数据集包含了来自美国加州交通部的862个传感器在2016至2018年间每小时的数据记录。这些数据详细记录了旧金山湾区高速公路上各传感器所测量的道路占用率。道路占用率的数值范围在0到1之间,0表示道路完全空闲,而1表示道路完全拥堵,这个数值范围反映了道路的实际使用情况。最后一列作为特征列。在TSLiB中基于Dataset_Custom类来读取数据集。
Weather
Weather数据集涵盖了21项关键气象指标,包括空气温度和湿度等。数据采集自2020年,以每10分钟的频率进行记录。在TSLiB中基于Dataset_Custom类来读取数据集。各列描述如下:
- p (mbar) / 气压(毫巴):大气压力的度量,单位为毫巴;
- T (degC) / 温度(摄氏度):空气的热力学温度,单位为摄氏度;
- Tpot (K) / 势温(开尔文):考虑湿度影响后的空气温度,单位为开尔文;
- Tdew (degC) / 露点温度(摄氏度):空气中水蒸气凝结成露水的温度,单位为摄氏度;
- rh (%) / 相对湿度(百分比):空气中水蒸气含量与饱和水蒸气含量的比值,以百分比表示;
- VPmax (mbar) / 最大蒸气压(毫巴):空气中水蒸气可能达到的最大压力,单位为毫巴;
- VPact (mbar) / 实际蒸气压(毫巴):当前空气中水蒸气的实际压力,单位为毫巴;
- VPdef (mbar) / 蒸气压差(毫巴):实际蒸气压与最大蒸气压之间的差值,单位为毫巴;
- sh (g/kg) / 比湿(克/千克):单位质量空气中水蒸气的质量,单位为克/千克;
- H2OC (mmol/mol) / 水汽浓度(毫摩尔/摩尔):空气中水蒸气的摩尔浓度,单位为毫摩尔/摩尔;
- rho (g/m³) / 空气密度(克/立方米):单位体积空气中的质量,单位为克/立方米;
- wv (m/s) / 水平风速(米/秒):风在水平方向上的速度,单位为米/秒;
- max. wv (m/s) / 最大风速(米/秒):记录期间风速的最大值,单位为米/秒;
- wd (deg) / 风向(度):风的来向,以角度表示;
- rain (mm) / 降水量(毫米):降水的总量,单位为毫米;
- raining (s) / 降雨时间(秒):降雨持续的时间,单位为秒;
- SWDR (W/m²) / 直接太阳辐射(瓦特/平方米):单位面积上接收到的直接太阳辐射能量,单位为瓦特/平方米;
- PAR (μmol/m²s) / 光合有效辐射(微摩尔/平方米秒):植物进行光合作用的有效辐射,单位为微摩尔/平方米秒;
- max. PAR (μmol/m²s) / 最大光合有效辐射(微摩尔/平方米秒):记录期间光合有效辐射的最大值,单位为微摩尔/平方米秒;
- Tlog (degC) / 对数平均温度(摄氏度):对数平均法计算的平均温度,单位为摄氏度;
- OT / CO2 (ppm,我搜索的,不一定对,但正确率可能性大约80%):二氧化碳的浓度单位 “parts per million”(百万分比浓度)。
1.3.2 短时预测
TSLiB在处理短时和长时预测任务时,其核心差异仅在于预测的时间跨度。深度学习时序预测模型能够一次性生成整个预测序列。因此,从模型结构的视角分析,短时预测与长时预测在本质上并无显著区别,主要的调整仅涉及模型输出长度这一超参数的设定。对于短时预测而言,采用对称平均绝对百分比误差(SMAPE)作为损失函数的计算基准。
TSLiB使用M4数据集来评价模型短时预测的能力。M4数据集的详细介绍见:M4。M4数据集是第四届Makridakis预测竞赛的多个时序数据集合,由年度、季度、月度、每周、每日、每小时等不同数据颗粒的时间序列组成,分为训练集和测试集。其涵盖经济、金融、商业、社会、环境等多个领域,M4数据集主要下数据文件如下:
- Yearly-train.csv:年度数据训练集
- Yearly-test.csv:年度数据训练集
- Quarterly-train.csv:季度数据训练集
- Quarterly-test.csv:季度数据训练集
- Monthly-train.csv:月度数据训练集
- Monthly-test.csv:月度数据训练集
- Weekly-train.csv:每周数据训练集
- Weekly-test.csv:每周数据训练集
- Daily-train.csv:每日数据训练集
- Daily-test.csv:每日数据训练集
