多任务多标签模型是现代机器学习中的基础架构,这个任务在概念上很简单 -训练一个模型同时预测多个任务的多个输出。
在本文中,我们将基于流行的 MovieLens 数据集,使用稀疏特征来创建一个多任务多标签模型,并逐步介绍整个过程。所以本文将涵盖数据准备、模型构建、训练循环、模型诊断,最后使用 Ray Serve 部署模型的全部流程。
1. 设置环境
在深入代码之前,请确保安装了必要的库(以下不是详尽列表):
pip install pandas scikit-learn torch ray[serve] matplotlib requests tensorboard
我们在这里使用的数据集足够小,所以可以使用 CPU 进行训练。
2. 准备数据集
我们将从创建用于处理 MovieLens 数据集的下载、预处理的类开始,然后将数据分割为训练集和测试集。
MovieLens数据集包含有关用户、电影及其评分的信息,我们将用它来预测评分(回归任务)和用户是否喜欢这部电影(二元分类任务)。
importos
importpandasaspd
fromsklearn.model_selectionimporttrain_test_split
fromsklearn.preprocessingimportLabelEncoder
importtorch
fromtorch.utils.dataimportDataset, DataLoader
importzipfile
importio
importrequests
classMovieLensDataset(Dataset):
def__init__(self, dataset_version="small", data_dir="data"):
print("Initializing MovieLensDataset...")
ifnotos.path.exists(data_dir):
os.makedirs(data_dir)
ifdataset_version=="small":
url="https://files.grouplens.org/datasets/movielens/ml-latest-small.zip"
local_zip_path=os.path.join(data_dir, "ml-latest-small.zip")
file_path='ml-latest-small/ratings.csv'
parquet_path=os.path.join(data_dir, "ml-latest-small.parquet")
elifdataset_version=="full":
url="https://files.grouplens.org/datasets/movielens/ml-latest.zip"
local_zip_path=os.path.join(data_dir, "ml-latest.zip")
file_path='ml-latest/ratings.csv'
parquet_path=os.path.join(data_dir, "ml-latest.parquet")
else:
raiseValueError("Invalid dataset_version. Choose 'small' or 'full'.")
ifos.path.exists(parquet_path):
print(f"Loading dataset from {parquet_path}...")
movielens=pd.read_parquet(parquet_path)
else:
ifnotos.path.exists(local_zip_path):
print(f"Downloading {dataset_version} dataset from {url}...")
response=requests.get(url)
withopen(local_zip_path, "wb") asf:
f.write(response.content)
withzipfile.ZipFile(local_zip_path, "r") asz:
withz.open(file_path) asf:
movielens=pd.read_csv(f, usecols=['userId', 'movieId', 'rating'], low_memory=True)
movielens.to_parquet(parquet_path, index=False)
movielens['liked'] = (movielens['rating'] >=4).astype(int)
self.user_encoder=LabelEncoder()
self.movie_encoder=LabelEncoder()
movielens['user'] =self.user_encoder.fit_transform(movielens['userId'])
movielens['movie'] =self.movie_encoder.fit_transform(movielens['movieId'])
self.train_df, self.test_df=train_test_split(movielens, test_size=0.2, random_state=42)
defget_data(self, split="train"):
ifsplit=="train":
data=self.train_df
elifsplit=="test":
data=self.test_df
else:
raiseValueError("Invalid split. Choose 'train' or 'test'.")
dense_features=torch.tensor(data[['user', 'movie']].values, dtype=torch.long)
labels=torch.tensor(data[['rating', 'liked']].values, dtype=torch.float32)
returndense_features, labels
defget_encoders(self):
returnself.user_encoder, self.movie_encoder
定义了
MovieLensDataset
,就可以将训练集和评估集加载到内存中
# Example usage with a single dataset object
print("Creating MovieLens dataset...")
# Feel free to use dataset_version="full" if you are using
# a GPU
dataset=MovieLensDataset(dataset_version="small")
print("Getting training data...")
train_dense_features, train_labels=dataset.get_data(split="train")
print("Getting testing data...")
test_dense_features, test_labels=dataset.get_data(split="test")
# Create DataLoader for training and testing
train_loader=DataLoader(torch.utils.data.TensorDataset(train_dense_features, train_labels), batch_size=64, shuffle=True)
test_loader=DataLoader(torch.utils.data.TensorDataset(test_dense_features, test_labels), batch_size=64, shuffle=False)
print("Accessing encoders...")
user_encoder, movie_encoder=dataset.get_encoders()
print("Setup complete.")

