**【导读】**多模态大模型主要是以LLM作为核心决策模块,主流架构有两种:LLM as Discrete Scheduler/Controller和LLM as joint part of system,第一种LLM充当任务调度的作用,第二种LLM通过Encoder-LLM-Decoder结构作为系统的关键连接部分,天花板更高。
01
MLLM架构起源
1. 基本idea:以大语言模型(LLM)作为支点
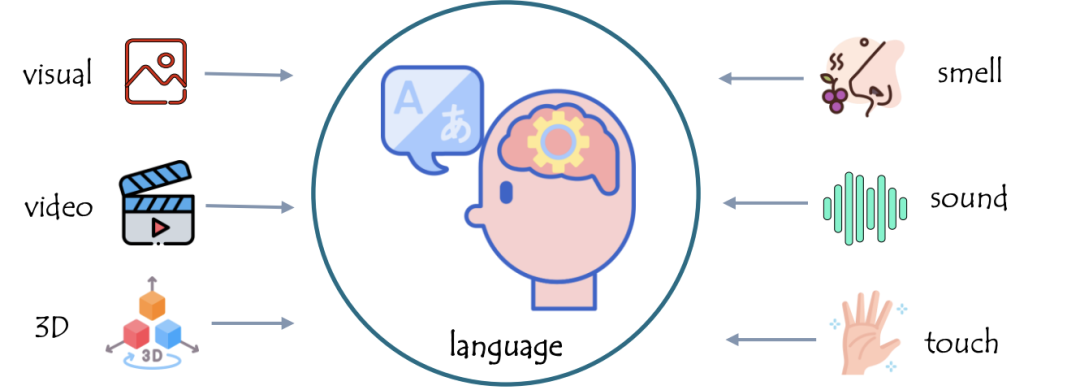
鉴于这一前提,几乎所有当前的MLLM都是基于大语言模型(LLM)构建的,作为核心决策模块(即大脑或中央处理器)。
通过添加额外的非文本模态模块,LLM具有多模态能力。
02
MLLM基本结构
1. LLM as Discrete Scheduler/Controller
LLM 角色是接受文本信号,下发调度下游模块的文本命令
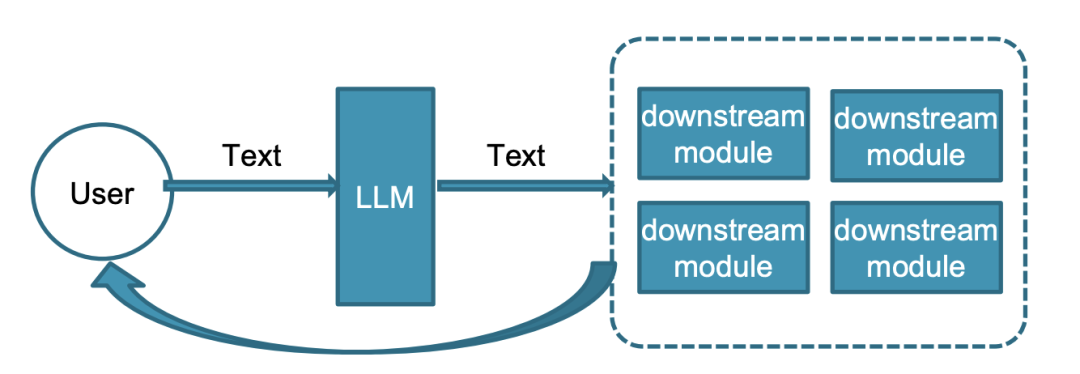
代表模型:
-
Visual-ChatGPT
-
HuggingGPT
-
