注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】
文章目录
- 自然语言处理系列三十三
- 同义词词林算法原理
- 代码实战
- 总结
自然语言处理系列三十三
同义词词林算法原理
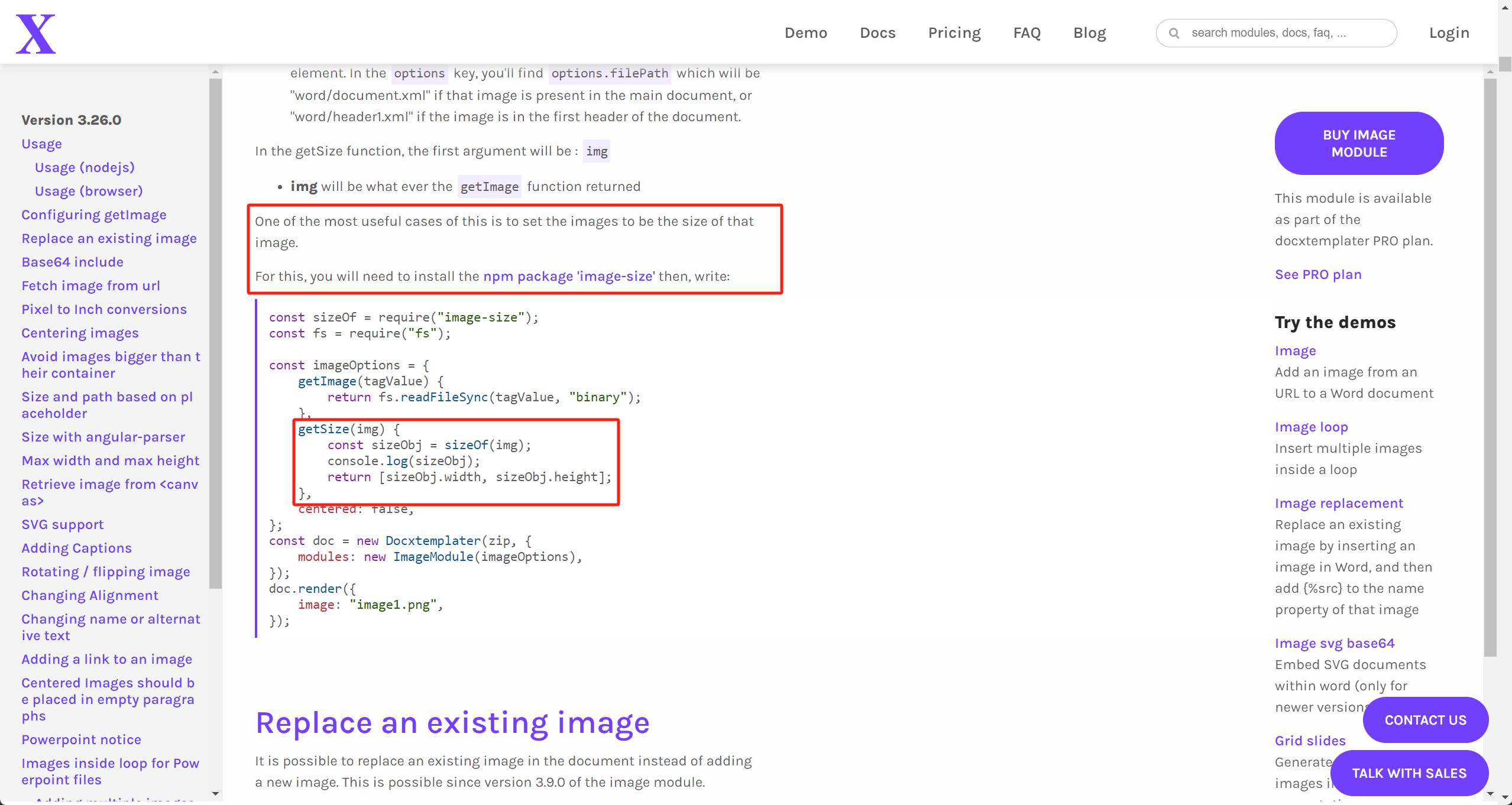
同义词词林主要用来衡量词和词之间的语义相似度,是人工整理的一个词典。《同义词词林》(亦称《义类词典》,以下简称《词林》)是由梅家驹等学者编纂的一部对汉语词汇按语义全面分类的词典,收录词语近7万条。《词林》根据汉语的特点和使用原则,确定了词的语义分类原:以词义为主,兼顾词类,并充分注意题材的集中。它将词义分为大类、中类、小类三级,共分12个大类(A类为人,B类为物,C类为时间与空间,D类为抽象事物,E类为特征,F类为动作,G类为心理活动,H类为活动,I类为现象与状态,J类为关联,K类为助语,L类为敬语),94个中类,1 428个小类,小类下再以同义词原则划分词群,每个词群以一标题词立目,共3 925个标题词。《词林》语义结构可用树型结构来表示,如图8.1所示。

图8.1 《词林》语义空间
编纂《词林》的初衷是提供从词义查词的工具,以便从中挑选适当的词语。作为一个语义分类体系,它也存在一些局限,如词典收词数量有限、复合词收录很少、词典更新滞后等等。若直接采用它作为同义词词典,显然不能满足实际需要。本书进行同义词的挖掘,是利用《词林》语义体系,并且将《词林》作为同义词底表来实现的。这样不仅可以依据《词林》作为底表的功能,直接识别出大量的、以词素形式出现的同义词,还可以依据其作为语义体系的功能,挖掘出大量的复合词形式的同义词。
同义词词林扩展版的词典比较大,这里给大家截取前面一部分展示:
Aa01A01= 人 士 人物 人士 人氏 人选
Aa01A02= 人类 生人 全人类 新人
Aa01A03= 人手 人员 人口 人丁 口 食指 生齿 职员
Aa01A04= 劳力 劳动力 工作者 血汗
Aa01A05= 匹夫 个人 个体 局部 片面 私人 一面 个别 小我 小我私家 部分 一边 一壁 私家 单方
Aa01A06= 家伙 东西 货色 厮 崽子 兔崽子 狗崽子 小子 杂种 畜生 混蛋 王八蛋 竖子 鼠辈 小崽子 用具 器材 器械 对象 牲畜 货品 货物 物品 忘八 工具 牲口 器具 方向 目标 宗旨
Aa01A07= 者 手 匠 客 主 子 家 夫 翁 汉 员 分子 鬼 货 棍 徒 份子
Aa01A08= 每人 各人 每位 大家 人人 众人 大众
Aa01A09= 该人 此人 这人
Aa01B01= 人民 民 国民 公民 平民 黎民 庶 庶民 老百姓 苍生 生灵 生人 布衣 白丁 赤子 氓 群氓 黔首 黎民百姓 庶人 百姓 全民 全员 萌 黔黎 子民 匹夫 平易近 新人 选民
Aa01B02= 群众 大众 公众 民众 万众 众生 千夫 公家 全体 大家 人人 众人 专家 公共 大伙 团体 人民 集体 全数 所有 大师 全部 一概 悉数 满堂 一切 黎民 整体 合座 完全 十足 全豹 百姓 美满 总共 举座 理想 齐备 扫数 世人 内行 统统 通盘 公民 全面 具体 一共 整个 全盘 行家 各人 国民
