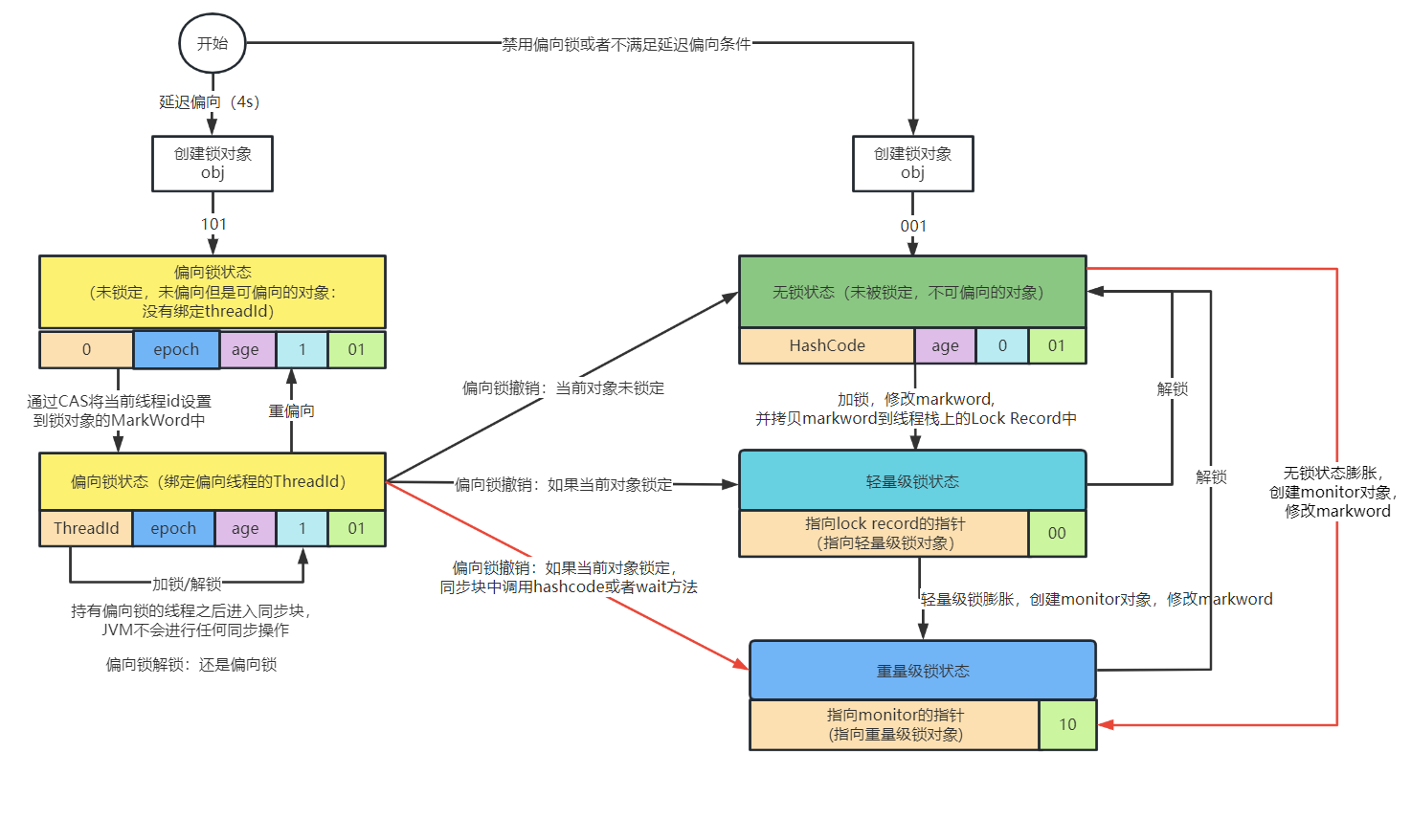
学习路线:感性认识现象->理解本质和原理->将所学知识用于解释新现象并指导实践。

LLM训练模型的的三个阶段:
1、Pre-train
2、Supervised Fine-Tuning:Instruction Fine-tuning
3、RLHF - > RLAIF:增强式学习 --ppo方法

LLM主要类别架构
Transformer -> Google提出
Google研究Encoder模块进行各自任务,Bert
OpenAI不走寻常路,研究Decoder,GPT - ChatGpt
GPT的训练目标是做词语接龙,其在预训练阶段的目标很简单:根据上文序列预测下一个词(token)。
BERT的训练目标是做完形填空。BERT在预训练阶段使用了两个任务:遮挡语言模型(MLM)和下一句预测(NSP)。MLM任务通过在输入文本中随机遮挡一些词汇,将遮挡的词汇重置为[MASK],并预测[MASK],帮助模型学会理解双向上下文。NSP任务则让模型学会判断两个句子是否是连续的。
AE模型:自编码模型
代表模型BERT:
- AE模型,代表作BERT,其特点为:Encoder-Only。
- 基本原理:是在输入中随机MASK掉一部分单词,根据上下文预测这个词。
- AE模型通常用于内容理解任务,比如自然语言理解(NLU)中的分类任务:情感分析、提取式问答。
BERT是2018年10月由Google AI研究院提出的一种预训练模型
BERT的预训练任务:
- Masked LM(带mask的语言模型训练)
在原始训练文本中,随机的抽取15%的token作为参与MASK任务的对象.
