自从 Neo4j 宣布与 LangChain 的集成以来,我们已经看到许多围绕使用 Neo4j 和大语言模型(LLM)构建检索增强生成(RAG)系统的用例。这导致了近年来知识图谱在 RAG 中使用的快速增加。基于知识图谱的 RAG 系统在处理幻觉方面的表现似乎优于传统的 RAG 系统。我们还注意到,使用基于代理的系统可以进一步增强 RAG 应用程序。为此,LangGraph 框架已被添加到 LangChain 生态系统中,以为 LLM 应用程序添加循环和持久性。
我将向你演示如何使用 LangChain 和 LangGraph 为 Neo4j 创建一个 GraphRAG 工作流程。我们将开发一个相当复杂的工作流程,在多个阶段使用 LLM,并采用动态提示词查询分解技术。我们还将使用一种路由技术,将查询在向量语义搜索和图 QA 链之间进行分流。使用 LangGraph 的 GraphState,我们将通过从早期步骤中提取的上下文来丰富我们的提示模板。
我们的工作流程的高级示例大致如下图所示。
在深入细节之前,首先回顾一下基于 LangChain 的 GraphRAG 工作流程:
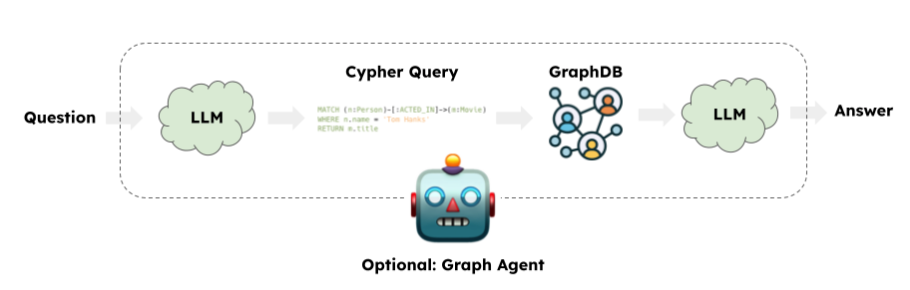
来源:LangChain
一个典型的 GraphRAG 应用涉及使用 LLM 生成 Cypher 查询语言。然后,LangChain 的 GraphCypherQAChain 将生成的 Cypher 查询提交到图数据库(例如 Neo4j)以检索查询输出。最后,LLM 将根据初始查询和图查询的响应返回一个答案。此时,响应仅基于传统的图查询。自从 Neo4j 引入向量索引功能以来,我们也可以执行语义查询。在处理属性图时,有时将语义查询和图查询结合使用或在两者之间进行分流是有益的。
图查询示例
假设我们有一个学术期刊的图数据库,其中包含文章、作者、期刊、机构等节点。
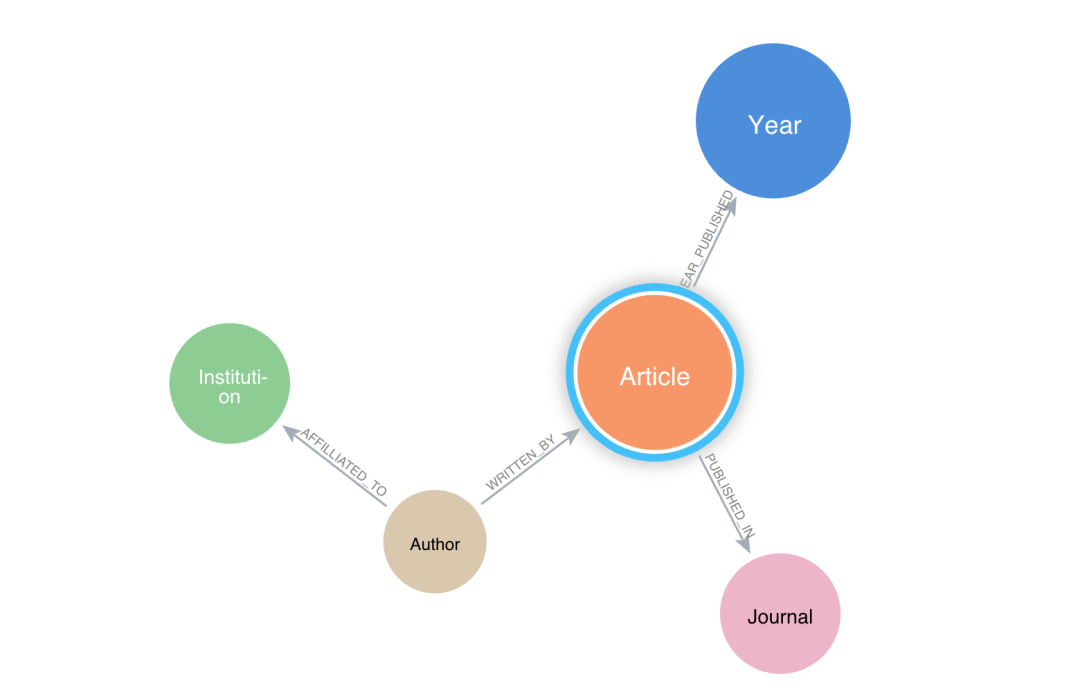
一个典型的图查询“查找引用次数最多的前 10 篇文章”将如下所示:

语义检索示例
“查找关于气候变化的文章”将如下所示:

混合查询
混合查询可能涉及先执行语义相似性搜索,然后使用语义搜索的结果进行图查询。这在我们希望使用属性图(例如学术图)时特别有用。一个典型的问题是“查找关于气候变化的文章,并返回其作者和机构。”
在这种情况下,我们需要将问题解析为多个子查询,以执行必要的任务。向量搜索在这里作为图查询的上下文使用。因此,我们需要设计一个能够容纳此类上下文的复杂提示模板。
LangGraph 工作流程
我们当前的工作流程将有两个分支(见下图)——一个是使用图模式进行简单图查询检索 QA,另一个是使用向量相似性搜索。要跟随这个工作流程,我创建了一个 GitHub 仓库,其中包含所有用于此实验的代码:我的LangGraph示例(https://github.com/sgautam666/my_graph_blogs/tree/main/neo4j_rag_with_langGraph)。该实验的数据集来自 OpenAlex,该平台提供学术元数据。此外,你还需要一个 Neo4j AuraDB 实例。
