生成式人工智能如何重新定义零售盈利能力
欢迎来到雲闪世界。想象一下这样的购物体验:您上传了一张心仪服装或商品的照片。片刻之后,您便会收到来自您喜爱的商店的个性化、AI 驱动的类似商品推荐。这是一种革命性的零售体验,由一款创新应用实现,该应用将生成式 AI 的强大功能(特别是GPT-4 Vision 等多模态模型)与 MongoDB 强大的数据管理功能相结合。

这款应用不仅仅是一个概念,它已经变成了现实,改变了消费者发现产品的方式以及零售商与客户联系的方式。通过利用 GPT-4 Vision 的尖端功能进行图像分析和利用 MongoDB 进行高效数据处理,这款应用站在了智能产品发现新时代的前沿。
在本文中,我们将仔细研究这款应用的工作原理,剖析其代码以了解人工智能与数据库管理之间的相互作用。我们将探索它如何创造无缝且直观的用户体验,不仅让客户满意,还为零售商提供宝贵的见解。那么,让我们踏上这段技术探索之旅,了解这款应用如何重塑零售格局。
该应用程序在零售业的实际应用
该应用程序在零售业的实际应用
该应用程序的影响远远超出了技术创新的范围;它正在改变零售业格局。从小型精品店到大型百货商店,零售商都在利用这款应用程序以更有意义和个性化的方式与客户建立联系。
- 时尚零售:在时尚界,这款应用改变了游戏规则。用户上传他们喜欢的服装或配饰的图片,应用会从零售商的库存中提供类似的选择。这不仅提高了客户满意度,还增加了销售额,因为用户可以发现他们可能找不到的产品。

作者创作的动画(附注:我尝试使用 draw io 来实现动态边缘)
- 家具和家居装饰:对于家具和家居装饰零售商,该应用可帮助客户找到与其现有家具相匹配或互补的物品,从而打造出统一的室内设计体验。这增强了客户参与度并简化了购物流程。
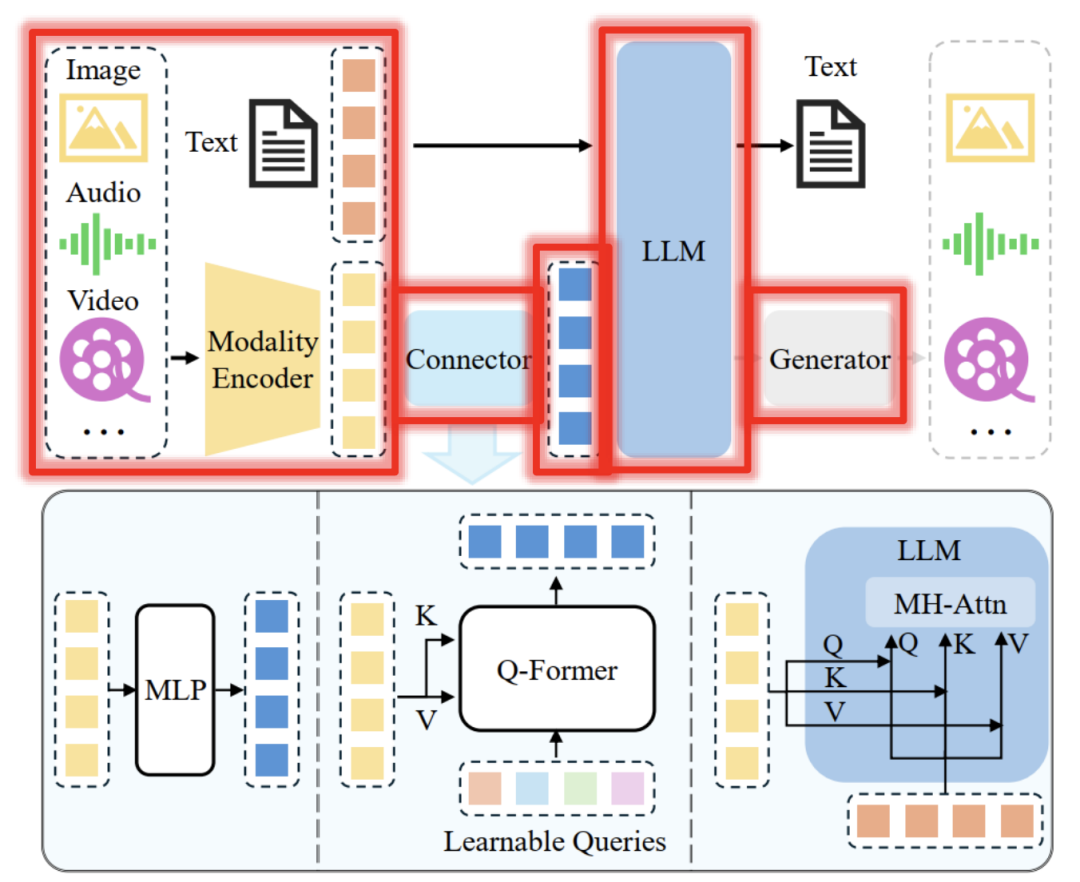
智能产品发现应用程序的架构概述
我们的智能产品发现应用程序的架构是一系列简化的交互和流程,旨在向用户提供精准的产品推荐。它的工作原理如下:

应用程序架构概述
- 用户互动:旅程从用户通过用户友好界面上传他们喜欢的产品图像开始。
- 图像分析:然后由 GPT-4 Vision 处理上传的图像,对图像进行分析以了解其内容和上下文。
- 向量嵌入:GPT-4 的分析被转换成向量嵌入,它们是适合数据库查询的数值表示。
- MongoDB 向量搜索:使用嵌入,MongoDB 在其产品目录中进行向量搜索,以查找视觉和上下文相似的项目。
- 产品推荐:然后向用户展示与其初始形象最接近的一系列产品。
这种架构不仅有利于实现当前的功能,而且还可扩展以适应未来的发展,为应用程序的运行提供强大的框架。
GPT-4 视觉的作用
生成式人工智能,尤其是 GPT-4 Vision,是这一革命性应用的核心。这一人工智能模型是 OpenAI 的一项创新,旨在以非凡的准确度处理和解读图像。GPT-4 Vision 的功能不仅限于图像识别;它擅长掌握上下文细微差别、精确定位复杂细节,甚至根据视觉内容生成富有洞察力的描述和建议。这种能力对于我们的应用至关重要,因为用户可以上传所需产品或服装的图片,并期待获得精确且相关的建议。
MongoDB 在管理数据和向量搜索方面的强大功能
MongoDB 以其作为 NoSQL 数据库的稳健性而闻名,在管理此应用程序所涉及的大量数据方面发挥着关键作用。它的灵活性、可扩展性和快速处理能力使其非常适合处理大型和多样化的数据集,这是零售应用程序中的常见情况。在我们的应用程序中,MongoDB 不仅存储详细的产品信息(包括图像和描述),而且还利用其矢量搜索功能。此功能使数据库能够根据从图像中派生的向量(数字数组)执行有效的搜索。通过将图像数据转换为矢量格式,MongoDB 可以快速筛选大量集合以找到在视觉上与用户上传的图像相似的产品,从而快速而精确地补充 AI 的分析。
零售业中人工智能与数据库管理的协同作用
GPT-4 Vision 与 MongoDB 的集成,尤其是后者的矢量搜索功能,为零售业提供了一个强大的工具。GPT-4 Vision 的高级图像分析功能使应用程序能够从上传的图像中辨别用户偏好,而 MongoDB 则高效地处理产品数据库,方便快速访问相关信息。这种双重功能不仅提升了用户体验,还为零售商提供了强大的工具,可以更准确地了解和满足客户的偏好。
使用 Streamlit、OpenAI 和 MongoDB 实现增强型产品发现
设置和用户交互功能
该应用程序用户界面的核心是使用 Streamlit 构建的,Streamlit 是一款使用 Python 创建交互式 Web 应用程序的强大工具。您的代码首先要导入基本库,包括 Streamlit ( st)、OpenAI 和 MongoDB ( MongoClient)。该应用程序利用 Streamlit 创建了一个用户友好的界面,用户可以在其中上传产品图像、与 AI 交互进行分析以及查看产品推荐。关键功能(如upload_photo和 )products_from_photo定义了核心用户交互,指导用户完成上传图像和接收 AI 驱动的洞察的过程。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#aa0d91">导入</span>streamlit<span style="color:#aa0d91">作为</span>st
<span style="color:#aa0d91">导入</span>openai
<span style="color:#aa0d91">从</span>openai<span style="color:#aa0d91">导入</span>OpenAI
<span style="color:#aa0d91">从</span>pymongo<span style="color:#aa0d91">导入</span>MongoClient
<span style="color:#aa0d91">导入</span>os
<span style="color:#aa0d91">导入</span>base64
<span style="color:#aa0d91">导入</span>请求
<span style="color:#aa0d91">导入</span>json
<span style="color:#007400"># MongoDB 和 OPENAI 设置</span>
MONGO_URI = os.environ[ <span style="color:#c41a16">"MONGO_URI"</span> ]
OPENAI_API_KEY = os.environ[ <span style="color:#c41a16">"OPENAI_API_KEY"</span> ]
<span style="color:#007400"># 使用 OpenAI 的 API 获取给定文本的嵌入的函数。</span>
<span style="color:#aa0d91">def </span> get_embedding ( <span style="color:#5c2699">text</span> ):
client = OpenAI()