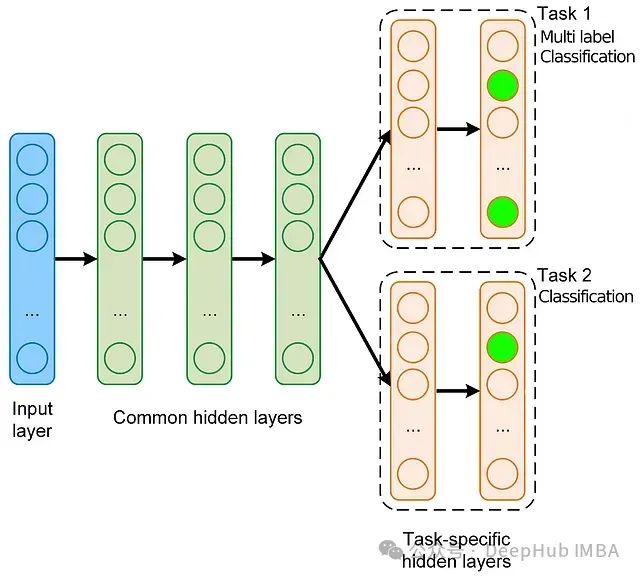
3. 定义多任务多标签模型
我们将定义一个基本的 PyTorch 模型,处理两个任务:预测评分(回归)和用户是否喜欢这部电影(二元分类)。
模型使用稀疏嵌入来表示用户和电影,并有共享层,这些共享层会输入到两个单独的输出层。
通过在任务之间共享一些层,并为每个特定任务的输出设置单独的层,该模型利用了共享表示,同时仍然针对每个任务定制其预测。
fromtorchimportnn
classMultiTaskMovieLensModel(nn.Module):
def__init__(self, n_users, n_movies, embedding_size, hidden_size):
super(MultiTaskMovieLensModel, self).__init__()
self.user_embedding=nn.Embedding(n_users, embedding_size)
self.movie_embedding=nn.Embedding(n_movies, embedding_size)
self.shared_layer=nn.Linear(embedding_size*2, hidden_size)
self.shared_activation=nn.ReLU()
self.task1_fc=nn.Linear(hidden_size, 1)
self.task2_fc=nn.Linear(hidden_size, 1)
self.task2_activation=nn.Sigmoid()
defforward(self, x):
user=x[:, 0]
movie=x[:, 1]
user_embed=self.user_embedding(user)
movie_embed=self.movie_embedding(movie)
combined=torch.cat((user_embed, movie_embed), dim=1)
shared_out=self.shared_activation(self.shared_layer(combined))
rating_out=self.task1_fc(shared_out)
liked_out=self.task2_fc(shared_out)
liked_out=self.task2_activation(liked_out)
returnrating_out, liked_out
**输入 (
x
)** :
- 输入
x预期是一个 2D 张量,其中每行包含一个用户 ID 和一个电影 ID。
用户和电影嵌入 :
user = x[:, 0]: 从第一列提取用户 ID。movie = x[:, 1]: 从第二列提取电影 ID。user_embed和movie_embed是对应这些 ID 的嵌入。
连接 :
combined = torch.cat((user_embed, movie_embed), dim=1): 沿特征维度连接用户和电影嵌入。
共享层 :
shared_out = self.shared_activation(self.shared_layer(combined)): 将组合的嵌入通过共享的全连接层和激活函数。
任务特定输出 :
rating_out = self.task1_fc(shared_out): 从第一个任务特定层输出预测评分。liked_out = self.task2_fc(shared_out): 输出用户是否喜欢电影的原始分数。liked_out = self.task2_activation(liked_out): 原始分数通过 sigmoid 函数转换为概率。
返回 :
模型返回两个输出:
rating_out: 预测的评分(回归输出)。liked_out: 用户喜欢电影的概率(分类输出)。
4. 训练循环
首先,用一些任意选择的超参数(嵌入维度和隐藏层中的神经元数量)实例化我们的模型。对于回归任务将使用均方误差损失,对于分类任务,将使用二元交叉熵。
我们可以通过它们的初始值来归一化两个损失,以确保它们都大致处于相似的尺度(这里也可以使用不确定性加权来归一化损失)
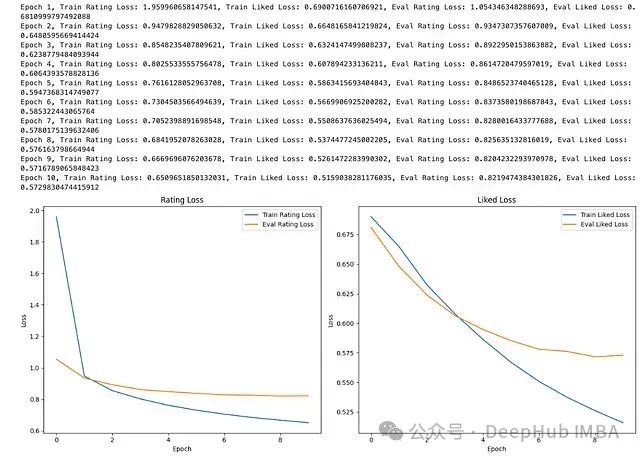
然后将使用数据加载器训练模型,并跟踪两个任务的损失。损失将被绘制成图表,以可视化模型在评估集上随时间的学习和泛化情况。
importtorch.optimasoptim
importmatplotlib.pyplotasplt
# Check if GPU is available
device=torch.device("cuda"iftorch.cuda.is_available() else"cpu")
print(f"Using device: {device}")
embedding_size=16
hidden_size=32
n_users=len(dataset.get_encoders()[0].classes_)
n_movies=len(dataset.get_encoders()[1].classes_)
model=MultiTaskMovieLensModel(n_users, n_movies, embedding_size, hidden_size).to(device)
criterion_rating=nn.MSELoss()
criterion_liked=nn.BCELoss()
optimizer=optim.Adam(model.parameters(), lr=0.001)
train_rating_losses, train_liked_losses= [], []
eval_rating_losses, eval_liked_losses= [], []
epochs=10
# used for loss normalization
initial_loss_rating=None
initial_loss_liked=None
forepochinrange(epochs):
model.train()
running_loss_rating=0.0