Aa01B03# 良民 顺民
Aa01B04# 遗民 贱民 流民 游民 顽民 刁民 愚民 不法分子 孑遗 余存 难民 灾民
Aa01C01= 众人 人人 人们 专家 世人 大家 大师 行家 大众 各人 内行
Aa01C02= 人丛 人群 人海 人流 人潮
Aa01C03= 大家 大伙儿 大家伙儿 大伙 一班人 众家 各户 人人 大师 专家 行家 众人 民众 大众 各人 群众 公共 老手 内行 世人 巨匠 熟稔
Aa01C04= 们 辈 曹 等
Aa01C05@ 众学生
Aa01C06# 妇孺 父老兄弟 男女老少 男女老幼
Aa01C07# 党群 干群 军民 工农兵 劳资 主仆 宾主 僧俗 师徒 师生 师生员工 教职员工 群体 爱国志士 党外人士 民主人士 爱国人士 政群 党政群 非党人士 业内人士 工农分子 军警民 党政军民
Aa01D01@ 角色
Aa02A01= 我 咱 俺 余 吾 予 侬 咱家 本人 身 个人 人家 斯人 个体 局部 片面 私人 一面 个别 小我 小我私家 部分 一边 一壁 私家 单方
Aa02A02= 区区 仆 鄙 愚 鄙人 小人 小子 在下 不才 不肖 戋戋
Aa02A03@ 老子
Aa02A04= 老朽 老汉 老夫 老拙
Aa02A05@ 老娘
Aa02A06@ 愚兄
Aa02A07= 小弟 兄弟 昆仲 昆季 手足 伯仲 昆玉
Aa02A08= 奴 妾 妾身 民女
Aa02A09= 朕 孤 寡人
Aa02A10= 职 卑职 下官 奴婢 奴才 仆从 仆众 奴仆 奴隶 跟班 跟随 奴役 跟从
Aa02A11= 贫道 小道
Aa02A12@ 贫僧
Aa02A13@ 下臣
Aa02B01= 我们 咱 咱们 吾侪 吾辈 俺们 我辈 咱俩
Aa03A01= 你 您 恁 而 尔 汝 若 乃 卿 君 公
Aa03A02= 老兄 仁兄 世兄 兄长 大哥 年老 老大 垂老 老迈 年迈
Aa03A03= 老弟 贤弟 仁弟 兄弟 昆仲 昆季 手足 伯仲 昆玉
Aa03A04= 大嫂 大姐 老大姐
Aa03A05= 阁下 足下 驾 同志 老同志 旁边 左右 安排 控制 操纵 傍边 同道 驾御 摆布 当中 台端 掌握 把握 大驾 驾驭 尊驾 独揽
Aa03A06= 陛下 主公 大王 万岁
Aa03A07= 您老 你咯
Aa03B01= 你们 尔等
Aa03B02= 诸位 各位 诸君 列位
Aa04A01= 他 她 彼 其 渠 伊 人家
Aa04B01= 他们 她们 他俩 她俩
Aa05A01= 自己 自家 自个儿 自各儿 自身 本身 自我 本人 小我 我 自 己 己方 我方 私人 个人
Aa05B01= 别人 旁人 他人 人家
Aa05B02= 谁 哪个 哪位 张三李四 哪一个 张王赵李
Aa05B03@ 其他人
Aa05C01= 某人 某 或人
Aa05D01@ 任何人
Aa05E01@ 克隆人
Aa06A01= 谁 孰 谁人 谁个 何人 哪个 哪位 何许人也 那个 哪一个 阿谁
Aa06B01@ 有人
Ab01A01= 男人 男子 男子汉 男儿 汉子 汉 士 丈夫 官人 男人家 光身汉 须眉 壮汉 男士 夫君 外子 良人
Ab01A02= 爷儿 爷们 爷儿们
