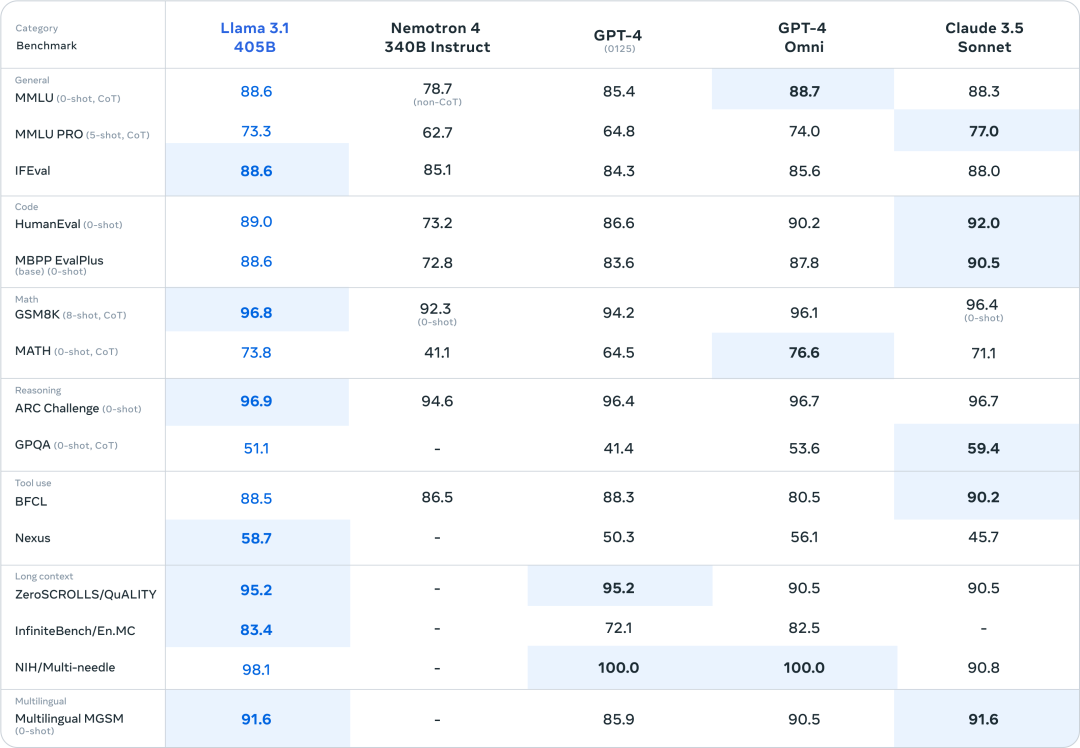
Meta官方发布的LLaMA3.1-405B的各项得分
©作者|格林
来源|神州问学
最近,AI领域掀起了一股数据合成的热潮,各大厂商最近推出的模型都或多或少有数据合成的影子。英伟达的Nemotron-4-340B-Instruct、微软的Orca-3,以及Meta的Meta-Llama-3.1-8B-Instruct,都提到使用了部分的合成数据,展现出了这个领域前所未有的潜力。那么,为什么数据合成技术突然变得如此火热?这些模型背后的驱动力究竟是什么?
1. 引言:近期的数据生成相关的模型:
随着人工智能产业的快速发展,AI数据生成技术逐渐成为业界关注的焦点,特别是在提升训练数据的质量、规模和多样性方面,大模型展现出了巨大的潜力。近年来,数据合成技术已经被成功应用于多个领域,例如网络文本的重新表述、为文本质量分类器生成训练数据,以及为预训练集中代表性不足的领域创建新数据。这些应用不仅提高了模型训练的效率,还有效降低了对人工注释数据的依赖和成本。与此同时,随着越来越多企业推出自己的数据生成模型,行业内关于数据生成的讨论也日益热烈。
然而,尽管合成数据在加速大型和小型语言模型开发中发挥了重要作用,研究人员仍对其潜在的缺陷表示担忧,尤其是模型崩溃和模仿其他模型的问题,主要源于合成数据较差的质量和多样性。为了提示合成数据的质量和多样性,研究者们提出了琳琅满目的方法和技巧,有些基于早期AI的相关walk-around方法,有些基于其他领域的传统方法,有些则是大模型时代原生的。在本文中,我们将深入探讨数据生成模型的最新进展,对应的生成要点和技巧,以及在不同领域的应用潜力。
1.1. 英伟达超大的数据生成模型 - Nemotron-4-340B-Instruct;
前段时间英伟达发布了超大规模的数据生成模型Nemotron-4-340B-Instruct,这是一个专为合成数据生成设计的大模型。
基础模型在包含 9 万亿个标记的语料库上进行了预训练,该语料库包含各种基于英语的文本、50 多种自然语言和 40 多种编码语言。随后,Nemotron-4-340B-Instruct 模型经历了额外的对齐步骤,其中包括SFT以及直接偏好优化(DPO)、奖励感知偏好优化 (RPO)两种对齐方法。在对其的过程中,模型仅依赖大约20K的人工注释的数据,而英伟达设计的数据生成流程合成了DPO和RPO所需的 98% 以上的数据。
在数据生成流程中包括了生成数据用的提示模板,以及用于质量过滤和偏好排名的 Nemotron-4-340B-Reward,是一种自动化的对市场数据进行筛选,提高数据质量的方式。
基于Nemotron-4-340B-Instruct,研究人员可以利用生成的合成数据,快速创建和微调适合自己特定应用的模型,从而加快了模型开发的进程,并减少了对庞大而昂贵的人工数据标注的依赖。开发团队还表示在未来会推出专用于合成数据生成的 NVIDIA 推理微服务 (NIM)。