MM-REACT
-
ViperGPT
-
AudioGPT
-
LLaVA-Plus

2. LLM as joint part of system
LLM的角色是感知多模态信息,通过Encoder-LLM-Decoder 结构做出反应
**关键特点:**LLM是系统的关键连接部分,直接从外部接收多模态信息,并以更流畅的方式将指令传递给解码器/生成器。
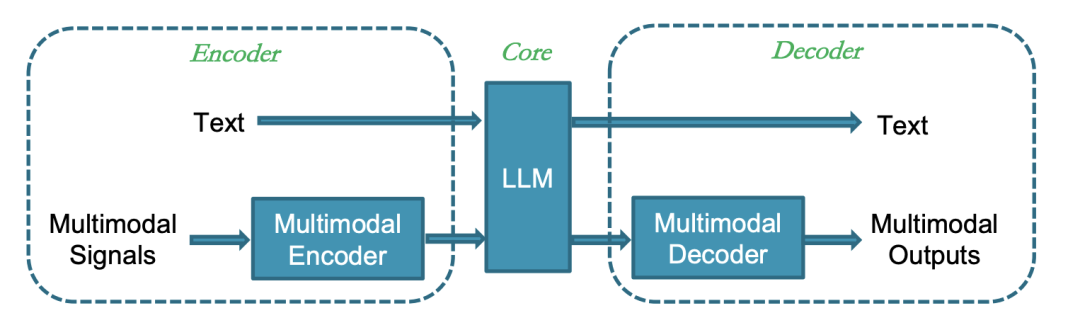
目前超过90% 的 MLLM 属于该类别,天花板更高,更好的集成到一个统一模型,如下是MLLM的经典架构:
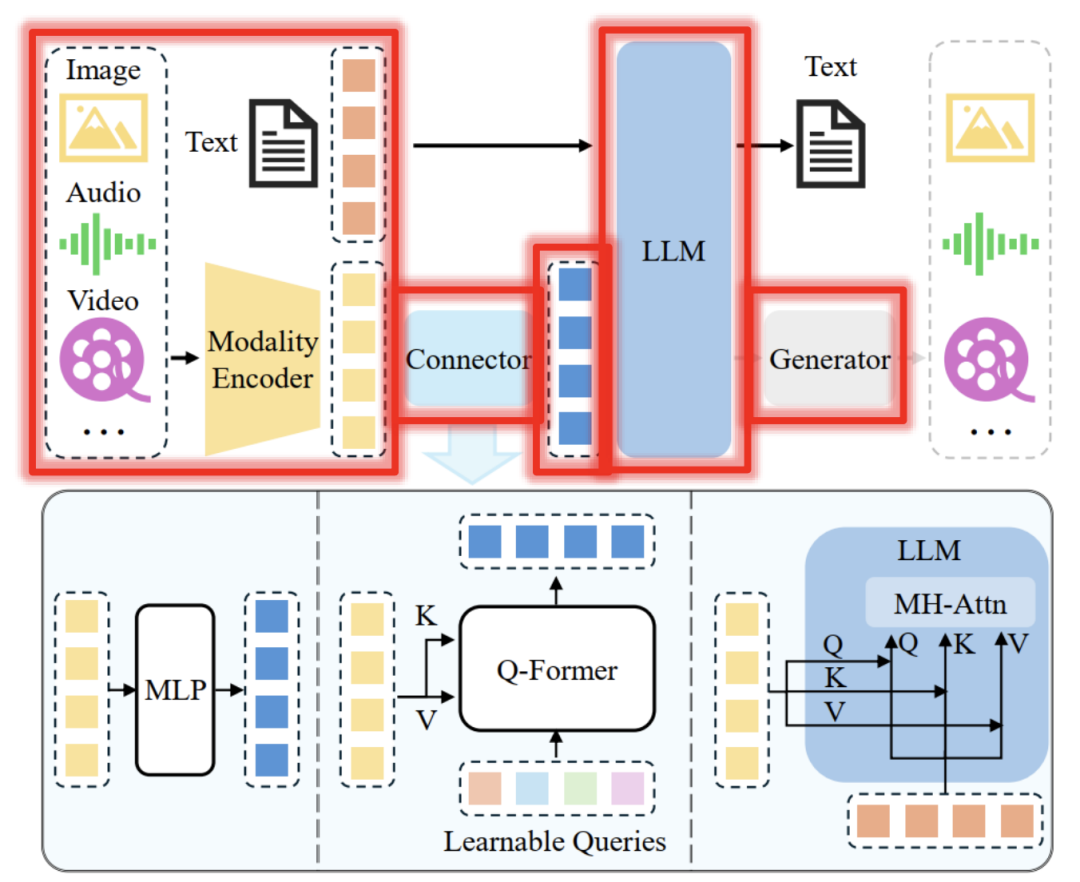
代表模型:
-
BLIP-2
-
InstructBLIP
-
LLAVA
-
Flamingo
-
Qwen-VL
该架构中包含的子模块主要有:Multimodal Encoding、Input-side Projection、Backbone LLMs、Decoding-side Projection、Multimodal Generaton。