Ab01A03= 先生 子 君 郎 哥 小先生 教师 教员 老师 师长教师 师长 教授 教练 西宾 西席
Ab01B01= 女人 女子 女性 女士 女儿 女 娘 妇 妇女 妇道 妇人 女人家 小娘子 女郎 巾帼 半边天 娘子军 石女 红装 家庭妇女 农妇 才女 密斯 小姐 姑娘 少女
Ab01B02= 女流 女人家 妇道人家 娘儿们 妞儿
Ab01B03= 少妇 婆娘 婆姨 娘子 小娘子
Ab01B04= 姑娘 少女 丫头 千金 小姐 闺女 室女 姑子 黄花闺女 大姑娘 小姑娘 童女 老姑娘 春姑娘 密斯 蜜斯 女士 令嫒 掌珠 令媛 女郎 仙女 女仆 梅香 婢女 使女 丫鬟
同义词词林扩展版详细说明如下:
《同义词词林》的第一版和第二版的词表完全一样,收词 53,859 条。其中有很多的词已经很不常用,成为所谓的罕用词。参照多部电子词典资源,并按照人民日报语料库中词语的出现频度,只保留频度不低于 3(小规模语料的统计结果)部分词语,可剔除 14,706 个罕用词和非常用词。经过这样的处理,《同义词词林》还剩下 39,099 个词条。为了满足自然语言处理的需要,这样规模的词典显然是少了一些,可以说远远不够。为了扩充《同义词词林》,本实验室利用很多词语相关资源,并投入了大量的人力和物力,完成了一部具有汉语大词表的《哈工大信息检索研究室同义词词林扩展版》。最终的词表包含 77,343 条词语。《同义词词林》按照树状的层次结构把所有收录的词条组织到一起,把词汇分成大、中、小三类,大类有 12 个,中类有 97 个,小类有 1,400 个。每个小类里都有很多的词,这些词有根据词义的远近和相关性分成了若干个词群(段落)。每个段落中的词语有进一步分成了若干个行,同一行的词语要么词义相同(有的词义十分接近),要么词义有很强的相关性。例如,“大豆”、“毛豆”和 “黄豆”在同一行;“西红柿”和“番茄”在同一行;“大家”、“大伙儿”、“大家伙儿”在同一行。另外,“将官”、“校官”、“尉官”在同一行,“雇农”、“贫农”、“下中农”、“中农”、“上中农”、“富农”在同一行, “外商”、“官商”、“坐商”、“私商”也在同一行,这些词不同义,但很相关。为了将词义相关的行和同义的行区分开,词典《同义词词林》在行的左端加上“* *”作为标记。小类中的段落可以看作第四级的分类,段落中的行可以看作第五级的分类。这样,词典《同义词词林》就具备了 5 层结构。随着级别的递增,词义刻画越来越细,到了第五层,每个分类里词语数量已经不大,很多只有一个词语,已经不可再分,可以称为原子词群 、原子类或原子节点。不同级别的分类结果可以为自然语言处理提供不同的服务,例如第四层的分类和第五层的分类在信息检索 、文本分类 、自动问答等研究领域得到应用。有研究证明,对词义进行有效扩展,或者对关键词做同义词替换可以明显改善信息检索、文本分类和自动问答系统的性能。词典《同义词词林》中保留下来的 39,099 条词语也保留了原有的分层结构,而新增的 36,267 条词语没有这样的结构。对于这些词,按照《同义词词林》的结构体系进行分类,工作量十分巨大。分类的某些环节可以使用机器自动完成,但是自动完成的结果不是很理想,各个环节主要还是依靠人工来完成。