一般的工作流程设计如下:
def route_question(state: GraphState):
print("---ROUTE QUESTION---")
question = state["question"]
source = question_router.invoke({"question": question})
if source.datasource == "vector search":
print("---ROUTE QUESTION TO VECTOR SEARCH---")
return "decomposer"
elif source.datasource == "graph query":
print("---ROUTE QUESTION TO GRAPH QA---")
return "prompt_template"
workflow = StateGraph(GraphState)
workflow.add_node(PROMPT_TEMPLATE, prompt_template)
workflow.add_node(GRAPH_QA, graph_qa)
workflow.add_node(DECOMPOSER, decomposer)
workflow.add_node(VECTOR_SEARCH, vector_search)
workflow.add_node(PROMPT_TEMPLATE_WITH_CONTEXT, prompt_template_with_context)
workflow.add_node(GRAPH_QA_WITH_CONTEXT, graph_qa_with_context)
workflow.set_conditional_entry_point(
route_question,
{
'decomposer': DECOMPOSER,
'prompt_template': PROMPT_TEMPLATE
},
)
workflow.add_edge(DECOMPOSER, VECTOR_SEARCH)
workflow.add_edge(VECTOR_SEARCH, PROMPT_TEMPLATE_WITH_CONTEXT)
workflow.add_edge(PROMPT_TEMPLATE_WITH_CONTEXT, GRAPH_QA_WITH_CONTEXT)
workflow.add_edge(GRAPH_QA_WITH_CONTEXT, END)
workflow.add_edge(PROMPT_TEMPLATE, GRAPH_QA)
workflow.add_edge(GRAPH_QA, END)
