一.回归
1.什么是回归
回归(Regression)最早是英国生物统计学家高尔顿和他的学生皮尔逊在研究父母和子女的身高遗传特性时提出的。1855年,他们在《遗传的身高向平均数方向的回归》中这样描述“子女的身高趋向于高于父母的身高的平均值,但一般不会超过父母的身高”,首次提出来回归的概念。现在的回归分析已经和这种趋势效应没有任何瓜葛了,它只是指源于高尔顿工作,用一个或多个自变量来预测因变量的数学方法。
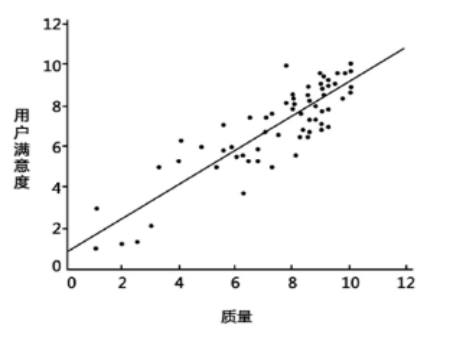
图1是一个简单的回归模型,X坐标是质量,Y坐标是用户满意度,从图中可知,产品的质量越高其用户评价越好,这可以拟合一条直线来预测新产品的用户满意度。
在回归模型中,我们需要预测的变量叫做因变量,比如产品质量;选取用来解释因变量变化的变量叫做自变量,比如用户满意度。回归的目的就是建立一个回归方程来预测目标值,整个回归的求解过程就是求这个回归方程的回归系数。
简言之,回归最简单的定义就是:
- 给出一个点集,构造一个函数来拟合这个点集,并且尽可能的让该点集与拟合函数间的误差最小,如果这个函数曲线是一条直线,那就被称为线性回归,如果曲线是一条三次曲线,就被称为三次多项回归。
2.线性回归
首先,作者引用类似于斯坦福大学机器学习公开课线性回归的例子,给大家讲解线性回归的基础知识和应用,方便大家的理解。同时,作者强烈推荐大家学习原版Andrew Ng教授的斯坦福机器学习公开课,会让您非常受益。
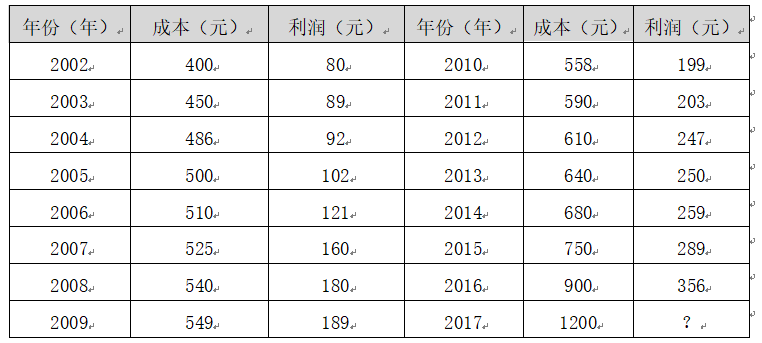
假设存在表1的数据集,它是某企业的成本和利润数据集。数据集中2002年到2016年的数据集称为训练集,整个训练集共15个样本数据。重点是成本和利润两个变量,成本是输入变量或一个特征,利润是输出变量或目标变量,整个回归模型如图2所示。

现建立模型,x表示企业成本,y表示企业利润,h(Hypothesis)表示将输入变量映射到输出变量y的函数,对应一个因变量的线性回归(单变量线性回归)公式如下:
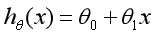
那么,现在要解决的问题是如何求解的两个参数和。我们的构想是选取的参数和使得函数尽可能接近y值,这里提出了求训练集(x,y)的平方误差函数(Squared Error Function)或最小二乘法。
在回归方程里,最小化误差平方和方法是求特征对应回归系数的最佳方法。误差是指预测y值和真实y值之间的差值,使用误差的简单累加将使得正差值和负差值相互抵消,所采用的平方误差(最小二乘法)如下:
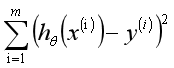
在数学上,求解过程就转化为求一组值使上式取到最小值,最常见的求解方法是梯度下降法(Gradient Descent)。根据平方误差,定义该线性回归模型的损耗函数(Cost Function)为,公式如下: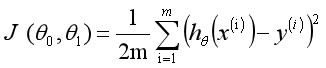
选择适当的参数让其最小化min,即可实现拟合求解过程。通过上面的这个示例,我们就可以对线性回归模型进行如下定义:根据样本x和y的坐标,去预估函数h,寻求变量之间近似的函数关系。公式如下:
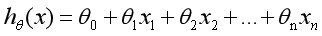
其中,n表示特征数目,表示每个训练样本的第i个特种值,当只有一个因变量x时,称为一元线性回归,类似于;而当多个因变量时,成为多元线性回归。我们的目的是使最小化,从而最好的将样本数据集进行拟合,更好地预测新的数据。
二.线性回归分析
线性回归是数据挖掘中基础的算法之一,其核心思想是求解一组因变量和自变量之间的方程,得到回归函数,同时误差项通常使用最小二乘法进行计算。在本书常用的Sklaern机器学习包中将调用Linear_model子类的LinearRegression类进行线性回归模型计算。
1.LinearRegression
LinearRegression回归模型在Sklearn.linear_model子类下,主要是调用fit(x,y)函数来训练模型,其中x为数据的属性,y为所属类型。sklearn中引用回归模型的代码如下:
from sklearn import linear_model #导入线性模型
regr = linear_model.LinearRegression() #使用线性回归
print(regr)
输出函数的构造方法如下:
LinearRegression(copy_X=True,
fit_intercept=True,
n_jobs=1,
normalize=False)
LinearRegression类主要包括如下方法:
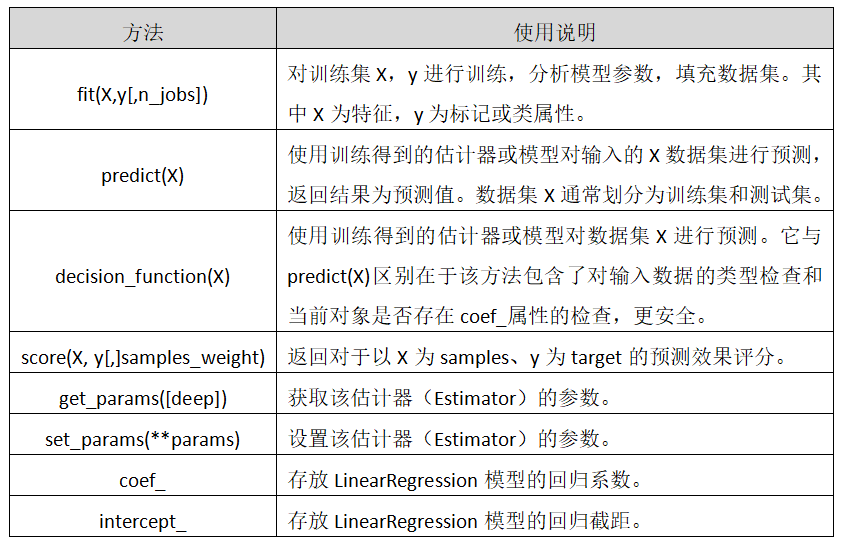
- fit(X,y[,n_jobs])
对训练集X,y进行训练,分析模型参数,填充数据集。其中X为特征,y为标记或类属性。 - predict(X)
使用训练得到的估计器或模型对输入的X数据集进行预测,返回结果为预测值。数据集X通常划分为训练集和测试集。 - decision_function(X)
使用训练得到的估计器或模型对数据集X进行预测。它与predict(X)区别在于该方法包含了对输入数据的类型检查和当前对象是否存在coef_属性的检查,更安全。 - score(X, y[,]samples_weight)
