目录
- 1-引言:初始缓存穿透
- 1-1 缓存穿透是什么?(What)
- 1-2 缓存穿透是怎么造成的?(Why)
- 2- 核心:如何避免缓存穿透(How)
- 2-1 方案1:缓存空数据
- 2-2 方案2:布隆过滤器
- 2-2-1 布隆过滤器原理
- 2-2-2 布隆过滤器误判
- 2-3 方案3:限流策略
- 3- 小结
- 3-1 Redis的使用场景有哪些?
- 3-2 什么是缓存穿透怎么解决?
- 3-3 布隆过滤器的原理?
1-引言:初始缓存穿透
1-1 缓存穿透是什么?(What)
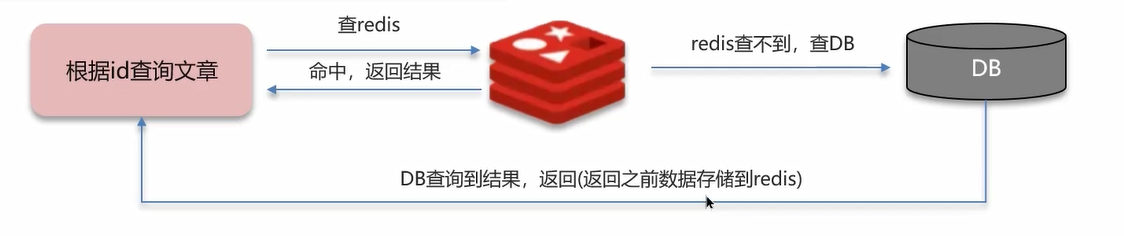
举个例子,比如对于一个文章接口,其有一个缓存场景
- 对于 get 请求 :
api/news/getById/1 - 正常使用缓存的流程:会先查 Redis ——> 若 Redis 中没有,则会去查 MySQL ——> MySQL的结果返回前将数据存储到 Redis
缓存穿透
- 查询一个 不存在 的数据,MySQL 查询不到数据也不会直接写入缓存,就会导致每次请求都查数据库
1-2 缓存穿透是怎么造成的?(Why)
- 如果有坏人,恶意调用接口,查询 Redis 以及 MySQL 中都不存在的数据,会导致很大访问量的请求打到 MySQL 上,如果并发过大会导致击垮 MySQL 。
2- 核心:如何避免缓存穿透(How)
2-1 方案1:缓存空数据
- 对于上述例子,如果查询的文章不在 MySQL 中,此时就写入一个 空的 key value 到 Redis 中
- 例如:
{ key:1 , value:null }
优缺点:
- 优点:简单
- 缺点:消耗内存,可能会发生不一致的问题(比如一开始不存在
id为1的文章,之后添加了文章,但缓存中还是有id为1,value为null的数据,会导致 Redis 和 MySQL 不一致)
2-2 方案2:布隆过滤器
2-2-1 布隆过滤器原理
- 布隆过滤器实现:布隆过滤器是用来判断是否存在当前请求 id 的文章数据。
