我的课程笔记,欢迎关注:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/tree/master/cuda-mode
CUDA-MODE课程笔记 第8课: CUDA性能检查清单
课程笔记

这节课实际上算是CUDA-MODE 课程笔记 第一课: 如何在 PyTorch 中 profile CUDA kernels 这节课更细节的讲解。另外关于nsight compute相关指标细节解释可以参考 CUDA-MODE 第一课课后实战(上),
CUDA-MODE 第一课课后实战(下) 这两篇笔记。
将GPU用于计算,我们最关心的肯定是性能。比较幸运的是,当我们掌握一些性能优化技巧之后它往往会经常被用到。这节课将会系统的介绍这些性能优化技巧。

本节课的课件和代码都在 https://github.com/cuda-mode/lectures 开源,我们可以用nvcc编译lecture8下面的cu文件,然后使用ncu进行profile。此外,这里的方法遵循了 https://arxiv.org/pdf/1804.06826.pdf 这篇论文的风格。up主也非常推荐大家阅读下这篇论文,用claude 3.5问了一下paper的主要内容,如下截图:
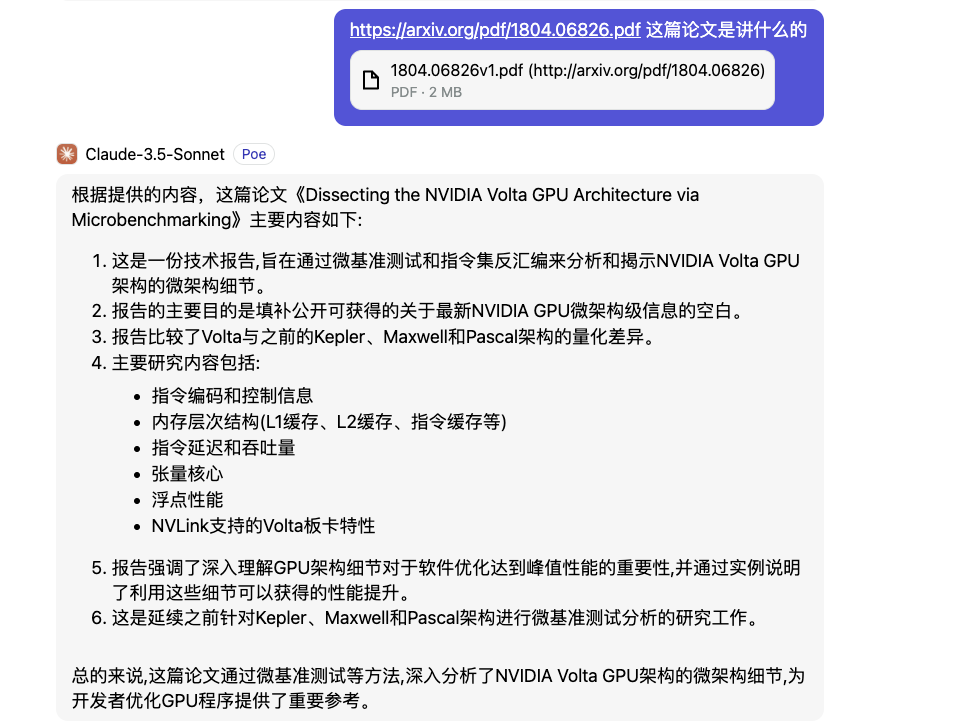
可以看到这篇论文主要是对Volta架构的GPU的架构细节进行分析,对性能优化是很重要的。
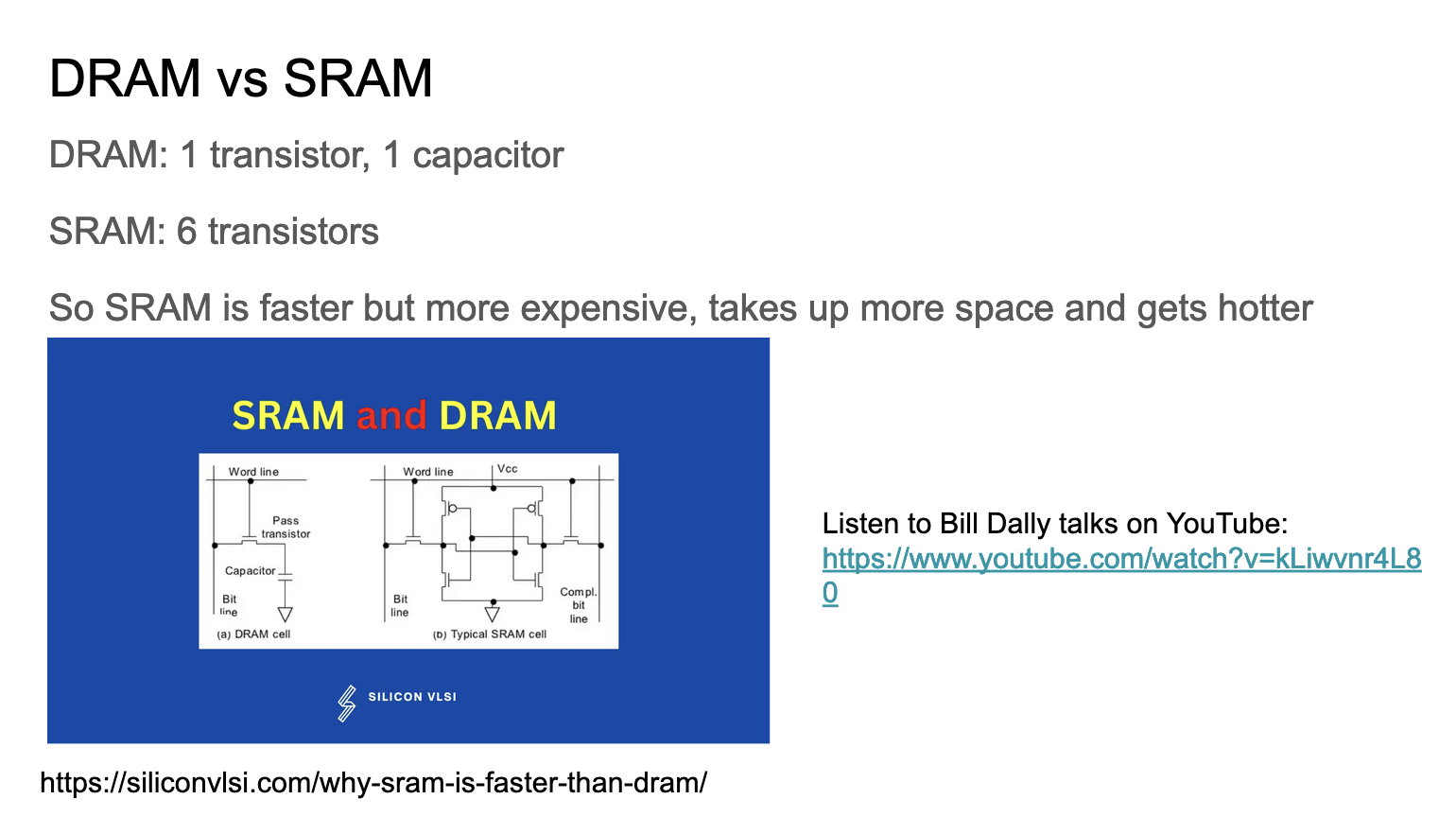
这张Slides从物理学的角度分析了下SRAM和DRAM的区别:
- DRAM由1个晶体管和1个电容器构成;SRAM: 由6个晶体管构成
- SRAM 比 DRAM 更快,但也更贵;SRAM 占用更多空间且发热更多;
实际上SRAM就对应了GPU的Shared Memory,而DRAM对应的则是Shared Memory。
这里的youtube链接作者Bill是NVIDIA的首席科学家,他解释了很多为什么GPU设计成现在这个样子,并且由浅入深,基础细节讲的非常清楚。