response = client.embeddings.create(
<span style="color:#5c2699">input</span> =text,
model= <span style="color:#c41a16">"text-embedding-ada-002"</span>
)
<span style="color:#aa0d91">return</span> response.data[ <span style="color:#1c00cf">0</span> ].embedding
<span style="color:#007400"># 将图像编码为 base64 的函数</span>
<span style="color:#aa0d91">def </span> encode_image ( <span style="color:#5c2699">image_bytes</span> ):
<span style="color:#aa0d91">return</span> base64.b64encode(image_bytes).decode( <span style="color:#c41a16">'utf-8'</span> )
<span style="color:#007400"># 处理图像上传的函数</span>
<span style="color:#aa0d91">def </span> upload_photo ():
st.header( <span style="color:#c41a16">"上传您的产品照片"</span> )
<span style="color:#007400"># 创建列</span>
uploaded_image = st.file_uploader( <span style="color:#c41a16">"选择照片并上传"</span> , <span style="color:#5c2699">type</span> =[ <span style="color:#c41a16">'jpg'</span> , <span style="color:#c41a16">'png'</span> ])
col1, col2, col3 = st.columns([ <span style="color:#1c00cf">1</span> , <span style="color:#1c00cf">2</span> , <span style="color:#1c00cf">1</span> ]) <span style="color:#007400"># 根据需要调整比例</span>
<span style="color:#aa0d91">with</span> col1:
<span style="color:#007400"># 用于间距的空列</span>
st.write( <span style="color:#c41a16">""</span> )
<span style="color:#aa0d91">with</span> col2:
<span style="color:#007400"># 实际的文件上传器</span>
<span style="color:#aa0d91">if</span> uploaded_image<span style="color:#aa0d91">不是</span> <span style="color:#aa0d91">None</span> : <span style="color:#007400"># 将文件读取为字节:</span> bytes_data = uploaded_image.getvalue() #<span style="color:#aa0d91">将</span><span style="color:#007400">上传的图像保存到会话状态</span> st.session_state[ <span style="color:#c41a16">'uploaded_image'</span> ] = bytes_data <span style="color:#007400"># 转换为 Streamlit 可以用来显示图像的格式:</span> st.image(bytes_data, caption= <span style="color:#c41a16">'Uploaded photo'</span> , use_column_width= <span style="color:#aa0d91">True</span> ) <span style="color:#aa0d91">with</span> col3: <span style="color:#007400"># 用于间距的空列</span> st.write( <span style="color:#c41a16">""</span> )
</span></span></span></span>OpenAI 的 GPT-4 Vision 用于图像分析
该应用程序的一个关键方面是它与 OpenAI 的 GPT-4 Vision 模型的集成,这在以下函数中显而易见analyze_image。此功能获取用户上传的图像,将其编码为 base64 格式,然后将其发送到 GPT-4 模型进行分析。AI 模型会解释图像并提供详细的见解,然后将其用于增强用户对类似产品的搜索。GPT-4 Vision 的集成使该应用程序能够以复杂而细致的方式理解和处理用户偏好。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#007400"># 使用 OpenAI 的 GPT-4 Vision 模型分析图像的函数</span>
<span style="color:#aa0d91">def </span> analyze_image ( <span style="color:#5c2699">image_bytes, user_prompt</span> ):
<span style="color:#007400"># 将图像转换为 base64 字符串</span>
base64_image = encode_image(image_bytes)
<span style="color:#007400"># OpenAI API 密钥 - 确保用您的实际 API 密钥替换“YOUR_OPENAI_API_KEY”</span>
api_key = OPENAI_API_KEY
headers = {
<span style="color:#c41a16">“Content-Type”</span>:<span style="color:#c41a16">“application/json”</span>,
<span style="color:#c41a16">“Authorization”</span>:<span style="color:#c41a16">f“Bearer <span style="color:#000000">{api_key}</span> ”</span>