- 如果布隆过滤器中不存在该数据,则直接返回,此时都无需访问 Redis。
- 如果布隆过滤器中存在该数据,则去 Redis 中访问
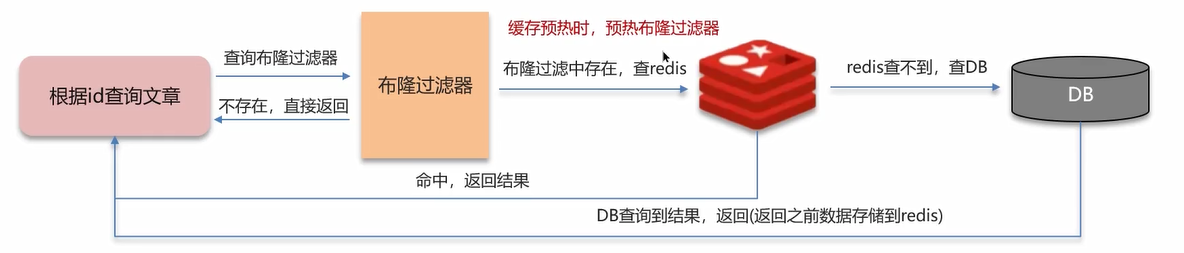
概述:布隆过滤器的实现原理实际上是和 bit(位图) 和 哈希函数有关。
- bitmap(位图):相当于是一个以 (
bit) 位 为单位的数组,数组找那个每个单元只能存储二进制数据0或1 - 布隆过滤器的作用:布隆过滤器可以用于检索一个元素是否在一个集合中
举例说明工作原理
- ① 存储数据: 一开始位图中所有位置上的数据都初始化为
0。比如此时要存储一个id为1的数据,通过多个 hash 函数获得 hash 值,根据 hash 计算的数组对应的位置值 改为1 - **② 查询数据:**使用相同 hash 函数获取 hash 值,判断对应位置是否都为
1。如果都为1证明该数据存在,但有可能存在误判场景。
2-2-2 布隆过滤器误判
场景
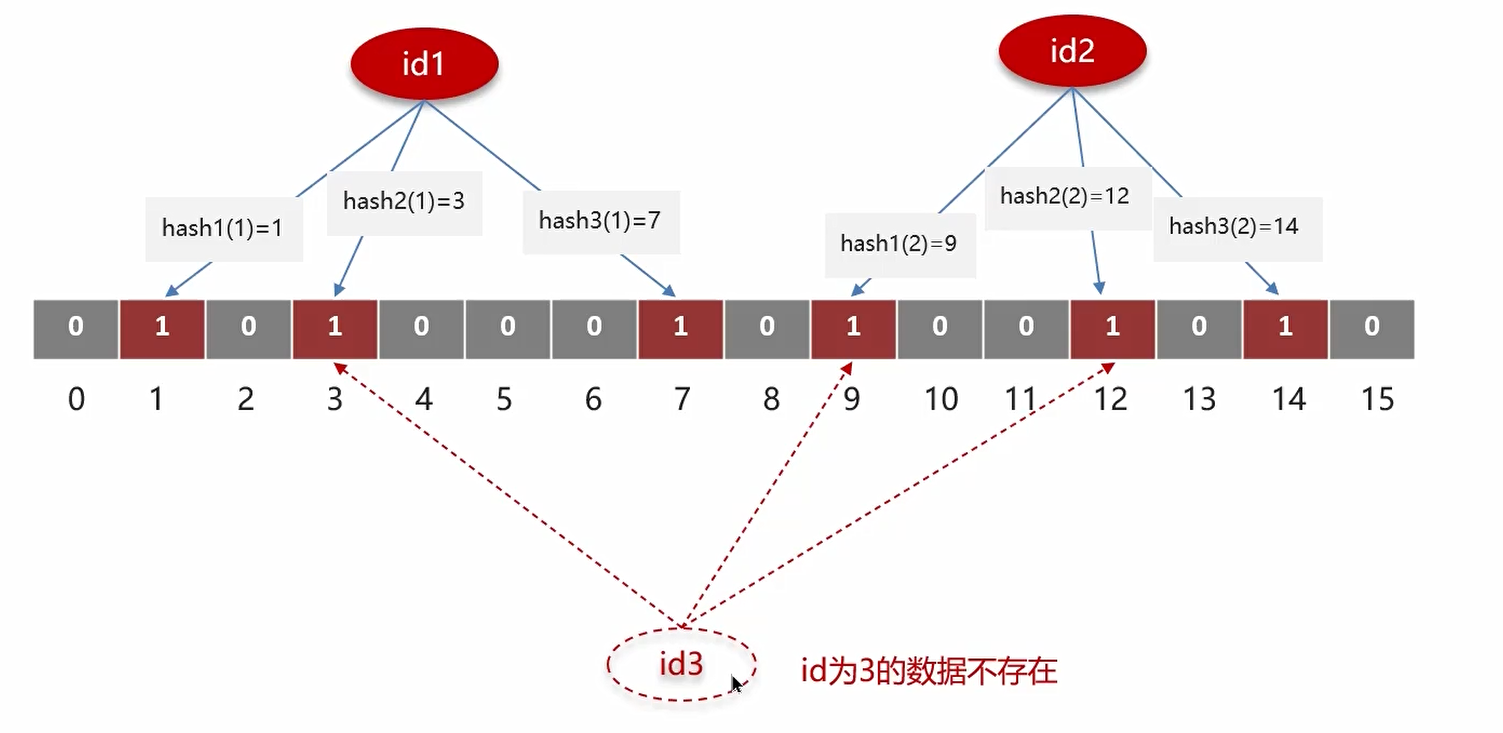
- 比如对于
id为1和id为2的数据,通过哈希更新了 bitmap 上的值 - 此时来了
id为3的数据,此时 ,会发现与之前id1和id2的 bitmap 上的值刚好重叠了,判断 id3 的数据在 Redis 中
- 误判率:数组越小误判率就越大,数组越大误判率就越小,但是同时带来了更多内存的消耗。(其实
5%是可以接受的,因为无论如何都存在误判的,所以5%的误判在高并发的情境下不会出现压垮数据库的情况)。 - 具体误判率的优化,可以根据布隆过滤器的实现方案来
优缺点:
- 优点:内存占用计较少,没有多余的key
- 缺点:实现复杂,存在误判
2-3 方案3:限流策略
- 限流策略:针对频繁请求的特定数据,可以设置限流策略,例如使用令牌桶算法或漏桶算法,限制对这些数据的请求频率,减轻数据库的压力。
3- 小结
3-1 Redis的使用场景有哪些?

3-2 什么是缓存穿透怎么解决?

3-3 布隆过滤器的原理?