running_loss_liked=0.0
fordense_features, labelsintrain_loader:
optimizer.zero_grad()
dense_features=dense_features.to(device)
labels=labels.to(device)
rating_pred, liked_pred=model(dense_features)
rating_target=labels[:, 0].unsqueeze(1)
liked_target=labels[:, 1].unsqueeze(1)
loss_rating=criterion_rating(rating_pred, rating_target)
loss_liked=criterion_liked(liked_pred, liked_target)
# Set initial losses
ifinitial_loss_ratingisNone:
initial_loss_rating=loss_rating.item()
ifinitial_loss_likedisNone:
initial_loss_liked=loss_liked.item()
# Normalize losses
loss= (loss_rating/initial_loss_rating) + (loss_liked/initial_loss_liked)
loss.backward()
optimizer.step()
running_loss_rating+=loss_rating.item()
running_loss_liked+=loss_liked.item()
train_rating_losses.append(running_loss_rating/len(train_loader))
train_liked_losses.append(running_loss_liked/len(train_loader))
model.eval()
eval_loss_rating=0.0
eval_loss_liked=0.0
withtorch.no_grad():
fordense_features, labelsintest_loader:
dense_features=dense_features.to(device)
labels=labels.to(device)
rating_pred, liked_pred=model(dense_features)
rating_target=labels[:, 0].unsqueeze(1)
liked_target=labels[:, 1].unsqueeze(1)
loss_rating=criterion_rating(rating_pred, rating_target)
loss_liked=criterion_liked(liked_pred, liked_target)
eval_loss_rating+=loss_rating.item()
eval_loss_liked+=loss_liked.item()
eval_rating_losses.append(eval_loss_rating/len(test_loader))
eval_liked_losses.append(eval_loss_liked/len(test_loader))
print(f'Epoch {epoch+1}, Train Rating Loss: {train_rating_losses[-1]}, Train Liked Loss: {train_liked_losses[-1]}, Eval Rating Loss: {eval_rating_losses[-1]}, Eval Liked Loss: {eval_liked_losses[-1]}')
# Plotting losses
plt.figure(figsize=(14, 6))
plt.subplot(1, 2, 1)
plt.plot(train_rating_losses, label='Train Rating Loss')
plt.plot(eval_rating_losses, label='Eval Rating Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Rating Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(train_liked_losses, label='Train Liked Loss')
plt.plot(eval_liked_losses, label='Eval Liked Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Liked Loss')
plt.legend()
plt.tight_layout()
plt.show()
还可以通过利用 Tensorboard 监控训练的过程
fromtorch.utils.tensorboardimportSummaryWriter
# Check if GPU is available
device=torch.device("cuda"iftorch.cuda.is_available() else"cpu")
print(f"Using device: {device}")
# Model and Training Setup
embedding_size=16
hidden_size=32
n_users=len(user_encoder.classes_)
n_movies=len(movie_encoder.classes_)
model=MultiTaskMovieLensModel(n_users, n_movies, embedding_size, hidden_size).to(device)
criterion_rating=nn.MSELoss()
criterion_liked=nn.BCELoss()