}
payload = {
<span style="color:#c41a16">“model”</span>:<span style="color:#c41a16">“gpt-4-vision-preview”</span>,
<span style="color:#c41a16">“messages”</span>:[
{
<span style="color:#c41a16">“role”</span>:<span style="color:#c41a16">“user”</span>,
<span style="color:#c41a16">“content”</span>:[
{
<span style="color:#c41a16">“type”</span>:<span style="color:#c41a16">“text”</span>,
<span style="color:#c41a16">“text”</span>:user_prompt <span style="color:#007400"># 用户提示替换静态问题</span>
},
{
<span style="color:#c41a16">“type”</span>:<span style="color:#c41a16">“image_url”</span>,
<span style="color:#c41a16">“image_url”</span>:{
<span style="color:#c41a16">“url”</span>:<span style="color:#c41a16">f"data:image/jpeg;base64, <span style="color:#000000">{base64_image}</span> "</span> ,
<span style="color:#c41a16">"detail"</span> : <span style="color:#c41a16">"high"</span>
}
}
]
}
],
<span style="color:#c41a16">"max_tokens"</span> : <span style="color:#1c00cf">300</span>
}
<span style="color:#007400"># 向 OpenAI API 发送发布请求</span>
response = request.post( <span style="color:#c41a16">"https://api.openai.com/v1/chat/completions"</span> , headers=headers, json=payload)
<span style="color:#5c2699">print</span> (response)
response_js = response.json()
<span style="color:#007400"># 从第一个选择中提取内容</span>
content = response_js.get( <span style="color:#c41a16">'choices'</span> , [{}])[ <span style="color:#1c00cf">0</span> ].get( <span style="color:#c41a16">'message'</span> , {}).get( <span style="color:#c41a16">'content'</span> , <span style="color:#c41a16">''</span> )
<span style="color:#007400"># 确保响应正常</span>
<span style="color:#aa0d91">if</span> response.status_code == <span style="color:#1c00cf">200</span> :
<span style="color:#aa0d91">try</span> :
response_js = response.json()
<span style="color:#007400"># 提取内容</span>
content = response_js.get( <span style="color:#c41a16">'choices'</span> , [{}])[ <span style="color:#1c00cf">0</span> ].get( <span style="color:#c41a16">'消息'</span> , {}).get( <span style="color:#c41a16">'内容'</span> ,<span style="color:#c41a16">''</span> )
<span style="color:#007400"># 查找 JSON 对象的开始和结束</span>
json_start_index = content.find( <span style="color:#c41a16">'{'</span> )
json_end_index = content.rfind(<span style="color:#c41a16">'}'</span> )
<span style="color:#aa0d91">if</span> json_start_index != - <span style="color:#1c00cf">1 </span> <span style="color:#aa0d91">and</span> json_end_index != - <span style="color:#1c00cf">1</span> :
<span style="color:#007400"># 仅提取有效的 JSON 部分</span>
content = content[json_start_index:json_end_index+ <span style="color:#1c00cf">1</span> ]
<span style="color:#007400"># 调试:打印内容</span>
<span style="color:#5c2699">print</span> ( <span style="color:#c41a16">"收到内容:"</span> , content)
<span style="color:#aa0d91">if</span> content:
<span style="color:#007400"># 将内容解析为 JSON</span>
content_dict = json.loads(content)
product_list = content_dict.get( <span style="color:#c41a16">'product_list'</span> , {})
st.session_state[ <span style="color:#c41a16">'product_list'</span> ] = product_list
