项目概述:随着人工智能技术的飞速发展,大模型(Large Models)和检索增强型生成(Retrieval-Augmented Generation, RAG)已成为自然语言处理(NLP)领域的热点。大模型以其强大的理解和生成能力,正在改变我们与机器交互的方式。RAG模型结合了检索机制和生成机制,进一步提升了生成任务的效果。本项目旨在为初学者提供一个快速入门的指南,帮助他们理解并实践这些前沿技术。
技术方案与实施步骤
- 模型选择利用NVIDIA NIM 微服务(网址:面向开发者的 NIM | NVIDIA 开发者)作为优化容器提供,旨在加速各种规模的企业的 AI 应用开发,为 AI 技术的快速生产和部署铺平道路。这些微服务集可用于在语音 AI、数据检索、数字生物学、数字人、模拟和大型语言模型(LLMs)中构建和部署 AI 解决方案。
笔者选用的是开源大活佛meta的llama-3.1-405b-instruct也就是俗称的llama3.1这里是405b-instruct的版本
NIM模型地址
https://build.nvidia.com/meta/llama-3_1-8b-instruct
- 环境搭建
我这里是使用Windows平台
首先创建好Python环境
大家可以根据自己的网络情况从下面的地址下载:
miniconda官网地址:https://docs.conda.io/en/latest/miniconda.html
清华大学镜像地址: https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/
安装完成打开Anaconda Prompt

在打开的终端中按照下面的步骤执行,配置环境
创建python 3.8虚拟环境
conda create --name ai_endpoint python=3.8
进入虚拟环境
conda activate ai_endpoint
安装nvidia_ai_endpoint工具
pip install langchain-nvidia-ai-endpoints
安装Jupyter Lab
pip install jupyterlab
安装langchain_core
pip install langchain_core
安装langchain
pip install langchain
安装matplotlib
pip install matplotlib
安装Numpy
pip install numpy
安装faiss, 这里如果没有GPU可以安装CPU版本
pip install faiss-cpu==1.7.2
安装OPENAI库
安装OPENAI库
在上面提到的NVIDIA NIM网站申请api
入网址https://build.nvidia.com/explore/discover` `点击右上角login``填写邮箱``如果是全新的邮箱需要创建账户``进入申请或登录邮箱进行验证``验证成功全选提交``创建用户名``任意点选模型图标,进入模型交互界面后会在右侧看到代码API,然后找到Get API KEY鼠标点击选择生成API KEY并保存好``简单就获得到一个free api
检测NVIDIA NIM模型服务(验证api是否正常)
from openai import OpenAI`` ``client = OpenAI(` `base_url = "https://integrate.api.nvidia.com/v1",` `api_key = "nvapi-oIx7VAq2myUlzhBk7U9wr7mCdQe7fq9KVZ9UC4JhbHg3REIWs1KZbHHRO7xxxx"``)`` ``completion = client.chat.completions.create(` `model="meta/llama-3.1-405b-instruct",` `messages=[{"role":"user","content":"泰坦尼克号的导演是谁"}],` `temperature=0.2,` `top_p=0.7,` `max_tokens=1024,` `stream=True``)`` ``for chunk in completion:` `if chunk.choices[0].delta.content is not None:` `print(chunk.choices[0].delta.content, end="")`` ``