80%的概率下,用[MASK]标记替换该token.
在10%的概率下,用一个随机的单词替换token,
在10%的概率下,保持该token不变, - Next Sentence Prediction(下一句话预测任务)
输入句子对(A,B),模型来预测句子B是不是句子A的真实的下一句话
所有参与任务训练的语句都被选中作为句子A.。其中50%的B是原始文本中真实跟随A的下一句话.(标记为IsNext,代表正样本).
其中50%的B是原始文本中随机抽取的一句话,(标记为NotNext,代表负样本)
优点:使用双向transformer,在语言理解相关任务中表现很好。
缺点:输入噪声,预训练-微调存在差异。更适合NLU(自然语言理解)任务,不适合NLG(自然语言生成)任务。

AR:自回归模型
代表模型GPT:
- AR模型,代表作GPT,其特点为:Decoder-Only。
- 基本原理:从左往右学习的模型,只能利用上文或者下文的信息。
- AR模型通常用于生成式任务,在长文本的生成能力很强,比如自然语言生成(NLG)领域的任务:摘要、翻译或抽象问答。
GPT训练过程
GPT的训练包括两阶段过程:
- 无监督的预训练语言模型;
- 有监督的下游任务fine-tunning。

优点:更易于并行化
缺点:单向的,针对不同任务,都需要采用不用数据集进行微调
AR模型总结:
优点:AR模型擅长生成式任务、生成数据较容易。
缺点:不能完全捕捉token的内在联系。
序列到序列模型
代表模型T5
encoder-decoder模型同时使用编码器和解码器,它将每个task视作序列到序列的转换/生成(比如,文本到文本,文本到图像或者图像到文本的多模态任务).Encoder-decoder模型通常用于需要内容理解和生成的任务,比如机器翻译。
T5 由谷歌提出,该模型的目的为构建任务统一框架:将所有NLP任务都视为文本转换任务.
T5模型架构与训练过程
T5模型结构与原始的Transformer基本一致,除了做了以下几点改动:
采用了一种简化版的Layer Normalization,去除了Layer Norm 的bias;将Layer Norm放在残差连接外面.
位置编码:T5使用了一种简化版的相对位置编码,即每个位置编码都是一个标量,被加到 logits 上用于计算注意力权重。各层共享位置编码,但是在同一层内,不同的注意力头的位置编码都是独立学习的.
encoder-decoder模型总结
优点:处理多种NLP任务,具有良好的可扩展性;相比GPT-2、GPT3等模型,T5参数量相对较少,训练速度更快.
缺点:训练时间较长、需要更大的算力。模型的可解释性不足.