<span style="color:#aa0d91">if </span> <span style="color:#aa0d91">not </span> <span style="color:#5c2699">isinstance</span> (product_list, <span style="color:#5c2699">dict</span> ):
<span style="color:#5c2699">print</span> ( <span style="color:#c41a16">"product_list 不是字典。"</span> )
<span style="color:#aa0d91">return</span> {}
<span style="color:#aa0d91">return</span> product_list
<span style="color:#aa0d91">else</span> :
<span style="color:#5c2699">print</span> ( <span style="color:#c41a16">"响应中未收到任何内容。"</span> )
<span style="color:#aa0d91">return</span> {}
<span style="color:#aa0d91">except</span> json.JSONDecodeError <span style="color:#aa0d91">as</span> e:
<span style="color:#5c2699">print</span> ( <span style="color:#c41a16">"无法解码 JSON:"</span> , e)
<span style="color:#aa0d91">return</span> {}
<span style="color:#aa0d91">else</span> :
<span style="color:#5c2699">print</span> ( <span style="color:#c41a16">f"API 请求失败,状态代码为:<span style="color:#000000">{response.status_code}</span> “</span>)
<span style="color:#aa0d91">返回</span>{}</span></span></span></span>MongoDB 集成用于数据管理和向量搜索
该应用程序巧妙地集成了 MongoDB,以实现有效的数据管理。该connect_mongodb功能与存储产品数据的 MongoDB 数据库建立连接。然后查询该数据库以根据 AI 的分析检索相关产品信息。该功能利用了 MongoDB 强大的向量搜索功能,find_similar_documents改变了游戏规则。它允许应用程序根据 GPT-4 模型生成的向量表示(嵌入)对类似产品进行有效搜索,从而确保产品推荐的准确性和相关性。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#007400"># 连接到 MongoDB 服务器并返回集合。def </span>
<span style="color:#aa0d91">connect_mongodb</span> (): mongo_client = MongoClient(MONGO_URI) db = mongo_client[ <span style="color:#c41a16">"produit"</span> ] collection = db[ <span style="color:#c41a16">"retailProducts"</span> ] <span style="color:#aa0d91">return</span> collection # 函数根据提供的<span style="color:#007400">嵌入在 MongoDB 中查找类似文档。</span><span style="color:#aa0d91">def </span>find_similar_documents ( <span style="color:#5c2699">embedding</span> ): collection = connect_mongodb() documents = <span style="color:#5c2699">list</span> (collection.aggregate([ { <span style="color:#c41a16">“$vectorSearch”</span>:{ <span style="color:#c41a16">“index”</span>:<span style="color:#c41a16">“vector_index”</span>,<span style="color:#c41a16">“path”</span>:<span style="color:#c41a16">“nameEmbeddings”</span>,<span style="color:#c41a16">“queryVector”</span>:embedding,<span style="color:#c41a16">“numCandidates”</span>:<span style="color:#1c00cf">10</span>,<span style="color:#c41a16">“limit”</span>:<span style="color:#1c00cf">1</span> } }, { <span style="color:#c41a16">“$project”</span>:{ <span style="color:#c41a16">“_id”</span>:<span style="color:#1c00cf">0</span>,<span style="color:#c41a16">“name”</span>:<span style="color:#1c00cf">1</span>,<span style="color:#c41a16">“subcategory”</span>:<span style="color:#1c00cf">1</span>,<span style="color:#c41a16">“model”</span>:<span style="color:#1c00cf">1</span>,<span style="color:#c41a16">“id”</span>:<span style="color:#1c00cf">1</span>,<span style="color:#c41a16">“variation_0_image”</span>:<span style="color:#1c00cf">1</span>,<span style="color:#c41a16">“raw_price”</span>:<span style="color:#1c00cf">1</span> }} ]))<span style="color:#5c2699">打印</span>(documents)<span style="color:#aa0d91">返回</span>文档