返回对于以X为samples、y为target的预测效果评分。 - get_params([deep])
获取该估计器(Estimator)的参数。 - **set_params(params)
设置该估计器(Estimator)的参数。 - coef_
存放LinearRegression模型的回归系数。 - intercept_
存放LinearRegression模型的回归截距。
现在对前面的企业成本和利润数据集进行线性回归实验。完整代码如下:
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
from sklearn import linear_model #导入线性模型
import matplotlib.pyplot as plt
import numpy as np
#X表示企业成本 Y表示企业利润
X = [[400], [450], [486], [500], [510], [525], [540], [549], [558], [590], [610], [640], [680], [750], [900]]
Y = [[80], [89], [92], [102], [121], [160], [180], [189], [199], [203], [247], [250], [259], [289], [356]]
print('数据集X: ', X)
print('数据集Y: ', Y)
#回归训练
clf = linear_model.LinearRegression()
clf.fit(X, Y)
#预测结果
X2 = [[400], [750], [950]]
Y2 = clf.predict(X2)
print(Y2)
res = clf.predict(np.array([1200]).reshape(-1, 1))[0]
print('预测成本1200元的利润:$%.1f' % res)
#绘制线性回归图形
plt.plot(X, Y, 'ks') #绘制训练数据集散点图
plt.plot(X2, Y2, 'g-') #绘制预测数据集直线
plt.show()
调用sklearn包中的LinearRegression()回归函数,fit(X,Y)载入数据集进行训练,然后通过predict(X2)预测数据集X2的利润,并将预测结果绘制成直线,(X,Y)数据集绘制成散点图,如图3所示。

同时调用代码预测2017年企业成本为1200元的利润为575.1元。注意,线性模型的回归系数会保存在coef_变量中,截距保存在intercept_变量中。clf.score(X, Y) 是一个评分函数,返回一个小于1的得分。评分过程的代码如下:
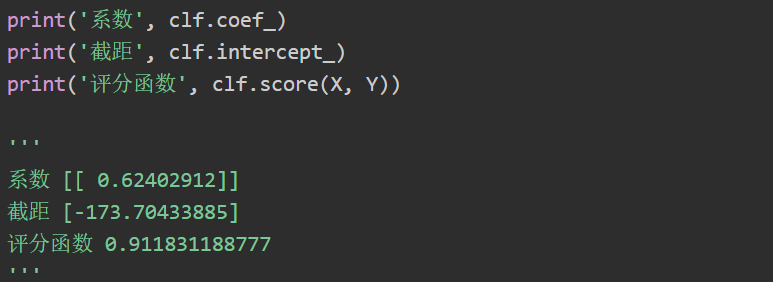

该直线对应的回归函数为:y = 0.62402912 * x - 173.70433885,则X2[1]=400这个点预测的利润值为75.9,而X1中成本为400元对应的真实利润是80元,预测是基本准确的。
2.线性回归预测糖尿病
(1).糖尿病数据集
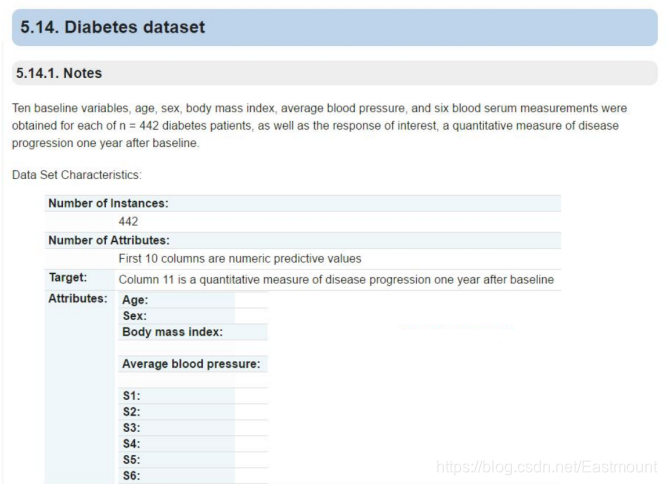
Sklearn机器学习包提供了糖尿病数据集(Diabetes Dataset),该数据集主要包括442行数据,10个特征值,分别是:年龄(Age)、性别(Sex)、体质指数(Body mass index)、平均血压(Average Blood Pressure)、S1~S6一年后疾病级数指标。预测指标为Target,它表示一年后患疾病的定量指标。原网址的描述如图4所示:
下面代码进行简单的调用及数据规模的测试。
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
from sklearn import datasets
diabetes = datasets.load_diabetes() #载入数据
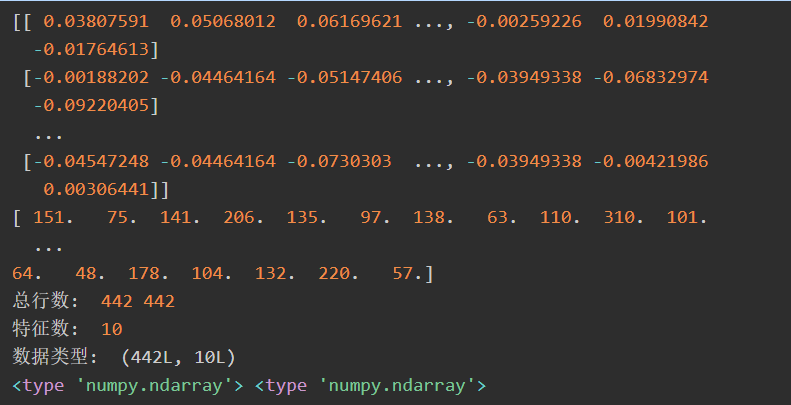
print(diabetes.data) #数据
print(diabetes.target) #类标
print('总行数: ', len(diabetes.data), len(diabetes.target))
print('特征数: ', len(diabetes.data[0])) #每行数据集维数
print('数据类型: ', diabetes.data.shape)
print(type(diabetes.data), type(diabetes.target))
调用load_diabetes()函数载入糖尿病数据集,然后输出其数据data和类标target。输出总行数442行,特征数共10个,类型为(442L, 10L)。其输出如下所示:
(2).代码实现
现在我们将糖尿病数据集划分为训练集和测试集,整个数据集共442行,我们取前422行数据用来线性回归模型训练,后20行数据用来预测。其中取预测数据的代码为diabetes_x_temp[-20:],表示从后20行开始取值,直到数组结束,共取值20个数。整个数据集共10个特征值,为了方便可视化画图我们只获取其中一个特征进行实验,这也可以绘制图形,而真实分析中,通常经过降维处理再绘制图形。这里获取第3个特征,对应代码为:diabetes_x_temp = diabetes.data[:, np.newaxis, 2]。完整代码如下:
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn import linear_model
import numpy as np
#数据集划分
diabetes = datasets.load_diabetes() #载入数据
diabetes_x_temp = diabetes.data[:, np.newaxis, 2] #获取其中一个特征
diabetes_x_train = diabetes_x_temp[:-20] #训练样本
diabetes_x_test = diabetes_x_temp[-20:] #测试样本 后20行
diabetes_y_train = diabetes.target[:-20] #训练标记
diabetes_y_test = diabetes.target[-20:] #预测对比标记
#回归训练及预测
clf = linear_model.LinearRegression()
clf.fit(diabetes_x_train, diabetes_y_train) #训练数据集
pre = clf.predict(diabetes_x_test)
#绘图
plt.title(u'LinearRegression Diabetes') #标题
plt.xlabel(u'Attributes') #x轴坐标
plt.ylabel(u'Measure of disease') #y轴坐标
plt.scatter(diabetes_x_test, diabetes_y_test, color = 'black') #散点图
plt.plot(diabetes_x_test, pre, color='blue', linewidth = 2) #预测直线
plt.show()
输出结果如图5所示,每个点表示真实的值,而直线表示预测的结果。
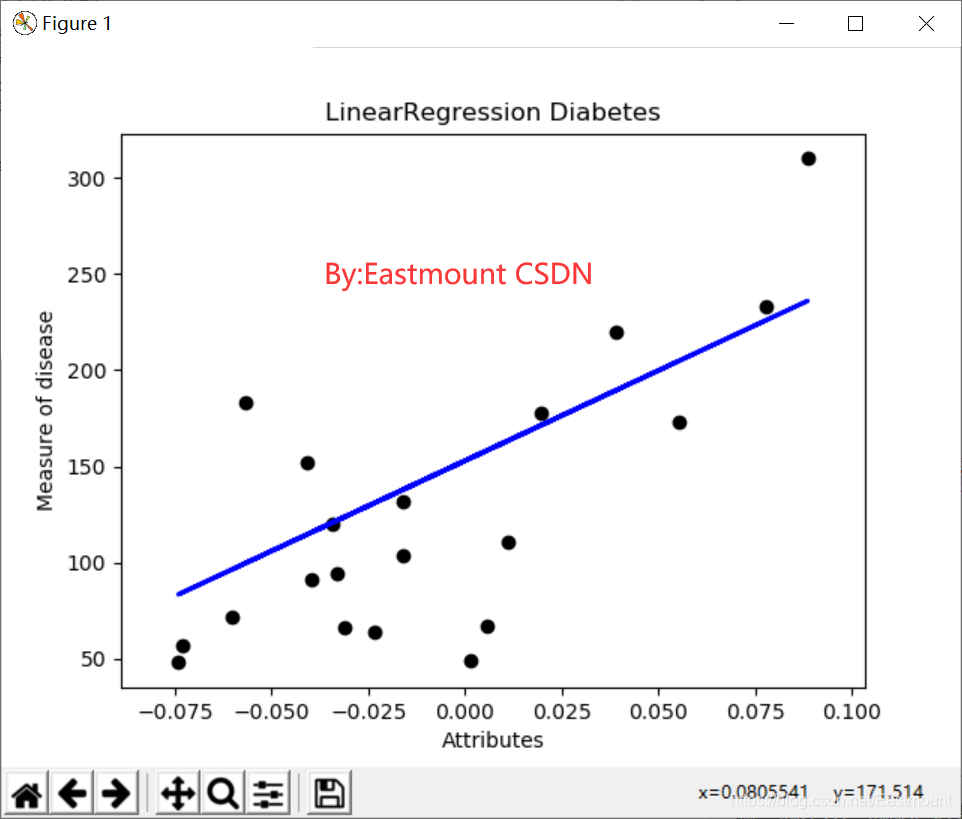
(3).代码优化
下面代码增加了几个优化措施,包括增加了斜率、 截距的计算,可视化绘图增加了散点到线性方程的距离线,增加了保存图片设置像素代码等。这些优化都更好地帮助我们分析真实的数据集。
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
from sklearn import datasets
import numpy as np
from sklearn import linear_model
import matplotlib.pyplot as plt
#第一步 数据集划分
d = datasets.load_diabetes() #数据 10*442
x = d.data
x_one = x[:,np.newaxis, 2] #获取一个特征 第3列数据
y = d.target #获取的正确结果
x_train = x_one[:-42] #训练集X [ 0:400]
x_test = x_one[-42:] #预测集X [401:442]
y_train = y[:-42] #训练集Y [ 0:400]
y_test = y[-42:] #预测集Y [401:442]
#第二步 线性回归实现
clf = linear_model.LinearRegression()
print(clf)
clf.fit(x_train, y_train)
pre = clf.predict(x_test)
print('预测结果', pre)
print('真实结果', y_test)
#第三步 评价结果
cost = np.mean(y_test-pre)**2 #2次方
print('平方和计算:', cost)
print('系数', clf.coef_)
print('截距', clf.intercept_)
print('方差', clf.score(x_test, y_test))
#第四步 绘图
plt.plot(x_test, y_test, 'k.') #散点图
plt.plot(x_test, pre, 'g-') #预测回归直线
#绘制点到直线距离
for idx, m in enumerate(x_test):
plt.plot([m, m],[y_test[idx], pre[idx]], 'r-')
plt.savefig('blog12-01.png', dpi=300) #保存图片
plt.show()
绘制的图形如图6所示。
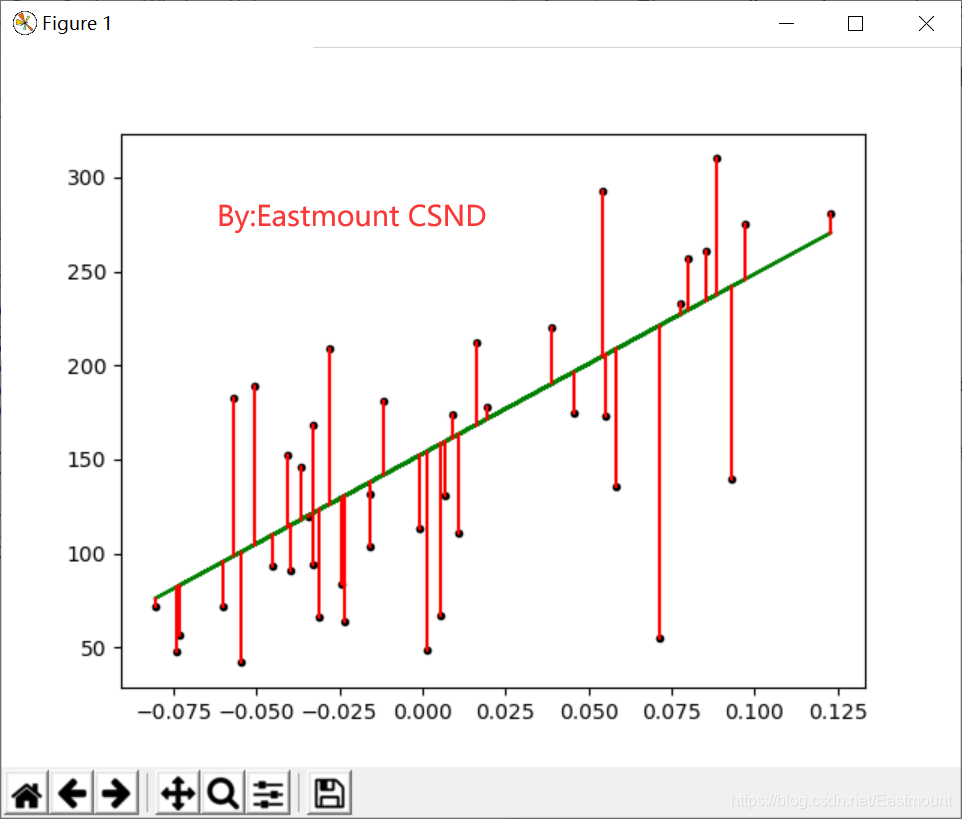
输出结果如下:
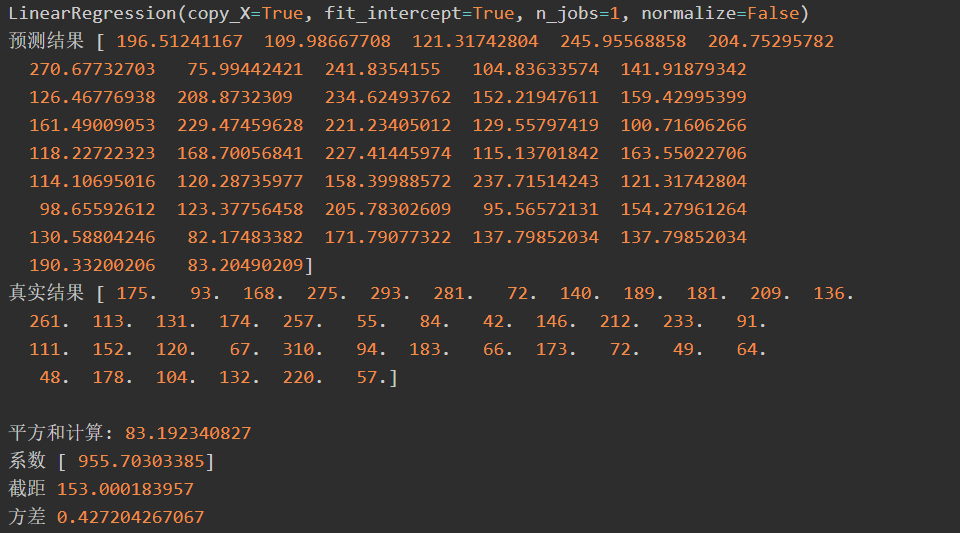
其中cost = np.mean(y_test-pre)**2表示计算预测结果和真实结果之间的平方和,为83.192340827,根据系数和截距得出其方程为:y = 955.70303385 * x + 153.000183957。
三.多项式回归分析
1.基础概念