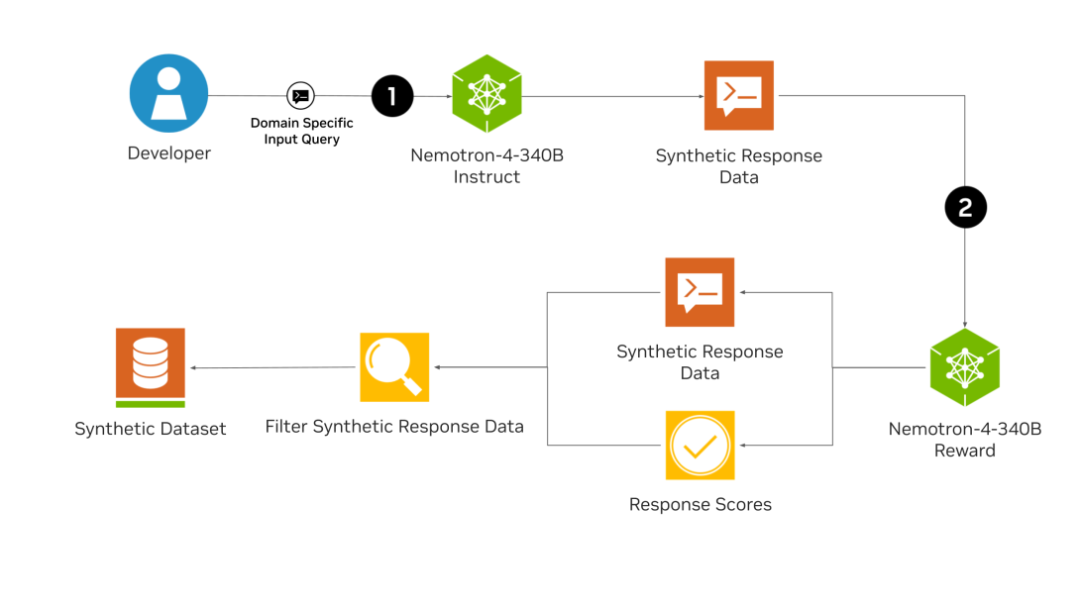
英伟达官方提供的基于Nemotron-4-340B的数据生成流程
1.2. 微软的虎鲸 - 重视步骤推理的Orca2模型和最新的Orca-3;(以及Meta的座头鲸Humpback)
Orca 是微软研究院的一个研究团队,专注于创建自动化数据合成流程,并使用合成数据训练模型以实现专业化和模型自我改进。Orca 的研究领域涉及:
1)设计用于大规模生成多样化高质量数据的自动化管道流程;
2)训练算法以实现模型专业化和持续改进;
3)构建用于微调即服务(自动为任何领域生成数据并进行学习)的通用管道流程;

去年6月份,微软就发布关于Orca的相关论文,当时的侧重点主要在从逐步的解释中学习来提高模型能力和技能。后续发布基于的Orca-2则更加强调了让大模型LLM通过反馈驱动教学来让小模型SLM学会特定技能以及推理模式。Orca-2基于LLaMA-2在合成数据上微调得到多种推理能力,包括各种推理技术,例如逐步处理、回忆然后生成、回忆-推理-生成、提取-生成和直接回答方法,并学习在不同的任务和条件下自动选用对应的推理方式,由此来得到解决复杂问题的能力。生成数据的检验通过微软Azure的服务完成,进行了内容过滤审核。
今年7月,Orca团队发布了Orca-3,以及对应的用于创建合成数据的Agent框架AgentInstruct。AgentInstruct 可以创建提示和答案,并可以仅使用原始数据源(如文本文档和代码文件)作为种子。团队基于AgentInstruct生成了约2500 万对的微调训练数据集,其中包括17种不同种类的任务,并通过这些数据基于Mistral-7b-Instruct训练了Orca-3模型,在各基准测试中展现了显著的改进。

AgentInstruct论文中提到的可生成的17种任务类型
其中包括阅读理解、开放领域问答、Web Agent、脑筋急转弯、分析推理、多项选择题、数据到文本、费米估计、编写代码、文本提取、文本分类、RAG、工具使用、创意内容生成、少量推理、对话;
1.3. Meta的最新模型 - llama3.1 模型;
7月23号,Meta发布了Meta-Llama-3.1-8B-Instruct模型,在进行post-train的时候,进行了多次的对齐流程,包括SFT、拒绝抽样 (RS) 以及DPO。和刚才我们提到的Orca系列类似,LLaMA的团队也使用了数据合成的方式来生成绝大部分的 SFT 数据,并进行了多次生成迭代来增加多样性和质量。Meta团队也发布了LLaMA Stack,这是一套标准化且自成体系的接口,用于构建规范的工具链组件(微调、合成数据生成)和Agent应用程序。
Meta官方发布的LLaMA3.1-405B的各项得分
显然,在微调阶段使用合成的数据已经成为了一种趋势,开始运用在了多种经典模型的训练过程中,尤其是在专业领域方面,使用蒸馏/合成的数据来微调展现出了巨大的潜力。那么数据生成有哪些关键点呢?