</span></span></span></span>Vector Search:增强产品匹配
向量搜索是一项关键功能,使该应用程序能够找到在视觉和上下文上符合用户兴趣的产品。该应用程序使用 OpenAI 的 GPT-4 为文本描述创建嵌入,然后 MongoDB 使用该嵌入进行向量搜索。该过程在函数中很明显product_Recommandation,其中生成嵌入并用于查询 MongoDB 中的类似项目。这种方法可确保应用程序的产品建议高度相关且与用户的初始图像查询紧密相关。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#aa0d91">def </span> product_Recommandation ( <span style="color:#5c2699">product_list</span> ):
<span style="color:#007400"># 为搜索结果初始化一个空列表</span>
search_results = []
<span style="color:#007400"># 检查 product_list 是否有效</span>
<span style="color:#aa0d91">if </span> <span style="color:#aa0d91">not </span> <span style="color:#5c2699">isinstance</span> (product_list, <span style="color:#5c2699">dict</span> ):
<span style="color:#5c2699">print</span> ( <span style="color:#c41a16">"无效的产品列表。应为字典。"</span> )
<span style="color:#aa0d91">return</span> search_results
<span style="color:#007400"># 遍历列表中的产品</span>
<span style="color:#aa0d91">for</span> key, value <span style="color:#aa0d91">in</span> product_list.items():
result = <span style="color:#c41a16">f" <span style="color:#000000">{key}</span> : <span style="color:#000000">{value}</span> \n" </span>
<span style="color:#5c2699">print</span> (result)
product_embedding = get_embedding(result)
<span style="color:#5c2699">print</span> ( <span style="color:#c41a16">f"正在搜索:<span style="color:#000000">{key}</span> : <span style="color:#000000">{value}</span> "</span> )
documents = find_similar_documents(product_embedding)
<span style="color:#007400"># 将找到的文档添加到搜索结果中</span>
search_results.extend(documents)
<span style="color:#007400"># 返回找到的文档列表</span>
<span style="color:#aa0d91">return</span> search_results</span></span></span></span>在 MongoDB 上创建向量搜索索引以查找类似产品。

<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">{
<span style="color:#836c28">“fields” </span>: [
{
<span style="color:#836c28">“numDimensions” </span>: <span style="color:#1c00cf">1536 </span>,
<span style="color:#836c28">“path” </span>: <span style="color:#c41a16">“nameEmbeddings” </span>,
<span style="color:#836c28">“similarity” </span>: <span style="color:#c41a16">“余弦” </span>,
<span style="color:#836c28">“type” </span>: <span style="color:#c41a16">“vector” </span>
}
]
}</span></span></span></span>用户界面演练
该应用由 Streamlit 提供支持,界面简洁直观,可引导用户完成无缝的产品发现之旅。从用户与应用交互的那一刻起,他们就会看到一个简单的菜单,这要归功于 Streamlit 的侧边栏功能。选项 — “上传照片”、“照片中的产品”和“显示产品” — 一目了然,即使是技术专业知识最少的人也可以使用该应用。
- 上传图片:该
upload_photo功能是用户的起点。在这里,他们可以轻松上传他们感兴趣的产品的照片。该应用程序使用 Streamlit 的文件上传器,支持各种图像格式,确保用户可以轻松上传图像。 - 人工智能驱动的产品分析:一旦上传图片,该
products_from_photo功能就会接管。用户可以在文本区域中输入他们的查询或偏好,启动 GPT-4 Vision 模型来分析图片。此功能体现了该应用程序将人工智能的复杂性与用户的简单性相结合的能力。 - 产品推荐:用户旅程的最后一步是查看产品。该
show_products功能显示 MongoDB 矢量搜索的结果,为用户提供类似产品的列表,并附有图片和说明。此功能不仅展示了该应用程序的技术实力,还展示了其对用户满意度的关注。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">
<span style="color:#007400"># 处理图像上传的函数</span>
<span style="color:#aa0d91">def </span> upload_photo ():
st.header( <span style="color:#c41a16">"上传您的产品照片"</span> )