线性回归研究的是一个目标变量和一个自变量之间的回归问题,但有时候在很多实际问题中,影响目标变量的自变量往往不止一个,而是多个,比如绵羊的产毛量这一变量同时受到绵羊体重、胸围、体长等多个变量的影响,因此需要设计一个目标变量与多个自变量间的回归分析,即多元回归分析。由于线性回归并不适用于所有的数据,我们需要建立曲线来适应我们的数据,现实世界中的曲线关系很多都是增加多项式实现的,比如一个二次函数模型:
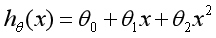
再或者一个三次函数模型:
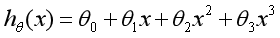
这两个模型我们绘制的图形如下所示:

多项式回归(Polynomial Regression)是研究一个因变量与一个或多个自变量间多项式的回归分析方法。如果自变量只有一个时,称为一元多项式回归;如果自变量有多个时,称为多元多项式回归。在一元回归分析中,如果依变量y与自变量x的关系为非线性的,但是又找不到适当的函数曲线来拟合,则可以采用一元多项式回归。17.3小节主要讲解一元多次的多项式回归分析,一元m次多项式方程如下:
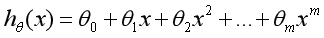
其方程的求解过程希望读者下来自行学习,接下来作者主要讲解Python如何代码实现多项式回归分析的。
2.PolynomialFeatures
Python的多项式回归需要导入sklearn.preprocessing子类中PolynomialFeatures类实现。PolynomialFeatures对应的函数原型如下:
class sklearn.preprocessing.PolynomialFeatures(degree=2,
interaction_only=False,
include_bias=True)
PolynomialFeatures类在Sklearn官网给出的解释是:专门产生多项式的模型或类,并且多项式包含的是相互影响的特征集。共有三个参数,degree表示多项式阶数,一般默认值是2;interaction_only如果值是true(默认是False),则会产生相互影响的特征集;include_bias表示是否包含偏差列。
PolynomialFeatures类通过实例化一个多项式,建立等差数列矩阵,然后进行训练和预测,最后绘制相关图形,接下来与前面的一元线性回归分析进行对比试验。
3.多项式回归预测成本和利润
本小节主要讲解多项式回归分析实例,分析的数据集是表17.1提供的企业成本和利润数据集。下面直接给出线性回归和多项式回归分析对比的完整代码和详细注释。
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
import matplotlib.pyplot as plt
import numpy as np
#X表示企业成本 Y表示企业利润
X = [[400], [450], [486], [500], [510], [525], [540], [549], [558], [590], [610], [640], [680], [750], [900]]
Y = [[80], [89], [92], [102], [121], [160], [180], [189], [199], [203], [247], [250], [259], [289], [356]]
print('数据集X: ', X)
print('数据集Y: ', Y)
#第一步 线性回归分析
clf = LinearRegression()
clf.fit(X, Y)
X2 = [[400], [750], [950]]
Y2 = clf.predict(X2)
print(Y2)
res = clf.predict(np.array([1200]).reshape(-1, 1))[0]
print('预测成本1200元的利润:$%.1f' % res)
plt.plot(X, Y, 'ks') #绘制训练数据集散点图
plt.plot(X2, Y2, 'g-') #绘制预测数据集直线
#第二步 多项式回归分析
xx = np.linspace(350,950,100) #350到950等差数列
quadratic_featurizer = PolynomialFeatures(degree = 2) #实例化一个二次多项式
x_train_quadratic = quadratic_featurizer.fit_transform(X) #用二次多项式x做变换
X_test_quadratic = quadratic_featurizer.transform(X2)
regressor_quadratic = LinearRegression()
regressor_quadratic.fit(x_train_quadratic, Y)
#把训练好X值的多项式特征实例应用到一系列点上,形成矩阵
xx_quadratic = quadratic_featurizer.transform(xx.reshape(xx.shape[0], 1))
plt.plot(xx, regressor_quadratic.predict(xx_quadratic), "r--",
label="$y = ax^2 + bx + c$",linewidth=2)
plt.legend()
plt.show()