模型回答
詹姆斯·卡梅隆 #精简干练且使用中文
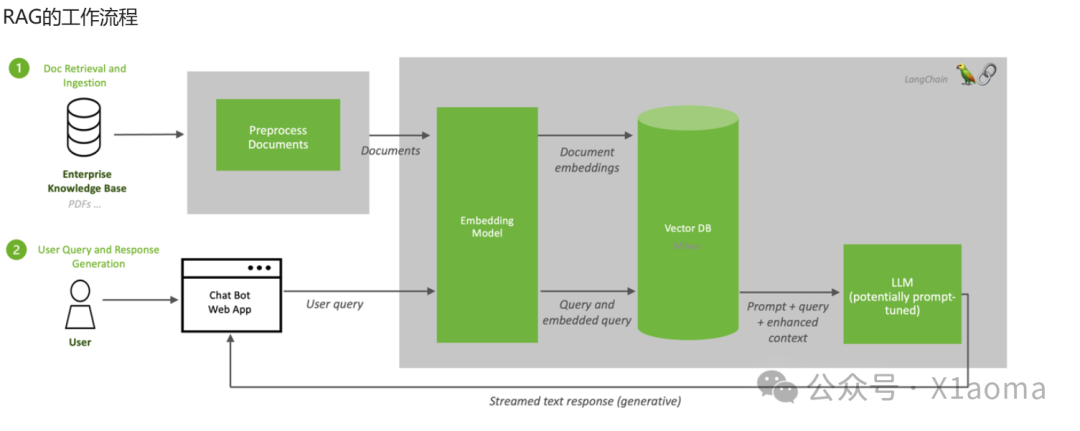
利用RAG进行数据构建
RAG的全称是Retrieval-Augmented Generation,中文翻译为检索增强生成。它是一个为大模型提供外部知识源的概念,这使它们能够生成准确且符合上下文的答案,同时能够减少模型幻觉。
初始化SLM
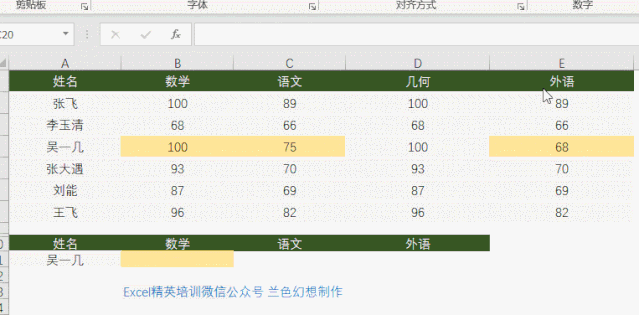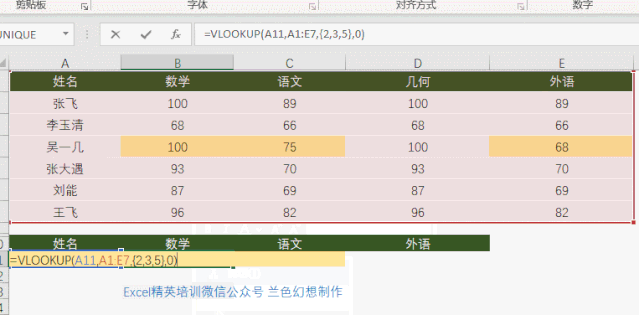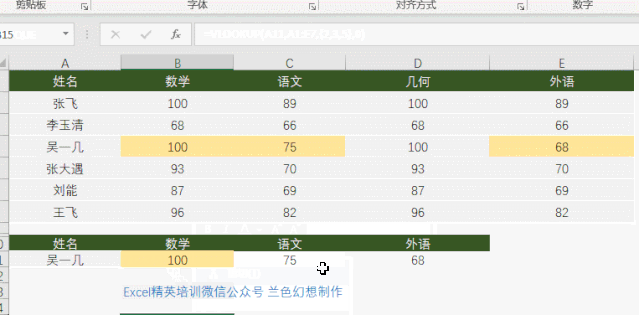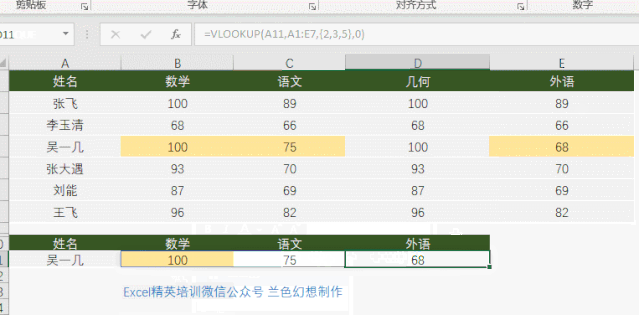
llm = ChatNVIDIA(model="meta/llama-3.1-405b-instruct", nvidia_api_key=nvapi_key, max_tokens=512)``result = llm.invoke("泰坦尼克号的导演是谁?")``print(result.content)
获取文本数据集
import os``from tqdm import tqdm``from pathlib import Path`` ``# Here we read in the text data and prepare them into vectorstore``ps = os.listdir("./zh_data/")``data = []``sources = []``for p in ps:` `if p.endswith('.txt'):` `path2file="./zh_data/"+p` `with open(path2file,encoding="utf-8") as f:` `lines=f.readlines()` `for line in lines:` `if len(line)>=1:` `data.append(line)` `sources.append(path2file)
进行一些基本的清理并删除空行
documents=[d for d in data if d != '\n']``len(data), len(documents), data[0]`` ``输出``(1,` `1,` `'泰坦尼克号是一部 1997 年美国史诗爱情灾难片,由詹姆斯·卡梅隆执导、编剧、制作和联合剪辑。该片以 1912 年泰坦尼克号沉没事件为基础,融合了历史和虚构的元素。凯特·温斯莱特和莱昂纳多·迪卡普里奥饰演不同社会阶层的成员,他们在泰坦尼克号的处女航中坠入爱河。比利·赞恩、凯西·贝茨、弗朗西斯·费舍尔、格洛丽亚·斯图尔特、伯纳德·希尔、乔纳森·海德、维克多·加伯和比尔·帕克斯顿也参演了这部电影。\\n卡梅隆的这部电影的灵感来自于他对沉船的迷恋。他认为,一个夹杂着人员伤亡的爱情故事对于传达灾难的情感影响至关重要。该片于 1995 年 9 月 1 日开始拍摄,当时卡梅隆拍摄了泰坦尼克号沉船的实际镜头。研究船上的现代场景是在卡梅伦拍摄沉船时使用的 Akademik Mstislav Keldysh 号上拍摄的。使用比例模型、计算机生成的图像以及巴哈工作室建造的泰坦尼克号重建模型来重现沉没过程。该片由派拉蒙影业和二十世纪福克斯公司共同资助;前者负责在北美发行,而后者则在国际上发行影片。这是当时制作成本最高的电影,制作预算为 2 亿美元。拍摄时间为1996年7月至1997年3月。\\n《泰坦尼克号》于 1997 年 12 月 19 日上映。它因其视觉效果、表演(尤其是迪卡普里奥、温斯莱特和斯图尔特的表演)、制作价值、导演、配乐、摄影、故事和情感深度而受到好评。除其他奖项外,它获得了14项奥斯卡金像奖提名,并赢得了11项奖项,其中包括最佳影片和最佳导演,追平了《宾虚》(1959 年),成为获得奥斯卡奖最多的电影。《泰坦尼克号》的全球首映票房超过 18.4 亿美元,是第一部突破 10 亿美元大关的电影。它是有史以来票房最高的电影,直到卡梅隆的下一部电影《阿凡达》(2009 年) 在 2010 年超越了它。经过多次重新上映,该电影的全球总票房达到 22.57 亿美元,成为第二部票房收入超过 100 万美元的电影。《阿凡达》之后全球票房达到 20 亿美元。它于2017年被选入美国国家电影登记处保存。')
将文档处理到 faiss vectorstore 并将其保存到磁盘
