人工智能咨询培训老师叶梓 转载标明出处
当前的视频扩散模型虽然在生成质量上取得了巨大进步,但在处理高维视频数据时仍然面临内存和计算资源的高需求。这些模型通常直接处理高维视频数据,导致在生成视频时需要大量的计算资源和内存消耗。为了解决这一问题,由韩国高等科学技术院(KAIST)、NVIDIA公司、加州大学伯克利分校和加州理工学院的研究人员联合提出了一种新颖的视频扩散模型——内容-运动潜在扩散模型(CMD),这是一种高效的视频生成模型,它通过将视频编码为内容帧和低维运动潜在表示的组合来显著降低计算成本。
方法

图2展示了视频生成中图像扩散模型的传统扩展方法与本文提出的CMD方法之间的比较。在(a)部分,传统方法通过在预训练的图像扩散模型中直接添加时间层来扩展至视频生成,而在(b)部分,CMD方法则采用不同的策略,它将每个视频编码为类似图像的内容帧和运动潜在表示,接着对预训练的图像扩散模型(例如Stable Diffusion)进行微调以生成内容帧,并训练一个新的轻量级扩散模型(例如DiT)来生成运动表示。图中以蓝色标记了新增加的参数,显示了CMD方法在避免直接处理高维视频数据的同时,如何利用预训练图像模型的知识来提高视频生成的效率和质量。
扩散模型的核心概念是通过一个渐进的去噪过程从高斯分布 N(0x, Ix) 学习目标分布 pdata(x)。这个过程涉及一个预定义的前向过程 q(xt|x0),它从 pdata(x) 开始逐渐添加高斯噪声,直到时间步 T。这里的关键是学习一个反向过程 p(xt−1|xt),它可以被表述为一个高斯分布,其中 ϵθ(xt, t) 是通过 ϵ-预测目标训练的去噪自编码器。
内容-运动潜在扩散模型(CMD)由一个自编码器和两个潜在扩散模型组成。自编码器将视频 x1:L 编码为单个内容帧 x¯ 和低维运动潜在表示 z。模型的目标是学习分布 p(x¯, z|c),这可以通过两个扩散模型来实现,其中一个预训练的图像扩散模型用于学习内容帧分布 p(x¯|c)。

自编码器使用简单的重构目标(例如,ℓ2 损失)来编码视频输入 x1:L。图 4 展示了自编码器的编码器和解码器的结构。编码器 fϕ 包括一个基础网络 fϕB 和两个头 fϕI, fϕM,分别用于计算内容帧 x¯ 和运动潜在表示 z。内容帧 x¯ 是通过将所有帧的重要性加权求和得到的,而运动潜在表示 z 则设计为两个潜在表示的串联,即 z = (zx, zy)。
解码器网络 gψ 包括两个嵌入层 gψI, gψM 和一个视频网络 gψB,用于从 gψI, gψM 的输出重建 x1:L。视频网络的输入 v 是通过将每个 vt, vx, vy 的相应向量相加得到的。
内容帧扩散模型利用预训练的图像扩散模型,通过微调来学习 p(x¯|c),而不增加额外的参数。这种微调是内存高效的,因为它不增加输入维度,并且由于内容帧和自然图像之间的小差距,可以高效地训练。
运动扩散模型用于学习条件分布 p(z|x¯, c)。该模型利用 DiT(Peebles & Xie, 2023)的网络架构,这是一个基于 Vision Transformer 的扩散模型。模型通过将条件内容帧 x¯ 作为输入级补丁嵌入,为预测运动潜在表示 z 提供“密集条件”。这种设计使得模型能够快速收敛,主要得益于条件提供的丰富信息和运动潜在表示的低维度。
通过这种方法,CMD模型不仅提高了视频生成的效率,还通过减少输入维度显著降低了内存和计算成本。
实验
数据集:研究团队使用了两个主要的数据集进行评估:UCF-101和WebVid-10M。此外,他们还使用了MSR-VTT数据集进行文本到视频模型的零样本评估。所有模型训练仅使用了训练集,而测试集或验证集则被排除在外。
基线对比:对于UCF-101上的条件生成(非零样本),研究者考虑了DIGAN、TATS、CogVideo、Make-A-Video和MAGVIT等最近的方法作为基线。对于零样本评估,他们与CogVideo、LVDM、ModelScope、VideoLDM、VideoFactory、PYoCo、GODIVA和NUWA等方法进行了比较。
训练细节:在所有实验中,视频被剪辑成16帧用于训练和评估。视频自编码器使用了TimeSFormer作为骨干网络。内容帧扩散模型使用了预训练的Stable Diffusion模型,而运动扩散模型则使用了DiT架构。
通过可视化生成的视频,研究者展示了CMD模型生成的视频在细节动态和内容上与文本提示高度一致,并且在不同视频帧之间保持了良好的时间连贯性。例如,在“A Teddy Bear Skating in Times Square”的示例中,时代广场的细节在不同视频帧中得到了很好的保留。