这里的"性能检查清单"(Performance checklist),列出了一系列优化GPU程序性能的策略和技巧:
- 合并全局内存访问(Coalesced Global Memory Access)
- 最大化占用率(Maximize occupancy)
- 理解是内存受限还是计算受限(Understand if memory or compute bound)
- 最小化线程分化(Minimize control divergence)
- Tiling以更好的重用数据(Tiling of reused data)
- 私有化(Privatization)
- Thread Coarsening
- 使用更好的数学方法重写算法(Rewrite your algorithm using better math)
这里的Privatization指的应该就是Shared Memory/寄存器优化全局内存读取,而Coarsening大概指的就是一个线程应该完成多少任务,一般情况下我们让一个线程完成的任务尽量少,但是在Compute Bound情况下,让一个线程执行更多的工作可以让程序运行得更快。最后一点更好的数学方法重写算法的经典例子就是Flash Attention。

这张Slides讲述了GPU内存访问延迟的相关内容,下面的Figure3和表格都来自 https://arxiv.org/pdf/2208.11174 ,这个表格(Table IV),列出了不同类型内存的访问延迟(以时钟周期为单位):
- 全局内存(Global memory): 290 cycles
- L2 缓存: 200 cycles
- L1 缓存: 33 cycles
- 共享内存(Shared Memory): 读取23 cycles,写入19 cycles
我后面也找到了这个paper里面做micro benchmark的代码:https://www.stuffedcow.net/research/cudabmk?q=research/cudabmk ,后面如果有空继续阅读下这篇 paper 以及测试代码。

这张Slides讲述了延迟(latency)在计算机系统中的重要性和一些相关概念。
- 标题 “It’s the latency stupid” 强调了延迟的重要性。
- 吞吐量(Throughput)和延迟(Latency)的对比:
- 吞吐量容易提高,但延迟却很难降低。
- 举例说明:即使你可以并行使用80条电话线,每条线传输一个比特,但100毫秒的延迟仍然存在。
- 量化(Quantization)技术:
- 用于减少数据包大小的一种方法。
- 例如,Bolo(可能是某个系统或协议)尽可能使用字节(byte)而不是16位或32位字来减少数据包大小。
- 底部提供了一个网址链接,包含更多关于这个话题的详细讨论。

这张Slides开始介绍内存合并(Memory Coalescing)的概念。我们无法减少延迟,但可以通过读取连续的内存元素来隐藏延迟。Slides建议在进行案例研究时要关注以下三个方面:
- DRAM Throughput(DRAM吞吐量)
- Duration(持续时间)
- L1 cache throughput(L1缓存吞吐量)
这里说的内存合并的案例就是 https://github.com/cuda-mode/lectures/blob/main/lecture_008/coalesce.cu 这里所展示的。代码如下:
#include <iostream>
#include <cuda_runtime.h>
__global__ void copyDataNonCoalesced(float *in, float *out, int n) {
int index = blockIdx.x * blockDim.x + threadIdx.x;
if (index < n) {
out[index] = in[(index * 2) % n];
}
}
__global__ void copyDataCoalesced(float *in, float *out, int n) {
int index = blockIdx.x * blockDim.x + threadIdx.x;
if (index < n) {
out[index] = in[index];
}
}
void initializeArray(float *arr, int n) {
for(int i = 0; i < n; ++i) {
arr[i] = static_cast<float>(i);
}
}
int main() {
const int n = 1 << 24; // Increase n to have a larger workload
float *in, *out;
cudaMallocManaged(&in, n * sizeof(float));
cudaMallocManaged(&out, n * sizeof(float));
initializeArray(in, n);
int blockSize = 128; // Define block size
// int blockSize = 1024; // change this when talking about occupancy
int numBlocks = (n + blockSize - 1) / blockSize; // Ensure there are enough blocks to cover all elements
// Launch non-coalesced kernel
copyDataNonCoalesced<<<numBlocks, blockSize>>>(in, out, n);
cudaDeviceSynchronize();
initializeArray(out, n); // Reset output array
// Launch coalesced kernel
copyDataCoalesced<<<numBlocks, blockSize>>>(in, out, n);
cudaDeviceSynchronize();
cudaFree(in);
cudaFree(out);
return 0;
}
这里段程序比较简单,用于演示内存合并(Memory Coalescing)的概念和其对性能的影响。它主要做了以下事情:
- 定义了两个CUDA kernel:
- copyDataNonCoalesced kernel:非合并内存访问模式,以非连续的方式读取输入数组(使用 (index * 2) % n 作为索引),这种访问模式会导致非合并的内存访问,可能降低性能。
- copyDataCoalesced kernel:合并内存访问模式,以连续的方式读取输入数组(直接使用 index 作为索引),这种访问模式允许合并内存访问,可以提高性能。
- 主函数:
- 分配统一内存(Unified Memory)用于输入和输出数组,初始化输入数组。
- 设置CUDA网格和块的大小,分别运行非合并和合并的kernel,在每次kernel执行后使用 cudaDeviceSynchronize() 确保GPU操作完成。
接着使用nvcc -o benchmark coalesce.cu来编译程序,然后执行ncu benchmark来Profile程序。

