1、msgpack介绍
1.MsgPack产生的数据更小,从而在数据传输过程中网络压力更小
2.MsgPack兼容性差,必须按照顺序保存字段
3.MsgPack是二进制序列化格式,兼容跨语言
官网地址: https://msgpack.org/
官方介绍:It's like JSON. but fast and small.
压缩规范表:https://github.com/msgpack/msgpack/blob/master/spec.md?plain=1
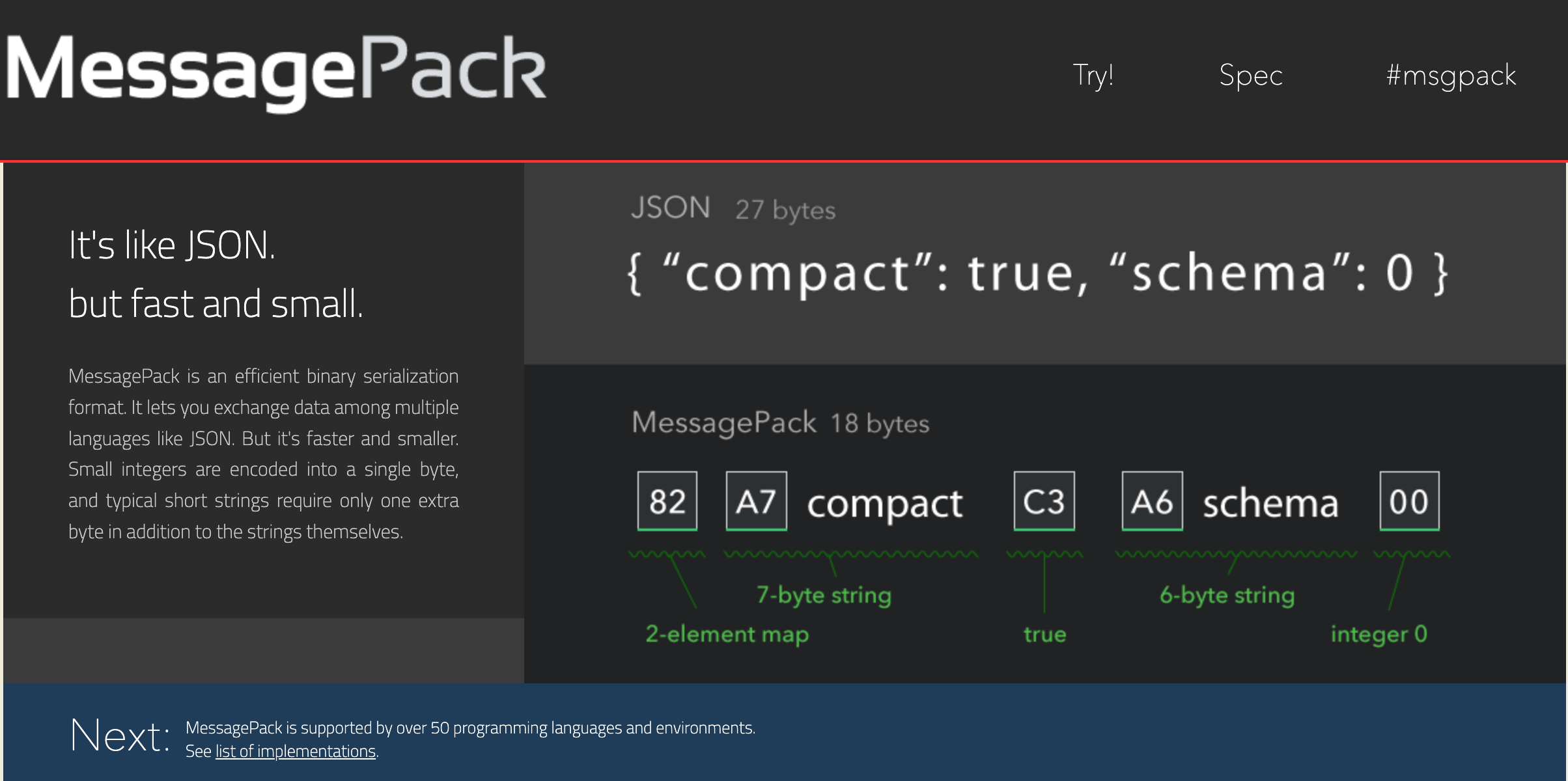
简单分析msgpack例子
json格式:{"age":14, "subject":["math", "chinese", "english"]}
msgpack格式: 82 a3 61 67 65 0e a7 73 75 62 6a 65 63 74 93 a4 6d 61 74 68 a7 63 68 69 6e 65 73 65 a7 65 6e 67 6c 69 73 68
解读:
82 :两组map,即两组key-value pairs of objects
a3 61 67 65 :第一组map的key,类型为fixstr为 "age"
0e :第一组map的value,类型为positive fixint为14
a7 73 75 62 6a 65 63 74 :第二组map的key,类型为fixstr为“subject”
93 a4 6d 61 74 68 a7 63 68 69 6e 65 73 65 a7 65 6e 67 6c 69 73 68 :第二组map的value是个array,元素内容为str
