1 核函数
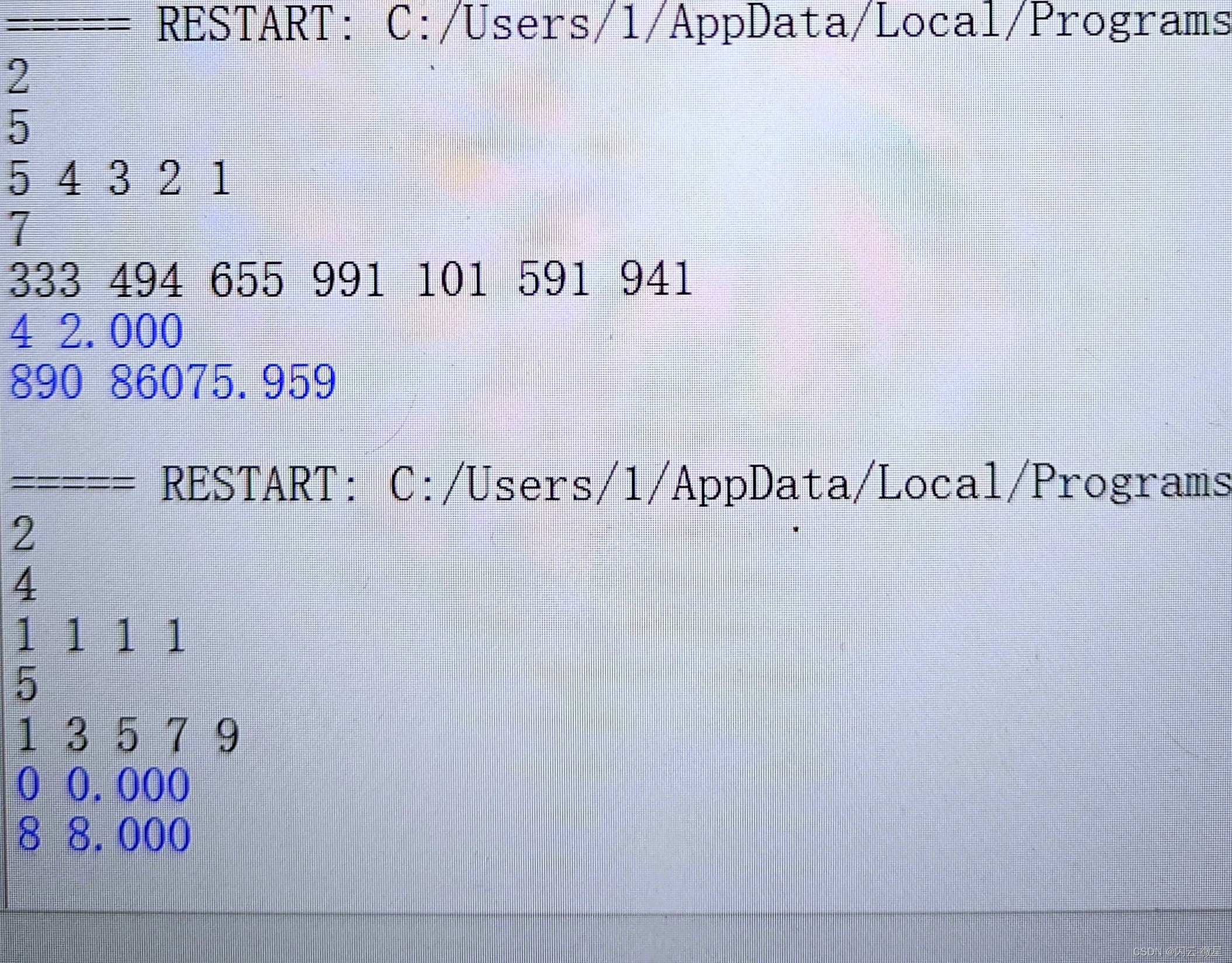
先看一个cuda版本的hello world
#include <stdio.h>
__global__ void helloworld()
{
printf("hello world\n");
}
int main()
{
helloworld()<<<1, 1>>>();
cudaDeviceSynchronize();
return 0;
}
这里helloworld()<<<1, 1>>>();就是核函数,关于核函数:
1 核函数(kernel function)在CPU调用,GPU执行
2 核函数必须用__global__修饰,返回值必须是void
3 核函数有两种写法,__global__ void xxx()或者 void __global__ xxx()
4 核函数的几个限制
4.1 核函数只能访问GPU内存
4.2 核函数不能使用变长参数
4.3 核函数不能使用static变量
4.4 核函数不能使用函数指针
4.5 核函数具有异步性
helloworld()<<<1, 1>>>();这行代码是什么意思,我们还不知道,不着急,接着往下看。
2 线程管理
当内核函数开始执行,如何组织GPU的线程就变成了最主要的问题了,我们必须明确,一个核函数只能有一个grid,一个grid可以有很多个块,每个块可以有很多的线程,这种分层的组织结构使得我们的并行过程更加自如灵活:

一个线程块block中的线程可以完成下述协作:
- 同步
- 共享内存
不同块内线程不能相互影响!他们是物理隔离的!