对于copyDataNonCoalesced kernel来说,DRAM内存吞吐量大约是89%,L1 Cache的吞吐量是30%,kernel的执行时间是764us。
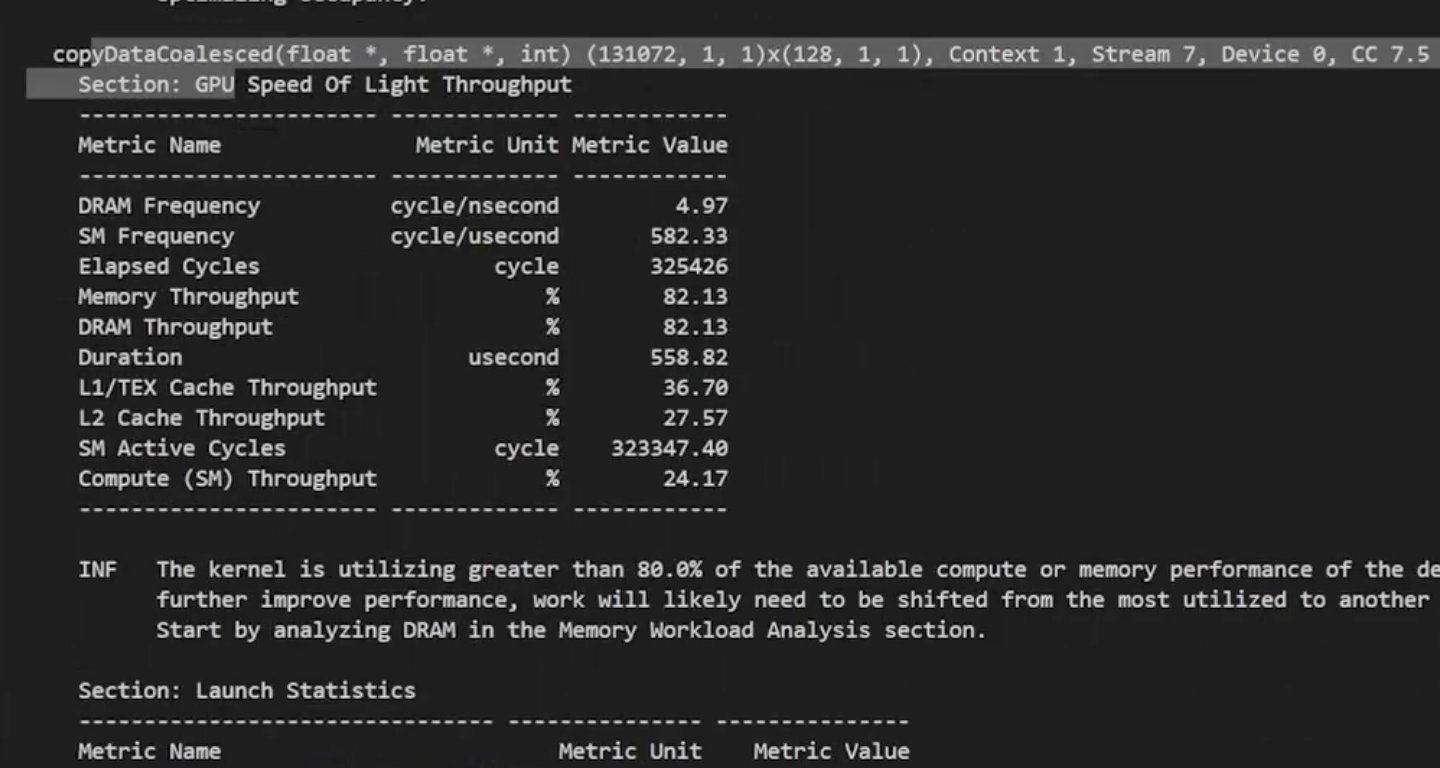
对于copyDataCoalesced kernel来说,L1 Cache的吞吐量大约是37%,DRAM内存吞吐量是82%,执行时间是558us。
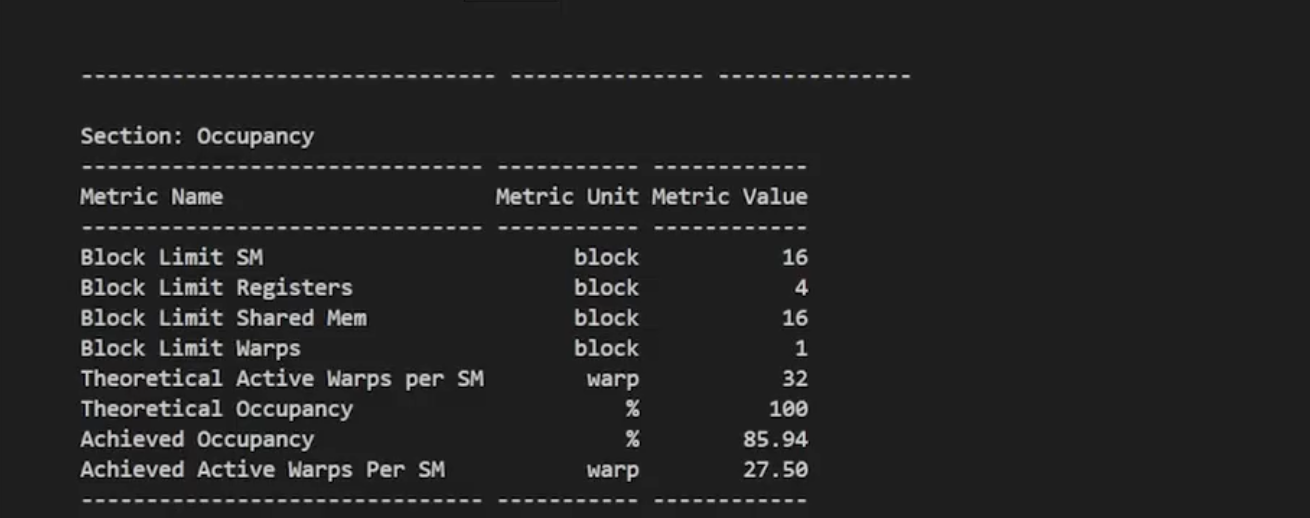
我们可以看到合并内存访问的kernel是有明显的性能提升的。可以预见,随着输入数据量的增大合并内存访问的优势会更明显。ncu的结果里面还提示计算的理论occupancy(100.0%)和实测的实际occupancy占用(77%)之间的差异可能是由于 kernel 执行期间的warp调度开销或工作负载不平衡导致的。在同一kernel 的不同块之间以及块内的不同 warps 之间都可能发生负载不平衡。把上面程序中的int blockSize = 128改成int blockSize = 1024再次用ncu profile,可以发现occupancy提升到了85.94%。
这张Slides讨论了GPU中的占用率(Occupancy)问题,主要内容如下:
- 两种quantization问题:
- a) Tile quantization:矩阵维度不能被线程块Tile大小整除。
- b) Wave quantization:Tile总数不能被GPU上的SM(流多处理器)数量整除。
- 性能图表比较和分析:
- 左图(a):cuBLAS v10 上 NN GEMM 的性能
- 右图(b):cuBLAS v11 上 NN GEMM 的性能
- 两图都是在 M = 1024, N = 1024 的矩阵维度下进行的测试
- 左图(a)显示性能呈现明显的阶梯状,有大幅波动。
- 右图(b)显示性能波动较小,整体更加平滑。
我们可以看到cuBLAS v11 可能采用了更好的调度策略或优化技术,减少了由于Tile和Wave Quantization 导致的性能波动。

这张Slides讲解了在PyTorch中使用padding(填充)来解决Tensor Core矩阵乘法维度要求的问题。具体内容如下:
- 在PyTorch环境中,使用padding是解决某些问题的方法。
- 表格展示了不同cuBLAS和cuDNN版本下,使用Tensor Core的数据精度要求。这些要求适用于矩阵维度M、N和K。
- 版本区分:
- 左列:cuBLAS < 11.0 和 cuDNN < 7.6.3 的旧版本
- 右列:cuBLAS ≥ 11.0 和 cuDNN ≥ 7.6.3 的新版本
- 数据类型的要求:
- INT8:旧版本要求16的倍数;新版本总是可用,但16的倍数最高效,在A100上128的倍数最佳。
- FP16:旧版本要求8的倍数;新版本总是可用,但8的倍数最高效,在A100上64的倍数最佳。
- TF32:旧版本不适用;新版本总是可用,但4的倍数最高效,在A100上32的倍数最佳。
- FP64:旧版本不适用;新版本总是可用,但2的倍数最高效,在A100上16的倍数最佳。
新版本的cuBLAS和cuDNN提供了更灵活的Tensor Core使用条件。而A100 GPU可能需要更大的倍数来获得最佳性能。Padding可以用来将矩阵维度调整为这些推荐的倍数,以提高性能。