LLM主流大模型类别
ChatGLM-6B
- ChatGLM-6B 是清华大学提出的一个开源、支持中英双语的对话语言模型,基于 General Language Model(GLM)架构,具有62 亿参数。
- 该模型使用了和 ChatGPT 相似的技术,经过约 1T 标识符的中英双语训练(中英文比例为 1:1),辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答(目前中文支持最好)。

BERT–MLM随机的对一个token进行mask
LLaMA
LLaMA模型简介与训练目标:
- LLaMA(Large Language Model Meta Al),由 Meta Al 于2023年发布的一个开放且高效的大型基础语言模型,共有7B、13B、33B、65B(650 亿)四种版本。
- LLaMA训练数据是以英语为主的拉丁语系,另外还包含了来自 GitHub 的代码数据。训练数据以英文为主,不包含中韩目文,所有训练数据都是开源的。其中LLaMA-65B和 LLaMA-33B 是在 1.4万亿(1.4T)个 token上训练的,而最小的模型 LLaMA-78 和LLaMA-13B 是在 1万亿(1T)个 token 上训练的.
LaMA 的训练目标是语言模型,即根据已有的上文去预测下一个词。
关于tokenizer,LLaMA 的训练语料以英文为主,使用了BPE 作为 tokenizer,词表大小只有 32000.词表里的中文 token 很少,只有几百个,LLaMA tokenizer 对中文分词的编码效率比较低。
BLOOM
BLOOM模型简介与训练目标:
- BLOOM系列模型是由 Hugging Face公司训练的大语言模型,训练数据包含了英语、中文、法语、西班牙语、葡萄牙语等共 46 种语言,另外还包含 13 种编程语言.1.5TB 经过去重和清洗的文本,其中中文语料占比为 16.2%。
- 按照模型参数量,BLOOM 模型有 560M、1.1B、1.7B、3B、7.18 和 176B 这几个不同参数规模的模型。
BLOOM 的训练目标是语言模型,即根据已有的上文去预测下一个词。
关于tokenizer,BLOOM 在多语种语料上使用 Bvte Pair Encoding(BPE)算法进行训练得到 tokenizer,词表大小为250880。
Baichuan-7B
Baichuan-7B由百川智能于2023年6月发布的一个开放且可商用的大型预训练语言模型,其支持中英双语。是在约 1.2万亿(1.2T)个 token上训练的70亿参数模型。
Baichuan-78 的训练目标也是语言模型,即根据已有的上文去预测下一个词。
关于tokenizer,使用了BPE分词算法作为 tokenizer,词表大小64000。
关于数据,原始数据包括开源的中英文数据和自行抓取的中文互联网数据,以及部分高质量知识性数据。
Prompt Tuning
GPT-3 开创性的提出In-context Learning的思想,即无须修改模型即可实现few-shot、zero-shot的learning。
1、Prompt-Oriented Fine-Tuning
本质是将目标任务转换为适应预训练模型的预训练任务,以适应预训练模型的学习体系。
这个方法种,预训练模型参数是可变的,本质是Prompt-Tuning + Fine-Tuning的结合体。该方法在Bert类相对较小的模型上表现较好,但是随着模型越来越大,如果每次针对下游任务,都需要更新预训练模型的参数,资源成本及时间成本都会很高,因此后续陆续提出了不更新预训练模型参数,单纯只针对prompt进行调优的方法。
针对Prompt调优方法的分类:Hard Prompt 和Soft Prompt
Hard Prompt:
离散提示: 是一种固定的提示模板,通过将特定的关键词或短语(真实的文本字符串)直接嵌入到文本中,引导模型生成符合要求的文本。
特点: 提示模板是固定的,不能根据不同的任务和需求进行调整。
缺陷:依赖人工,改变prompt中的单个单词会给实验结果带来巨大的差异。
Soft Prompt:
连续提示:是指通过给模型输入一个可参数化的提示模板,从而引导模型生成符合特定要求的文本。
特点: 提示模板中的参数可以根据具体任务和需求进行调整,以达到最佳的生成效果。
优点:不需要显式地指定这些模板中各个token具体是什么,而只需要在语义空间中表示一个向量即可。
-
基于Soft Prompt,不同的任务、数据可以自适应地在语义空间中寻找若干合适的向量,来代表模板中的每一个词,相较于显式的token,这类token称为 伪标记(Pseudo Token).下面给出基于连续提示的模板定义:
-
假设针对分类任务,给定一个输入句子x,连续提示的模板可以定义为T=[x],[v1],[v2]…,[VnJ[MASK]:其中[vn]则是伪标记,其仅代表一个抽象的token,并没有实际的含义,本质上是一个向量。
