学习如何将大型语言模型连接到外部工具。
介绍
函数调用允许您将模型如gpt-4o与外部工具和系统连接起来。这对于许多事情都很有用,比如为AI助手赋能,或者在你的应用程序与模型之间建立深度集成。
在2024年8月,我们推出了结构化输出功能。当你在函数定义中通过设置strict: true来开启时,结构化输出确保模型为函数调用生成的参数完全符合你在函数定义中提供的JSON架构。
使用场景示例
函数调用在许多用例中都非常有用,例如:
使助手能够获取数据:当用户询问“我的最近订单是什么?”时,AI助手需要从内部系统中获取最新的客户数据,然后才能生成回应给用户。
使助手能够采取行动:AI助手需要根据用户的偏好和日历的空闲时间来安排会议。
使助手能够执行计算:一个数学辅导助手需要执行数学计算。
构建丰富的流程:一个数据提取管道首先获取原始文本,然后将其转换为结构化数据并保存到数据库中。
修改应用程序的UI:你可以使用函数调用根据用户输入更新UI,例如,在地图上渲染一个标记点。
函数调用的生命周期
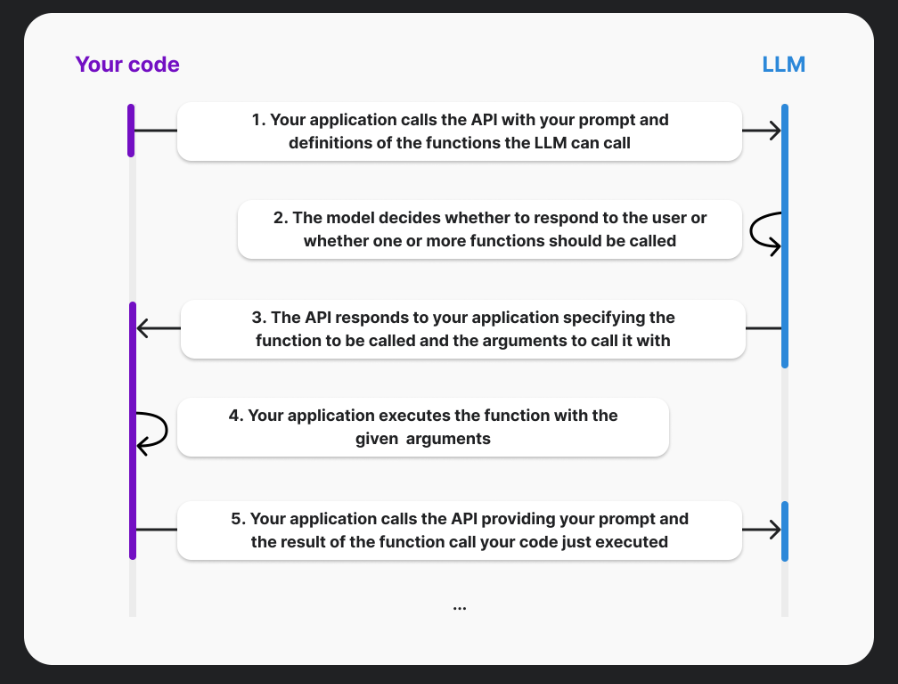
当您使用具有函数调用的OpenAI API时,模型实际上从不自行执行函数,而是在第3步中,模型仅生成可以用来调用您的参数,您的代码可以选择如何处理,很可能是通过调用指示的函数。您的应用程序始终完全掌控。
如何使用函数调用
在聊天补全API、助手API以及批量API中都支持函数调用。本指南重点介绍使用聊天补全API进行函数调用。我们还有一个单独的指南介绍使用助手API进行函数调用。
以下示例中,我们将构建一个对话助手,它能够帮助用户处理他们的配送订单。与让用户与典型表单互动不同,用户可以与一个由AI驱动的助手进行聊天。为了使这个助手更有帮助,我们希望它能够查询订单并回复用户订单的真实数据。
步骤1:在您的代码库中选择一个模型应该能够调用的函数
对于这个例子,让我们假设你希望允许模型生成调用你代码库中get_delivery_date函数所需的参数。该函数接受一个order_id并查询你的数据库,以确定给定包裹的发货日期。你的函数可能看起来像下面的样子。
# This is the function that we want the model to be able to call
def get_delivery_date(order_id: str) -> datetime:
# Connect to the database
conn = sqlite3.connect('ecommerce.db')
cursor = conn.cursor()