在CUDA中提升Occupancy的一个方法是修改kernel。
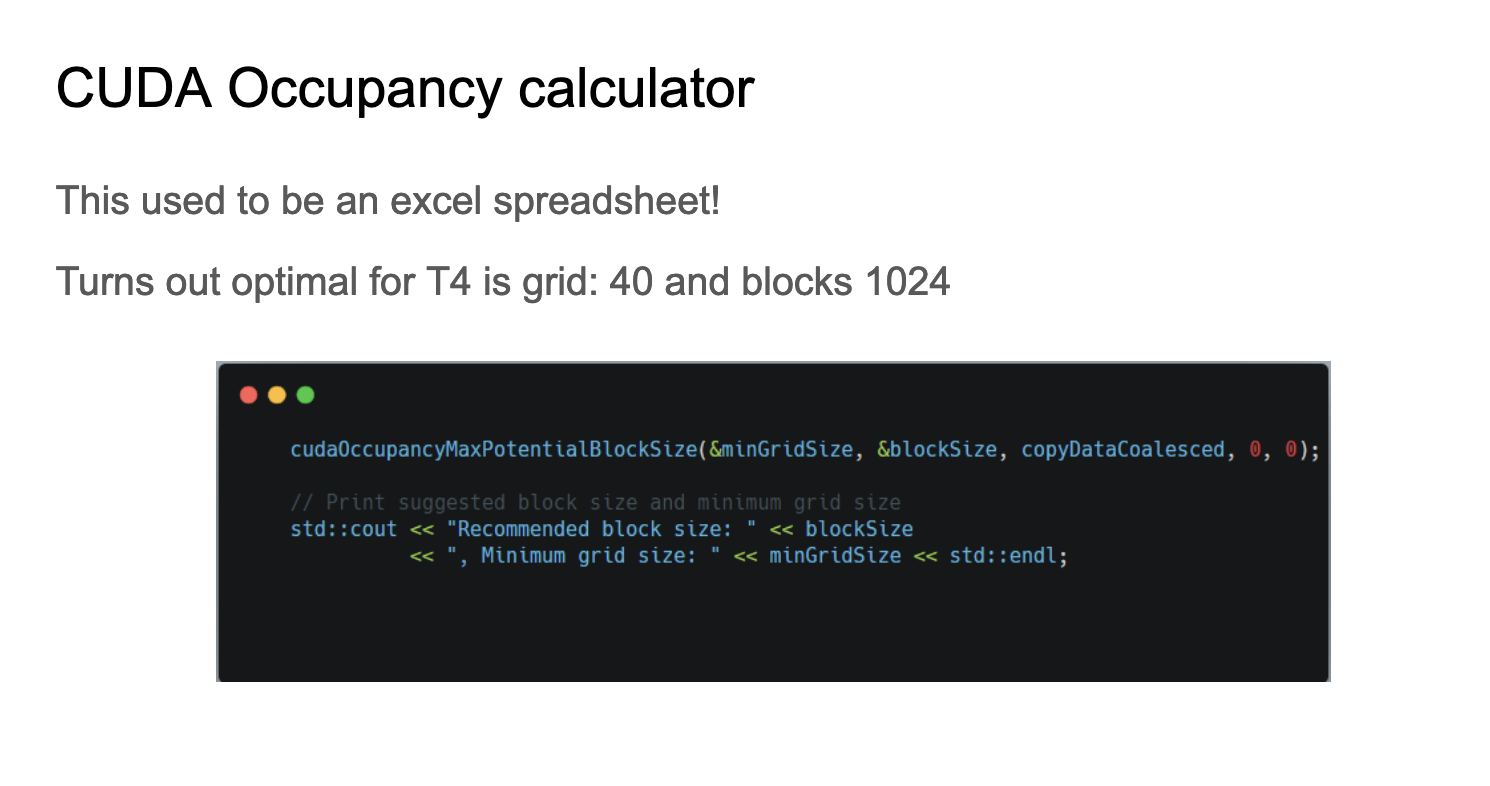
CUDA Occupancy calculator工具可以帮我们自动计算达到更好Occupancy的kernel启动参数,在上一节合并访存的.cu中调用这个Api结果显示,对于T4 GPU,最优的配置是网格大小为40,块大小为1024。代码见:https://github.com/cuda-mode/lectures/blob/main/lecture_008/occupancy.cu
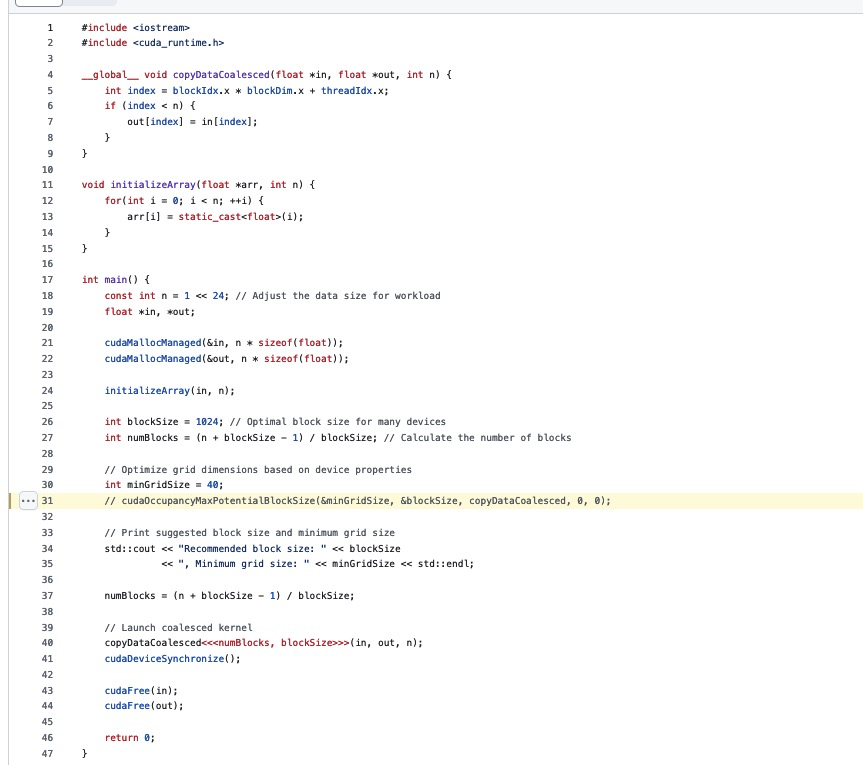
在对这个程序进行ncu的时候有新的问题,那就是下面所展示的:

