文本匹配任务
- 1.文本匹配介绍
- 1.1文本匹配定义
- 1.1.1狭义定义
- 1.1.2广义定义
- 1.2文本匹配应用
- 1.2.1问答对话
- 1.2.1信息检索
- 2.文本匹配--智能问答
- 2.1基本思路
- 2.2技术路线分类
- 2.2.1按基础资源划分
- 2.2.2 答案生成方式
- 2.2.3 NLP技术
- 2.3智能问答-Faq知识库问答
- 2.3.1运行逻辑
- 2.3.2核心关键点-相似度
- 1.文本匹配算法
- 1.1编辑距离
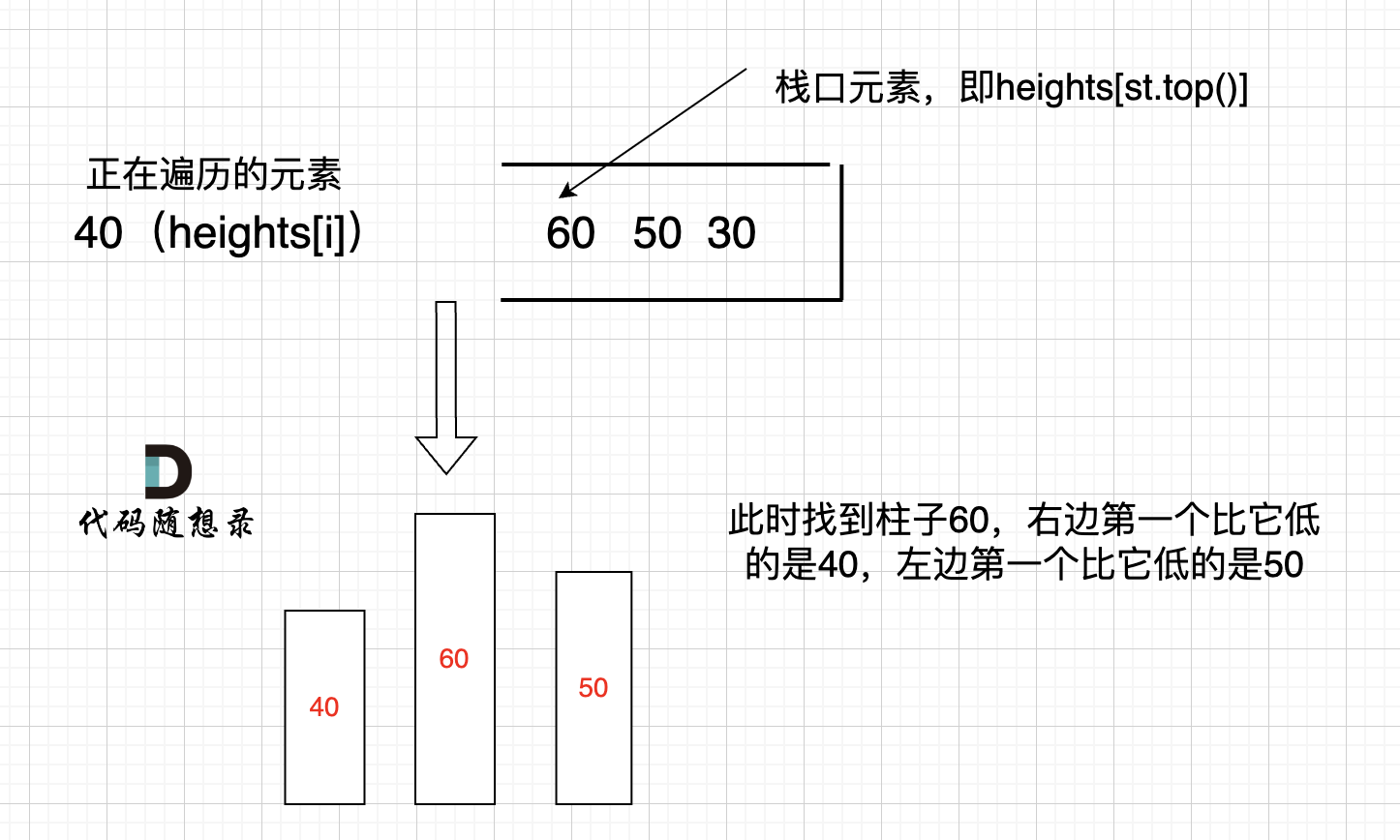
- 1.1.1算法实现截图
- 1.1.2优缺点
- Jaccard
- 优缺点
- BM25算法
- 优缺点
- word2vec
- 词向量相似度计算
- 优缺点
1.文本匹配介绍
1.1文本匹配定义
1.1.1狭义定义
释义: 给定一组文本,判断其是否语义相似
示例:
1.判断语义是否相似
今天天气不错 match 今儿个天不错呀 √
今天天气不错 match 你今天吃饭了吗 ×
1.判断语义的相似度
今天天气不错 match 今儿个天不错呀 0.9
今天天气不错 match 这几天天气不错 0.75
今天天气不错 match 你今天吃饭了吗 0.1
1.1.2广义定义
释义: 给定一组文本,计算某种自定义的关联度;也就是说多段文本,想计算他们之间的关系,我们都可用文本匹配任务解决。
-
Natural Language Inference
两句话判断是否有关联、矛盾、中立。
明天要下雨 vs 明天大晴天。 -
Text Entailment
给出一段文本,和一个假设,判断文本是否能支持或反驳这个假设。
他是男的。假设:她身份证性别为女。 -
主题判断
文章标题匹配内容等
1.2文本匹配应用
释义: 从文本的长度来讲,可以简单的概括为下面几类:
-
短文本 vs 短文本
知识库问答 ,聊天机器人等 -
短文本 vs 长文本
文章检索,广告推荐等 -
长文本 vs 长文本
新闻、文章的关联推荐等
1.2.1问答对话
- 车载导航
- 手机助手
- 聊天机器人
- 智能音箱
- 智能客服
1.2.1信息检索
- 搜索引擎
- 微信、头条的相关文章推荐
2.文本匹配–智能问答
2.1基本思路
- 准备基础资源
包括faq库,书籍文档,网页,知识图谱等等 - 构建问答系统
对基础资源进行了加工处理,形成问答所需要索引和模型等 - 用户输入问题
- 问答系统给出答案

