前言
近期,SD(Stable Diffusion)原班人马(跳槽后新成立团队——Black Forest Lab)开源模型 FLUX.1,或成文生图模型新霸主!
FLUX.1 系列包含 pro、dev、schnell 3 个模型。主要在文字生成、复杂指令遵循和人手生成上具备优势。
FLUX.1pro:FLUX.1中最先进的,具有顶级的即时提示词遵循、视觉质量、图像细节和输出多样性,面向专业用户提供定制的企业解决方案。
FLUX.1dev:从FLUX.1[pro]蒸馏而来,具有相似的质量和能力,同时比相同尺寸的标准模型更高效,多面向非商业应用。
FLUX.1schnell:最快模型,适合本地开发和个人使用。

所有的AI设计工具,模型和插件,都已经整理好了,👇获取~
对于下一步工作,团队表示将推出基于 FLUX.1 的 SOTA 文生视频模型,预示着一场视觉盛宴的即将开启,让我们共同期待其带来的全新震撼体验!
同时,本文精心策划,深入挖掘并汇聚了一系列顶尖的开源Text-to-Image生成模型,旨在为科研工作者打造一把高效利器,促进其在探索之旅中取得更加辉煌的成就。
Stable Diffusion
Stable Diffusion 各版本升级亮点:
-
v1:基础的文字生成图像(文生图)功能,可以通过输入关键词或描述来生成对应的图像。
-
v2:引入 OpenCLIP,提升画质至 768x768(兼容512x512),新增 Depth2img 与优化 inpainting,全面提升质量与速度。
-
v3:采用 Sora 相似技术(Diffusion Transformer),增强扩展性,支持视频、3D等多类型内容创作。
开源团队:Stabililty AI

-
中文介绍:https://zhuanlan.zhihu.com/p/669570827
-
开源地址v1:https://github.com/CompVis/stable-diffusion
-
开源地址v2:https://github.com/Stability-AI/stablediffusion
Kandinsky
Kandinsky3.0:升级版文本转图像技术,实现更高质量、真实感的图像生成,模型总参数达到了 119 亿(11.9B),约是 Kandinsky 家族先前模型中最大模型的三倍。
开源团队:俄罗斯 AI 研究团队 AI Forever
应用:Inpainting、Outpainting、Image-to-Video Generation、Text-to-Video、text-to-image、Deforum

Hunyuan-DiT
Hunyuan-DiT 是由腾讯开源的高性能细粒度中文理解多分辨率扩散 Transformer 模型。Sora 同架构,支持中英文双语输入及理解,参数量15亿,并且可免费商用。
特点:
-
首个中英双语DiT架构
-
支持中文元素理解
-
支持长文本理解能力
-
支持细粒度语义理解
-
支持多轮对话文生图


PixArt
PixArt各版本升级亮点:
-
PixArt-α:高质量、低成本的文生图模型,训练时长只有 SD 1.5 的 10.8%。
-
PIXART-δ: Pixart 家族的Controlent,为 DiT 模型引入可控生成能力,可在 8GB GPU上合成 1024px 图像,可定位为SD 模型的平替。
-
PixArt-Σ:生成 4K 图像,在保持较小模型大小(0.6B参数)的同时,实现了优于现有文本到图像扩散模型(如SDXL和SD Cascade)的图像质量和用户提示遵循能力。
开源团队:华为

这里分享给大家一份Adobe大神整理的《AIGC全家桶学习笔记》,相信大家会对AIGC有着更深入、更系统的理解。
有需要的朋友,可以点击下方免费领取!

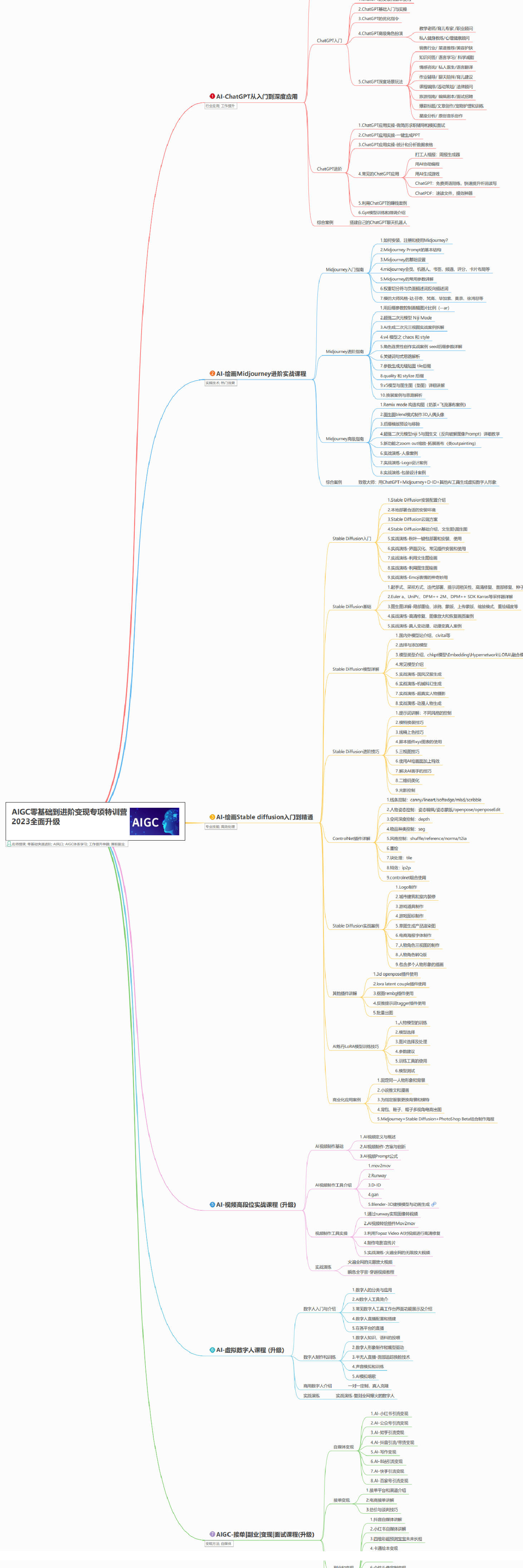
AIGC所有方向的学习路线思维导图
这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。如果下面这个学习路线能帮助大家将AI利用到自身工作上去,那么我的使命也就完成了:
AIGC工具库
AIGC工具库是一个利用人工智能技术来生成应用程序的代码和内容的工具集合,通过使用AIGC工具库,能更加快速,准确的辅助我们学习AIGC

有需要的朋友,可以点击下方卡片免费领取!

精品AIGC学习书籍手册
书籍阅读永不过时,阅读AIGC经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验,结合自身案例融会贯通。
AI绘画视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,科学有趣才能更方便的学习下去。