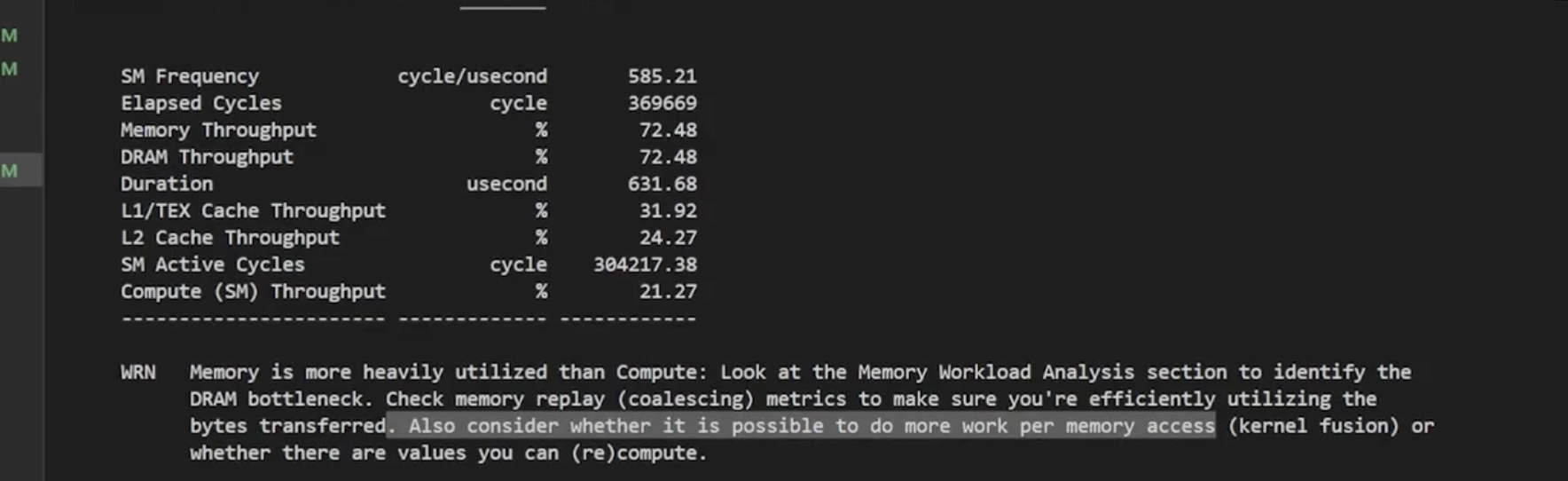
警告(WRN):内存利用率高于计算利用率:请查看内存工作负载分析部分以识别DRAM瓶颈。检查内存重放(合并)指标,以确保您正在有效利用传输的字节。同时考虑是否可以通过每次内存访问执行更多工作(kernel融合)或是否有可以(重新)计算的值。
接下来开始讨论这个问题
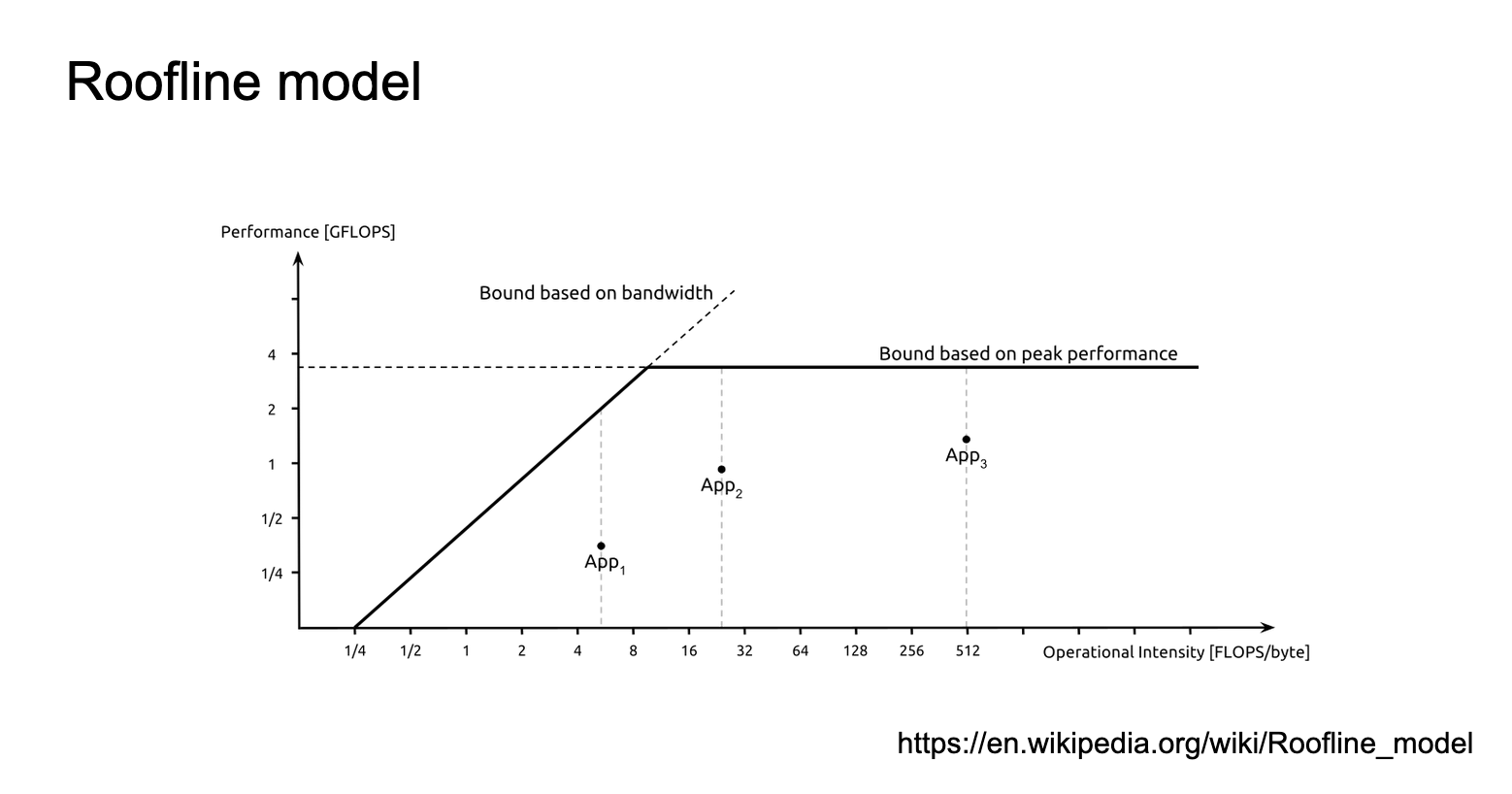
讨论之前需要先了解一下这张Slides展示的Roofline模型,它决定了一个cuda kernel是compute bound还是memory bound。
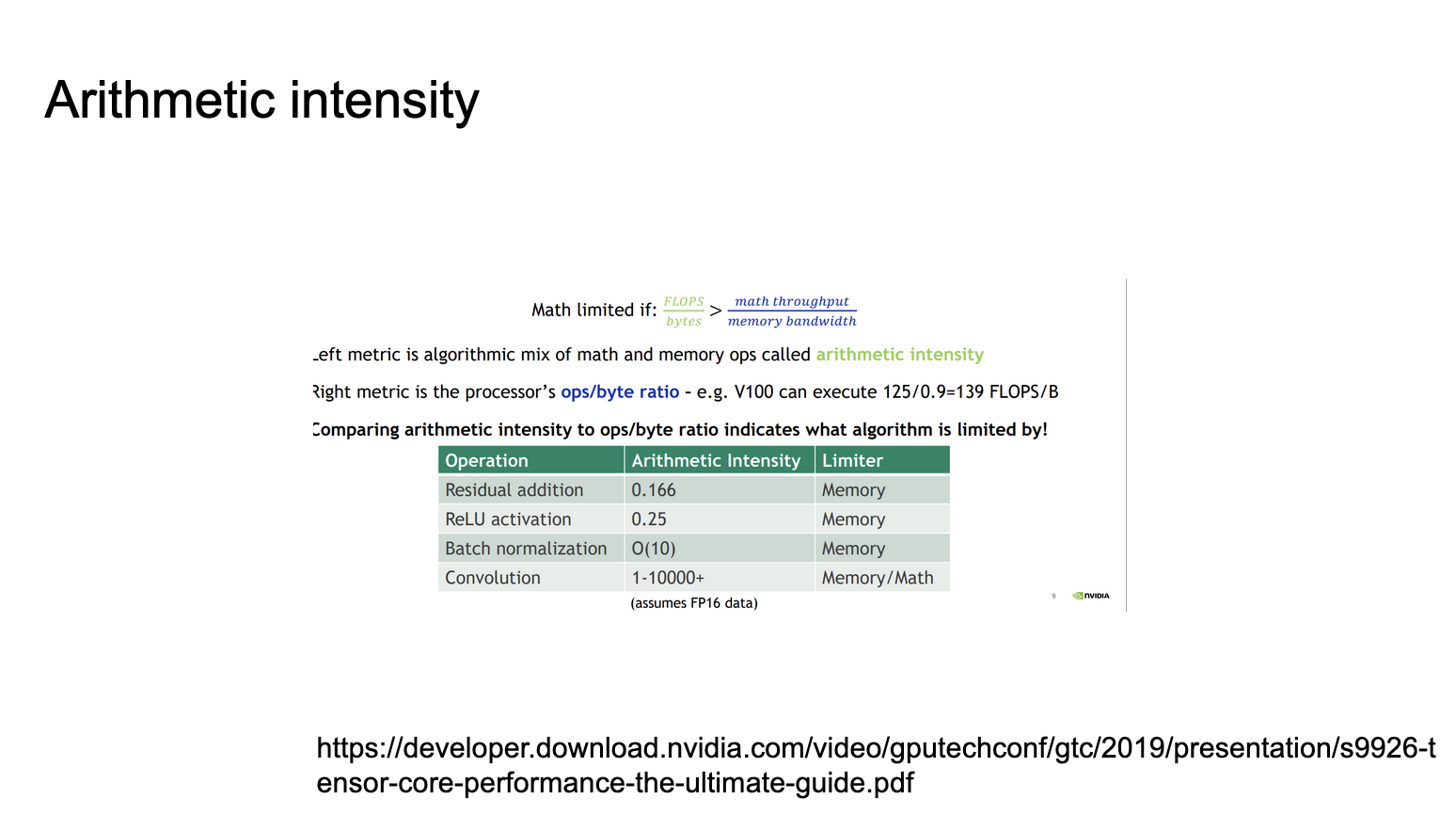
这张Slides讲解了算术强度(Arithmetic intensity)的概念及其在处理器性能分析中的应用。这个slides来自gtc2019的一个讲解。
左侧指标是数学运算和内存操作的算法混合,称为算术强度。右侧指标是处理器的ops/byte比率。例如,V100 GPU可以执行125/0.9=139 FLOPS/B。比较算术强度和ops/byte比率可以指出算法受什么因素限制。
下面还给出了操作类型及其算术强度表格:
- Residual addition(残差加法):0.166,受内存限制
- ReLU activation(ReLU激活):0.25,受内存限制
- Batch normalization(批量归一化):O(10),受内存限制
- Convolution(卷积):1-10000+(假设FP16数据),可能受内存或数学运算限制
链接:https://developer.download.nvidia.com/video/gputechconf/gtc/2019/presentation/s9926-tensor-core-performance-the-ultimate-guide.pdf