- Hourly-train.csv:小时数据训练集
- Hourly-test.csv:小时数据测试集
- M4-info.csv:数据集描述文件,文件各列含义如下:
- M4id:数据的ID
- category:数据所处领域
- Frequency:数据的频率
- Horizon:数据的序列长度
- SP:数据的时间颗粒度
- StartingDate:数据起始时间
1.3.3 缺失值填补
缺失值填补是一项旨在预测时间序列中某些缺失值的任务,因此在某种程度上类似于预测。缺失值填补Imputation涉及到的数据集有ECL、ETT、Weather数据集。这些数据集在长时预测已经提到了。TSLiB库中用于实现Imputation的模型架构与长时预测相同。然而,其区别在于,TSLiB在训练过程中会对输入数据中的部分信息进行掩码处理,随后利用模型预测输入数据中被掩码的值。并基于均方误差(MSEloss)损失计算掩码部分的差值。这一阶段不需要训练标签的参与。
1.3.4 分类
TSLib库基于CrossEntropyLoss损失来训练时序分类模型,注意输入数据特征不包含时间特征和分类特征。时序分类训练流程类似于图像分类模型的训练流程。
| 数据集 | 输入数据特征数 | 训练样本长度 | 分类类别数 |
|---|---|---|---|
| EthanolConcentration | 3 | 261个(1751, 3)的特征向量 | 4 |
| FaceDetection | 144 | 5890个(62, 144)的特征向量 | 2 |
| Handwriting | 3 | 150个(152,3)的特征向量 | 26 |
| Heartbeat | 61 | 204个(405,61)的特征向量 | 2 |
| JapaneseVowels | 12 | 270个(29,12)的特征向量 | 9 |
| PEMS-SF | 963 | 267个(144,963)的特征向量 | 7 |
| SelfRegulationSCP1 | 6 | 268个(896,6)的特征向量 | 2 |
| SelfRegulationSCP2 | 7 | 200个(1152,7)的特征向量 | 2 |
| SpokenArabicDigits | 13 | 6599个(93,13)的特征向量 | 10 |
| UWaveGestureLibrary | 3 | 120个(315,3)的特征向量 | 8 |
EthanolConcentration
EthanolConcentration数据集是一个多变量时间序列数据集,它包含了44种不同真实威士忌酒瓶中水和乙醇溶液的原始光谱数据。这些数据用于预测样本中的乙醇浓度。数据集中的乙醇浓度分别为35%、38%、40%和45%,其中40%是苏格兰威士忌的最低法定酒精含量。数据集包含524个多变量时间序列,分为训练集(261个样本)和测试集(263个样本)。每个时间序列由1751个时间点组成,记录了三个变量的测量值。这些变量代表了在不同波长下的光谱强度,数据覆盖了从226nm到1101.5nm的波长范围,采样频率为0.5nm。输入数据集的列包括:
- 时间点:表示时间测量点。
- 变量1:表示第一个光谱强度测量值。
- 变量2:表示第二个光谱强度测量值。
- 变量3:表示第三个光谱强度测量值。
此外,还有一个数值向量classes,它包含了与输入数据相对应的四个类别,每个类别与不同的乙醇浓度相关联。因此模型对维度维度为(1751,3)的向量进行分类,判断其属于哪个类别。在TSLiB中基于UEAloader类来读取数据集,此类和普通时序数据读取类不一样。里面过于啰嗦,因为分类原始数据被统一为ts格式,需要过多数据处理代码。
FaceDetection
FaceDetection数据集属于面部时序数据,其中每组包含62个观测值,每个观测值又有144个特征点。该数据集主要用于区分输入数据表示人脸还是非人脸。这个数据集的读取速度较为缓慢。在TSLiB中基于UEAloader类来读取数据集。
Handwriting
Handwriting数据集包含26个字母的手写样本,共有150个训练用例和850个测试用例。数据集中包含的三个特征维度为加速度计和陀螺仪的输出。在TSLiB中基于UEAloader类来读取数据集。
Heartbeat