# ...
步骤2:向模型描述你的函数,以便它知道如何调用它
现在我们知道我们希望允许模型调用的功能,我们将创建一个“函数定义”,向模型描述该函数。这个定义既描述了函数的作用(以及可能调用它的时机),也说明了调用该函数所需的参数。
函数定义中的参数部分应该使用JSON Schema来描述。如果模型生成了函数调用,它将根据您提供的架构来生成参数。
在此示例中,它可能看起来像这样:
{
"name": "get_delivery_date",
"description": "Get the delivery date for a customer's order. Call this whenever you need to know the delivery date, for example when a customer asks 'Where is my package'",
"parameters": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "The customer's order ID.",
},
},
"required": ["order_id"],
"additionalProperties": false,
}
}
步骤3:将您的函数定义作为可用的“工具”传递给模型,同时附上消息内容
接下来,在调用聊天完成API时,我们需要在提供的“工具”数组中给出我们的函数定义。
与往常一样,我们将提供一个“消息”数组,其中可能包含你的提示或用户与助手之间的完整对话往复。
此示例展示了如何调用聊天完成API,为处理商店客户咨询的助手提供相关的函数和消息。
tools = [
{
"type": "function",
"function": {
"name": "get_delivery_date",
"description": "Get the delivery date for a customer's order. Call this whenever you need to know the delivery date, for example when a customer asks 'Where is my package'",
"parameters": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "The customer's order ID.",
},
},
"required": ["order_id"],
"additionalProperties": False,
},
}
}
]
messages = [
{"role": "system", "content": "You are a helpful customer support assistant. Use the supplied tools to assist the user."},
{"role": "user", "content": "Hi, can you tell me the delivery date for my order?"}
]
response = openai.chat.completions.create(
model="gpt-4o",
messages=messages,
tools=tools,
)
步骤4:接收并处理模型响应
如果模型决定不调用任何函数
如果模型没有生成函数调用,那么响应将包含一个直接的回复给用户,就像Chat Completions通常做的那样。
例如,在这种情况下,chat_response.choices[0].message 可能包含:
chat.completionsMessage(content='Hi there! I can help with that. Can you please provide your order ID?', role='assistant', function_call=None, tool_calls=None)
在助手使用场景中,你通常会希望向用户展示这个回应,并让他们对其进行回复,在这种情况下,你将再次调用API(将助手的最新回应和用户的回应都追加到消息中)。
假设我们的用户回应了他们的订单号,我们向API发送了以下请求。
tools = [
{
"type": "function",
"function": {
"name": "get_delivery_date",
"description": "Get the delivery date for a customer's order. Call this whenever you need to know the delivery date, for example when a customer asks 'Where is my package'",
"parameters": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "The customer's order ID."
}
},
"required": ["order_id"],
"additionalProperties": False
}
}
}
]
messages = []
messages.append({"role": "system", "content": "You are a helpful customer support assistant. Use the supplied tools to assist the user."})
messages.append({"role": "user", "content": "Hi, can you tell me the delivery date for my order?"})
// highlight-start
messages.append({"role": "assistant", "content": "Hi there! I can help with that. Can you please provide your order ID?"})
messages.append({"role": "user", "content": "i think it is order_12345"})
// highlight-end
response = client.chat.completions.create(
model='gpt-4o',
messages=messages,
tools=tools
)
如果模型生成了一个函数调用
如果模型生成了一个函数调用,它将根据您提供的参数定义生成调用参数。
以下是一个显示此情况的示例响应:
Choice(
finish_reason='tool_calls',
index=0,
logprobs=None,
message=chat.completionsMessage(
content=None,
role='assistant',
function_call=None,
tool_calls=[
chat.completionsMessageToolCall(
id='call_62136354',
function=Function(
arguments='{"order_id":"order_12345"}',
name='get_delivery_date'),
type='function')
])
)
处理模型响应以指示应调用某个函数的情况
假设响应表明应该调用一个函数,现在您的代码将处理这一点:
# 提取 get_delivery_date 的参数
# 请注意,此代码假设我们已经确定模型生成了一个函数调用。以下是一个更符合生产环境的示例,展示如何检查模型是否生成了函数调用
tool_call = response.choices[0].message.tool_calls[0]
arguments = json.loads(tool_call['function']['arguments'])
order_id = arguments.get('order_id')
# 使用提取的 order_id 调用 get_delivery_date 函数
delivery_date = get_delivery_date(order_id)