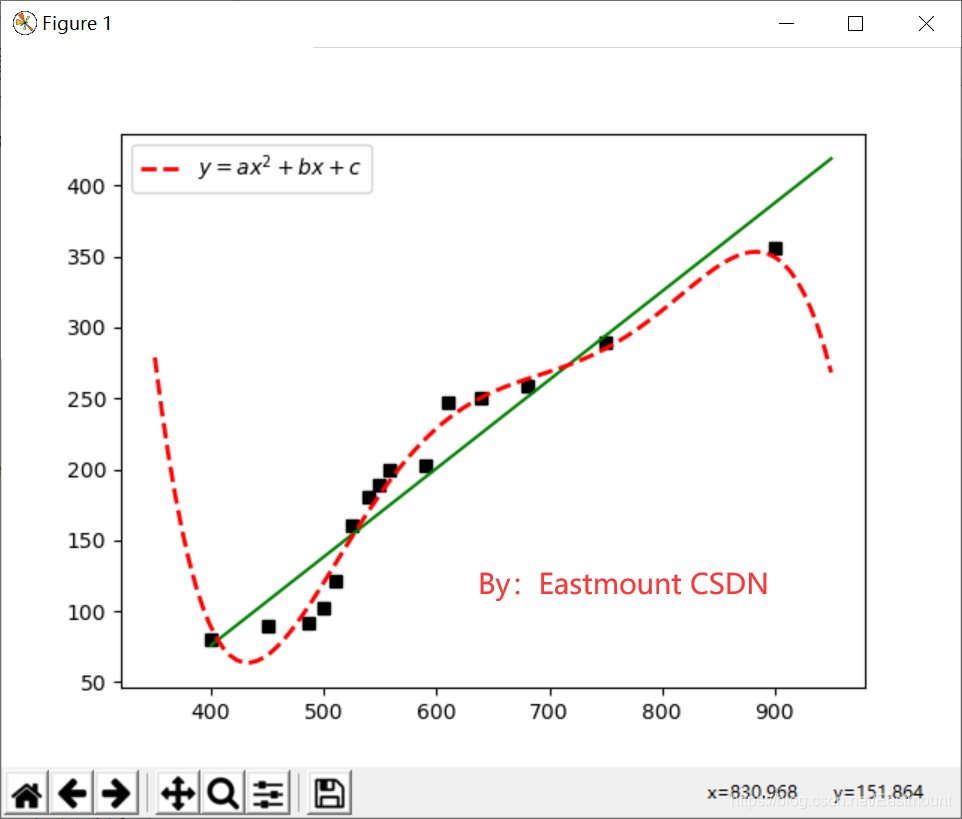
输出图形如下图所示,其中黑色散点图表示真实的企业成本和利润的关系,绿色直线为一元线性回归方程,红色虚曲线为二次多项式方程。它更接近真实的散点图。
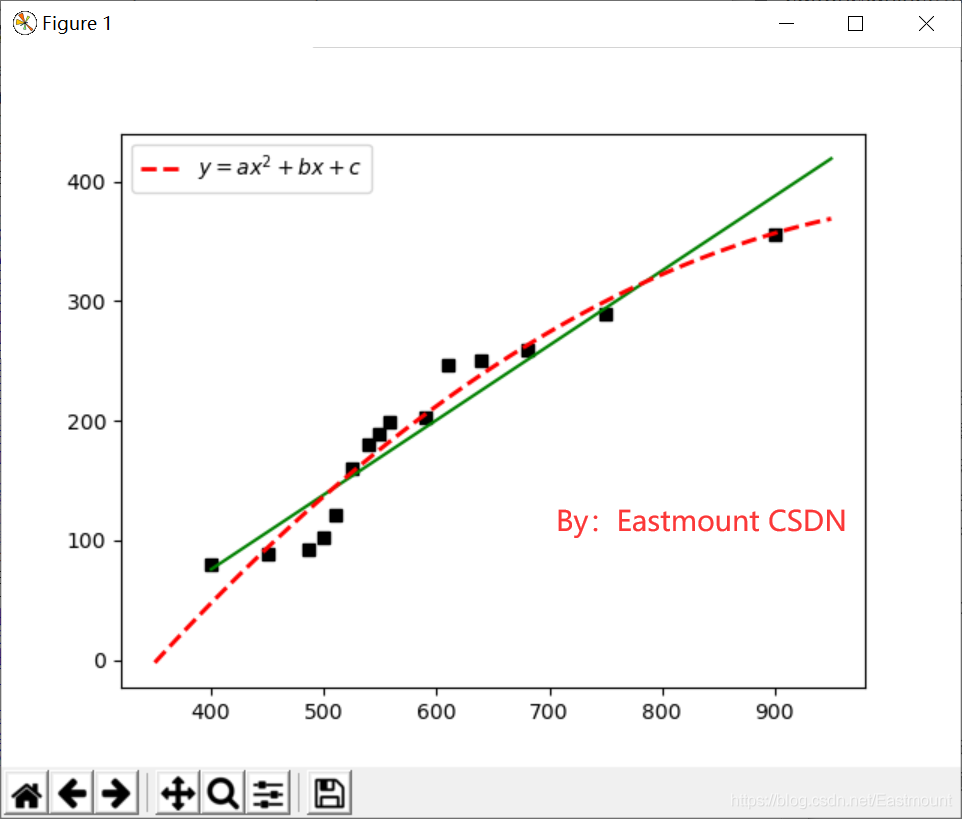
这里我们使用R方(R-Squared)来评估多项式回归预测的效果,R方也叫确定系数(Coefficient of Determination),它表示模型对现实数据拟合的程度。计算R方的方法有几种,一元线性回归中R方等于皮尔逊积矩相关系数(Pearson Product Moment Correlation Coefficient)的平方,该方法计算的R方是一定介于0~1之间的正数。另一种是Sklearn库提供的方法来计算R方。R方计算代码如下:
print('1 r-squared', clf.score(X, Y))
print('2 r-squared', regressor_quadratic.score(x_train_quadratic, Y))
输出如下所示:
('1 r-squared', 0.9118311887769025)
('2 r-squared', 0.94073599498559335)
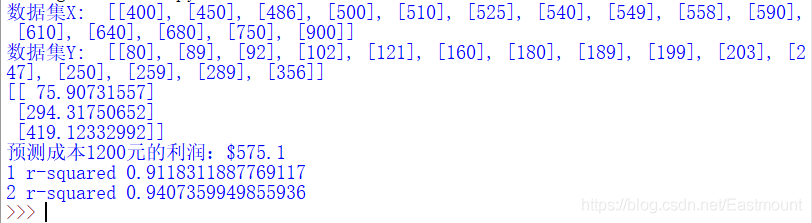
一元线性回归的R方值为0.9118,多项式回归的R方值为0.9407,说明数据集中超过94%的价格都可以通过模型解释。最后补充5次项的拟合过程,下面只给出核心代码。
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
import matplotlib.pyplot as plt
import numpy as np
#X表示企业成本 Y表示企业利润
X = [[400], [450], [486], [500], [510], [525], [540], [549], [558], [590], [610], [640], [680], [750], [900]]
Y = [[80], [89], [92], [102], [121], [160], [180], [189], [199], [203], [247], [250], [259], [289], [356]]
print('数据集X: ', X)
print('数据集Y: ', Y)
#第一步 线性回归分析
clf = LinearRegression()
clf.fit(X, Y)
X2 = [[400], [750], [950]]
Y2 = clf.predict(X2)
print(Y2)
res = clf.predict(np.array([1200]).reshape(-1, 1))[0]
print('预测成本1200元的利润:$%.1f' % res)
plt.plot(X, Y, 'ks') #绘制训练数据集散点图
plt.plot(X2, Y2, 'g-') #绘制预测数据集直线
#第二步 多项式回归分析
xx = np.linspace(350,950,100)
quadratic_featurizer = PolynomialFeatures(degree = 5)
x_train_quadratic = quadratic_featurizer.fit_transform(X)
X_test_quadratic = quadratic_featurizer.transform(X2)
regressor_quadratic = LinearRegression()
regressor_quadratic.fit(x_train_quadratic, Y)
#把训练好X值的多项式特征实例应用到一系列点上,形成矩阵
xx_quadratic = quadratic_featurizer.transform(xx.reshape(xx.shape[0], 1))
plt.plot(xx, regressor_quadratic.predict(xx_quadratic), "r--",
label="$y = ax^2 + bx + c$",linewidth=2)
plt.legend()
plt.show()
print('1 r-squared', clf.score(X, Y))
print('5 r-squared', regressor_quadratic.score(x_train_quadratic, Y))
# ('1 r-squared', 0.9118311887769025)
# ('5 r-squared', 0.98087802460869788)
输出如下所示,其中红色虚线为五次多项式曲线,它更加接近真实数据集的分布情况,而绿色直线为一元线性回归方程,显然相较于五次多项式曲线,线性方程拟合的结果更差。同时,五次多项式曲线的R方值为98.08%,非常准确的预测了数据趋势。
最后补充一点,建议多项式回归的阶数不要太高,否则会出现过拟合现象。
四.逻辑回归
1.基础原理
在前面讲述的回归模型中,处理的因变量都是数值型区间变量,建立的模型描述是因变量的期望与自变量之间的线性关系或多项式曲线关系。比如常见的线性回归模型:

而在采用回归模型分析实际问题中,所研究的变量往往不全是区间变量而是顺序变量或属性变量,比如二项分布问题。通过分析年龄、性别、体质指数、平均血压、疾病指数等指标,判断一个人是否换糖尿病,Y=0表示未患病,Y=1表示患病,这里的响应变量是一个两点(0或1)分布变量,它就不能用h函数连续的值来预测因变量Y(Y只能取0或1)。
总之,线性回归或多项式回归模型通常是处理因变量为连续变量的问题,如果因变量是定性变量,线性回归模型就不再适用了,此时需采用逻辑回归模型解决。
逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题,常见的是二分类或二项分布问题,也可以处理多分类问题,它实际上是属于一种分类方法。
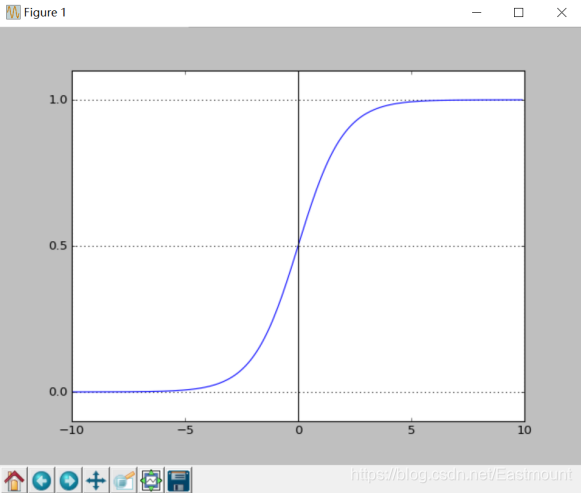
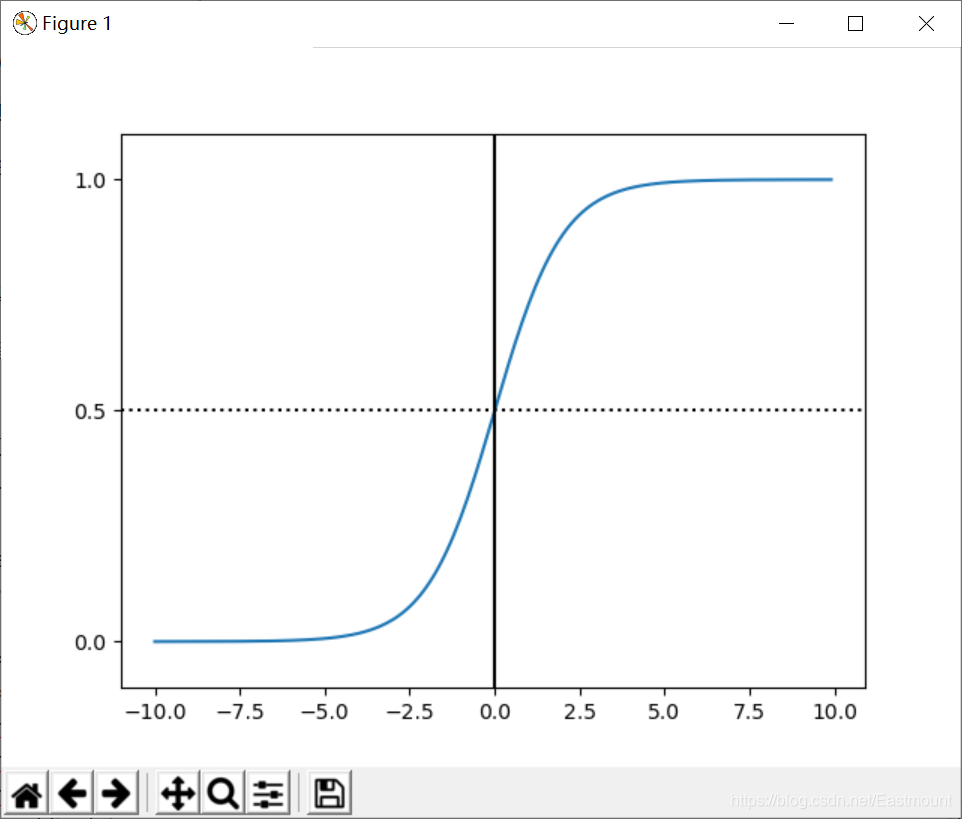
二分类问题的概率与自变量之间的关系图形往往是一个S型曲线,如图17.10所示,采用的Sigmoid函数实现。这里我们将该函数定义如下:
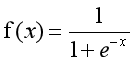
函数的定义域为全体实数,值域在[0,1]之间,x轴在0点对应的结果为0.5。当x取值足够大的时候,可以看成0或1两类问题,大于0.5可以认为是1类问题,反之是0类问题,而刚好是0.5,则可以划分至0类或1类。对于0-1型变量,y=1的概率分布公式定义如下:
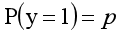
y=0的概率分布公式定义如下:
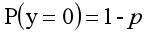
其离散型随机变量期望值公式如下:

采用线性模型进行分析,其公式变换如下:
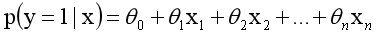
而实际应用中,概率p与因变量往往是非线性的,为了解决该类问题,我们引入了logit变换,使得logit§与自变量之间存在线性相关的关系,逻辑回归模型定义如下:
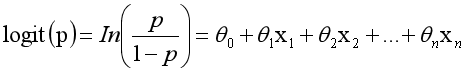
通过推导,概率p变换如下,这与Sigmoid函数相符,也体现了概率p与因变量之间的非线性关系。以0.5为界限,预测p大于0.5时,我们判断此时y更可能为1,否则y为0。

得到所需的Sigmoid函数后,接下来只需要和前面的线性回归一样,拟合出该式中n个参数θ即可。下列为绘制Sigmoid曲线,输出如图10所示。
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
import matplotlib.pyplot as plt
import numpy as np
def Sigmoid(x):
return 1.0 / (1.0 + np.exp(-x))
x= np.arange(-10, 10, 0.1)
h = Sigmoid(x) #Sigmoid函数
plt.plot(x, h)
plt.axvline(0.0, color='k') #坐标轴上加一条竖直的线(0位置)
plt.axhspan(0.0, 1.0, facecolor='1.0', alpha=1.0, ls='dotted')
plt.axhline(y=0.5, ls='dotted', color='k')
plt.yticks([0.0, 0.5, 1.0]) #y轴标度
plt.ylim(-0.1, 1.1) #y轴范围
plt.show()
由于篇幅有限,逻辑回归构造损失函数J函数,求解最小J函数及回归参数θ的方法就不在叙述,原理和前面介绍的一样,请读者下去深入研究。
2.LogisticRegression
LogisticRegression回归模型在Sklearn.linear_model子类下,调用sklearn逻辑回归算法步骤比较简单,即:
- 导入模型。调用逻辑回归LogisticRegression()函数。
- fit()训练。调用fit(x,y)的方法来训练模型,其中x为数据的属性,y为所属类型。
- predict()预测。利用训练得到的模型对数据集进行预测,返回预测结果。
代码如下:
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
from sklearn.linear_model import LogisticRegression #导入逻辑回归模型
clf = LogisticRegression()
print(clf)
clf.fit(train_feature,label)
predict['label'] = clf.predict(predict_feature)
输出函数的构造方法如下:

这里仅介绍两个参数:参数penalty表示惩罚项,包括两个可选值L1和L2。L1表示向量中各元素绝对值的和,常用于特征选择;L2表示向量中各个元素平方之和再开根号,当需要选择较多的特征时,使用L2参数,使他们都趋近于0。C值的目标函数约束条件为:s.t.||w||1<C,默认值是0,C值越小,则正则化强度越大。
3.鸢尾花数据集回归分析实例
下面将结合Scikit-learn官网的逻辑回归模型分析鸢尾花数据集。由于该数据分类标签划分为3类(0类、1类、2类),属于三分类问题,所以能利用逻辑回归模型对其进行分析。