optimizer=optim.Adam(model.parameters(), lr=0.001)
epochs=10
# used for loss normalization
initial_loss_rating=None
initial_loss_liked=None
# TensorBoard setup
writer=SummaryWriter(log_dir='runs/multitask_movie_lens')
# Training Loop with TensorBoard Logging
forepochinrange(epochs):
model.train()
running_loss_rating=0.0
running_loss_liked=0.0
forbatch_idx, (dense_features, labels) inenumerate(train_loader):
# Move data to GPU
dense_features=dense_features.to(device)
labels=labels.to(device)
optimizer.zero_grad()
rating_pred, liked_pred=model(dense_features)
rating_target=labels[:, 0].unsqueeze(1)
liked_target=labels[:, 1].unsqueeze(1)
loss_rating=criterion_rating(rating_pred, rating_target)
loss_liked=criterion_liked(liked_pred, liked_target)
# Set initial losses
ifinitial_loss_ratingisNone:
initial_loss_rating=loss_rating.item()
ifinitial_loss_likedisNone:
initial_loss_liked=loss_liked.item()
# Normalize losses
loss= (loss_rating/initial_loss_rating) + (loss_liked/initial_loss_liked)
loss.backward()
optimizer.step()
running_loss_rating+=loss_rating.item()
running_loss_liked+=loss_liked.item()
# Log loss to TensorBoard
writer.add_scalar('Loss/Train_Rating', loss_rating.item(), epoch*len(train_loader) +batch_idx)
writer.add_scalar('Loss/Train_Liked', loss_liked.item(), epoch*len(train_loader) +batch_idx)
print(f'Epoch {epoch+1}/{epochs}, Train Rating Loss: {running_loss_rating/len(train_loader)}, Train Liked Loss: {running_loss_liked/len(train_loader)}')
# Evaluate on the test set
model.eval()
eval_loss_rating=0.0
eval_loss_liked=0.0
withtorch.no_grad():
fordense_features, labelsintest_loader:
# Move data to GPU
dense_features=dense_features.to(device)
labels=labels.to(device)
rating_pred, liked_pred=model(dense_features)
rating_target=labels[:, 0].unsqueeze(1)
liked_target=labels[:, 1].unsqueeze(1)
loss_rating=criterion_rating(rating_pred, rating_target)
loss_liked=criterion_liked(liked_pred, liked_target)
eval_loss_rating+=loss_rating.item()
eval_loss_liked+=loss_liked.item()
eval_loss_avg_rating=eval_loss_rating/len(test_loader)
eval_loss_avg_liked=eval_loss_liked/len(test_loader)
print(f'Epoch {epoch+1}/{epochs}, Eval Rating Loss: {eval_loss_avg_rating}, Eval Liked Loss: {eval_loss_avg_liked}')
# Log evaluation loss to TensorBoard
writer.add_scalar('Loss/Eval_Rating', eval_loss_avg_rating, epoch)
writer.add_scalar('Loss/Eval_Liked', eval_loss_avg_liked, epoch)
# Close the TensorBoard writer
writer.close()
我们在同一目录下运行 TensorBoard 来启动服务器,并在网络浏览器中检查训练和评估曲线。在以下 bash 命令中,将
runs/mutlitask_movie_lens
替换为包含事件文件(日志)的目录路径。
(base) $ tensorboard--logdir=runs/multitask_movie_lens
TensorFlow installation not found - running with reduced feature set.