步骤5:将函数调用结果返回给模型
现在我们在本地执行了函数调用,我们需要将这个函数调用的结果反馈给聊天完成API,以便模型可以生成用户实际应该看到的响应:
# Simulate the order_id and delivery_date
order_id = "order_12345"
delivery_date = datetime.now()
# Simulate the tool call response
response = {
"choices": [
{
"message": {
"tool_calls": [
{"id": "tool_call_1"}
]
}
}
]
}
# Create a message containing the result of the function call
function_call_result_message = {
"role": "tool",
"content": json.dumps({
"order_id": order_id,
"delivery_date": delivery_date.strftime('%Y-%m-%d %H:%M:%S')
}),
"tool_call_id": response['choices'][0]['message']['tool_calls'][0]['id']
}
# Prepare the chat completion call payload
completion_payload = {
"model": "gpt-4o",
"messages": [
{"role": "system", "content": "You are a helpful customer support assistant. Use the supplied tools to assist the user."},
{"role": "user", "content": "Hi, can you tell me the delivery date for my order?"},
{"role": "assistant", "content": "Hi there! I can help with that. Can you please provide your order ID?"},
{"role": "user", "content": "i think it is order_12345"},
response['choices'][0]['message'],
function_call_result_message
]
}
# Call the OpenAI API's chat completions endpoint to send the tool call result back to the model
response = openai.chat.completions.create(
model=completion_payload["model"],
messages=completion_payload["messages"]
)
# Print the response from the API. In this case it will typically contain a message such as "The delivery date for your order #12345 is xyz. Is there anything else I can help you with?"
print(response)
这就是全部你所需要的,以便让gpt-4o访问你的函数。
处理边缘情况
当您从API接收到响应时,如果您没有使用SDK,生产代码应该处理许多边缘情况。
通常,API将返回一个有效的函数调用,但在某些边缘情况下不会这样,例如,当您指定了max_tokens并且模型的响应因此被截断时。
这个示例解释了它们:
# Check if the conversation was too long for the context window
if response['choices'][0]['message']['finish_reason'] == "length":
print("Error: The conversation was too long for the context window.")
# Handle the error as needed, e.g., by truncating the conversation or asking for clarification
handle_length_error(response)
# Check if the model's output included copyright material (or similar)
if response['choices'][0]['message']['finish_reason'] == "content_filter":
print("Error: The content was filtered due to policy violations.")
# Handle the error as needed, e.g., by modifying the request or notifying the user
handle_content_filter_error(response)
# Check if the model has made a tool_call. This is the case either if the "finish_reason" is "tool_calls" or if the "finish_reason" is "stop" and our API request had forced a function call
if (response['choices'][0]['message']['finish_reason'] == "tool_calls" or
# This handles the edge case where if we forced the model to call one of our functions, the finish_reason will actually be "stop" instead of "tool_calls"
(our_api_request_forced_a_tool_call and response['choices'][0]['message']['finish_reason'] == "stop")):
# Handle tool call
print("Model made a tool call.")
# Your code to handle tool calls
handle_tool_call(response)
# Else finish_reason is "stop", in which case the model was just responding directly to the user
elif response['choices'][0]['message']['finish_reason'] == "stop":
# Handle the normal stop case
print("Model responded directly to the user.")
# Your code to handle normal responses
handle_normal_response(response)
# Catch any other case, this is unexpected
else:
print("Unexpected finish_reason:", response['choices'][0]['message']['finish_reason'])
# Handle unexpected cases as needed
handle_unexpected_case(response)
具有结构化输出的函数调用
默认情况下,在使用函数调用时,API会为您的参数提供最佳努力匹配,这意味着在使用复杂的模式时,模型可能会偶尔遗漏参数或参数类型出错。
