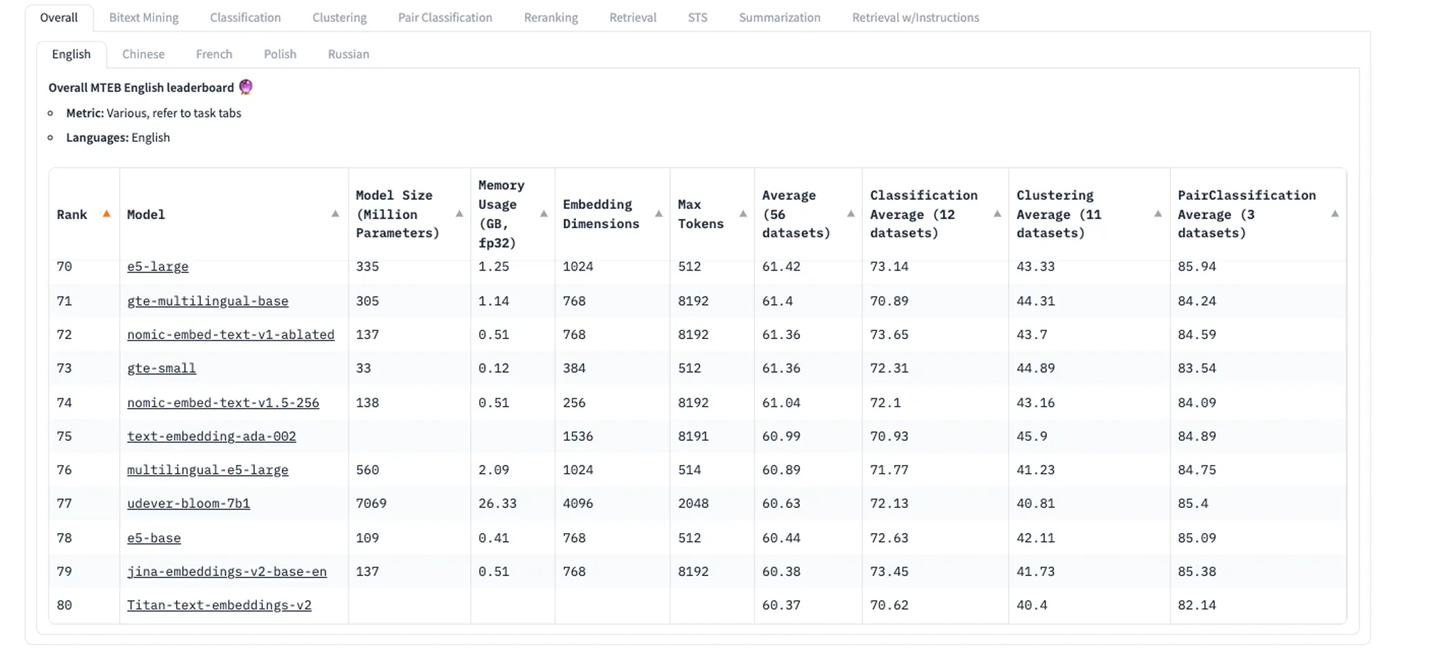
上节课遗留问题
封装一些简单的方法,比如:
- set:设置缓存,带默认超时时间
- get:获取缓存
- delete:删除缓存
- delete_all:清空缓存
封装set方法
基本方法
from zdppy_cache import Cache
# 创建缓存对象
cache = Cache()
# 关闭缓存对象
cache.close()
# 通过上下文自动关闭缓存对象
with Cache(cache.directory) as reference:
reference.set('key', 'value')
# 通过缓存对象获取值
print(cache.get('key'))
封装思路
- 1、基于内存
- 2、带默认缓存时间,单位秒,默认180秒
- 3、缓存默认上限
size_limit=100 * 1024 * 1024100M
基本封装
def set(key, value, expire=180):
"""
设置缓存
@param expire 默认过期时间,单位秒,默认180,也就是3分钟
:return:
"""
# 设置缓存
with Cache(cache_directory, ) as cache:
return cache.set(key, value, expire=expire)
封装get方法
原始代码
value = cache.get('key1')
print('Cached value:', value) # 输出: Cached value: value1
封装
def get(key):
"""
根据key获取缓存
:param key: 缓存的key
:return:
"""
with Cache(cache_directory, ) as cache:
return cache.get(key)
封装delete方法
原始代码
cache.delete('key1')
封装方法
def delete(key):
"""
根据key删除缓存
:param key: 缓存的key
:return:
"""
with Cache(cache_directory, ) as cache:
return cache.delete(key)
封装delete_all方法
原始代码
cache.close()
import shutil
try:
shutil.rmtree(cache.directory)
except OSError: # Windows wonkiness
pass
封装代码
def delete_all():
"""
删除所有的缓存
:return:
"""
try:
shutil.rmtree(cache_directory)
except OSError:
pass
测试代码
import zdppy_cache as c
# 设置缓存
key = "code"
value = "A13k"
c.set(key, value)
# 获取缓存
print(c.get(key))
# 删除缓存
c.delete(key)
print(c.get(key))
# 清空缓存
c.delete_all()
测试超时
默认三分钟超时,我们手动设置为3秒超时,3秒以后再访问。
import zdppy_cache as c
import time
# 设置缓存
key = "code"
value = "A13k"
c.set(key, value, 3)
# 获取缓存
print(c.get(key))
# 3秒后再获取
time.sleep(3)
print(c.get(key))
# 清空缓存
c.delete_all()
为什么cache都关闭了还能计算超时
因为数据是存在文件里面的,记录了开始时间和缓存结束时间。当我们get的时候,获取get那个时刻的时间,和缓存结束时间对比,就知道有没有过期了。
底层核心代码如下:
select = (
'SELECT rowid, expire_time, tag, mode, filename, value'
' FROM Cache WHERE key = ? AND raw = ?'