app = workflow.compile()
app.get_graph().draw_mermaid_png(output_file_path="graph.png")
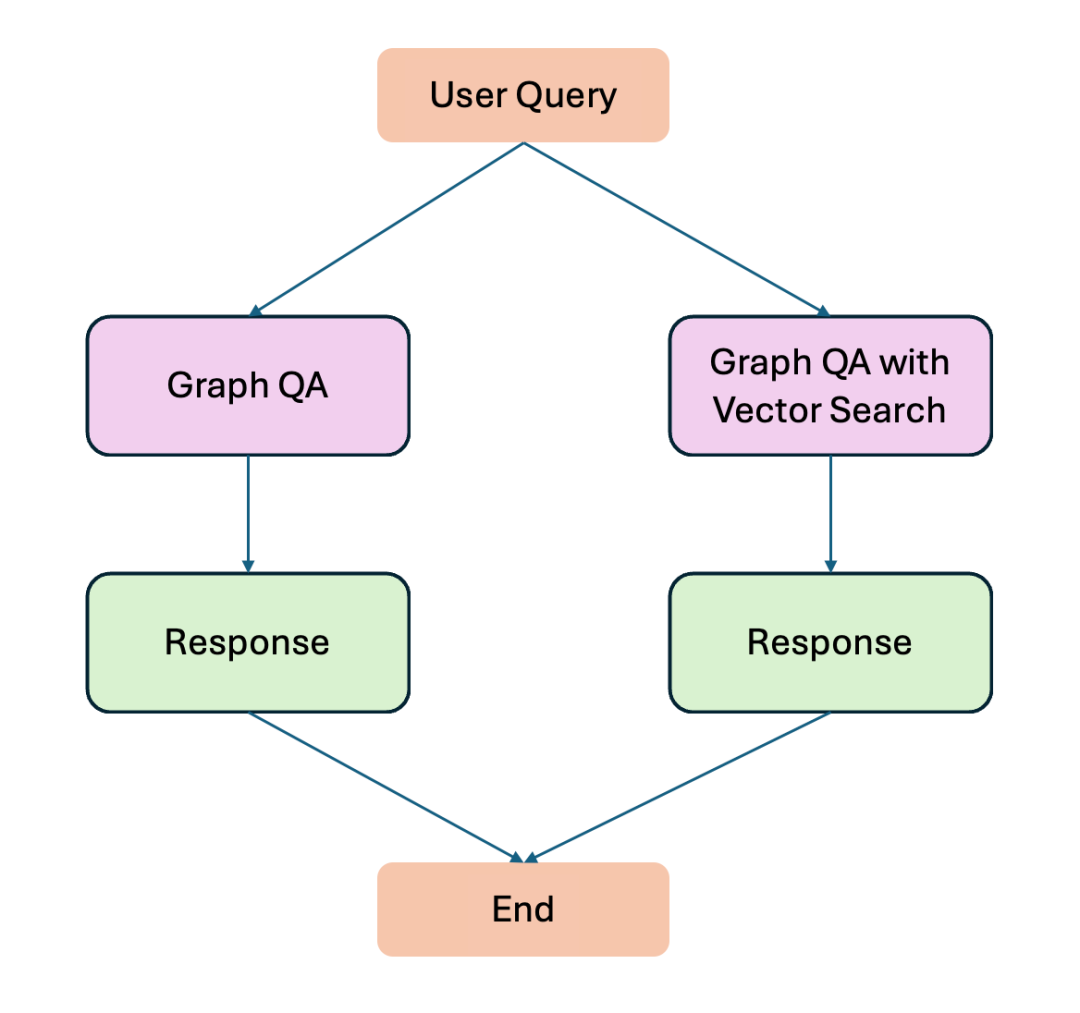
这段代码将生成如下所示的工作流程:
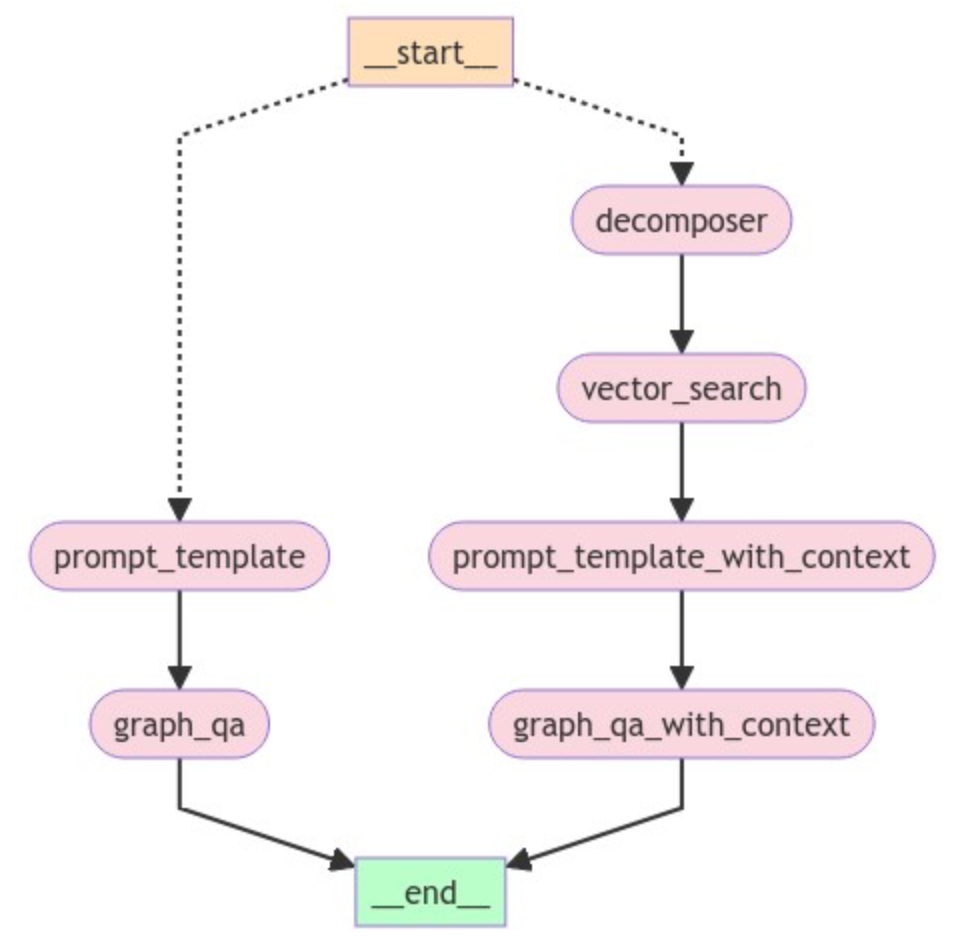
在这个 GraphRAG 流程中,我们的工作流程从一个条件入口点开始,该入口点允许我们决定查询流的路线。在这个例子中,START 节点从用户查询开始。根据查询的不同,信息会流向两侧。如果查询需要查找向量嵌入,它将流向右侧。如果查询是简单的基于图的查询,则工作流程遵循左侧部分。工作流程的左侧基本上是之前讨论的典型图查询,唯一的区别是我们在这里使用了 LangGraph。
让我们看看上面工作流程的右侧。我们从一个 DECOMPOSER 节点开始。该节点基本上将用户问题分解为子查询。假设我们有一个用户问题,要求“查找关于氧化应激的文章。返回最相关文章的标题。”
子查询:
- • 查找与氧化应激相关的文章——用于向量相似性搜索
- • 返回最相关文章的标题——用于图 QA 链
你可以理解为什么我们需要分解问题。当将整个用户问题作为输入查询时,图 QA 链会遇到困难。分解是通过使用 GPT-3.5 Turbo 模型和一个基本的提示模板的 query_analyzer 链完成的:
class SubQuery(BaseModel):
"""将给定问题/查询分解为子查询"""
sub_query: str = Field(
...,
description="对原始问题的唯一释义。",
)
system = """你是一名专家,能够将用户问题转换为 Neo4j Cypher 查询。
执行查询分解。给定用户问题,将其分解为两个独立的子查询,
你需要回答这些子查询以回答原始问题。
对于给定的输入问题,创建一个用于相似性搜索的查询,并创建一个用于执行 neo4j 图查询的查询。
以下是示例:
问题:查找关于光合作用的文章并返回其标题。
答案:
sub_query1:查找与光合作用相关的文章。
sub_query2:返回文章的标题
"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm_with_tools = llm.bind_tools([SubQuery])
parser = PydanticToolsParser(tools=[SubQuery])
query_analyzer = prompt | llm_with_tools | parser
向量搜索
右侧分支的另一个重要节点是带有上下文的提示模板。当我们针对属性图进行查询时,如果我们的 Cypher 生成使用图模式,我们将得到期望的结果。通过向量搜索创建上下文,使我们能够将 Cypher 模板聚焦于向量搜索提供的特定节点,从而获得更准确的结果:

带有上下文的提示模板
我们使用存储的向量嵌入的相似性搜索创建上下文。我们可以生成语义上下文或将节点本身作为上下文。例如,这里我们正在检索表示与用户查询最相似的文章的节点 ID。这些节点 ID 作为上下文传递给我们的提示模板。
一旦捕获上下文,我们还希望确保我们的提示模板获得正确的 Cypher 示例。随着 Cypher 示例的增加,我们可以预期静态提示示例开始变得无关紧要,导致 LLM 处理困难。我们引入了一种动态提示机制,根据相似性选择最相关的 Cypher 示例。我们可以在运行时使用 Chroma 向量存储根据用户查询选择 k 样本。因此,我们的最终提示模板如下所示:

注意,动态选择的 Cypher 示例通过 suffix 参数传递。最后,我们将模板传递给调用图 QA 链的节点。我们在工作流程的左侧也使用了类似的动态提示模板,但没有上下文。
与典型的 RAG 工作流程不同,在将上下文引入提示模板时,我们通过创建输入变量并在调用模型链(例如 GraphCypherQAChain())时传递这些变量来实现:

有时通过 LangChain 链传递多个变量会变得更加棘手:

上述工作流程将不起作用,因为 GraphCypherQAChain() 需要提示模板,而不是提示文本(当你调用链时,提示模板的输出将是文本)。这促使我尝试使用 LangGraph,它似乎可以传递尽可能多的上下文并执行工作流程。
图 QA 链
带有上下文的提示模板之后的最后一步是图查询。从这里开始,典型的图 QA 链用于将提示传递给图数据库以执行查询,并且 LLM 生成响应。请注意,工作流程左侧的类似路径是在提示生成之后。此外,我们还使用类似的动态提示方法在任一侧生成提示模板。
在执行工作流程之前,以下是关于路由链和 GraphState 的一些思考。
路由链
如前所述,我们的工作流程从一个条件入口点开始,该入口点允许我们决定查询流的路线。通过路由链实现这一点,我们使用了一个简单的提示模板和 LLM。Pydantic 模型在这种情况下非常有用:
class RouteQuery(BaseModel):
"""将用户查询路由到最相关的数据源。"""
datasource: Literal["vector search", "graph query"] = Field(
...,
description="给定用户问题选择将其路由到向量存储或图数据库。",
)
llm = ChatOpenAI(temperature=0)
structured_llm_router = llm.with_structured_output(RouteQuery)
system = """你是一名专家,能够将用户问题路由以执行向量搜索或图查询。
向量存储包含与文章标题、摘要和主题相关的文档。以下是三个路由情况:
如果用户问题涉及相似性搜索,请执行向量搜索。用户查询可能包含类似“相似”、“相关”、“相关性”、“相同”、“最近”等术语,表明向量搜索。对于其他情况,请使用图查询。
