【大模型LLMs】文本分块Chunking调研&LangChain实战
- Chunking策略类型
- 1. 基于规则的文本分块
- 2. 基于语义Embedding分块
- 3. 基于端到端模型的分块
- 4. 基于大模型的分块
- Chunking工具使用(LangChain)
- 1. 固定大小分块(字符&token)
- 2. 语义分块
总结目前主流的文本分块chunking方法,给出LangChain实现各类chunking方法的示例
Chunking策略类型
1. 基于规则的文本分块
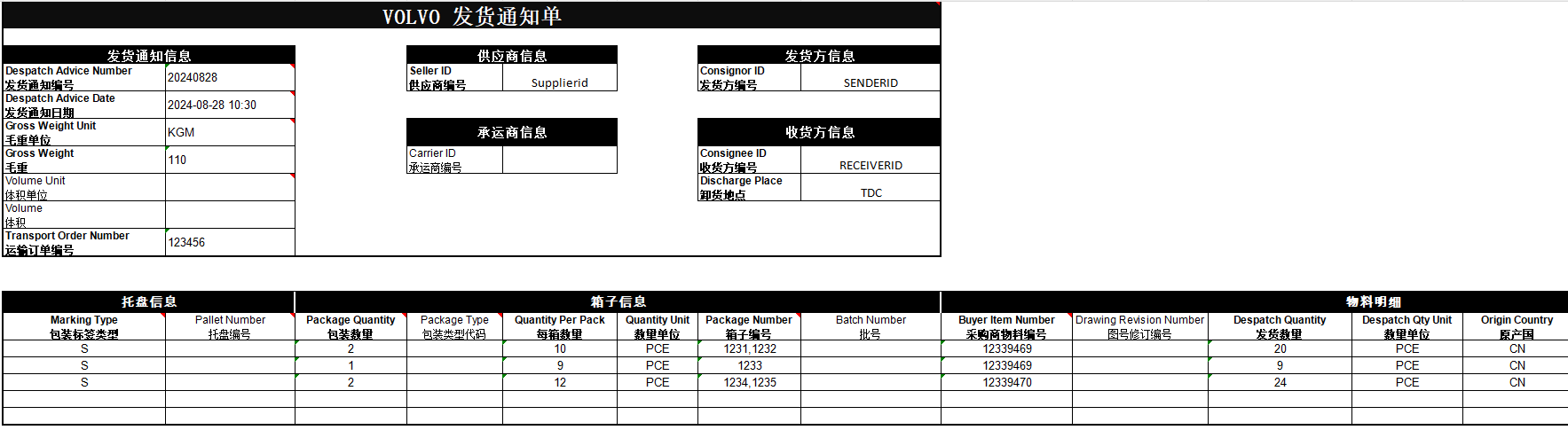
- 固定大小分块: 按照固定大小的字符数目/token数目以及特定的分隔符对文本进行切分,是最常见的分块方式,简单直接,不依赖NLP能力,成本低易于使用
- chunk_size: 块大小
- chunk_overlap: 重叠字符数目,允许不同块之间存在重复内容,以保证语义上下文的一致性和连贯性
- tokenizer: 分词模型(非必需,直接用原字符分块则无需tokenizer)
- 内容感知分块: 考虑文本本身的 语法/句法结构(显式的分隔符) 进行分块
- 依赖显式的分隔符进行切块: 常用的标点符号、空格字符、换行符等
- 依赖各类工具库: NLTK、spaCy等
- 结构感知分块: 主要针对Markdown或HTML等具有明确结构格式的文档,对文本进行解析
- 递归分块: 递归分块首先尝试按照一定的标准(如段落或标题)分割文本,如果分割后的文本块仍然过大,就会在这些块上重复进行分割过程,直到所有块的大小都符合要求
2. 基于语义Embedding分块
本质是基于滑动窗口的思想,依次计算相邻的两句话之间的语义相似度,满足阈值的视为表示同样的语义/主题,会划分到同一个块中,不满足阈值的则进行切分。
- 文本表征: 基于BERT、OpenAI的Embedding model等预训练模型对所有文本进行embedding,获得文本的语义特征向量
- 语义分析: 通过余弦相似度等方式计算两句话之间的语义关系
- 分块决策: 判断两句话之间是否需要分块,一般基于语义相似度,超过阈值则划分至同一个块,反之则切分;尽量保证每个分块的语义独立和完整
3. 基于端到端模型的分块
- NSP: 使用BERT模型的 下一句预测任务(Next Sentence Prediction,NSP) 判断两句话之间是否需要切分
- Cross-Segment: 采用跨片段的注意力机制来分析文本。首先利用BERT模型获取句子的向量表示,然后将连续多个句子的向量表示输入到另一个BERT或者LSTM模型中,一次性预测每个句子是否为分块的边界