3 线程索引计算方式
3.1 内建变量gridDim / blockDim / blockIdx / threadIdx
内建变量只在核函数有限,且无需定义。
threadIdx是一个uint3类型,表示一个线程的索引。
blockIdx是一个uint3类型,表示一个线程块的索引,一个线程块中通常有多个线程。
blockDim是一个dim3类型,表示线程块的大小。
gridDim是一个dim3类型,表示网格的大小,一个网格中通常有多个线程块。
gridDim和blockDim
gridDim和blockDim是dim3类型(基于uint3定义的数据结构)的变量,都包含三个字段x,y,z,这两个内建变量三个字段的值分别等于初始化时grid_size和block_size的值。如:
dim3 grid_size(2,1,1);
dim3 block_size(3,2,1);
kernel_xxx<<<<gird_size, block_size>>>();
/*
gridDim.x=2, gridDim.y=1, gridDim.z=1
blockDim.x=3, blockDim.y=2, blockDim.z=1
*/
Note: gridDim和blockDim没有指定的维度默认为1
blockIdx和threadIdx
blockIdx和threadIdx是类型为uint3的变量,该类型是一个结构体,包含x,y,z三个字段,其取值范围如下:
blockIdx.x 取值范围[0, gridDim.x -1]
blockIdx.y 取值范围[0, gridDim.y -1]
blockIdx.z 取值范围[0, gridDim.y -1]
threadIdx.x 取值范围[0, blockDim.x -1]
threadIdx.y 取值范围[0, blockDim.y -1]
threadIdx.z 取值范围[0, blockDim.z -1]
3.2 线程索引计算方式
一个Grid可以包含多个Blocks,Blocks的组织方式可以是一维的,二维或者三维的。block包含多个Threads,这些Threads的组织方式也可以是一维,二维或者三维的。所以共有九种方式。
CUDA中每一个线程都有一个唯一的标识ID—ThreadIdx,这个ID随着Grid和Block的划分方式的不同而变化,这里给出Grid和Block不同划分方式下线程索引ID的计算公式。

第一种:一维grid,一维block
int threadId = blockIdx.x *blockDim.x + threadIdx.x;
第二种:一维grid,二维block
int threadId = blockIdx.x * blockDim.x * blockDim.y+ threadIdx.y * blockDim.x + threadIdx.x;
第三种:一维grid,三维block
int threadId = blockIdx.x * blockDim.x * blockDim.y * blockDim.z
+ threadIdx.z * blockDim.y * blockDim.x
+ threadIdx.y * blockDim.x + threadIdx.x;
第四种:二维grid,一维block
int blockId = blockIdx.y * gridDim.x + blockIdx.x;
int threadId = blockId * blockDim.x + threadIdx.x;
第五种:二维grid,二维block
int blockId = blockIdx.x + blockIdx.y * gridDim.x;
int threadId = blockId * (blockDim.x * blockDim.y)
第六种:二维grid,三维block
int blockId = blockIdx.x + blockIdx.y * gridDim.x;
int threadId = blockId * (blockDim.x * blockDim.y * blockDim.z)
+ (threadIdx.z * (blockDim.x * blockDim.y))
+ (threadIdx.y * blockDim.x) + threadIdx.x;
第七种:三维grid,一维block
int blockId = blockIdx.x + blockIdx.y * gridDim.x
+ gridDim.x * gridDim.y * blockIdx.z;
int threadId = blockId * blockDim.x + threadIdx.x;
第八种:三维grid,二维block
int blockId = blockIdx.x + blockIdx.y * gridDim.x
+ gridDim.x * gridDim.y * blockIdx.z;
int threadId = blockId * (blockDim.x * blockDim.y)
+ (threadIdx.y * blockDim.x) + threadIdx.x;
第九种:三维grid,三维block
int blockId = blockIdx.x + blockIdx.y * gridDim.x
+ gridDim.x * gridDim.y * blockIdx.z;
int threadId = blockId * (blockDim.x * blockDim.y * blockDim.z)
+ (threadIdx.z * (blockDim.x * blockDim.y))
+ (threadIdx.y * blockDim.x) + threadIdx.x;
3.3 网格大小限制
gridDim.x 最大值 2^31-1
gridDim.y 最大值 2^16-1
gridDim.z 最大值 2^16-1
blockDim.x 最大值 1024
blockDim.y 最大值 1024
blockDim.z 最大值 64