(1).鸢尾花数据集
在Sklearn机器学习包中,集成了各种各样的数据集,包括前面的糖尿病数据集,这里引入的是鸢尾花卉(Iris)数据集,它也是一个很常用的数据集。该数据集一共包含4个特征变量,1个类别变量,共有150个样本。其中四个特征分别是萼片的长度和宽度、花瓣的长度和宽度,一个类别变量是标记鸢尾花所属的分类情况,该值包含三种情况,即山鸢尾(Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)。鸢尾花数据集详细介绍如表2所示:
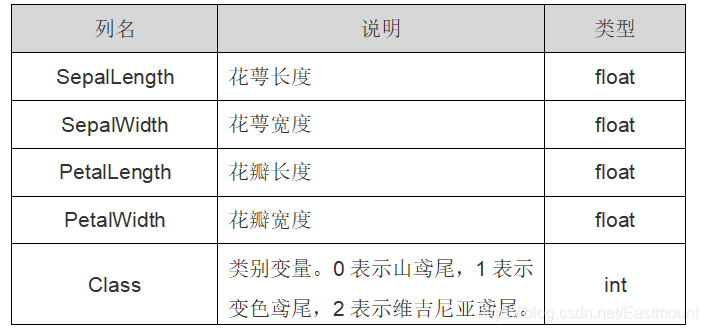
Class 类别变量。0表示山鸢尾,1表示变色鸢尾,2表示维吉尼亚鸢尾。 int
iris里有两个属性iris.data,iris.target。data是一个矩阵,每一列代表了萼片或花瓣的长宽,一共4列,每一行代表一个被测量的鸢尾植物,一共采样了150条记录,即150朵鸢尾花样本。
from sklearn.datasets import load_iris #导入数据集iris
iris = load_iris() #载入数据集
print(iris.data)
target是一个数组,存储了每行数据对应的样本属于哪一类鸢尾植物,要么是山鸢尾(值为0),要么是变色鸢尾(值为1),要么是维吉尼亚鸢尾(值为2),数组的长度是150。

从输出结果可以看到,类标共分为三类,前面50个类标位0,中间50个类标位1,后面为2。下面给详细介绍使用逻辑回归对这个数据集进行分析的代码。
(2).散点图绘制
在载入了鸢尾花数据集(数据data和标签target)之后,我们需要获取其中两列数据或两个特征,再调用scatter()函数绘制散点图。其中获取一个特征的核心代码为:X = [x[0] for x in DD],将获取的值赋值给X变量。完整代码如下:
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_iris #导入数据集iris
#载入数据集
iris = load_iris()
print(iris.data) #输出数据集
print(iris.target) #输出真实标签
#获取花卉两列数据集
DD = iris.data
X = [x[0] for x in DD]
print(X)
Y = [x[1] for x in DD]
print(Y)
#plt.scatter(X, Y, c=iris.target, marker='x')
plt.scatter(X[:50], Y[:50], color='red', marker='o', label='setosa') #前50个样本
plt.scatter(X[50:100], Y[50:100], color='blue', marker='x', label='versicolor') #中间50个
plt.scatter(X[100:], Y[100:],color='green', marker='+', label='Virginica') #后50个样本
plt.legend(loc=2) #左上角
plt.show()
输出如图11所示:

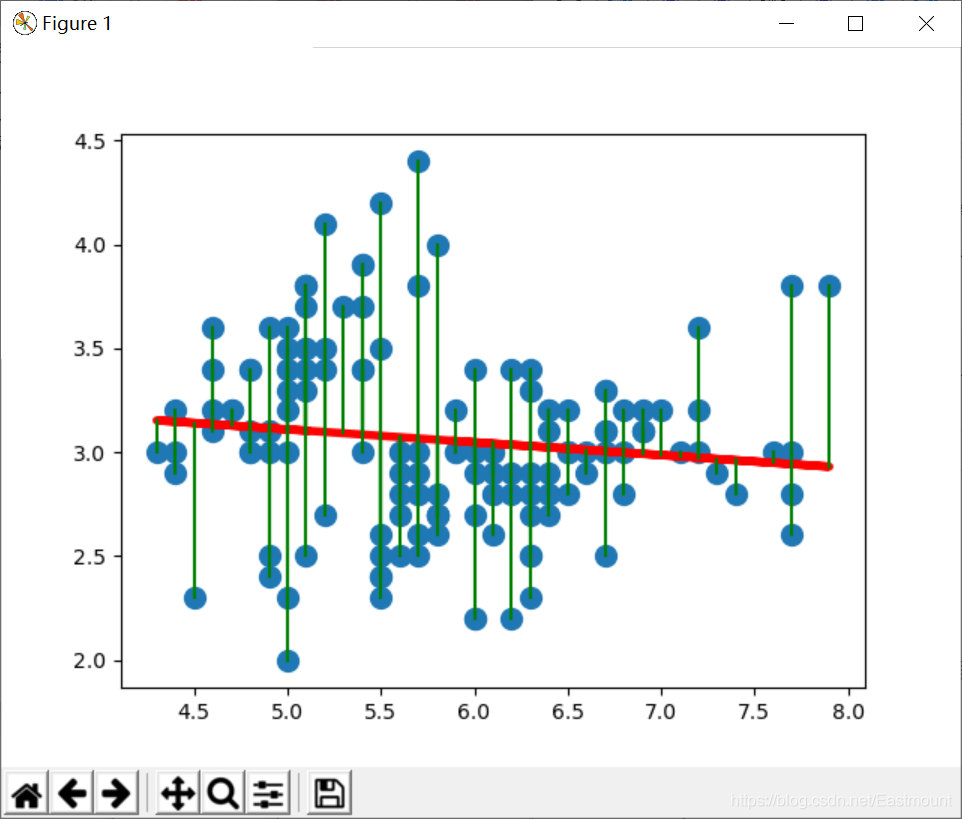
(3).线性回归分析
下述代码先获取鸢尾花数据集的前两列数据,再调用Sklearn库中线性回归模型进行分析,完整代码如文件所示。
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
#第一步 导入数据集
from sklearn.datasets import load_iris
hua = load_iris()
#获取花瓣的长和宽
x = [n[0] for n in hua.data]
y = [n[1] for n in hua.data]
import numpy as np #转换成数组
x = np.array(x).reshape(len(x),1)
y = np.array(y).reshape(len(y),1)
#第二步 线性回归分析
from sklearn.linear_model import LinearRegression
clf = LinearRegression()
clf.fit(x,y)
pre = clf.predict(x)
print(pre)
#第三步 画图
import matplotlib.pyplot as plt
plt.scatter(x,y,s=100)
plt.plot(x,pre,"r-",linewidth=4)
for idx, m in enumerate(x):
plt.plot([m,m],[y[idx],pre[idx]], 'g-')
plt.show()
输出图形如图12所示,并且可以看到所有散点到拟合的一元一次方程的距离。
(4).逻辑回归分析鸢尾花
讲解完线性回归分析之后,那如果用逻辑回归分析的结果究竟如何呢?下面开始讲述。从散点图(图11)中可以看出,数据集是线性可分的,划分为3类,分别对应三种类型的鸢尾花,下面采用逻辑回归对其进行分析预测。前面使用X=[x[0] for x in DD]获取第一列数据,Y=[x[1] for x in DD]获取第二列数据,这里采用另一种方法,iris.data[:, :2]获取其中两列数据或两个特征,完整代码如下:
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
#载入数据集
iris = load_iris()
X = X = iris.data[:, :2] #获取花卉两列数据集
Y = iris.target
#逻辑回归模型
lr = LogisticRegression(C=1e5)
lr.fit(X,Y)
#meshgrid函数生成两个网格矩阵
h = .02
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
#pcolormesh函数将xx,yy两个网格矩阵和对应的预测结果Z绘制在图片上
Z = lr.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure(1, figsize=(8,6))
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired)
#绘制散点图
plt.scatter(X[:50,0], X[:50,1], color='red',marker='o', label='setosa')
plt.scatter(X[50:100,0], X[50:100,1], color='blue', marker='x', label='versicolor')
plt.scatter(X[100:,0], X[100:,1], color='green', marker='s', label='Virginica')
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.xticks(())
plt.yticks(())
plt.legend(loc=2)
plt.show()
输出如图13所示。经过逻辑回归后划分为三个区域,左上角部分为红色的圆点,对应setosa鸢尾花;右上角部分为绿色方块,对应virginica鸢尾花;中间下部分为蓝色星形,对应versicolor鸢尾花。散点图为各数据点真实的花类型,划分的三个区域为数据点预测的花类型,预测的分类结果与训练数据的真实结果结果基本一致,部分鸢尾花出现交叉。
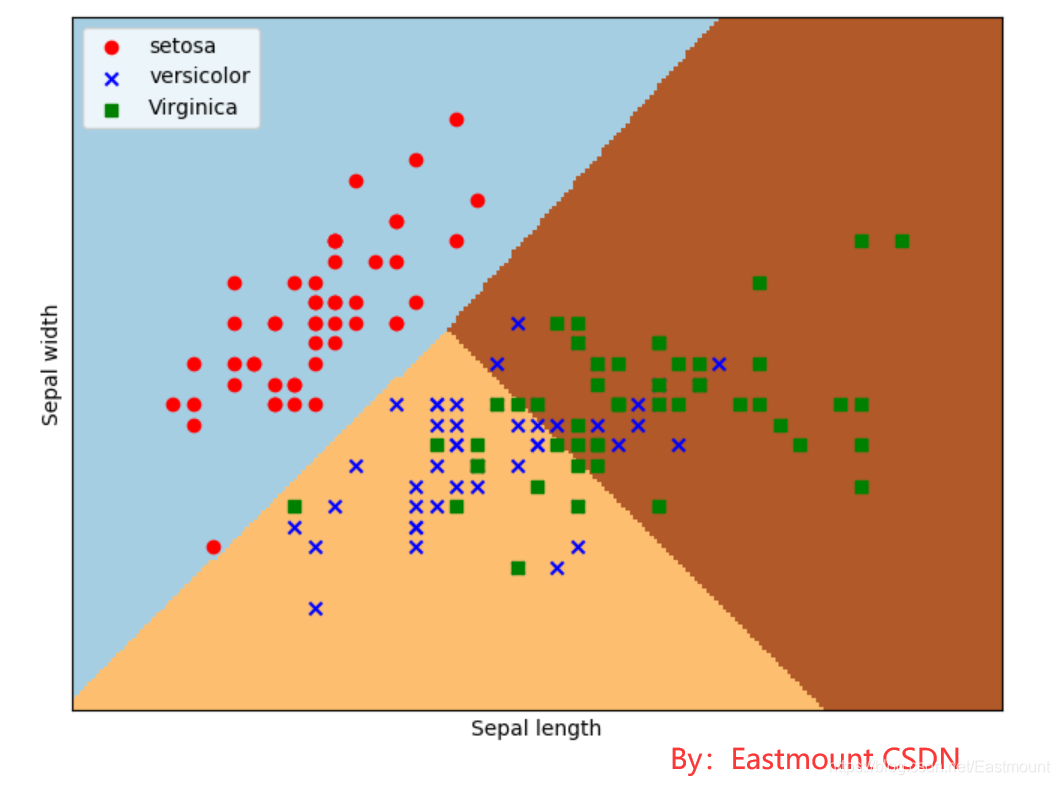
下面作者对导入数据集后的代码进行详细讲解。
- lr = LogisticRegression(C=1e5)
初始化逻辑回归模型,C=1e5表示目标函数。 - lr.fit(X,Y)
调用逻辑回归模型进行训练,参数X为数据特征,参数Y为数据类标。 - xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
获取鸢尾花数据集的两列数据,对应为花萼长度和花萼宽度,每个点的坐标就是(x,y)。 先取X二维数组的第一列(长度)的最小值、最大值和步长h(设置为0.02)生成数组,再取X二维数组的第二列(宽度)的最小值、最大值和步长h生成数组, 最后用meshgrid函数生成两个网格矩阵xx和yy,如下所示:
- Z = lr.predict(np.c_[xx.ravel(), yy.ravel()])
调用ravel()函数将xx和yy的两个矩阵转变成一维数组,由于两个矩阵大小相等,因此两个一维数组大小也相等。np.c_[xx.ravel(), yy.ravel()]是获取并合并成矩阵,即:
总之,上述操作是把第一列花萼长度数据按h取等分作为行,并复制多行得到xx网格矩阵;再把第二列花萼宽度数据按h取等分作为列,并复制多列得到yy网格矩阵;最后将xx和yy矩阵都变成两个一维数组,再调用np.c_[]函数将其组合成一个二维数组进行预测。
- Z = logreg.predict(np.c_[xx.ravel(), yy.ravel()])
调用predict()函数进行预测,预测结果赋值给Z。即:
- Z = Z.reshape(xx.shape)
调用reshape()函数修改形状,将Z变量转换为两个特征(长度和宽度),则39501个数据转换为171*231的矩阵。Z = Z.reshape(xx.shape)输出如下:
- plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired)
调用pcolormesh()函数将xx、yy两个网格矩阵和对应的预测结果Z绘制在图片上,可以发现输出为三个颜色区块,分布表示分类的三类区域。cmap=plt.cm.Paired表示绘图样式选择Paired主题,输出区域如下图所示:

- plt.scatter(X[:50,0], X[:50,1], color=‘red’,marker=‘o’, label=‘setosa’)
调用scatter()绘制散点图,第一个参数为第一列数据(长度),第二个参数为第二列数据(宽度),第三、四个参数为设置点的颜色为红色,款式为圆圈,最后标记为setosa。
















![[ICS] 物理安全](https://img-blog.csdnimg.cn/img_convert/345ed33f47a2af29433820df448b9795.jpeg)