2. 合成数据的“三美德”
在Saleforce的APIGen(7月发布)以及Microsoft的AgentInstruct(也是7月发布)中,都提到了数据生成的三个要点:
多样性、质量以及规模。
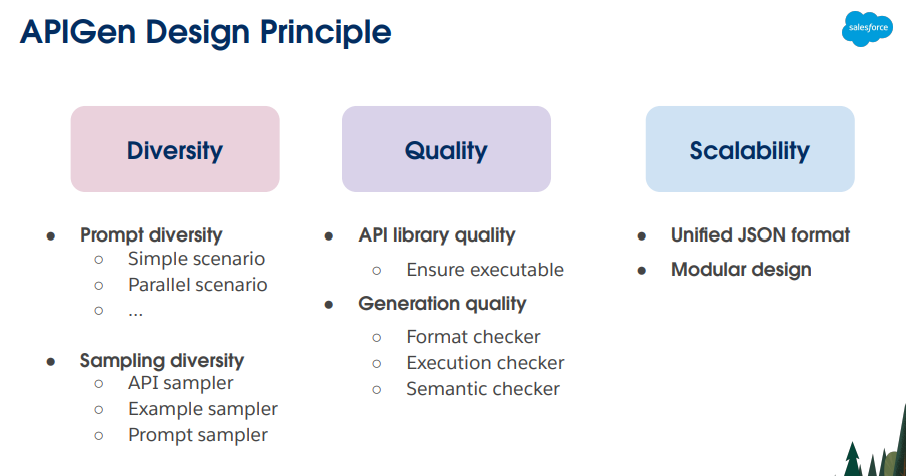
Salesforce作者在APIGen 青源Talk156期 PPT中关于三个重点的描述

MicrosoftAgentInstruct关于三个重点的描述
2.1. 多样性 / 多元化 Diversity;
多样性对于模型在处理类似未见任务时的表现至关重要,提升模型的泛化能力,更好地适应不同的情境和用户需求:
➢ 多种提示模板与随机取样器:通过使用多样化的提示模板和随机取样器(包括不同的答案、样例和提示),可以在数据生成过程中引入变异性,提升模型应对不同场景的能力;
➢ 提问改写与增强:通过改写提问和增强问法,可以丰富数据集中的表达方式,确保模型能够理解和处理各种提问方式,从而提升模型在真实世界中的适应性。而且通过这类数据增强的方法,能够高效地提升数据集的数量,同时兼顾数据集的多样性;
➢ 角色设定与场景模拟:在提示模板中加入角色设定,以模拟不同类型用户的提问方式。这种方法有助于生成更贴近实际应用场景的数据,使得模型能够更好地应对多样化的用户群体。比如在模拟医疗咨询时,可以设定不同年龄、性别、职业的角色,以生成多样化的询问方式;
➢ 错别字与问题泛化:在直接面向用户的场景中,适当引入错别字和非标准表达,以提升模型的泛化能力。这种策略可以让模型更灵活地处理非标准输入,增强其在实际使用中的鲁棒性。尤其是对于和语音/手写体识别的场景,可能更容易导致错别字或错词,通过加入这些非标准的表达方式来提升模型对错别字的耐受程度;
➢ 多种Agent与分类法的结合:以微软的AgentInstruct流程为例,基于Agentic Workflow的数据生成方法采用了多种不同类型的Agent(不同的提示、工具、模型)以及复杂的分类法(涵盖超过100个子类别)来创建多样化且高质量的提示和响应。这种方法不仅提高了数据生成的多样性,还确保了生成数据的覆盖面和质量,从而为模型的多样化训练提供了有力支持。
通过这些方法,数据生成过程能够更全面地涵盖各种可能的应用场景,确保模型在面对不同任务时具备更强的适应性和泛化能力。
2.2. 准确性 / 质量 Quality;
准确性对模型在已知任务的表现至关重要,同时也直接影响微调后模型的表现性能,为了提升数据生成的准确性,以下策略被广泛应用:
➢ 奖励模型进行质量过滤:通过训练一个奖励模型(RM),系统能够有效识别和评估生成数据的质量。奖励模型是人类反馈强化学习(RLHF)中的核心组件,也是合成数据生成中进行质量过滤和偏好排名的有力工具。例如,在英伟达Nemotron模型的对齐过程中,奖励模型帮助筛选出高质量的答案(response);
➢ 检查器(Checker):为了进一步保证数据的准确性,可以使用检查器。检查器的概念可以运用在更广泛的场景中,可以通过多种类型的检查器对生成的数据进行评估和过滤:
○ 语义检查器:利用大模型驱动的语义检查器,对生成的答案是否有效回答问题进行评估。这一过程可以通过使用多种大模型进行交叉验证,从而过滤掉无意义或错误的答案,给出具体的过滤原因;