' AND (expire_time IS NULL OR expire_time > ?)'
)
if expire_time and tag:
default = (default, None, None)
elif expire_time or tag:
default = (default, None)
if not self.statistics and update_column is None:
# Fast path, no transaction necessary.
rows = self._sql(select, (db_key, raw, time.time())).fetchall()
想要有可以查询所有key的方法
原本的方法
from zdppy_cache import Cache
cache = Cache()
for key in [4, 1, 3, 0, 2]:
cache[key] = key
print(list(cache.iterkeys()))
封装方法
def get_all_keys():
"""
获取所有的key
:return:
"""
with Cache(cache_directory) as cache:
return list(cache.iterkeys())
测试封装的方法
import zdppy_cache as c
import time
# 设置缓存
key = "code"
value = "A13k"
c.set(key, value, 3)
# 获取所有的缓存的key
print(c.get_all_keys())
time.sleep(3)
print("过期后:", c.get_all_keys())
# 清空缓存
c.delete_all()
查询所有有效的key
底层的方法
def iterkeys(self, reverse=False):
"""Iterate Cache keys in database sort order.
>>> cache = Cache()
>>> for key in [4, 1, 3, 0, 2]:
... cache[key] = key
>>> list(cache.iterkeys())
[0, 1, 2, 3, 4]
>>> list(cache.iterkeys(reverse=True))
[4, 3, 2, 1, 0]
:param bool reverse: reverse sort order (default False)
:return: iterator of Cache keys
"""
sql = self._sql
limit = 100
_disk_get = self._disk.get
if reverse:
select = (
'SELECT key, raw FROM Cache'
' ORDER BY key DESC, raw DESC LIMIT 1'
)
iterate = (
'SELECT key, raw FROM Cache'
' WHERE key = ? AND raw < ? OR key < ?'
' ORDER BY key DESC, raw DESC LIMIT ?'
)
else:
select = (
'SELECT key, raw FROM Cache'
' ORDER BY key ASC, raw ASC LIMIT 1'
)
iterate = (
'SELECT key, raw FROM Cache'
' WHERE key = ? AND raw > ? OR key > ?'
' ORDER BY key ASC, raw ASC LIMIT ?'
)
row = sql(select).fetchall()
if row:
((key, raw),) = row
else:
return
yield _disk_get(key, raw)
while True:
rows = sql(iterate, (key, raw, key, limit)).fetchall()
if not rows:
break
for key, raw in rows:
yield _disk_get(key, raw)
缓存表的结构

封装的方法1
def get_all_keys(self, is_active=False, limit=100000):
"""
遍历数据库中所有的key,默认查询所有没过期的
:param is_active: 是否只查没过期的
:param limit: 默认10000,但是允许做限制
:return: 遍历到的所有的key,没有返回空列表
"""
sql = self._sql
_disk_get = self._disk.get
rows = None
if is_active:
# 查没过期的
select = 'SELECT key FROM Cache where expire_time < ? LIMIT ?'
rows = sql(select, (time.time(), limit)).fetchall()
else:
# 查所有的
select = 'SELECT key FROM Cache LIMIT ?'
rows = sql(select, (limit,)).fetchall()
# 返回,这里rows不可能为None,所以可以这么写
return [v[0] for v in rows]
测试方法1
from zdppy_cache import Cache
cache = Cache("tmp/a")
for key in [4, 1, 3, 0, 2]:
cache[key] = key
print(cache.get_all_keys())
封装的方法2
def get_all_keys(is_active=True):
"""
获取所有的key
:return:
"""
with Cache(cache_directory) as cache:
return cache.get_all_keys(is_active=is_active)
测试方法2
import zdppy_cache as c
import time
# 设置缓存
key = "code"
value = "A13k"
c.set(key, value, 3)
# 获取所有的缓存的key
print(c.get_all_keys())
time.sleep(3)
print("默认查询未过期的:", c.get_all_keys())
print("查询过期的:", c.get_all_keys(False))
# 清空缓存
c.delete_all()
查询所有的键值对
import zdppy_cache as c
import time
# 设置缓存
key = "code"
value = "A13k"
c.set(key, value, 3)
# 获取所有的缓存的key-value
print(c.get_all_items())
time.sleep(3)
print("默认查询未过期的:", c.get_all_items())
print("查询过期的:", c.get_all_items(False))
# 清空缓存
c.delete_all()
其他想法
- 1、封装API
- 2、有账号密码
- 3、想要有可以查询所有key的方法 搞定
- 4、查所有key value的方法,字典格式 搞定
- 5、查询所有有效的key 搞定
- 6、查所有有效的key value 搞定
- 7、查询所有有效的具体数据,也就是缓存的所有字段