<span style="color:#007400"># 创建列</span>
uploaded_image = st.file_uploader( <span style="color:#c41a16">"选择照片并上传"</span> , <span style="color:#5c2699">type</span> =[ <span style="color:#c41a16">'jpg'</span> , <span style="color:#c41a16">'png'</span> ])
col1, col2, col3 = st.columns([ <span style="color:#1c00cf">1</span> , <span style="color:#1c00cf">2</span> , <span style="color:#1c00cf">1</span> ]) <span style="color:#007400"># 根据需要调整比例</span>
<span style="color:#aa0d91">with</span> col1:
<span style="color:#007400"># 用于间距的空列</span>
st.write( <span style="color:#c41a16">""</span> )
<span style="color:#aa0d91">with</span> col2:
<span style="color:#007400"># 实际的文件上传器</span>
<span style="color:#aa0d91">if</span> uploaded_image<span style="color:#aa0d91">不是</span> <span style="color:#aa0d91">None</span> : <span style="color:#007400"># 将文件读取为字节:</span><span style="color:#aa0d91">bytes_data</span> = uploaded_image.getvalue() <span style="color:#007400"># 将上传的图像保存到会话状态</span> st.session_state[ <span style="color:#c41a16">'uploaded_image'</span> ] = bytes_data <span style="color:#007400"># 转换为 Streamlit 可以用来显示图像的格式:</span> st.image(bytes_data, caption= <span style="color:#c41a16">'上传的照片'</span> , use_column_width= <span style="color:#aa0d91">True</span> ) <span style="color:#aa0d91">with</span> col3:<span style="color:#007400"># 用于间距的空列</span> st.write( <span style="color:#c41a16">“”</span> ) <span style="color:#007400"># 用于处理聊天机器人交互和产品提取的函数</span><span style="color:#aa0d91">def </span>products_from_photo(): st.header(<span style="color:#c41a16">“从您的照片中提取产品”</span>) user_prompt =(<span style="color:#c41a16">“您是一个有用的AI助手,从照片中提取服装产品,每种产品都采用单独的JSON格式,“ </span><span style="color:#c41a16">”用法语简单描述和颜色。 " </span><span style="color:#c41a16">"您应该严格遵循格式,但不是内容:" </span><span style="color:#c41a16">"```{\"product_list\": {\"{产品类别}\": \"{产品描述}\", \"{产品类别}\": " </span><span style="color:#c41a16">"\"{产品描述}\", \"{产品类别}\": \"{产品描述}\", " </span><span style="color:#c41a16">"\"{产品类别}\": \"{产品描述}\"}```"</span> ) user_input = st.text_area( <span style="color:#c41a16">"要求AI提取服装细节:"</span> , user_prompt, height= <span style="color:#1c00cf">200</span> ) <span style="color:#007400"># 从会话状态中检索上传的图像</span> bytes_data = st.session_state.get( <span style="color:#c41a16">'uploaded_image'</span> , <span style="color:#aa0d91">None</span> ) <span style="color:#aa0d91">if</span> bytes_data: st.write( <span style="color:#c41a16">"图像存在。</span>" ) col1, col2, col3 = st.columns([ <span style="color:#1c00cf">1</span> , <span style="color:#1c00cf">2</span> , <span style="color:#1c00cf">1</span> ])
<span style="color:#007400"># 根据需要调整比例</span>
<span style="color:#aa0d91">with</span> col1:
<span style="color:#007400"># 用于间隔的空列</span>
st.write( <span style="color:#c41a16">""</span> )
<span style="color:#aa0d91">with</span> col2:
<span style="color:#007400"># 实际文件上传者</span>
st.image(bytes_data, caption= <span style="color:#c41a16">'Uploaded Outfit'</span> , use_column_width= <span style="color:#aa0d91">True</span> )
<span style="color:#aa0d91">with</span> col3:
<span style="color:#007400"># 用于间隔的空列</span>
st.write( <span style="color:#c41a16">""</span> )
<span style="color:#aa0d91">else</span> :
st.write( <span style="color:#c41a16">"尚未上传图像。"</span> )
<span style="color:#aa0d91">if</span> st.button( <span style="color:#c41a16">"Extract"</span> ):
<span style="color:#aa0d91">如果</span>bytes_data<span style="color:#aa0d91">不是</span> <span style="color:#aa0d91">None</span> <span style="color:#aa0d91">并且</span>user_input: <span style="color:#007400"># 使用图像字节和用户提示调用 analyze_image 函数</span> result = analyze_image(bytes_data, user_input) <span style="color:#aa0d91">#</span> <span style="color:#007400">处理结果并提取服装元素描述</span><span style="color:#007400"># 结果处理将取决于响应的结构</span> st.write(result) <span style="color:#007400"># 用于显示原始结果的占位符</span><span style="color:#007400"># 用于显示推荐产品的函数</span><span style="color:#aa0d91">def </span>show_products (): st.header( <span style="color:#c41a16">"Show Products from Vector Search"</span> ) <span style="color:#007400"># 检查 'product_list' 是否可用在会话状态中</span><span style="color:#aa0d91">if </span><span style="color:#c41a16">'product_list' </span><span style="color:#aa0d91">in</span> st.session_state <span style="color:#aa0d91">and</span> st.session_state[ <span style="color:#c41a16">'product_list'</span> ]: product_list = st.session_state[ <span style="color:#c41a16">'product_list'</span> ] <span style="color:#007400"># 假设 product_list 是一个字典</span><span style="color:#aa0d91">if </span><span style="color:#5c2699">isinstance</span> (product_list, <span style="color:#5c2699">dict</span> ): st.subheader( <span style="color:#c41a16">"Current Product List:"</span> ) <span style="color:#007400"># 临时字典存储修改</span> modified_product_list = {} <span style="color:#aa0d91">for</span> category, description <span style="color:#aa0d91">in</span> product_list.items(): st.text( <span style="color:#c41a16">f"Category: </span><span style="color:#c41a16"><span style="color:#000000">{category}</span></span><span style="color:#c41a16"> "</span> ) modified_description = st.text_area( <span style="color:#c41a16">f"Modify description for </span><span style="color:#c41a16"><span style="color:#000000">{category}</span></span><span style="color:#c41a16"> "</span> , value=description) modified_product_list[category] = modified_description <span style="color:#aa0d91">if</span> st.button( <span style="color:#c41a16">"Update and Search Similar Products"</span> ): <span style="color:#007400"># 使用修改后的产品列表更新会话状态</span> st.session_state[ <span style="color:#c41a16">'product_list'</span> ] = modified_product_list <span style="color:#007400"># 使用更新后的产品列表调用 product_Recommandation 函数</span>
vector_search_results = product_Recommandation(modified_product_list)
<span style="color:#007400"># 显示搜索结果</span>
<span style="color:#aa0d91">if</span> vector_search_results:
st.subheader( <span style="color:#c41a16">"搜索结果:"</span> )
st.subheader( <span style="color:#c41a16">"搜索结果:"</span> )
<span style="color:#aa0d91">for</span> product <span style="color:#aa0d91">in</span> vector_search_results:
