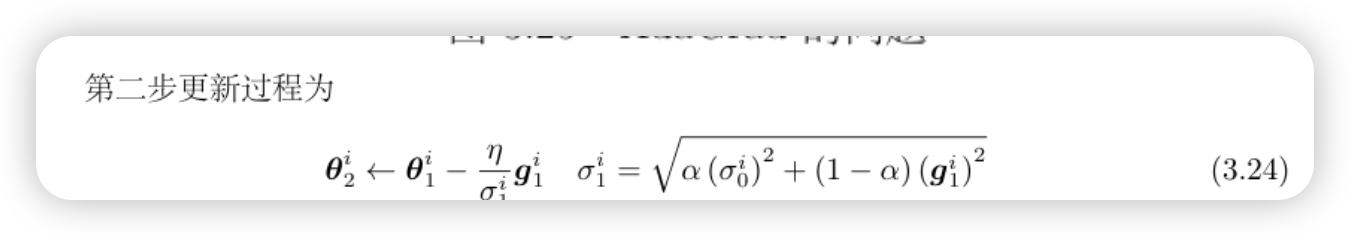- 标题:ORLM: Training Large Language Models for Optimization Modeling
- 文章链接:ORLM: Training Large Language Models for Optimization Modeling
- 代码:Cardinal-Operations/ORLM
- 发表:2024
- 领域:使用 LLM 解决运筹优化问题
- 摘要:得益于大型语言模型(LLMs)的优化建模能力,其已成为处理复杂运筹学(OR)问题的强大工具。然而,目前的方法严重依赖于提示工程(如不同 prompt 诱导的 multi-agent 协作)和专有 LLMs,在工业应用场景中这可能导致敏感的数据泄露问题。为了解决这一问题,我们建议针对 “自然语言->优化问题建模” 任务训练开源领域 LLMs。我们确定了构造 OR LLMs 训练数据集的四个关键要求,并提出了 OR-Instruct 数据合成框架,可以针对特定要求半自动化地创建合成数据。我们还介绍了 IndustryOR benchmark,这是第一个用于测试 LLMs 在解决实际 OR 问题上的工业基准。我们将 OR-Instruct 的合成数据应用于多个 7b 大小的开源 LLMs(称为ORLMs),显著提高了模型的优化问题建模能力。我们最佳表现的 ORLM 在 NL4OPT、MAMO 和 IndustryOR 基 准测试上取得了最佳性能
文章目录
- 1 方法
- 2. 实验
- 3. 结论
1 方法
- 本文研究复杂运筹学 (OR) 问题的自动建模与编程,以减轻对人类专家的严重依赖。具体而言,这类问题要求输入一段自然语言描述的显示工业问题(比如配送货、生产规划等问题),要求模型或系统写出求解问题的代码(比如调用启发式求解器等)
- 过去的方法大多使用多个 LLM 构建 multi agent 协作框架,每个 agent 复制整个管线的一部分,比如术语解释、数学建模、代码生成、代码运行评估等,它们通过 “多步问题分解” 和 “反思循环纠错” 来生成正确的求解代码。作者认为这种方法有两个问题
- 误差会在多步分解中被积累,影响泛化性能
- 过去方法大多使用预训练的 LLM,通过 prompting engineering 来配置各个 agent。这意味着求解过程中,具体工业问题的敏感信息将被上传到 LLM 服务提供商(如 OpenAI)等,会导致隐私问题
- 针对以上问题,作者提出通过训练单一 LLM 本地运行来解决以上两个问题。因此这里的核心问题被转换为如何构造良好的训练数据,数据形式为
(
p
,
m
,
c
)
(p,m,c)
(p,m,c),其中
p
p
p 为自然语言描述的问题,
m
m
m 为问题的数学建模,
c
c
c 为求解代码(调用 COPT 求解器),整个系统可以表示为一个映射
f
:
p
→
(
m
,
c
)
f:p\to (m,c)
f:p→(m,c) 作者认为训练数据集应该满足以下四个关键需求
- 为了提高模型鲁棒性,数据集应该涵盖各种场景、问题类型和不同难度
- 由于业务目标、市场条件或资源可用性的变化,运筹问题的优化目标和约束条件可能经常发生变化,数据集应该反映这些变化
- 由于不同客户可能会使用不同的术语来描述相同的问题,数据集应该适应这种语言多样性
- 对于同一个问题,可以有多种数学建模方案(例如通过引入辅助变量把多项式优化转为线性优化),数据集中应该包含这种数据
- 作者提出了一个半自动化方法来合成具有以上性质的高质量数据,如下图所示

- 从一组种子数据开始(686个来自不用行业的问题+求解数据),将它们添加到数据池中
- 使用两种策略扩展数据,将合成数据添加到数据池中