○ 格式检查器:如果生成的输出对格式有特定要求,可以通过格式检查器来确保输出符合预期格式。这在需要严格结构化数据的场景中尤为重要,例如代码和JSON等等;(Open AI JSON Mode)
○ 执行检查器:对于生成具有可执行属性的数据(如代码或API),可以通过执行检查器来验证输出的执行状态。这种方法可以有效识别并排除生成过程中出现的错误,从而提高数据的实用性和准确性;
➢ 参数的生成:在数据的参数生成过程中,可以使用直接的真实参数,或基于提示和样例让某些生成高质量参数。这些参数需要经过精心设计,以确保生成的数据能够准确反映目标任务的要求;
➢ 使用更强大的模型进行生成:使用更大、更强的模型进行生成是常见策略。微软的AgentInstruct流程就是一个典型的例子,通过GPT-4这样的强大模型结合搜索和代码解释器等工具,生成高质量的数据来满足不同的任务需求;
这些策略通过不同的途径和工具,确保生成数据的准确性,使得模型在已知任务中的表现更加可靠。通过多层次的质量控制和验证,生成的数据不仅在表面上符合要求,更在实际应用中展现出强大的实用性和有效性。
2.3. 自动化 / 规模化 Scalability;
规模化对减少成本以及使用不同方式微调至关重要,让整套流程能够快速适用于任何领域的数据合成;
➢ 基于种子数据的全流程自动化:在自动化数据生成中,编写一小部分高质量且具有代表性的种子数据,这些数据将作为自动化流程的基准。种子数据包括精心编写的答案和提示,通过这些样例,自动化系统能够生成大量类似格式的数据。这种方法不仅减少了手动标注的工作量,还能够以更快的速度扩展数据集的规模。当然也有不使用种子数据的自动化流程,AgentInstruct就能够在不依赖额外种子提示的情况下,自主生成新数据,通过分析原始文档,生成与种子数据相似的内容,并结合流程验证和数据过滤,确保生成的数据质量。
➢ 模块化设计:模块化设计使得数据生成过程更具灵活性和可扩展性。核心生成部分,如问题、API答案等,可以独立生成并保存。后续的流程可以根据不同的微调需求进行调整,例如适配ShareGPT格式、Alpaca格式,或者使用LLaMA-Factory、Swift等多种框架。这种模块化的设计不仅提高了数据生成的效率,还允许开发者根据具体需求调整不同的生成步骤。例如,在Function Calling的场景下,只需使用大模型生成用户问题和工具调用的部分,其他格式整合的部分则可以通过人工编写的代码来完成。
➢ 多领域微调:通过模块化和自动化的结合,开发者可以轻松微调模型以适应特定领域的需求。例如,在法律领域,种子数据可以包括法律问答和案例分析,自动化系统则根据这些种子数据生成大量法律相关的问答对。通过模块化设计,生成的法律问答数据可以进一步与现有的法律数据库整合,形成一个更为全面的数据集,用于微调法律AI模型。这种方法不仅大大减少了手动数据生成的成本,还提高了模型在特定领域的表现能力。
通过上述方法,数据生成过程不仅能够实现规模化,还能确保生成数据的质量和多样性,从而更好地支持不同领域的模型开发和微调需求。
在实际业务场景场景中,这三个要点都需要兼顾,才能说是实用的数据生成流程。
3. 知识相关的数据生成:
3.1. 基于文档或源代码的微调数据生成;