- SeqModel:在Cross-Segment基础上,增强了上下文表示,并通过自适应滑动窗口的思想提高模型速度。相比Cross-Segment,SeqModel 可以同时处理更多句子,通过自注意力机制建模更长上下文和句子间的依赖关系

4. 基于大模型的分块
基本等效于single-document的summarization extraction任务,参考LLMs-based Summarization方法,通过知识蒸馏或提示工程的方式,让LLMs抽取文本中的要点
- 基于知识蒸馏的方法: 一般采用teacher-student架构,由GPT4类参数规模较大的LLMs作为teacher,从全文中抽取摘要作为“标准答案”,作为训练语料微调Llama2-7B类参数规模较小的LLMs(student)
- 基于CoT的方法: 设置预制问题/Plan规划等,让大模型按照要求给出回复
Chunking工具使用(LangChain)
1. 固定大小分块(字符&token)
from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter
def get_document_text(doc_path_list: list[str]) -> list[str]:
text_list = []
for doc_path in doc_path_list:
with open(doc_path, 'r', encoding='utf-8') as f:
text = f.read()
text_list.append(text)
return text_list
def character_chunking(text_list: list[str], character_type: str="char"):
if character_type == "char":
# 字符级
text_splitter = CharacterTextSplitter(
chunk_size=512,
chunk_overlap=128,
separator="\n",
strip_whitespace=True
)
elif character_type == "token":
# token级别
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
model_name="gpt-4",
chunk_size=512,
chunk_overlap=128,
separator="\n",
strip_whitespace=True
)
else:
return
chunking_res_list = text_splitter.create_documents(text_list)
for chunking_res in chunking_res_list:
print(chunking_res)
print("*"*100)
def recursive_character_chunking(text_list: list[str], character_type: str="char"):
if character_type == "char":
# 字符级
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
chunk_overlap=128,
separators=["\n\n", "\n", "。", ".", "?", "?", "!", "!"],
strip_whitespace=True
)
elif character_type == "token":
# token级别
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name="gpt-4",
chunk_size=512,
chunk_overlap=128,
separators=["\n\n", "\n", "。", ".", "?", "?", "!", "!"],
strip_whitespace=True
)
else:
return
chunking_res_list = text_splitter.create_documents(text_list)
for chunking_res in chunking_res_list:
print(chunking_res)
print("*"*100)
if __name__ == "__main__":
doc_path_list = [
'../data/chunking_test.txt'
]
text_list = get_document_text(doc_path_list)
# character_chunking(text_list)
recursive_character_chunking(text_list, character_type="token")

2. 语义分块
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
def get_document_text(doc_path_list: list[str]) -> list[str]:
text_list = []
for doc_path in doc_path_list:
with open(doc_path, 'r', encoding='utf-8') as f:
text = f.read()
text_list.append(text)
return text_list
def semantic_chunking(text_list: list[str]):
# embeddings = OpenAIEmbeddings() # 使用openai模型
embeddings = HuggingFaceBgeEmbeddings(
model_name = '../../../model/bge-base-zh-v1.5'
) # 使用huggingface的bge embeddings模型
text_splitter = SemanticChunker(
embeddings = embeddings,
breakpoint_threshold_type = "percentile", # 百分位数
breakpoint_threshold_amount = 30, # 百分比
sentence_split_regex = r"(?<=[。?!])\s+" # 正则,用于分句
)
chunking_res_list = text_splitter.create_documents(text_list)
for chunking_res in chunking_res_list:
print(chunking_res)
print("*"*100)
if __name__ == "__main__":
doc_path_list = [
'../data/chunking_test.txt'
]
text_list = get_document_text(doc_path_list)
semantic_chunking(text_list)