《同义词词林》只提供了三层编码,即大类用大写英文字母表示,中类用小写英文字母表示,小类用二位十进制整数表示。例如:“Ae 07 农民 牧民 渔民”,“Ae 07”是编码,“农民 牧民 渔民”是该类的标题。标题是由一个或者多个第四层的“段首(即每个段的第一个词)”组成。根据标题词可以知道小类有分成多少个第四级类,如图8.2所示。

图8.2 词典结构
为了使用上的方便,对于第四级和第五级的分类也需要编码。新增的第四级
和第五级的编码与原有的三级编码和并构成一个完整的编码,唯一的代表词典中
的出现的词语。如:
Ba01A02= 物质 质 素
Cb02A01= 东南西北 四方
Ba01A03@ 万物
Cb06E09@ 民间
Ba01B08# 固体 液体 气体 流体 半流体
Ba01B10# 导体 半导体 超导体
编码的方法说明如下:
第四级用大写英文字母表示,第五级用二位十进制整数表示。由于第五级的
分类结果需要特别说明,例如,有的行是同义词,有的行是相关词,有的行只有
一个词,可以分出具体的三种情况。在使用上,有时需要对这三种情况进行区别
对待,所以有必要再增加标记来分别代表着几种情形。具体的标记如表8.3所示。

表8.3词语编码表
图中的编码位是按照从左到右的顺序排列。第八位的标记有 3 种,分别是
“=”、“#”、“@”,“=”代表“相等”、“同义”。末尾的“#”代表“不等”、“同
类”,属于相关词语。末尾的“@”代表“自我封闭”、“独立”,它在词典中既没
有同义词,也没有相关词。
代码实战
HanLP本身就提供了语义相似度的方法,下一篇文章给大家演示代码。
总结
此文章有对应的配套新书教材和视频:
【配套新书教材】
《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】
新书特色:本书从自然语言处理基础开始,逐步深入各种NLP热点前沿技术,使用了Java和Python两门语言精心编排了大量代码实例,契合公司实际工作场景技能,侧重实战。
全书共分为19章,详细讲解中文分词、词性标注、命名实体识别、依存句法分析、语义角色标注、文本相似度算法、语义相似度计算、词频-逆文档频率(TF-IDF)、条件随机场、新词发现与短语提取、搜索引擎Solr Cloud和Elasticsearch、Word2vec词向量模型、文本分类、文本聚类、关键词提取和文本摘要、自然语言模型(Language Model)、分布式深度学习实战等内容,同时配套完整实战项目,例如对话机器人实战、搜索引擎项目实战、推荐算法系统实战。
本书理论联系实践,深入浅出,知识点全面,通过阅读本书,读者不仅可以理解自然语言处理的知识,还能通过实战项目案例更好地将理论融入实际工作中。
【配套视频】
自然语言处理NLP原理与实战 视频教程【陈敬雷】
视频特色:《自然语言处理NLP原理与实战》包含了互联网公司前沿的热门算法的核心原理,以及源码级别的应用操作实战,直接讲解自然语言处理的核心精髓部分,自然语言处理从业者或者转行自然语言处理者必听视频!
上一篇:自然语言处理系列三十二》 语义相似度》语义相似度概念及入门
下一篇:自然语言处理系列三十》文本相似度算法》余弦相似度》Java代码实现