这张slides讲解了ReLU(Rectified Linear Unit)函数的算术强度分析:
- ReLU函数定义:f(x) = max(0, x),应用于向量的每个元素。
- 操作描述:对每个元素进行1次读取、1次比较操作,可能还有1次写入。
- 数据类型:假设使用float32,即每个数占4字节(32位)。
- 计算分析:
- 操作数(Ops):1(每个元素一次比较操作)
- 字节数(Byte):2 * 4 = 8(读取和可能的写入,每次4字节)
- 算术强度计算:
- 最坏情况:1/8(当每个元素都需要写入时)
- 最好情况:1/4(当不需要写入时,只有读取操作)
结论:1/4 < 1,表明ReLU操作受内存带宽限制(Memory bound)

这张Slides对Float16的ReLU进行了算术强度分析,可以看打这种情况下最坏的算术强度是1/4,而不是Float32时的1/8,因此量化是可以提高计算强度的。

这张Slides讲解了矩阵乘法(Matmul)的算术强度分析。其中:
- FLOPS(浮点运算次数)计算:
- 对C中的每个输出元素,需要A的一行和B的一列做点积
- 需要N次乘法和N次加法
- 总FLOPS = M * K * 2N
- 字节数计算:
- 加载矩阵A和B:MN + NK
- 写入输出矩阵C:MK
- 总字节数 = MN + NK + MK
- 算术强度(AI)计算:
- AI = 2MNK / (MN + NK + MK)
- 结论:
- 对于大型矩阵,计算受限(Compute bound)
- 否则,带宽受限(Bandwidth bound)

这张Slides总结了如何优化不同类型的kernels:
- 带宽受限的kernel(Bandwidth Bound Kernels)优化策略:
- Fuse(融合):合并多个操作以减少内存访问
- Quantize(量化):使用更小的数据类型来减少内存传输
- Compile(编译):可能指使用特定的编译技术来优化内存访问模式
- 计算受限的kernel(Compute Bound Kernels)优化策略:
- Write a better algorithm(编写更好的算法):这意味着需要从算法层面进行优化

关于矩阵乘法Tiling减少全局内存访问请查看以前的CUDA-MODE 课程笔记 第四课: PMPP 书的第4-5章笔记 。

这张Slides对应这里的代码: https://github.com/cuda-mode/lectures/blob/main/lecture_008/divergence.cu ,主要是对下面2个kernel进行分析:
__global__ void processArrayWithDivergence(int *data, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
if (data[idx] % 2 == 0) {
data[idx] = data[idx] * 2; // 注意这个分支比下面的分支要慢,可能一个Warp里执行这个分支的线程会落后,Warp里的其它线程必须等待这些线程计算完成
} else {
data[idx] = data[idx] + 1;
}
}
}
__global__ void processArrayWithoutDivergence(int *data, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
int isEven = !(data[idx] % 2); // 这里做的事情和上面相同,但是规避了线程分化问题
data[idx] = isEven * (data[idx] * 2) + (!isEven) * (data[idx] + 1);
}
}
- 控制分歧(control divergence)与占用率(occupancy)有关,但如果条件语句导致大量线程闲置,这是不好的。
- processArrayWithDivergence 耗时 0.074272 毫秒; processArrayWithoutDivergence 耗时 0.024704 毫秒;这表明去除control divergence可以显著提高性能(约3倍)。
- “ncu --set full divergence” 用这行命令来设置线程control divergence分析。