product_name = product.get( <span style="color:#c41a16">"name"</span> , <span style="color:#c41a16">"未知产品名称"</span> )
product_subcategory = product.get( <span style="color:#c41a16">'subcategory'</span> , <span style="color:#c41a16">'未知'</span> )
product_image_url = product.get( <span style="color:#c41a16">"variation_0_image"</span> , <span style="color:#c41a16">""</span> )
<span style="color:#007400"># 调试:打印图片网址</span>
<span style="color:#5c2699">print</span> ( <span style="color:#c41a16">"尝试显示图片网址:"</span> , product_image_url)
st.write(product_name)
st.write( <span style="color:#c41a16">f"子类别:<span style="color:#000000">{product_subcategory}</span> "</span> )
<span style="color:#007400"># 如果网址存在,则显示图片</span>
<span style="color:#aa0d91">if</span> product_image_url:
<span style="color:#aa0d91">try</span> :
col1, col2, col3 = st.columns([ <span style="color:#1c00cf">1</span> , <span style="color:#1c00cf">2</span> , <span style="color:#1c00cf">1</span> ]) <span style="color:#007400"># 根据需要调整比例</span>
<span style="color:#aa0d91">with</span> col1:
<span style="color:#007400"># 空列用于间隔</span>
st.write( <span style="color:#c41a16">""</span> )
<span style="color:#aa0d91">with</span> col2:
<span style="color:#007400"># 实际的文件上传者</span>
st.image(product_image_url, caption=product_name, use_column_width= <span style="color:#aa0d91">True</span> )
<span style="color:#aa0d91">with</span> col3:
<span style="color:#007400"># 空列用于间隔</span>
st.write( <span style="color:#c41a16">""</span> )
<span style="color:#aa0d91">except</span> Exception <span style="color:#aa0d91">as</span> e:
st.error( <span style="color:#c41a16">f"显示图像时出错:<span style="color:#000000">{e}</span> "</span> )
<span style="color:#aa0d91">else</span> :
st.write( <span style="color:#c41a16">"此产品没有可用图像。"</span> )
<span style="color:#007400">#st.write(product.get("name", "未知产品名称")) </span>
<span style="color:#007400">#st.write(f"子类别: {product.get('subcategory', 'Unknown')}") </span>
<span style="color:#007400">#st.image(product.get("image_url", ""), caption=product.get("name", "产品名称"), use_column_width=True) </span>
<span style="color:#aa0d91">else</span> :
st.write( <span style="color:#c41a16">"未找到类似产品。</span>“ )
<span style="color:#aa0d91">否则</span>:
st.error(<span style="color:#c41a16">“产品列表的格式不符合要求,请检查数据源。”</span> )
<span style="color:#aa0d91">else</span> :
st.write( <span style="color:#c41a16">“未找到产品列表,请先分析一张图片。”</span> )</span></span></span></span>您可以在我的 Github 上找到完整代码:GitHub - cozypet/multimodalProductsFinder
展示应用程序的界面和功能
该应用程序的界面展示了以用户为中心的设计和功能。通过一系列屏幕截图,我们可以直观地看到从图片上传到产品推荐的无缝过程。
主页 — 欢迎垫
主页是一个简洁、易于导航的起点,邀请用户探索应用程序的各种功能,如人工智能分析和交互式推荐。

主页
上传——第一次互动
上传页面非常简单,提供简单的拖放或文件选择方法,供用户上传他们想要找到的产品图像。

分析——人工智能驱动的洞察
在分析部分,用户提示人工智能从他们的照片中提取产品详细信息,突出显示该应用程序实时响应的人工智能集成。


结果 — 发现产品
最后,结果页面向用户展示应用程序识别的视觉上相似的产品,并包含详细信息和查看更多内容的选项,有效地展示了应用程序的端到端功能。



结论
零售业中 AI 与 MongoDB 的整合展示了提高投资回报率的明确途径。通过个性化购物体验,这项技术不仅可以提高销售额,还可以培养客户忠诚度。利用此类应用程序的零售商可以期望在竞争激烈的数字市场中实现更高的效率、更高的转化率,并最终实现更强劲的财务业绩。
感谢关注雲闪世界。(Aws解决方案架构师vs开发人员&GCP解决方案架构师vs开发人员)
订阅频道(https://t.me/awsgoogvps_Host)
TG交流群(t.me/awsgoogvpsHost)