向量搜索案例的问题示例:
查找关于光合作用的文章
查找与氧化应激相关的类似文章
图数据库查询的问题示例:
MATCH (n:Article) RETURN COUNT(n)
MATCH (n:Article) RETURN n.title
图 QA 链的问题示例:
查找特定年份发表的文章并返回其标题、作者
查找来自位于特定国家(例如日本)的机构的作者
"""
route_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}")
]
)
question_router = route_prompt | structured_llm_router
def route_question(state: GraphState):
print("---ROUTE QUESTION---")
question = state["question"]
source = question_router.invoke({"question": question})
if source.datasource == "vector search":
print("---ROUTE QUESTION TO VECTOR SEARCH---")
return "decomposer"
elif source.datasource == "graph query":
print("---ROUTE QUESTION TO GRAPH QA---")
return "prompt_template"
GraphState
LangGraph 的一个美妙之处在于信息通过 GraphState 的流动。你需要在 GraphState 中定义所有潜在数据,以便某个节点在任何阶段都可以访问:

要访问这些数据,你只需在定义节点或任何函数时继承 state。例如:
def prompt_template_with_context(state: GraphState):
question = state["question"]
queries = state["subqueries"]
prompt_with_context = create_few_shot_prompt_with_context(state)
return {"prompt_with_context": prompt_with_context, "question":question, "subqueries": queries}
讨论完这些主要话
题后,让我们执行 Neo4j GraphRAG 应用程序。
图 QA:
app.invoke({"question": "查找引用次数最多的前 5 篇文章并返回其标题"})
---ROUTE QUESTION---
---ROUTE QUESTION TO GRAPH QA---
> 正在进入新的 GraphCypherQAChain 链...