结构化输出是一项功能,它确保函数调用的模型输出将精确匹配您提供的模式。
通过提供一个参数strict: true,即可启用函数调用的结构化输出。
from enum import Enum
from typing import Union
from pydantic import BaseModel
import openai
from openai import OpenAI
client = OpenAI()
class GetDeliveryDate(BaseModel):
order_id: str
tools = [openai.pydantic_function_tool(GetDeliveryDate)]
messages = []
messages.append({"role": "system", "content": "You are a helpful customer support assistant. Use the supplied tools to assist the user."})
messages.append({"role": "user", "content": "Hi, can you tell me the delivery date for my order #12345?"})
response = client.chat.completions.create(
model='gpt-4o-2024-08-06',
messages=messages,
tools=tools
)
print(response.choices[0].message.tool_calls[0].function)
当您提供 strict: true 来启用结构化输出时,OpenAI API 将在您的第一个请求中对您提供的架构进行预处理,并使用这个工件来约束模型遵循您的架构。
因此,除非在少数情况下,模型将始终遵循您的确切架构:
- 当模型的响应被截断(由于max_tokens、停止令牌或最大上下文长度)。
- 当发生模型拒绝行为时。
- 当出现内容过滤器结束原因时。
支持的架构(或模式)
函数调用支持结构化输出,这部分输出是JSON架构语言的一个子集。
有关支持的模式的信息,请参阅结构化输出指南。
自定义函数调用行为
函数调用支持许多高级功能,例如强制函数调用、并行函数调用等。
配置并行函数调用
自2023年11月6日或以后发布任何模型可能会在单个响应中默认产生多个函数调用,表明这些调用应当并行执行。
这对于执行给定函数需要很长时间的情况特别有用。例如,模型可能同时调用获取3个不同地点天气的函数,这将导致工具调用数组中含有3个函数调用的一条消息。
示例响应:
response = Choice(
finish_reason='tool_calls',
index=0,
logprobs=None,
message=chat.completionsMessage(
content=None,
role='assistant',
function_call=None,
tool_calls=[
chat.completionsMessageToolCall(
id='call_62136355',
function=Function(
arguments='{"city":"New York"}',
name='check_weather'),
type='function'),
chat.completionsMessageToolCall(
id='call_62136356',
function=Function(
arguments='{"city":"London"}',
name='check_weather'),
type='function'),
chat.completionsMessageToolCall(
id='call_62136357',
function=Function(
arguments='{"city":"Tokyo"}',
name='check_weather'),
type='function')
])
)
# Iterate through tool calls to handle each weather check
for tool_call in response.message.tool_calls:
arguments = json.loads(tool_call.function.arguments)
city = arguments['city']
weather_info = check_weather(city)
print(f"Weather in {city}: {weather_info}")
每个数组中的函数调用都有一个唯一的ID。
在你的应用程序中执行了这些函数调用后,你可以通过为每个函数调用添加一条新消息来向模型提供结果,每条消息都包含一个函数调用的结果,并带有引用自 tool_calls 的 id 的 tool_call_id,例如:
# Assume we have fetched the weather data from somewhere
weather_data = {
"New York": {"temperature": "22°C", "condition": "Sunny"},
"London": {"temperature": "15°C", "condition": "Cloudy"},
"Tokyo": {"temperature": "25°C", "condition": "Rainy"}
}
# Prepare the chat completion call payload with inline function call result creation
completion_payload = {
"model": "gpt-4o",
"messages": [
{"role": "system", "content": "You are a helpful assistant providing weather updates."},
{"role": "user", "content": "Can you tell me the weather in New York, London, and Tokyo?"},
# Append the original function calls to the conversation
response['message'],
# Include the result of the function calls
{
"role": "tool",
"content": json.dumps({
"city": "New York",
"weather": weather_data["New York"]
}),
# Here we specify the tool_call_id that this result corresponds to
"tool_call_id": response['message']['tool_calls'][0]['id']
},
{
"role": "tool",
"content": json.dumps({
"city": "London",
"weather": weather_data["London"]
}),
"tool_call_id": response['message']['tool_calls'][1]['id']
},
{
"role": "tool",
"content": json.dumps({
"city": "Tokyo",
"weather": weather_data["Tokyo"]
}),
"tool_call_id": response['message']['tool_calls'][2]['id']
}
]
}
# Call the OpenAI API's chat completions endpoint to send the tool call result back to the model
response = openai.chat.completions.create(
model=completion_payload["model"],
messages=completion_payload["messages"]
)
