目录
前言
一、K-means算法
1.K-means算法概念
2.具体步骤
3.精彩动图
4.算法效果评价
二、代码实现
1.完整代码
2.结果展示
3.步骤解析
1.数据预处理
2.建立并训练模型
3.打印图像
四、算法优缺点
1.优点
2.缺点
总结
前言
机器学习里除了分类算法,回归算法,还有聚类算法,这里讲的k均值算法便是其中一种
一、K-means算法
1.K-means算法概念
K均值(K-Means)算法是一种常见的聚类算法,用于将数据集分成预定数量的簇(k个簇)。算法的目标是将数据点划分到k个簇中,以最小化簇内数据点之间的平方距离的总和。
2.具体步骤
-
初始化簇中心:
随机选择k个数据点作为初始簇中心,或者通过某些启发式方法选择。 -
分配数据点:
将每个数据点分配到离它最近的簇中心所对应的簇中。 -
更新簇中心:
计算每个簇内所有数据点的均值,并将簇中心更新为这个均值。 -
重复:
重复步骤2和3,直到簇中心的变化非常小或达到最大迭代次数为止。 -
结束:
算法收敛,簇中心不再变化或变化非常小,最终得到的簇划分即为聚类结果。
3.精彩动图
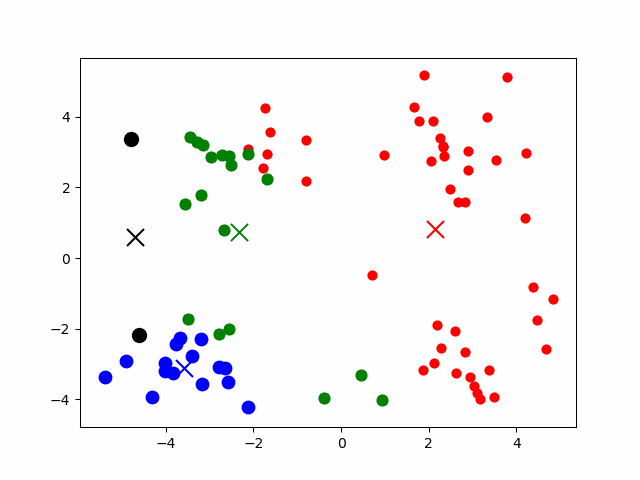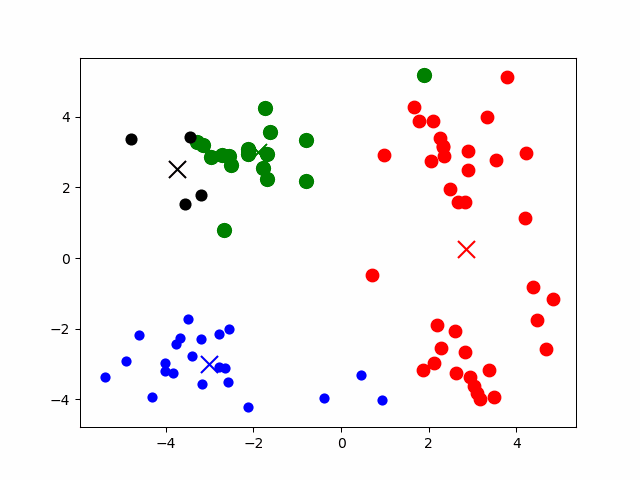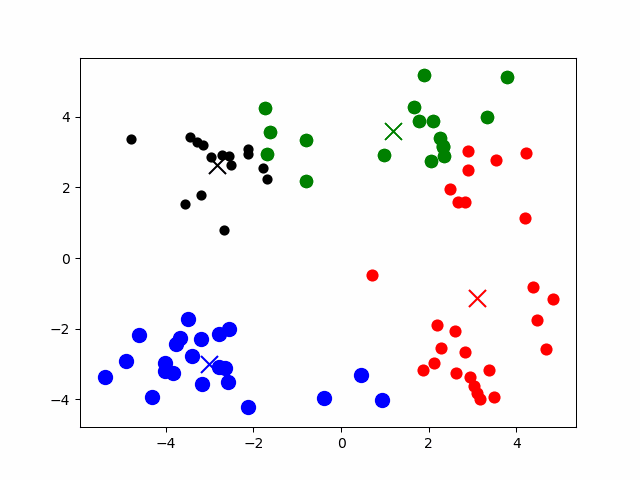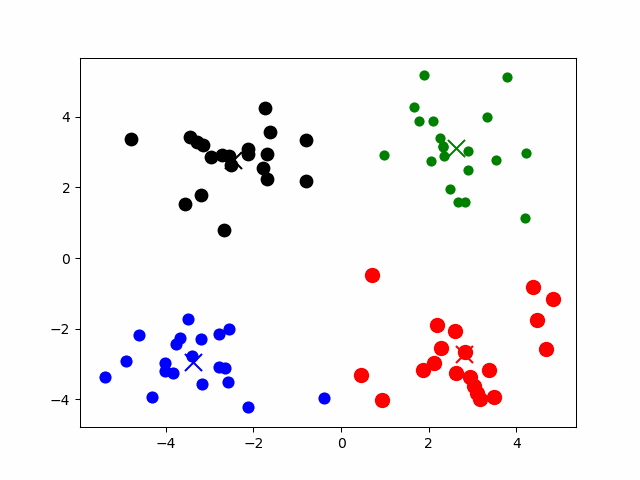
4.算法效果评价
- 轮廓系数(Silhouette Score)是用于评估聚类效果的指标。它衡量了数据点在其簇内的一致性和与其他簇的分隔度。轮廓系数的值范围从 -1 到 1,值越高表示聚类效果越好。


二、代码实现
1.完整代码
- 代码完成的是对学生的分类
import pandas as pd
# data = pd.read_csv('data.txt', sep=' ')
# x = data.iloc[:, 1:5]
from sklearn.preprocessing import StandardScaler
data = pd.read_csv('datingTestSet2.txt', sep='\t', header=None)
x = data.iloc[:, 0:3]
std = StandardScaler()
x = std.fit_transform(x)
"""
根据分成不同的簇,自动计算轮廓系数得分
"""
from sklearn.cluster import KMeans
from sklearn import metrics
scores = []
for k in range(2, 10): # 选取最佳的簇数
labels = KMeans(n_clusters=k).fit(x).labels_ # 簇标签
score = metrics.silhouette_score(x, labels) # 轮廓系数
scores.append(score)
print(scores)
best_k = scores.index(max(scores)) + 2
print(best_k)
labels = KMeans(n_clusters=best_k).fit(x).labels_
score = metrics.silhouette_score(x, labels)
print(labels, score)
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体
plt.rcParams['axes.unicode_minus'] = False # 解决符号显示为方块的问题