对于compute bound的kernel,让线程可以做更多工作,可能会更快。
- 性能比较:
- 运行命令:main ~/lecturex ./benchmark
- VecAdd 执行时间:0.245600 ms
- VecAddCoarsened 执行时间:0.015264 ms
- 关键观察:
- VecAddCoarsened启动了一半的线程数量
- 尽管线程数减少,但执行速度显著提高(约16倍)
这里的代码在 https://github.com/cuda-mode/lectures/blob/main/lecture_008/coarsening.cu 。
这也许可以解释Lecture 7中为什么对于Int4 Weight Only量化的高效kernel实现比普通的fp16的Kernel跑得更快。

这张Slides讨论了在GPU编程中的"私有化"(Privatization)技术。要点为:
- 将部分更新应用到数据的私有副本上,然后再写回全局或共享内存。
- 示例:
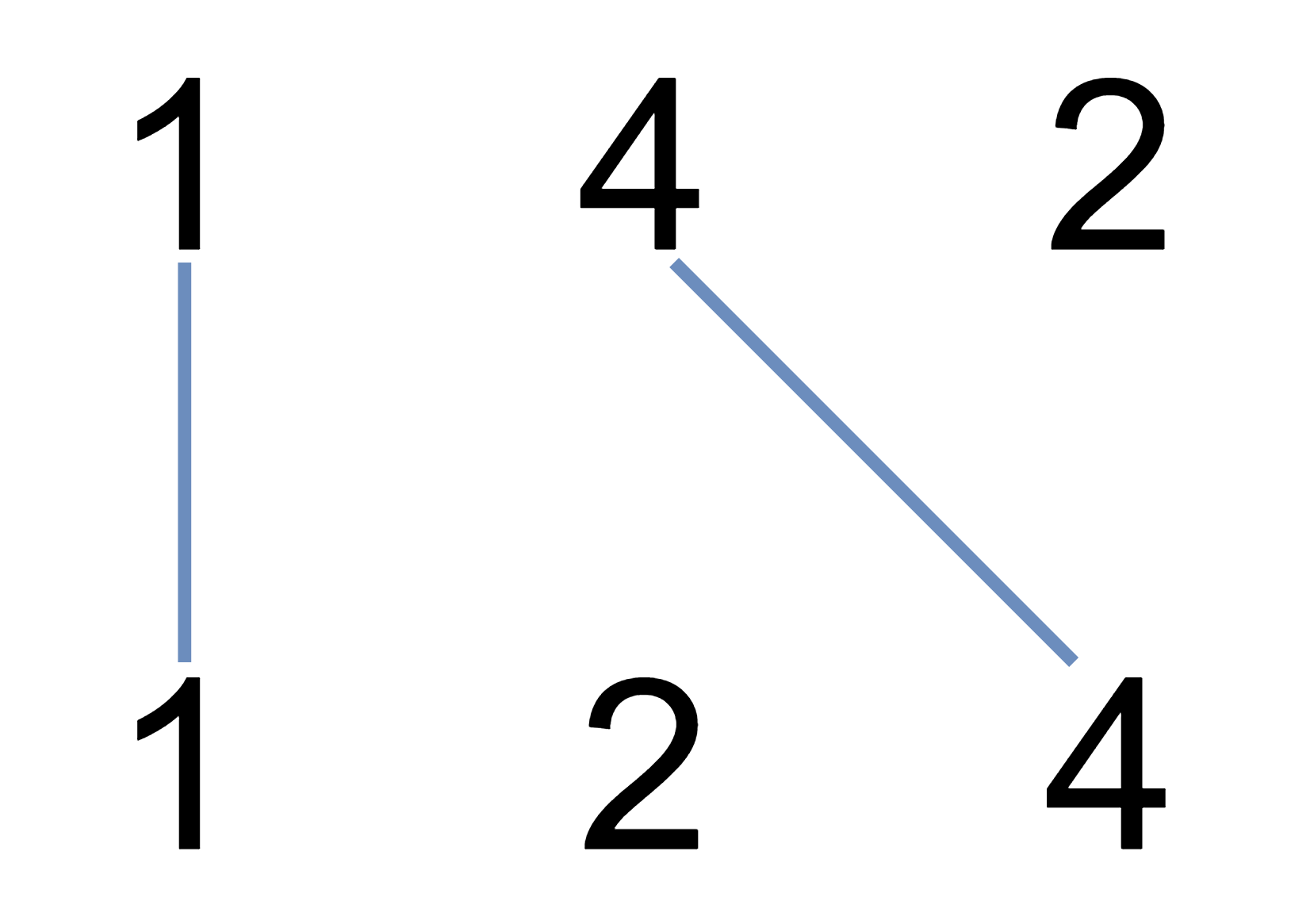
- 滑动窗口算法(Sliding window algorithm)
- 图示:1 2 [3] [4] [5] 6 7
- 这表明算法在一个局部窗口内进行操作。
- Privatization的优势:
- 更高的占用率(Higher occupancy)
- 更高的计算SM吞吐量(Higher compute SM throughput)
- 更低的DRAM吞吐量(Lower DRAM throughput)
这个滑动窗口算法对应的例子就是Mistral等大模型里面的滑动窗口注意力算法,
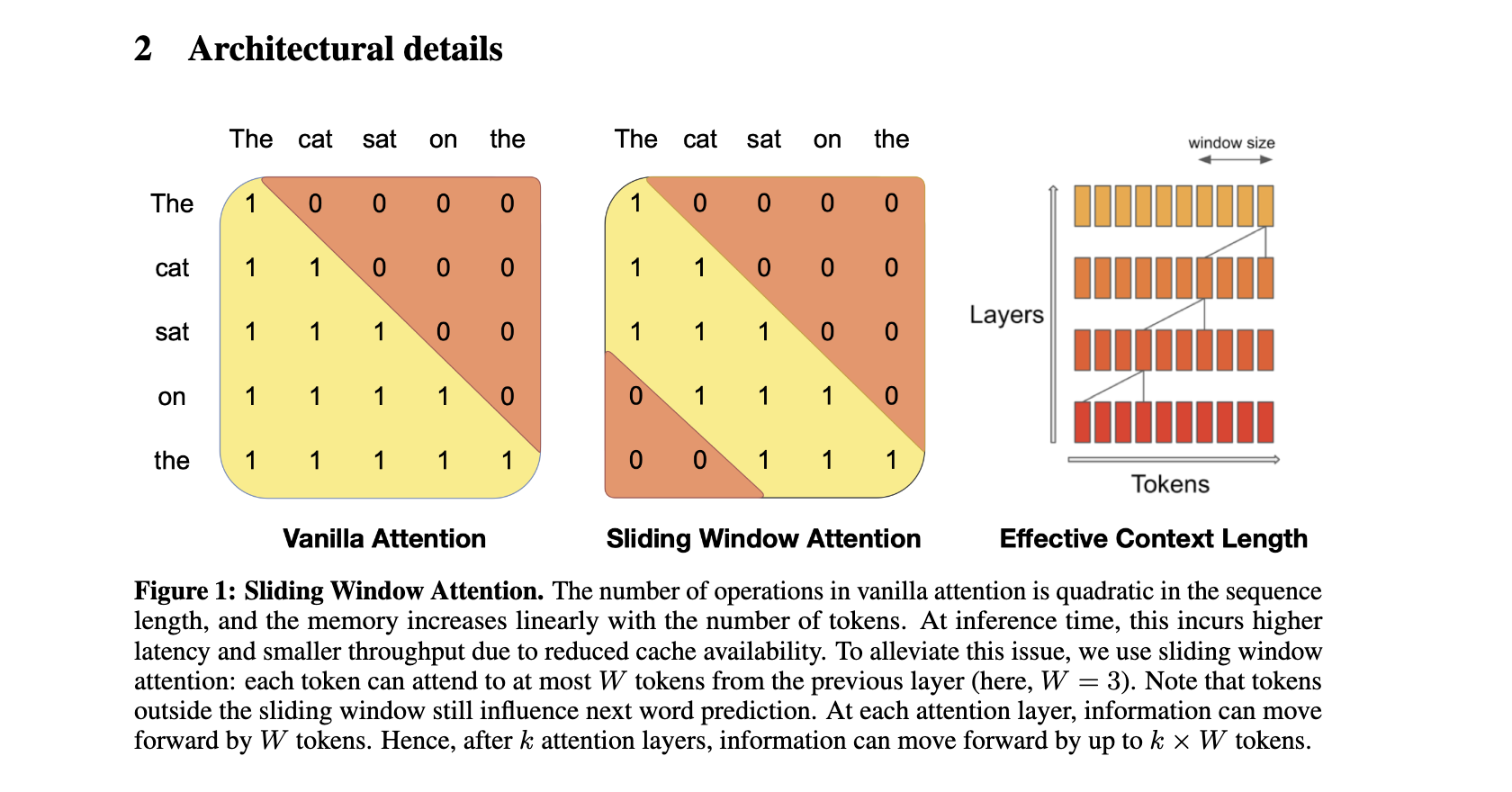
解释下这个图:
- 左侧矩阵:Vanilla Attention
- 展示了传统注意力机制,每个token都可以关注到所有其他token。
- 矩阵是下三角形,表示每个token只能关注到它自己和之前的token。
- 中间矩阵:Sliding Window Attention
- 展示了滑动窗口注意力机制,每个token只关注固定窗口大小内的相邻token。
- 这里窗口大小W=3,可以看到每个token只与前后3个token有连接。
- 右侧图:Effective Context Length
- 展示了多层滑动窗口注意力如何扩大有效上下文长度。
- 每一层都可以使信息向前传播W个token。
总结来说,传统注意力的操作数量与序列长度成二次方关系,内存使用随token数线性增长。在推理时,这会导致更高的延迟和更低的吞吐量,因为缓存可用性降低。滑动窗口注意力通过限制每个token最多只关注前一层的W个token来缓解这个问题。虽然窗口外的token不直接参与注意力计算,但它们仍然可以影响下一个词的预测。在每个注意力层,信息可以向前传播W个token。经过k个注意力层后,信息可以向前传播最多k × W个token。
继续讨论Privatization技术,https://github.com/cuda-mode/lectures/blob/main/lecture_008/privatization.cu 这里的核心代码是:
// CUDA kernel for vector addition without privatization
__global__ void vectorAdd(const float *a, const float *b, float *result, int n) {
int index = threadIdx.x + blockIdx.x * blockDim.x;
if (index < n) {
result[index] = a[index] + b[index];
}
}
// CUDA kernel for vector addition with privatization
__global__ void vectorAddPrivatized(const float *a, const float *b, float *result, int n) {
int index = threadIdx.x + blockIdx.x * blockDim.x;
if (index < n) {
float a_private = a[index]; // Load into private memory
float b_private = b[index]; // Load into private memory
result[index] = a_private + b_private;
}
}
我们把a[index],b[index]加载到private memory里面避免对全局内存的直接操作,但在这个VectorAdd的例子中没有加速。
但是在下面的滑动窗口求和的例子中通过把global memory加载到shared memory中,然后进行累加时求和操作就是在shared memory中进行操作。