其中一种方式就是使用原始数据(非结构化文本文档或源代码)作为种子,这种方法有两个好处。首先,这些数据非常丰富,包含了最完整的信息,直接涉及到真实业务场景,目前仍然是有待开采的油田宝矿;此外使用原始数据作为种子,可以降低对模型本身能力和提示模板的依赖,从操作的角度上来讲也相对更加自动化,可以随着数据的更新快速反复迭代。
但纯粹的原始数据距离能用的高质量训练集还有较长距离,直接一步到位难以成功,需要拆分成多个步骤:
1. 从种子数据得到中间内容,包括内容总结,API列表,抽取的关键信息;
2. 基于每条关键信息,生成对应的多种类型的指令;
3. 迭代优化指令来提升表现性能;
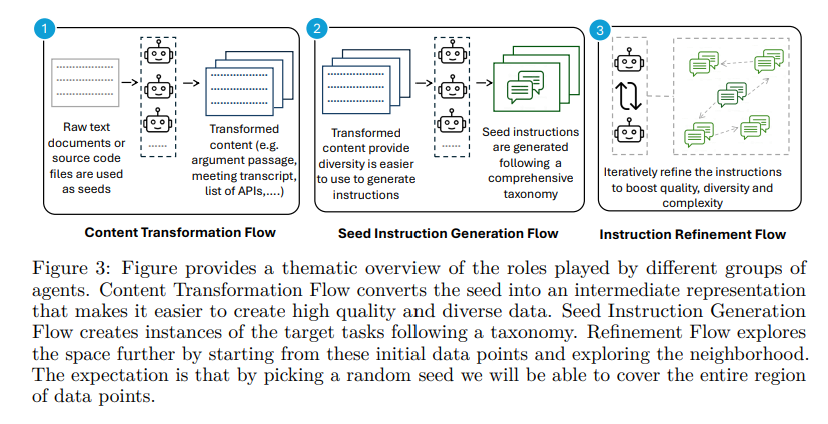
AgentInstruct中基于原始文档/代码的问答生成流程
在这个流程中,指令的生成可以基于不同的提示模板变得更加多样化,美国布朗大学(Brown University)的Bats Research研究组在今年2月份发布的鲣鱼(Bonito)任务生成模型中提到了多种可以生成的指令/任务/提问方式,其中包括:
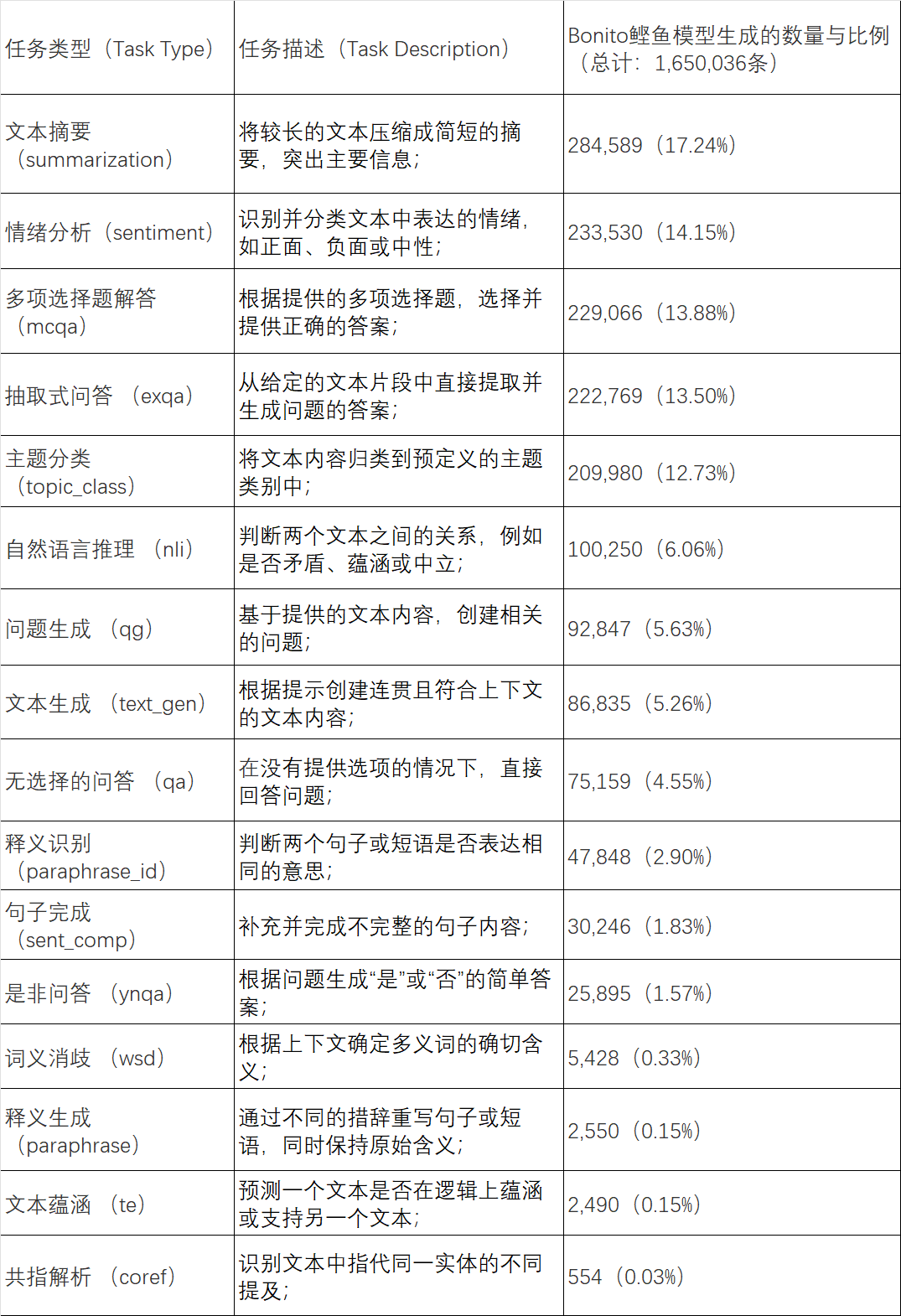
Bonito鲣鱼模型论文中提到的生成的16类任务以及其解释
3.2. 基于提示的知识蒸馏;
知识蒸馏是2015年AI领域大师Geoffrey Hinton在论文中提及的,在当时描述的机器学习中的一种技术,用于从一个较大的复杂模型(“教师模型”)中提取知识,并将这些知识转移到一个较小的模型(“学生模型”)中。
到了大模型时代,知识蒸馏依然存在,通常来说,知识蒸馏是通过提示模板萃取模型知识,将这些知识传授给较小模型,涉及较少的外部资源和数据,属于一种模型压缩技术。
虽然LLM模型参数变大带来了模型的“涌现能力”(Emergent Ability,ICL / CoT / 指令遵循 IF),让模型具有强大的泛化能力,但对于SLM,小参数语言模型,泛化能力不如LLM,更加适用于拟合到特定领域,由此蒸馏的逻辑适用于语言模型。目的是在保持模型性能的同时,减少模型的复杂性和计算需求。

知识蒸馏方法,来自综述:A Survey on Model Compression for Large Language Models
4. 任务相关的数据生成:
4.1. ”德州神枪手谬论“的正确打开方式:从答案生成任务问题;
所谓“德州神枪手谬论”(Texas Sharpshooter Fallacy),类似“先射箭,后画靶”,源自于一个比喻故事:一个神枪手在谷仓的墙上随意开了几枪,然后在子弹集中最密集的地方画了一个靶心,声称自己射击非常精准。这种行为显然是先有结果(子弹孔集中),然后人为地去创造解释(画上靶心),这就构成了“德州神枪手谬论”。
在逻辑或统计分析中,这种谬误的表现是人为选择数据来支持某个特定结论,选择性忽略或排除那些与结论不符的数据。换句话说,是先得出结论,然后选择性地解释数据以符合结论,而不是通过全面而合理的分析或实验得出结论。
然而,对于数据生成来说,这种谬误反倒可以成为一种不错的生成逻辑:先生成数据集中答案的部分,再对应地生成问题。这种方法的好处在于,让答案生成的部分更加准确,尤其是基于种子答案和原始文件的情况。另一个好处就是,问题可以用更加多样化的方式提问,并且不用担心教师模型回答错误。