总结来说:Soft Prompt方法,是将模板变为可训练的参数,不同的样本可以在连续的向量空间中寻找合适的伪标记,同时也增加模型的泛化能力.因此,连续法需要引入少量的参数并在训练时进行参数更新,但预训练模型参数是不变的,变的是prompt token对应的词向量(Word Embedding)表征及其他引入的少量参数。
1.1、Prompt Tuning(NLG任务)
谷歌2021年提出的微调方法,基于T5(最大参数11B)为每一个输入文本假设一个固定前缀提示,该提示由神经网络参数化,并在下游任务微调时进行更新,整个过程种预训练的大模型参数被冻结。

清华2022年提出的微调方法,主要是为了解决大模型的Prompt构造方式严重影响下游任务的效果。
提出将Prompt转换为可以学习的Embedding层,只是考虑到直接对Embedding参数化进行优化。
核心思想:P-tuning 固定 LLM 参数,利用多层感知机(MLP)和 LSTM对 Prompt 进行编码,编码之后与其他向量进行拼接之后正常输入LLM。注意,训练之后只保留 Prompt 编码之后的向量即可,无需保留编码器。

与Prompt Tuning的区别:
Prompt Tuning 是将额外的 embedding 加在开头,看起来更像是模仿Instruction 指令;而 P-Tuning 的位置则不固定!
Prompt Tuning 不需要加入 MLP 来参数初始化;而 P-Tuning 通过LSTM+MLP 来初始化。
P-Tuning V2是升级版本,主要解决P-Tuning V1 在小参数量模型上表现差的问题。核心思想:在模型的每一层都应用连续的 prompts,并对 prompts 参数进行更新优化.同时,该方法也是针对NLU任务优化和适配的。
2、超大规模参数模型的Prompt-Tuning方法
针对大规模参数(10亿)的方法:
1、不训练参数:few-shot、 one-shot、zero-shot
2、训练部分参数(固定大模型参数,只微调部分其他参数):P-Tuning、Prefix-Tuning、Lora
3、训练所有参数(资源、算力)
2.1、上下文学习 In-Context Learing
直接挑选少量的训练样本作为该任务的提示。
最早在GPT3中提出,旨在从训练集中挑选少量的标准样本,设计任务相关的指令形成提示模板,用于指导测试样本生成相应的结果。few-shot、 one-shot、zero-shot三种方法
2.2、指令学习 Instruction-Tuning
构建任务指令集,促使模型根据任务指令做出反馈。
做判别任务,比生成更容易;激发语言模型的理解能力。
以电影二分类任务为例:
在对电影评论进行二分类的时候,最简单的提示模板(Prompt)是“.lt was [mask].”,但是其并没有突出该任务的具体特性,我们可以为其设计一个能够突出该任务特性的模板(加上Instruction),例如“The movie review is.lt was [mask].”,然后根据mask位置的输出结果通过Verbalizer映射到具体的标签上。这一类具备任务特性的模板可以称之为指令Instruction.
2.3、思维链 Chain-of-Thought
给予或激发模型具有推理和解释的信息,通过线性链式的模式指导模型生成合理的结果。
谷歌提出,相较于之前的上下文学习,思维链多了中间的推导过程。
特点:逻辑性、全面性、可行性、可验证性
Few-shot CoT:举一个例子,让模型按照例子学习
Zero-shot CoT:prompt加入 Let’s think step by step
3、PEFT大模型参数高效微调方法
目前工业界应用大模型的主流方式:PEFT(Prompt-Tuning的方法)微调部分参数;RAG(知识检索增强–外怪知识库)。
PEFT(Parameter-Efficient Fine-Tuning)参数高效微调方法是目前大模型在工业界应用的主流方式之,PEFT 方法仅微调少量或额外的模型参数,固定大部分预训练参数,大大降低了计算和存储成本,同时最先进的 PEFT 技术也能实现了与全量微调相当的性能。
优势:该方法可以使 PLM 高效适应各种下游应用任务,而无需微调预训练模型的所有参数,且让大模型在消费级硬件上进行全量微调(Full Fine-Tuning)变得可行。
3.1、Prefix/Prompt-Tuning
在模型的输入或隐层添加k个额外可训练的前缀伪tokens,只训练这些前缀参数。
2021年论文《Prefix-Tuning: Optimizing Continuous Prompts for Generation》中提出了 Prefix-Tuning 方法,该方法是在输入 token 之前构造一段任务相关的 virtual tokens 作为 Prefix,然后训练的时候只更新 Prefix 部分的参数,而 Transformer 中的其他部分参数固定。
注意:由于直接更新 Prefix 的参数会导致训练不稳定,作者在 Prefix 层前面加了 MLP 结构(相当于将Prefix分解为更小维度的 Input 与 MLP 的组合后输出的结果)训练完成后,只保留 Prefix 的参数.