# 绘制轮廓系数得分与簇数量的关系图
plt.figure(figsize=(8, 6))
plt.plot(range(2, 10), scores, marker='o')
plt.xlabel('簇数量 (k)')
plt.ylabel('轮廓系数')
plt.title('簇数量与轮廓系数')
plt.xticks(range(2, 10))
plt.grid(True)
plt.show()
# 打印最佳簇数量
best_k = scores.index(max(scores)) + 2
print(f"最佳簇数量: {best_k}")
2.结果展示
- 因为数据比较分散,所以轮廓系数比较低

3.步骤解析
1.数据预处理
- 导入pands库
- 导入数据,取出特征数据
- 对数据进行标准化
import pandas as pd
# data = pd.read_csv('data.txt', sep=' ')
# x = data.iloc[:, 1:5]
from sklearn.preprocessing import StandardScaler
data = pd.read_csv('datingTestSet2.txt', sep='\t', header=None)
x = data.iloc[:, 0:3]
std = StandardScaler()
x = std.fit_transform(x)
2.建立并训练模型
- 利用for循环找到模型内某个参数在某个范围内的最佳值
"""
根据分成不同的簇,自动计算轮廓系数得分
"""
from sklearn.cluster import KMeans
from sklearn import metrics
scores = []
for k in range(2, 10): # 选取最佳的簇数
labels = KMeans(n_clusters=k).fit(x).labels_ # 簇标签
score = metrics.silhouette_score(x, labels) # 轮廓系数
scores.append(score)
print(scores)
best_k = scores.index(max(scores)) + 2
print(best_k)
labels = KMeans(n_clusters=best_k).fit(x).labels_
score = metrics.silhouette_score(x, labels)
print(labels, score)
3.打印图像
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体
plt.rcParams['axes.unicode_minus'] = False # 解决符号显示为方块的问题
# 绘制轮廓系数得分与簇数量的关系图
plt.figure(figsize=(8, 6))
plt.plot(range(2, 10), scores, marker='o')
plt.xlabel('簇数量 (k)')
plt.ylabel('轮廓系数')
plt.title('簇数量与轮廓系数')
plt.xticks(range(2, 10))
plt.grid(True)
plt.show()
四、算法优缺点
1.优点
- 简单易实现。
- 计算效率较高,适用于大规模数据集。
2.缺点
- 需要事先指定k的值,且k的选择可能影响结果。
- 对初始簇中心敏感,可能会收敛到局部最优解。
- 不适用于具有非凸形状簇的数据集。
- 对噪声和异常值敏感。
总结
K均值是一种迭代的聚类算法,旨在将数据集分成k个簇,使得每个簇的内部数据点尽可能相似,而不同簇的数据点尽可能不同。