代码链接:https://github.com/cuda-mode/lectures/blob/main/lecture_008/privatization2.cu
// Kernel without privatization: Direct global memory access
__global__ void windowSumDirect(const float *input, float *output, int n, int windowSize) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int halfWindow = windowSize / 2;
if (idx < n) {
float sum = 0.0f;
for (int i = -halfWindow; i <= halfWindow; ++i) {
int accessIdx = idx + i;
if (accessIdx >= 0 && accessIdx < n) {
sum += input[accessIdx];
}
}
output[idx] = sum;
}
}
// Kernel with privatization: Preload window elements into registers
__global__ void windowSumPrivatized(const float *input, float *output, int n, int windowSize) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int halfWindow = windowSize / 2;
__shared__ float sharedData[1024]; // Assuming blockDim.x <= 1024
// Load input into shared memory (for demonstration, assuming window fits into shared memory)
if (idx < n) {
sharedData[threadIdx.x] = input[idx];
__syncthreads(); // Ensure all loads are complete
float sum = 0.0f;
for (int i = -halfWindow; i <= halfWindow; ++i) {
int accessIdx = threadIdx.x + i;
// Check bounds within shared memory
if (accessIdx >= 0 && accessIdx < blockDim.x && (idx + i) < n && (idx + i) >= 0) {
sum += sharedData[accessIdx];
}
}
output[idx] = sum;
}
}
作者最后讲的一点是以Flash Attention为例,如果你可以从数学的角度重写算法,有可能可以让代码的性能大幅度提升。比如Flash Attention利用Safe Softmax的数学形式分块计算Attention。这部分讲解已经非常多了,大家可以参考 https://github.com/BBuf/how-to-optim-algorithm-in-cuda/README.md 里面收集的Flash Attention相关的资料,最后这几张Slides就不再赘述了。
总结
这节课相当于对Lecture 1更系统的补充,重点介绍GPU kernel优化的一些实用技术和分析工具ncu。课程深入探讨了“性能检查清单”,概述了关键的优化策略:
- 合并全局内存访问: 确保线程访问连续的内存位置,以最大限度地提高内存带宽利用率。
- 最大化占用率: 优化kernel启动参数,以充分利用 GPU 的处理能力。
- 理解内存与计算限制: 分析kernel特征以确定限制因素(内存带宽或计算能力),并应用适当的优化技术。
- 最小化线程的分化: 避免导致warp内的线程采用不同执行路径的条件语句,从而导致性能下降。
- Tiling以重用数据: 组织数据访问模式,以最大限度地提高缓存中的数据局部性和重用率。
- 私有化: 利用私有内存(寄存器或共享内存)来减少全局内存访问并提高占用率。
- 线程粗化: 调整线程粒度以平衡工作负载并最小化线程开销。
- 算法重写: 探索替代的数学公式或算法以提高计算效率。
up主还通过cuda代码示例和使用 ncu 工具的分析结果来说明这些概念。它展示了内存合并、占用率优化和控制分歧最小化的好处。它还介绍了用于分析kernel性能瓶颈的 Roofline 模型,以及算术强度的概念,以确定kernel是受内存限制还是受计算限制。接着up主讨论了私有化技术,重点介绍了在滑动窗口算法中使用共享内存来改善数据局部性和减少全局内存访问。最后,简单描述了一下通过从数学角度重写算法来获得显著性能提升的潜力,并以 Flash Attention 为主要示例,这里就没有截最后几张slides了,毕竟Flash Attention的资料非常多了。