# Print the response from the API, which will return something like "In New York the weather is..."
print(response)
并行函数调用和结构化输出
当模型通过并行函数调用输出多个函数调用时,模型的输出可能不符合工具中提供的严格模式。
为了确保严格遵守模式,请通过提供 parallel_tool_calls: false 来禁用并行函数调用。在此设置下,模型将一次生成一个函数调用。
使用tool_choice参数配置函数调用行为
默认情况下,模型配置为自动选择要调用的函数,这由“tool_choice: ‘auto’”设置决定。
我们提供了三种方法来自定义默认行为:
- 若要强制模型始终调用一个或多个函数,可以将“tool_choice”设置为“required”。然后模型将始终选择一个或多个要调用的函数。这对于例如你想让模型在多个动作之间选择执行下一个时很有用。
- 若要强制模型调用特定函数,可以设置“tool_choice”:{“type”: “function”, “function”: {“name”: “my_function”}}。
- 若要禁用函数调用并强制模型仅生成面向用户的消息,可以不提供任何工具,或者设置“tool_choice: ‘none’”。
请注意,如果你执行1或2(即强制模型调用一个函数),那么随后的“finish_reason”将是“stop”而不是“tool_calls”。
from openai import OpenAI
client = OpenAI()
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"strict": True,
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string"},
"unit": {"type": "string", "enum": ["c", "f"]},
},
"required": ["location", "unit"],
"additionalProperties": False,
},
},
},
{
"type": "function",
"function": {
"name": "get_stock_price",
"strict": True,
"parameters": {
"type": "object",
"properties": {
"symbol": {"type": "string"},
},
"required": ["symbol"],
"additionalProperties": False,
},
},
},
]
messages = [{"role": "user", "content": "What's the weather like in Boston today?"}]
completion = client.chat.completions.create(
model="gpt-4o",
messages=messages,
tools=tools,
# highlight-start
tool_choice="required"
# highlight-end
)
print(completion)
理解令牌使用
在幕后,函数以模型训练时所用的语法被注入到系统消息中。这意味着函数会占用模型的内容限制,并且对函数的参数描述长度进行计费,作为输入令牌。如果您遇到了令牌限制,我们建议您限制函数的数量或提供函数参数描述的长度。
如果您在工具规范中定义了大量的函数,也可以使用微调来减少使用的令牌数量。
技巧和最佳实践
开启结构化输出,将strict设置为true
当启用结构化输出时,模型为函数调用生成的参数将可靠地匹配您提供的JSON模式。
如果您没有使用结构化输出,那么参数的结构不能保证是正确的,因此我们建议先使用像Pydantic这样的验证库来验证参数,然后再使用它们。
直观地命名函数,并附上详细描述
如果你发现模型没有生成对正确函数的调用,你可能需要更新你的函数名称和描述,以便模型更清楚地理解何时选择每个函数。避免使用缩写或首字母缩略词来缩短函数和参数名称。
你也可以为工具何时被调用包含详细的描述。对于复杂的函数,你应该为每个参数包含描述,以帮助模型知道它需要向用户收集哪个参数。
为函数参数直观命名,并附上详细描述
为函数参数使用清晰且描述性的名称。例如,在描述中指定日期参数的预期格式(例如:YYYY-MM-dd 或 dd/mm/yy)。
考虑在系统消息中提供关于何时以及如何调用函数的额外信息
在系统消息中提供清晰的指令可以显著提高模型功能调用的准确性。例如,指导模型在用户询问订单状态时使用“check_order_status”,比如用户说“我的订单在哪里?”或“我的订单还没发货吗?”。在复杂场景中提供上下文,比如“在使用schedule_meeting安排会议之前,使用check_availability检查用户的日历是否有空,以避免冲突。”
在可能的情况下使用枚举作为函数参数
如果您的使用案例允许,您可以使用枚举来限制参数的可能值。这有助于减少幻觉。
例如,假设您有一个AI助手,用于帮助订购T恤。T恤的尺码很可能有一个固定的集合,并且您可能希望模型以特定的格式输出。如果您希望模型输出“s”、“m”、“l”等来代表小号、中号和大号,那么您可以在枚举中提供这些值,例如:
{
"name": "pick_tshirt_size",
"description": "Call this if the user specifies which size t-shirt they want",
"parameters": {
"type": "object",
"properties": {
"size": {
"type": "string",
"enum": ["s", "m", "l"],
"description": "The size of the t-shirt that the user would like to order"
}
},
"required": ["size"],
"additionalProperties": false
}
}
如果不限制输出,用户可能会说“大”或“L”,而模型可能会返回这两个任一值。您的代码可能期待一个特定的结构,因此限制模型可以选择的格式数量非常重要。
保持少量函数以获得更高准确度
我们建议在单个工具调用中使用不超过20个函数。一旦有10-20个工具,开发者通常会发现模型选择正确工具的能力有所下降。
如果您的用例需要模型能够在大量函数之间进行选择,您可能需要探索微调或按逻辑将工具划分并组建多代理系统。
设置评估以辅助在提示工程中定义你的函数和系统消息
对于非平凡的函数调用使用情况,我们建议您设置一套评估,以测量在广泛的可能用户消息中,正确函数被调用的频率或为正确参数生成的频率。在OpenAI Cookbook上了解更多关于设置评估的信息。
然后,您可以利用这些评估来衡量对函数定义和系统消息的调整是否会提高或损害您的集成效果。
微调可能有助于提高函数调用的准确性
对模型进行微调可以提升在你的用例中函数调用的性能,特别是当你拥有大量函数,或者函数复杂、细微且相似时。
FAQ
函数与工具的区别是什么?