# Here we create a vector store from the documents and save it to disk.``from operator import itemgetter``from langchain.vectorstores import FAISS``from langchain_core.output_parsers import StrOutputParser``from langchain_core.prompts import ChatPromptTemplate``from langchain_core.runnables import RunnablePassthrough``from langchain.text_splitter import CharacterTextSplitter``from langchain_nvidia_ai_endpoints import ChatNVIDIA``import faiss`` ``# 只需要执行一次,后面可以重读已经保存的向量存储``# text_splitter = CharacterTextSplitter(chunk_size=400, separator=" ")``# docs = []``# metadatas = []`` ``# for i, d in enumerate(documents):``# splits = text_splitter.split_text(d)``# #print(len(splits))``# docs.extend(splits)``# metadatas.extend([{"source": sources[i]}] * len(splits))`` ``# store = FAISS.from_texts(docs, embedder , metadatas=metadatas)``# store.save_local('./zh_data/nv_embedding')
重读之前处理并保存的 Faiss Vectore 存储
retriever = store.as_retriever()`` ``prompt = ChatPromptTemplate.from_messages(` `[` `(` `"system",` `"Answer solely based on the following context:\n<Documents>\n{context}\n</Documents>",` `),` `("user", "{question}"),` `]``)`` ``chain = (` `{"context": retriever, "question": RunnablePassthrough()}` `| prompt` `| llm` `| StrOutputParser()``)`` ``chain.invoke("泰坦尼克号的导演是谁?")`` ``输出` `泰坦尼克号的导演是詹姆斯·卡梅隆。
-
NVIDIA AI Endpoint介绍页面: https://python.langchain.com/v0.1/docs/integrations/chat/nvidia_ai_endpoints/
-
NVIDIA NIM页面: https://build.nvidia.com/explore/discover
-
NVIDIA DLI课程学习资料页面:https://www.nvidia.cn/training/online/
应用场景:小白学习RAG原理并上手的不二之选,进阶玩家可以利用平台进行不同的场景应用。
问题分析:新手没有使用过python的同学可能会遇到些许问题如不懂如何导包,但是利用这个NIM平台可以非常方便进行测试并纠错
#测试中,from langchain.vectorstores import FAISS 无法运行,发现环境还需要安装一些组件,安装命令如下:
pip install -U langchain-community
项目总结与展望:
我也是第一次了解RAG很顺利就现实并了解RAG的原理及工作流程,从搭建到使用,再到知识数据的重建,同时也让我们认识了大模型的一些问题,特别是数据的准确性和真实性,非常非常重要。对于老手可以利用更多技术实现眼花缭乱的功能。
附上技术清单
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。