Heartbeat数据集是一个心跳音频监测时序数据,根据心跳声音分为声音正常和异常两类。共有204训练用例和205个测试用例。在TSLiB中基于UEAloader类来读取数据集。
JapaneseVowels
JapaneseVowels数据集记录了来自9名男性日语说话者的语音时间序列。特征为12个LPC cepstrum coefficients,共有270训练用例和370个测试用例。在TSLiB中基于UEAloader类来读取数据集。
PEMS-SF
PEMS-SF数据描述了旧金山湾区高速公路不同车道的占用率,介于0和1之间。测量范围为2008年1月1日至2009年3月30日,每10分钟采样一次。数据库中的每一天视为一个维度为963(在整个研究期间持续运行的传感器数量)、长度为6x24=144的单一时间序列。共有267训练用例和173个测试用例。在TSLiB中基于UEAloader类来读取数据集。
SelfRegulationSCP
SelfRegulationSCP1和SelfRegulationSCP2数据集为深入研究自我调节相关的皮层慢电位时序数据数据集。数据集详细介绍见:A spelling device for the paralysed。在TSLiB中基于UEAloader类来读取数据集。
SpokenArabicDigits
SpokenArabicDigits数据集包含与口语阿拉伯数字对应的梅尔频率倒谱系数(MFCC)的时间序列。从44名男性和44名女性阿拉伯语母语者那里采集了由8800个(10 位数字 × 10 次重复 × 88 位说话者)样本。每个样本由13个梅尔频率倒谱系数(MFCCs)组成,以代表10个阿拉伯语口语数字。共有6599个训练用例和2199个测试用例。在TSLiB中基于UEAloader类来读取数据集。
UWaveGestureLibrary
UWaveGestureLibrary数据集是一个有关手势运动的时序数据集合。其中,时序数据是由每个运动对应的 X、Y、Z 坐标构成,且每个序列的长度为315。该数据集一共记录了8种不同的手势。共有120个训练用例和320个测试用例。在TSLiB中基于UEAloader类来读取数据集。
1.3.5 异常检测
异常检测在训练时类似于缺失值填补Imputation的训练方式,即训练模型重建输入数据,并使用MSEloss来计算重建误差。在测试阶段,模型尝试重建输入数据。如果重建误差高于某个阈值,则认为数据点是异常的。阈值通常设置为训练数据的高百分位数,这样只有那些重建误差极高的数据点才会被标记为异常。然后得到预测的异常标签,并与真实异常标签进行比较,计算准确率等评估指标。
| 数据集 | 数据输入特征数 | 序列长度 |
|---|---|---|
| MSL | 55 | 100 |
| PSM | 25 | 100 |
| SMAP | 25 | 100 |
| SMD | 38 | 100 |
| SWaT | 51 | 100 |
MSL
MSL(Mars Science Laboratory rover)数据集包含火星好奇号探测器的异常情况。输入为55个信道的探测数据。训练集无label,测试集有状态label。状态label为0或者1(0为信号没发送,而1信号代表已发送)。数据集更多介绍可查看https://github.com/khundman/telemanom。共有58317个训练用例、11664个验证用例(来自训练数据末端20%数据)和73729个测试用例。在TSLiB中基于MSLSegLoader类来读取数据集。在训练时,每次随机提取100个连续序列进行数据重建。
PSM
PSM数据集是从eBay公司的多个应用程序服务器节点内部收集的,共有132481个训练用例、26398个验证用例(来自训练数据末端20%数据)和87841个测试用例。在TSLiB中基于PSMSegLoader类来读取数据集。
SMAP
SMAP数据集是航天器数据集,输入为25个信道的探测数据。共有135084个训练用例、26938个验证用例(来自训练数据末端20%数据)和427518个测试用例。在TSLiB中基于SMAPSegLoader类来读取数据集。
SMD
SMD(服务器机组数据集,Server Machine Datase)由38个传感器数据组成。共有708405个训练用例、141681个验证用例(来自训练数据末端20%数据)和708420个测试用例。在TSLiB中基于SMDSegLoader类来读取数据集。
SWaT