> 生成的 Cypher:
> MATCH (a:Article) WITH a ORDER BY a.citation_count DESC RETURN a.title LIMIT 5
> 链完成。
graph_qa_result['documents']
{'query': '查找引用次数最多的前 5 篇文章并返回其标题',
'result': [
{'a.title': '从蚯蚓堆肥中分离出的腐殖酸增强了玉米根的根伸长、侧根出现和质膜 H+-ATPase 活性'},
{'a.title': '快速估算相对含水量'},
{'a.title': 'ARAMEMNON,一个用于阿拉伯芥整合膜蛋白的新数据库'},
{'a.title': '植物生理学中的多胺。'},
{'a.title': '对阿拉伯芥根和芽中硝酸盐反应的微阵列分析揭示了 1000 多个快速反应基因以及与葡萄糖、海藻糖-6-磷酸、铁和硫酸盐代谢的新联系'}]}
带有向量搜索的图 QA:
app.invoke({"question": "查找关于氧化应激的文章。返回最相关文章的标题"})
---ROUTE QUESTION---
---ROUTE QUESTION TO VECTOR SEARCH---
> 正在进入新的 RetrievalQA 链...
> 链完成。
graph_qa_result['documents']
{'query': '返回最相关文章的标题。',
'result': [{'a.title': '苔藓和谷类之间对脱落酸和应激的分子反应的保守性'}]}
graph_qa_result.keys()
dict_keys(['question', 'documents', 'article_ids', 'prompt_with_context', 'subqueries'])
graph_qa_result['subqueries']
[SubQuery(sub_query='查找与氧化应激相关的文章。'),
SubQuery(sub_query='返回最相关文章的标题。')]
如你所见,根据用户问题,我们能够成功地将问题路由到正确的分支并检索到所需的输出。随着复杂性的增加,我们必须修改路由链本身的提示。虽然分解对于像这样的应用程序至关重要,但查询扩展是 LangChain 中的另一个功能,尤其是当有多种方式编写 Cypher 查询以返回类似答案时,这可能也是一个有用的工具。
我们已经涵盖了工作流程中最重要的部分。请跟随我的LangGraph示例(https://github.com/sgautam666/my_graph_blogs/tree/main/neo4j_rag_with_langGraph) 代码库以进行更深入的探索。
总结
这个工作流程结合了许多步骤,而我在这里没有讨论所有步骤。然而,我承认,仅使用 LangChain 构建高级 GraphRAG 应用程序遇到了一些困难。通过使用 LangGraph 解决了这些困难。最让我沮丧的是无法在提示模板中引入所需的多个输入变量,并将该模板传递给 LangChain Expression Language 中的 Graph QA 链。
起初,LangGraph 看起来需要大量的学习,但一旦你克服了这个障碍,它就会变得顺畅起来。未来,我会尝试将代理引入到工作流程中。如果你有任何建议,请与我联系。我正在尽可能多地学习。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。