在23年7月份OpenBMB发布的ToolLLM中,就使用了这种基于首先生成答案,再生成问题的流程,用于生产工具调用类的数据集,以下是大概的生成流程:
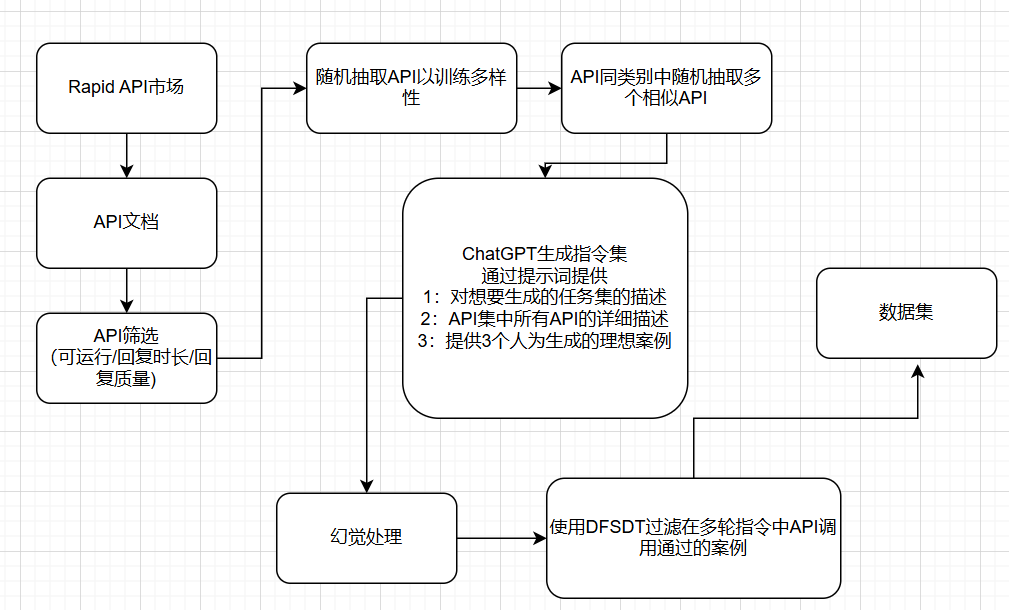
ToolLLM论文中提到的工具调用数据生成流程
4.2. 检查并运行可执行的答案,提升合成准确性;
相比于难以评测的文本或聊天数据,有格式的可执行数据(如函数调用、代码、指令等)在准确性检测方面具有明显的优势。这类数据不仅可以通过格式检查来确保其语法和结构的正确性,还能够通过实际执行的结果来验证其功能的有效性,从而筛选出高质量的数据。
在实际场景中,这种方法的应用非常广泛。例如,在生成代码的过程中,模型输出的代码片段可以通过抽象语法树(AST)来验证其语法正确性。AST方法通过将代码解析为树状结构,从而检查每个节点(如变量、函数、条件语句等)是否符合编程语言的语法规则。如果语法正确,代码还可通过执行(Exec方法)来验证其功能性,即检查代码在实际运行时是否能够返回预期的结果。通过这种双重验证,开发者可以筛选出那些不仅语法正确而且功能完备的代码片段,为后续的模型训练和优化提供可靠的高质量数据。
抽象语法树AST在计算中的样例
这种方法同样适用于生成API调用的数据场景,这一点已经在先前关于BFCL的文章中提到,可以使用AST和Exec方法对函数调用的JSON进行评测,生成的API请求可以通过解析JSON格式来检查其结构是否符合预期,并通过执行实际API调用来验证其返回值是否正确。在自动驾驶领域,生成的控制指令可以通过仿真系统来执行,检查车辆的响应是否符合预期的行为模式。近期,国内知名的评测榜单Superclue也发布了SuperCLUE-ICabin榜单,通过使用Function Calling来测评大模型在汽车智能座舱场景中的表现。
4.3. 函数调用类答案中参数的生成技巧;
在函数调用类答案的生成过程中,有三个至关重要的能力:1)合理选择函数;2)合理填入参数;3)合理输出结构格式;
参数的设计和生成技巧对模型的学习效果至关重要。虽然训练数据集中的参数不一定是真实可执行的,但仍需符合逻辑并贴近实际场景。通过合理设计这些参数,模型能够更好地掌握从用户语句中提取API所需参数的能力,并在各种复杂的查询场景中表现出色。
虚构参数的使用:
在训练数据集中,参数如公司名称、人名、证件号码等,可以是虚构的、不真实的。这些参数虽然并不需要实际可运行,但其设计仍需符合逻辑。例如,虚构的公司名称应具有真实公司名称的格式和特点,而虚构的人名应符合目标语言文化中的命名习惯。这种设计使模型在训练过程中能够学会识别和提取类似的真实参数,从而更好地处理实际任务中的API调用。例如,在生成用户查询企业信息的任务中,训练数据可以使用虚构的公司名称作为参数,重点在于让模型学会如何从用户的查询中提取相关信息并匹配到API所需的参数格式。
真实参数的使用:
当API调用需要进行实际的可行性检测时,参数的生成则需要更加谨慎。为了确保生成的参数能够执行成功,通常会预先提供一个真实的参数选项列表。模型在生成答案时,需要从这个列表中选择合适的参数,而非自由生成。这一策略确保了在实际应用中,模型生成的调用参数能够通过API的验证,从而提高了整个系统的可靠性。