对比P-Tuning:
- Prefix-Tuning 是将额外的embedding加在开头,看起来更像模仿Instruction指令,而P-Tuning位置不固定.
- Prefix-Tuning 通过在每个层都添加可训练参数,通过MLP初始化:而P-Tuning只在输入的时候加入embedding,并通过LSTM+MLP初始化。
对比Prompt-Tuning:
Prompt Tuning 方式可以看做是Prefix Tuning 的简化,只在输入层加入 prompt tokens,并不需要加入MLP 进行调整来解决难训练的问题。
3.2、Adapter-Tuning
将较小的神经网络层或模块插入预训练模型的每一层,下游任务微调也只训练这些适配器参数。
2019年谷歌的研究人员首次在论文《Parameter-Efficient Transfer Learning for NLP》提出针对BERT 的 PEFT微调方式,拉开了 PEFT 研究的序幕。
不同于Prefix Tuning这类在输入前添加可训练 prompt参数,以少量参数适配下游任务,Adapter Tuning则是在预训练模型内部的网络层之间添加新的网络层或模块来适配下游任务。当模型训练时,固定佳原来预训练模型的参数不变,只对新增的 Adapter 结构进行微调。
Adapter:全连接层构成,先降维 在升维;同时搭配残差链接
3.3、LoRA
通过学习小参数的低秩矩阵来近似模型权重矩阵 W 的参数更新,训练时只优化低秩矩阵参数。
低秩适应(Low-Rank Adaptation)是一种参数高效的微调技术,其核心思想是对大型模型的权重矩阵进行隐式的低秩转换,也就是:通过一个较低维度的表示来近似表示一个高维矩阵或数据集.
LORA的产生:
上述Adapter Tuning 方法在 PLM 基础上添加适配器层云引入额外的计算,带来推理延迟问题;而 PrefixTuning 方法难以优化,其性能随可训练参数规模非单调变化,更根本的是,为前缀保留部分序列长度必然会减少用于处理下游任务的序列长度。因此微软推出了LORA方法。
具体架构图如下所示:

LoRA技术冻结预训练模型的权重,并在每个Transformer块中注入可训练层(称为秩分解矩阵),即在模型的多头注意力层的旁边增加一个“旁支”A和B。其中,A将数据从d维降到r维,这个r是LORA的秩,是一个重要的超参数;B将数据从r维升到d维,B部分的参数初始为0。模型训练结束后,需要将A+B部分的参数与原大模型的参数合并在一起使用。
LoRA伪代码实现:
input_dim = 768 #例如,预训练模型的隐藏大小
output_dim = 768#例如,层的输出大小
rank = 8 #低秩适应的等级'r'
W = .. #来自预训练网络的权重,形状为input_dim 乘 output_dim
W_A = nn.Parameter(torch.empty(input_dim, rank))# LORA权重A
W_B = nn.Parameter(torch.empty(rank, output_dim))# LORA权重F
nn.init.kaiming_uniform_(W_A, a=math.sqrt(5))
nn.init.zeros_(W_B)
#原始的
def regular_forward_matmul(x, W):
h = x @ W
return h
#加入LoRA之后的
def lora _forward_matmul(x, W, W_A, W_B):
h = x @ W#常规矩阵乘法
h += x @ (W_A @ W B)*alpha #使用缩放的LORA权重,alpha缩放因子
return h