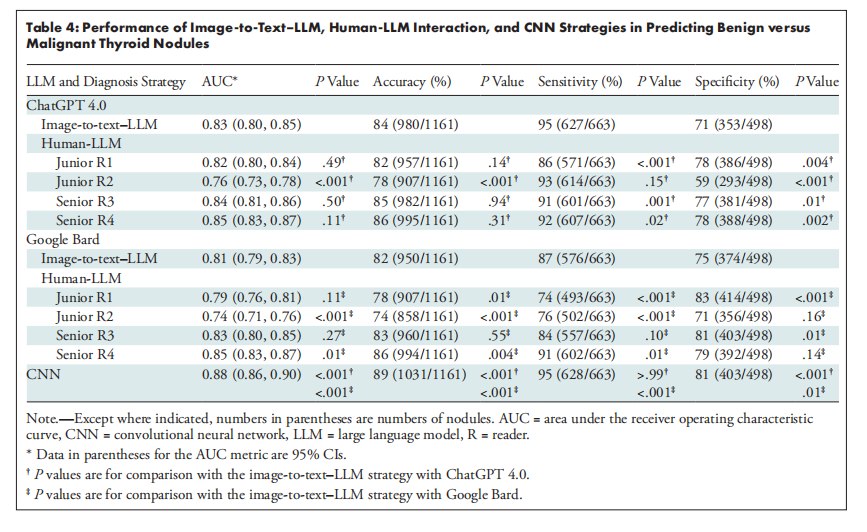
表1展示了在UCF-101上进行非零样本生成的结果。CMD在所有其他视频生成方法中表现最佳,这表明CMD框架设计本身就是一种有效的视频生成方法,无论是否利用预训练的图像扩散模型。此外,通过在WebVid-10M上训练CMD,并使用预训练的SD骨干进行内容帧生成,研究者发现在相同数据量的情况下,CMD模型的FVD得分优于先前的方法。

表2:展示了在MSR-VTT上进行文本到视频生成的结果,CMD模型在数据集大小为10.7M时表现良好。表3:展示了在WebVid-10M上进行文本到视频生成的结果,CMD模型在不同的分类器自由指导尺度下都取得了较低的FVD得分和较高的CLIPSIM得分。

图5总结了CMD各个组成部分的训练计算(浮点运算次数;FLOPs)、时间和内存消耗,并与其他公开的文本到视频扩散模型进行了比较。CMD的所有组成部分由于将视频分解为两个低维潜在变量(内容帧和运动潜在表示),因此在训练时需要更少的内存和计算。值得注意的是,CMD的FLOPs显著少于以前的方法:自编码器的瓶颈是0.77 TFLOPs,比ModelScope的9.41 TFLOPs大约12倍更高效。

图6报告了不同方法采样视频的FLOPs、时间和内存消耗。CMD避免了处理巨大的立方体数组,因此大大减少了冗余操作,从而实现了计算高效的视频生成框架。采样效率也反映在采样时间上;CMD仅需要大约3秒就可以使用DDIM采样器生成视频,比现有的文本到视频扩散模型快10倍。
通过这些实验,研究者证明了CMD模型在视频生成的质量和效率上都取得了显著的改进,并且与以往的方法相比具有明显的优势。
论文链接:https://arxiv.org/abs/2403.14148
项目地址:https://sihyun.me/CMD/