用户提问中多样化的参数出现方式:
为了使模型能够应对各种不同的用户查询情境,参数生成时应当灵活多样。这不仅有助于提升数据生成的多样性,还能够让模型更好地适应实际场景中的复杂查询。通过以下几种方式设置查询任务,可以有效模拟实际情况:
➢ 直接输入所有必要参数的任务Query:在这种情况下,用户的查询已经包含了API调用所需的所有参数。模型需要做的只是识别这些参数并将其传递给API。这种场景可以帮助模型熟悉标准的API调用流程。
➢ 输入包含多余参数的任务Query:用户的查询中可能包含了超出API调用需求的额外信息。模型需要学会过滤掉这些无关信息,提取出API所需的关键参数。这种情境下,模型不仅要能够提取有效参数,还要具备一定的判断能力。
➢ 输入缺少一些必要参数的任务Query:在这种场景中,用户的查询可能不完整,缺少某些必需的参数。模型需要能够根据上下文推断出缺失的参数,或者生成合理的默认值,以确保API调用的成功执行。
例如,考虑一个天气查询API,用户可能输入“查询明天北京的天气”,其中“北京”是明确的地点参数。然而,若用户只输入“查询明天的天气”,模型需要自动推断缺失的地点信息,可能通过上下文补全或询问用户以获取完整参数。
通过这些生成技巧,模型能够更灵活、更准确地处理函数调用任务,并在实际应用中表现出色。无论是虚构参数的使用、真实参数的生成,还是多样化场景的模拟,这些策略都在帮助模型更好地掌握API调用所需的核心技能。
5. 基于已生成的问题和答案进一步增强数据:
除了刚刚提到的Function Calling在任务问题中的参数设置以外,还有更多种针对提问和回答的增强方式。通过模块化的生成方式,在获得数据生成的核心产出物:AI生成的用户输入和模型输出之后,可以在此基础上进行进一步改造。
5.1. 多轮对话:历史记录与模型追问:
在多轮对话和RAG任务中,有效利用历史记录和模型追问能力对于提升对话系统的表现至关重要。这种能力不仅帮助模型更好地理解上下文,还能在用户提供的信息不完整或模糊时,通过追问引导用户提供更多信息,从而实现更准确的响应
历史记录中的关键信息:
在实际对话场景中,用户常常会在多轮对话中逐步提供关键信息,而不是一次性全部给出。为了训练模型在这种情况下保持上下文连贯性和信息追踪能力,可以将包含关键信息的用户输入拆散,并将这些信息分布到多轮对话中。在这种训练集中,加入一些不相关或可能导致混淆的噪声信息,模型需要能够识别和过滤这些噪声,专注于提取相关的关键内容。
模型追问的能力:
当用户在对话中没有提供足够的信息时,模型需要具备主动追问的能力,以引导用户提供更多信息。这种追问不仅可以帮助模型获得必要的上下文,还能提高对话的互动性和用户体验。在训练数据集中,可以通过设计缺失关键信息的对话场景,鼓励模型生成追问。在对话的上文中故意遗漏一些关键信息,而在下文中由模型通过追问来引导用户提供这些信息。
例如,在一个医生问诊的对话场景中,如果用户仅描述了“我头疼”,但没有说明疼痛的具体部位或持续时间,模型可以通过追问“请问头疼是持续性的吗?还有其他症状吗?”来获取更多的诊断信息。通过这种方式训练模型,让其学会在信息不全的情况下,通过追问补全对话内容,从而给出更准确的建议或答案。
基于检索的生成(RAG)任务:
在RAG任务中,模型需要从外部知识库中检索相关信息并生成有针对性的响应,通常返回的片段较长,信息密度较低。为了训练模型更好地处理这类任务,生成的训练数据应当模拟实际的检索场景,而不是仅仅依赖于高信息密度的用户输入。在生成prompt时,可以选择不包含知识的提问作为输入,同时提供与提问相关的原始数据片段作为知识来源。这种设计可以让模型学会从检索到的较为杂乱的原始信息中生成准确的回答。
5.2. 学会拒绝:设置无法/不想回答的问题和对应的拒绝原因:
在构建AI模型时,学会拒绝回答特定问题是一项关键能力,尤其是在处理涉及安全性、伦理性或技术性限制的问题时。模型需要具备明确的边界意识,知道哪些问题不在其能力范围内,哪些问题可能涉及潜在的风险或不适宜回答。这部分同样可以采用“先射箭-后画靶”的方法,先确定模型拒绝回答的原因,再生成符合这些原因的问题。通过预定义的拒绝理由,如“涉及安全风险”或“工具不可用”,并创建与这些理由对应的用户问题,形成丰富的训练数据集。这种方法不仅帮助模型学会在特定情况下拒绝回答,还可以帮助其理解在什么样的情境下拒绝是必要的。
基于安全考虑的不想回答问题
在设计数据集时,首先需要明确模型拒绝回答的具体原因。这些原因可能包括隐私保护、伦理道德、法律风险或其他安全考虑。例如,用户可能提出涉及个人敏感信息的问题,如“请告诉我某人的住址”或“如何制作危险物品”。在这种情况下,模型应能够拒绝回答,并提供合理的解释。
一旦确定了拒绝的原因,就可以生成相应的问题。例如,如果拒绝的原因是“涉及个人隐私”,那么可以生成类似“如何找到某人的私人联系方式”的问题。随后,设计一个合适的提示模板和回应,例如“抱歉,我无法提供此类信息,因为这涉及到个人隐私保护。”
通过这种方法,可以创建一个丰富的训练集,帮助模型在面临这类敏感问题时作出合适的回应。在医疗场景中,模型可以拒绝回答“请告诉我某个病人的病历信息”这样的问题,并解释说“抱歉,我无法提供此信息,因为这涉及到患者隐私保护。”
基于知识或工具限制无法回答的问题
模型可能会面对一些它无法解答的问题,这通常是因为所需的知识或工具超出了模型的能力范围。为了训练模型在这种情况下正确拒绝回答,可以生成一些与知识或工具相关的问题,然后创建相应的拒绝响应。对于这种无能为力的问题,对于函数调用类的数据相对容易生成,生成了对应的问题-工具-答案对之后,把所使用的工具以及同类的其他工具从工具列表中移除并修改答案回复,则可生成这类无法回答的问题。
6. 结尾:自动生成的数据将成为企业的主要训练数据来源
AI生成的数据正迅速成为企业的主要训练数据来源,这一趋势反映了AI数据生成技术在提升训练数据质量、规模和多样性方面的显著优势。通过合成数据,企业能够快速创建高质量的训练数据集,尤其是在传统方法难以获取数据的领域,从而有效降低人工数据标注的成本。尽管研究人员对模型崩溃和模仿问题表示担忧,但随着技术的不断进步,合成数据的质量和多样性正在逐步提升,进一步推动了其在大模型开发中的广泛应用。未来,随着更多企业推出自己的数据生成模型,这一领域有望成为AI训练数据的主要驱动力。














![[MRCTF2020]pyFlag(详解附送多个python脚本)](https://i-blog.csdnimg.cn/direct/f5029031e51d4e19b6bee480411212d8.png)