- 数据扩展:使用 GPT-4 生成涵盖更广泛的场景和问题类型的数据。每次迭代,从数据集采样 3 个样本(如果存在合成样本,则有1个是合成的)作为示例,使用一个预置的 prompt 模板进行 in-context learning 来生成扩展数据,上下文长度限制在 GPT-4 最大长度以内。这种方法部分扩展了场景和问题类型的覆盖度(要求 1),但是无法满足其他 3 个要求
- 数据增强:使用三种增强手段,满足以上其他数据要求
- 修改目标和约束(要求 2):使用预置 prompt 模板进行 in-context learning 来实现。首先向 GPT-4 提供原始例子,要求其首先列出优化目标和约束条件的 5 个潜在变化, 然后把潜在变化和一个 few-shot 提示模板组合后再次输入 GPT-4,从而相应地修改问题、模型和程序。
- 重新描述问题(要求 3):使用预置 prompt 模板,要求 GPT-4 修改问题的表述,在确保核心逻辑与解决方案保持一致的情况下使其简化或复杂化,从而模拟不同客户的表达习惯
- 扩展数学建模方案(要求 4):作者从工程师的经验中确定了五种常用数学建模技术(如引入辅助变量或使用 Big M 方法),使用预置 prompt 模板,要求 GPT-4 使用新的建模技术重写问题的数学建模方案
- 最后,使用启发式方法自动过滤出明显低质量的数据,通过数据扩展合成的数据正确性约70%,通过数据增强合成的数据正确性约75%。以上整个过程可以多次迭代,直到总数据量达到要求为止
2. 实验
- 作者使用以上流程,将 686 个种子数据扩展为拥有 30k 数据的 OR-INSTRUCT 数据集,行业分布和问题类型分布如下

- 作者使用以上数据集微调了几个 7B 左右规模的开源 LLM,包括 Mistral-7B、Deepseek-math-7B 和 LLaMA-3-8B
- 训练过程中,数据被包装为类似 Alpaca 的模板进行训练,输入数据的 ( p , m , c ) (p,m,c) (p,m,c) 问题的 p p p 部分,要求模型预测出 m , c m,c m,c,仅在预测部分计算损失
- 评估过程中,输入目标问题描述 p p p,使用 greedy 解码策略生成 m , c m,c m,c,从中提取程序 c c c 并执行以得到模型解的量化性能
3. 结论
-
作者在 NL4OPT、 IndustryOR 和 MAMO 三个 benchmark 上评估模型性能,对比方法包括 NIPS 竞赛冠军方法 tag-BART、多 LLM agent 方法 Chain-of-Experts 和 OptiMUS 等。实验结果显示,经过 OR-INSTRUCT 数据集微调的 LLaMA-3-8B 模型(记为 ORLM-LLaMA-3-8B)在所有 benchmark 上取得了 SOTA 性能,大幅超越了所有 Baseline 方法,相比直接使用 GPT-4 求解(记为 Stander)平均提升 55.4%
- 在分问题难度评估时,ORLM-LLaMA-3-8B 在所有难度的问题上超越 Stander GPT-4,尤其是在困难问题上超越更多
- 在分问题类型评估时,ORLM-LLaMA-3-8B 和 Stander GPT-4 都无法求解任何非线性规划和某些罕见类型问题,这可能是因为这些类型的问题过于复杂,且数据量不足
总的来说,本文提出的数据合成方法有效提升了问题类型和难度的覆盖度
-
作者进一步进行消融实验,验证三种数据增强方案的有效性。具体而言
- 从 OR-INSTRUCT 数据集中选择了一个 4 个尺寸为 3k 的子集,第一个应用了所有三种数据增强方法,其他三个分别剔除某种增强数据
- 使用选出的 4 个数据集微调具有相同超参数的 LLaMA-3-8B 模型,对比性能
发现去除任何一种增强方法都会导致性能下降,说明三种增强方法都有效,其中 “重新描述问题” 对性能影响最大
-
本文关注的运筹优化问题确实是一个非常现实的问题,对于生产生活中遇到的具体优化问题,使用这种方法,不再需要专家进行数学建模,只需普通工人用自然语言描述问题即可求解,这个具体问题上已经产生了多篇相关文章