2.2技术路线分类
2.2.1按基础资源划分
1)基于faq知识库的问答(Frequently asked Questions )
2)基于文档/网页/书籍的问答
引申:当前基于生成式模型的RAG技术,当然并不完全是文本匹配了
3)基于图像/视频的问答
引申:当前生成式多模态大模型,是基于多模态技术
4)基于知识图谱的问答
5)基于表格的问答
4、5有点类似,都是基于结构化内容进行匹配问答
6)基于特定领域知识的问答
7)基于人工规则的问答
2.2.2 答案生成方式
-
检索式的问答
答案原文或答案的多个片段,存在于基础资源中
faq就是典型的这类 -
生成式的问答
答案文本不存在于基础资源,由问答系统来生成答案
RAG等 -
二者结合
2.2.3 NLP技术
依照NLP相关技术划分
1)单轮问答
2)多轮问答
3)多语种问答
4)事实性问答
5)开放性问答
6)多模态问答
7)选择型问答
8)抽取式问答
9)生成式问答
2.3智能问答-Faq知识库问答
目标: 让用户以自然语言描述自己的问题,算法进行faq库的检索,给出对应的答案。
常见概念定义:
- 问答对
一个(或多个相似的)问题与它对应的答案- faq库/知识库
很多问答对组成的集合- 标准问
每组问答对中的问题,有多个时,为其中代表- 相似问/扩展问
问答对中,标准问之外的其他问题。即相同的答案对应着不同的提问方式。- 用户问
用户输入的问题- 知识加工
人工编辑faq库的过程;比如:添加相似问、新的问答对等
2.3.1运行逻辑
步骤如下:
1.对用户问进行预处理
2.使用处理后的问题,与faq库中问题计算相似度
3.按照相似度分值排序
4.返回最相似问题对应的答案
示例如下图

注意: 预处理包括:分词,去停用词,去标点、大小写转换,全半角转换、词性标注,句法分析等等
2.3.2核心关键点-相似度
理解: 语义相似度计算是faq问答的核心,一般简称文本匹配f(x, y)→Score;相似度分值合理,才可以找到正确的对应问题,计算分值的同时,也要考虑速度。
引申:
- 排序之前可能有召回模块,为了减少排序的耗时。
- 如果最高相似度的问题,分值依然很低,一般会有兜底答案,不会强行回答。
注意:
- 如果相似度算法足够强,对知识加工的依赖就越低,算法越弱,对知识的加工要求就越高,这样才能准确匹配到知识。
- 上面说的是用户的问题,和知识库中的问题进行相似度匹配。有可以
通过用户问题和知识库答案相匹配,跳过问题匹配这一步,根据具体的材料和实现技术来确定。因为实际情况中,答案不一定是统一的形态,可能是图片、链接、视频等。匹配问题是为了更好的拓展,即不管什么模态的答案,我都能快速调整标准问、拓展问即可。
1.文本匹配算法
1.1编辑距离
释义: 两个字符串之间,由一个转成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
举例:

计算编辑距离公式:

结论:
- 两个字符串完全一致,编辑距离 = 0,相似度 = 1
- 两个字符串完全不一致,编辑距离 = 较长者长度,相似度 = 0
1.1.1算法实现截图
实现采用动态规划思想:

1.1.2优缺点
优点:
- 可解释性强
- 跨语种(甚至对于非语言序列)有效
- 不需要训练模型
缺点:
- 字符之间没有语义相似度:我也一样。俺也一样。
- 受无关词/停用词影响大:我要办卡。我想办一张卡。
- 受语序影响大:今天天气不错;天气不错今天。
- 文本长度对速度影响很大。
Jaccard
原理: 根据两个集合中,不同元素所占的比例,来衡量两个样本之间的相似度。即:根据两个文本中,不同的字或词所占的比例,来衡量两个文本之间的相似度。
计算方式如下:

举例:
- 今天天气真不错
- 估计明天天气更好
公共字数: 天、气
总字数:今,天,气,真,不,错,估,计,明,更,好
jaccard相似度: 2 / 11 = 0.18
当然,除了通过字来计算,还可以通过词来计算。
用词和用字,要具体场景,具体分析,测试后决定;名词、缩略词、文本长度都会影响
优缺点
优点:
- 语序不影响分数(词袋模型)
示例:
今天天气不错
天气不错今天 - 实现简单,速度很快
- 可跨语种,无需训练等
缺点:
- 语序不影响分数
示例:
他打了我
我打了他 - 字词之间没有相似度衡量
- 受无关词影响
- 非一致文本可能出现满分
示例:
他是不知道
他不是不知道
适用场景: jaccard更适合-长文本;长文本中能够降低语序对分数的影响、以及非一致性文本的满分问题。
BM25算法
应用: 在搜索引擎框架中,用来做文档和搜索问题的匹配。在问答中,做文本匹配。
核心思想: 假如一个词在某类文本(假设为A类)中出现次数很多,而在其他类别文本(非A类)出现很少,那么这个词是A类文本的重要词(高权重词)。反之,如果一个词在出现在很多领域,则其对于任意类别的重要性都很差。
举例: 恒星 --> 天文; 你好 --> 在大多数文本中都有,但都不是关键词
本质: BM25是对TF·IDF的一种改进,优化其表示效果。TF·IDF存在的问题:统计的TF·IDF值与文本的长度有关。而BM25通过求平均的方式,改进了这个问题,降低了文本长度对统计值的影响。
公式如下:

释义:
这个算法的具体计算方式,不做详细介绍。
qi 为问题中某词,fi为词频; k1, k2, b为可调节常数;dl为文档长度;avgdl为所有文档平均长度
这些参数和改动的意义在于控制文本长度对分值的影响
优缺点
优点:
1.通过使用TF·IDF弱化了无关词的影响,强化了重要词的影响,使得效果大幅提升
2.统计模型计算快,不需要迭代
3.词袋模型*、跨语种等
缺点:
1.依然没有考虑词与词之间的相似性
2.需要一定量的训练(统计)样本(faq库本身)
3.对于新增类别,需要重新计算统计模型
4.分值未归一化
word2vec
原理: 将每个词或字转换成同一向量空间内的一个向量;两个词如果语义相近,则在空间中的向量接近。
训练词向量:
1.基于窗口
2.基于语言模型
3.基于共现矩阵
优化要点:
1.层次softmax/Huffman树
2.负采样
词向量相似度计算
计算相似度:
1.将文本中的所有词的词向量相加取平均
2.文本 -> 句向量
3.SentenceVector = ∑(1-𝑛)𝑊𝑖 / n
4.句向量维度 = 词向量维度,不论文本长度
5.文本相似度 = 向量相似度 = 向量夹角余弦值
6.向量夹角为0,余弦值为1
计算公式:

工程优化:
如何加快相似度计算?
1.由公式出发,可以先将词向量的模求解出来
2.计算内积,可以通过将词向量矩阵转置;所有的词向量,原来是一排一个,现在变成一列一个;通过矩阵运算,就可以一次算出每一个列的相似度。因为矩阵相乘,是前一个矩阵的行乘后一个矩阵的列;输入只有一行。
上面就是工程上可以加快优化点。
优缺点
优点:
1.两个文本包含语义相似的词,会提高相似度
2.训练需要的数据简单(纯文本语料即可)
3.计算速度快,可以对知识库内问题预先计算向量
4.将文本转化为数字,使后续复杂模型成为可能
缺点:
1.词向量的效果决定句向量效果(语料数量、领域适配、分词结果、未登录词都会影响)
2.一词多意的情况难以处理。梨–苹果–华为。
3.受停用词和文本长度影响很大(是词袋模型)。
4.更换语种,甚至更换领域,都需要重新训练。







![三角形最小路径和[中等]](https://i-blog.csdnimg.cn/direct/265e8feb2249434e89b6fdcb3578d30f.png)