SWaT数据集包含了水处理系统中传感器的时序异常数据。这些数据特征涵盖了来自51个传感器和执行器的信息。数据集记录了连续11天的运行情况,其中前7天为正常操作,后4天则模拟了遭受41次阶段性攻击的情况。数据的时间粒度为每秒一次。共有495000个训练用例、99000个验证用例(来自训练数据末端20%数据)和449919个测试用例。在TSLiB中基于SWATSegLoader类来读取数据集。
1.4 模型训练
TSLiB库为各种时序任务提供了不同模型的训练脚本,具体内容请参见TSLiB项目仓库的scripts文件夹。以数据集ETTh1为例,查看TimesNet在长时预测任务中的表现:
model_name=TimesNet
python -u run.py \
--task_name long_term_forecast \
--is_training 1 \
--root_path ./dataset/ETT-small/ \
--data_path ETTh1.csv \
--model_id ETTh1_96_96 \
--model $model_name \
--data ETTh1 \
--features M \
--seq_len 96 \
--label_len 48 \
--pred_len 96 \
--e_layers 2 \
--d_layers 1 \
--factor 3 \
--enc_in 7 \
--dec_in 7 \
--c_out 7 \
--d_model 16 \
--d_ff 32 \
--des 'Exp' \
--itr 1 \
--top_k 5
不同训练任务和不同模型对应不同的训练参数。这些训练参数的介绍可以通过项目run.py文件中argparse参数找到所有参数的含义和介绍:https://github.com/thuml/Time-Series-Library/blob/main/run.py#L19-L135。
在Linux环境下运行以下代码即可执行相关脚本。注意,不同模型的脚本中包含多次训练选项,需要提取并使用单次运行选项:
./scripts/long_term_forecast/ETT_script/TimesNet_ETTh1.sh
在训练过程中,会输出训练集、验证集和测试集的数据集损失。许多深度学习领域的代码库普遍倾向于在训练过程中实时打印测试集的损失数据。这种做法目的是为了快速调参,同时避免逐个测试数据集。但是在工程项目中这样做是不对的,因为测试数据泄露了。
Epoch: 2, Steps: 265 | Train Loss: 0.3978408 Vali Loss: 0.8001348 Test Loss: 0.3954313
在模型训练完成后,将立即进行模型测试,以评估模型在测试集上的表现。注意,TSLiB并未提供模型推理的代码,需要自行编写相关代码:
print('>>>>>>>start training : {}>>>>>>>>>>>>>>>>>>>>>>>>>>'.format(setting))
exp.train(setting)
print('>>>>>>>testing : {}<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(setting))
exp.test(setting)
torch.cuda.empty_cache()
训练好的模型权重保存在checkpoints文件夹中。测试集详细结果将保存到results文件夹中。此外还有详细的可视化结果,以PDF格式保存到test_results文件夹中,内容如下所示。

在上图中,横轴表示序列长度,纵轴则显示预测结果。由于数据在处理过程中经过归一化处理,预测结果和实际结果均为负值。需要注意的是,TimesNet模型在训练和推理阶段也会对输入数据进行归一化处理。
2 参考
- Time-Series-Library
- TimesNet: 时序基础模型,预测、填补、分类等五大任务领先
- TimesNet_tutorial.ipynb
- TimesBlock类
- TimesNet类
- TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis
- 时间序列论文标准数据集
- TimesNet复现结果
- M4
- A spelling device for the paralysed