在使用函数调用的OpenAI API时,您将它们作为工具提供,通过tool_choice进行配置,并监控finish_reason: “tool_calls”。
像functions和function_call这样的参数名现在已经弃用了。
我应该将函数调用指令包含在工具规范中还是系统提示中?
我们建议在系统提示中包含关于何时调用函数的指令,同时使用函数定义来提供关于如何调用函数以及如何生成参数的说明。
哪些模型支持函数调用?
函数调用是在2023年6月13日发布gpt-4-turbo时引入的。这包括:gpt-4o、gpt-4o-2024-08-06、gpt-4o-2024-05-13、gpt-4o-mini、gpt-4o-mini-2024-07-18、gpt-4-turbo、gpt-4-turbo-2024-04-09、gpt-4-turbo-preview、gpt-4-0125-preview、gpt-4-1106-preview、gpt-4、gpt-4-0613、gpt-3.5-turbo、gpt-3.5-turbo-0125、gpt-3.5-turbo-1106和gpt-3.5-turbo-0613。
在此日期之前发布的旧版模型未经过训练以支持函数调用。
并行函数调用支持在2023年11月6日或之后发布的模型上。这包括:gpt-4o、gpt-4o-2024-08-06、gpt-4o-2024-05-13、gpt-4o-mini、gpt-4o-mini-2024-07-18、gpt-4-turbo、gpt-4-turbo-2024-04-09、gpt-4-turbo-preview、gpt-4-0125-preview、gpt-4-1106-preview、gpt-3.5-turbo、gpt-3.5-turbo-0125和gpt-3.5-turbo-1106。
一些示例函数是什么?
数据检索:
情景:当用户问“我的顶级客户是谁?”时,聊天机器人需要从内部系统获取最新的客户数据。
实现:定义一个函数get_customers(min_revenue: int, created_before: string, limit: int),从内部API检索客户数据。模型可以根据用户输入建议使用适当的参数调用此函数。
任务自动化:
情景:一个助手机器人根据用户的偏好和日历可用性安排会议。
实现:定义一个函数scheduleMeeting(date: str, time: str, participants: list),与日历API交互。模型可以建议最佳调用此函数的时间和日期。
计算任务:
情景:一个财务应用程序根据用户输入计算贷款付款。
实现:定义一个函数calculateLoanPayment(principal: float, interestRate: float, term: int)来执行必要的计算。模型可以为此函数提供输入值。
客户支持:
情景:一个客户支持机器人通过提供订单状态帮助用户。
实现:定义一个函数getOrderStatus(orderId: str),从数据库检索订单状态信息。模型可以根据用户输入建议使用适当的订单ID参数调用此函数。
模型可以自己执行函数吗?
不可以,模型仅建议函数调用并生成参数。您的应用程序根据这些建议处理函数的执行(并将调用这些函数的结果返回给模型)。
什么是结构化输出?
结构化输出是在2024年8月引入的一项功能,确保模型生成的参数与提供的JSON Schema完全匹配,提高了可靠性和减少了错误。我们建议使用这个功能,可以通过设置"strict": true来启用。
为什么我可能不想打开结构化输出?
不使用结构化输出的主要原因是:
如果您需要使用JSON Schema尚未支持的功能(了解更多),例如递归模式。
如果您的每个API请求都会包含一个新颖的架构(即您的架构不是固定的,而是按需生成的,并且很少重复),因为第一个包含新颖JSON Schema的请求将由于架构预处理和缓存而延迟增加,以便为未来的生成约束模型的输出。
如何确保模型调用正确的函数?
为函数和参数使用直观的名称和详细的描述。在系统消息中提供清晰的指导,以提高模型选择正确函数的能力。
结构化输出对零数据保留意味着什么?
当启用结构化输出时,提供的架构不符合零数据保留条件。
资源
OpenAI Cookbook有几个端到端的例子,可以帮助您实现函数调用。在我们的介绍性食谱《如何用聊天模型调用函数》中,我们概述了两个模型的例子,展示了如何使用函数调用。在您开始时,这是一个很好的资源来参考。
您可以在OpenAI Cookbook中找到更多帮助您开始使用函数调用的示例。
来源
https://platform.openai.com/docs/guides/function-calling