a4 6d 61 74 68:第一个数组对象类型为fixstr为"math"
a7 63 68 69 6e 65 73 65 :第二个数组对象类型为fixstr为"chinese"
a7 65 6e 67 6c 69 73 68:第三个数组对象类型为fixstr为"english"
拼装起来就是{ "compact" : true , "schema" : 0 }
具体magpack的核心压缩方式可参看官方说明messagepack specification,这里就不细介绍了
2、Hessian序列化介绍
hessian是一种基于二进制的远程调用协议。占用空间小,跨语言,反序列化快
hessian会把复杂对象所有属性存储在一个 Map 中进行序列化,通过名称进行取值
3、hessian和msgpack对比
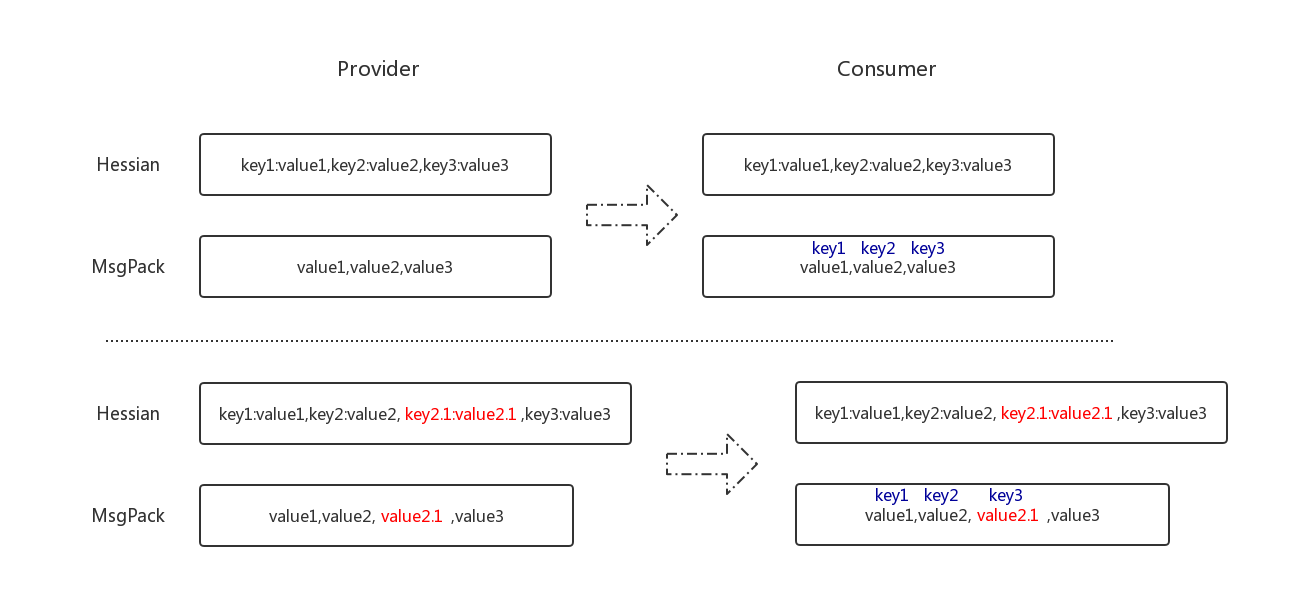
通过以上两种协议的实现原理,我们可以清楚的明白为什么msgpack从中间新加变量为什么会出错了
4、为什么从中间添加字段调用方会序列化报错?
【原因分析】:Msgpack是按字段顺序进行序列化和反序列化的,其缺点是无法改变字段顺序。
【解决方案】:
因Msgpack序列化不能改变字段顺序,所以在两边不同时升级的情况下,字段兼容规则如下:
1、不要调整原有字段顺序,不能删减字段,除非是删最后一个字段。
2、新加的字段必须在字段最后面(只是字段顺序,不是文件最后面,getter/setter方法等随意)。
3、父类的字段不能变。因为父类一变相当于子类的中间插入一个字段。
满足上面规则,服务端和客户端哪边先升级都无所谓。
如果是需要父类加字段,或者中间加减字段这种,则需要服务端和调用端同时升级。