运行结果如下:
NOTE: Using experimental fast data loading logic. To disable, pass
"--load_fast=false" and report issues on GitHub. More details:
<https://github.com/tensorflow/tensorboard/issues/4784>
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.12.0 at <http://localhost:6006/> (Press CTRL+C to quit)

Tensorboard 损失曲线视图如上所示
5. 推理
在训练完成后要使用
torch.save
函数将模型保存到磁盘。这个函数允许你保存模型的状态字典,其中包含模型的所有参数和缓冲区。保存的文件通常使用
.pth
或
.pt
扩展名。
import torch
torch.save(model.state_dict(), "model.pth")
状态字典包含所有模型参数(权重和偏置),当想要将模型加载回代码中时,可以使用以下步骤:
# Initialize the model (make sure the architecture matches the saved model)
model = MultiTaskMovieLensModel(n_users, n_movies, embedding_size, hidden_size)
# Load the saved state dictionary into the model
model.load_state_dict(torch.load("model.pth"))
# Set the model to evaluation mode (important for inference)
model.eval()
为了在一些未见过的数据上评估模型,可以对单个用户-电影对进行预测,并将它们与实际值进行比较。
def predict_and_compare(user_id, movie_id, model, user_encoder, movie_encoder, train_dataset, test_dataset):
user_idx = user_encoder.transform([user_id])[0]
movie_idx = movie_encoder.transform([movie_id])[0]
example_user = torch.tensor([[user_idx]], dtype=torch.long)
example_movie = torch.tensor([[movie_idx]], dtype=torch.long)
example_dense_features = torch.cat((example_user, example_movie), dim=1)
model.eval()
with torch.no_grad():
rating_pred, liked_pred = model(example_dense_features)
predicted_rating = rating_pred.item()
predicted_liked = liked_pred.item()
actual_row = train_dataset.data[(train_dataset.data['userId'] == user_id) & (train_dataset.data['movieId'] == movie_id)]
if actual_row.empty:
actual_row = test_dataset.data[(test_dataset.data['userId'] == user_id) & (test_dataset.data['movieId'] == movie_id)]
if not actual_row.empty:
actual_rating = actual_row['rating'].values[0]
actual_liked = actual_row['liked'].values[0]
return {
'User ID': user_id,
'Movie ID': movie_id,
'Predicted Rating': round(predicted_rating, 2),
'Actual Rating': actual_rating,
'Predicted Liked': 'Yes' if predicted_liked >= 0.5 else 'No',
'Actual Liked': 'Yes' if actual_liked == 1 else 'No'
}
else:
return None
example_pairs = test_dataset.data.sample(n=5)
results = []
for _, row in example_pairs.iterrows():
user_id = row['userId']
movie_id = row['movieId']
result = predict_and_compare(user_id, movie_id, model, user_encoder, movie_encoder, train_dataset, test_dataset)
if result:
results.append(result)
results_df = pd.DataFrame(results)
results_df.head()

6. 使用 Ray Serve 部署模型
最后就是将模型部署为一个服务,使其可以通过 API 访问,这里使用使用 Ray Serve。
使用 Ray Serve是因为它可以从单机无缝扩展到大型集群,可以处理不断增加的负载。Ray Serve 还集成了 Ray 的仪表板,为监控部署的健康状况、性能和资源使用提供了用户友好的界面。
步骤 1:加载训练好的模型
# Load your trained model (assuming it's saved as 'model.pth')
n_users = 1000 # 示例值,替换为实际用户数
n_movies = 1000 # 示例值,替换为实际电影数
embedding_size = 16
hidden_size = 32
model = MultiTaskMovieLensModel(n_users, n_movies, embedding_size, hidden_size)
model.load_state_dict(torch.load("model.pth"))
model.eval()
步骤 2:定义模型服务类
import ray
from ray import serve
@serve.deployment
class ModelServeDeployment:
def __init__(self, model):
self.model = model
self.model.eval()
async def __call__(self, request):
json_input = await request.json()
user_id = torch.tensor([json_input["user_id"]])
movie_id = torch.tensor([json_input["movie_id"]])
with torch.no_grad():
rating_pred, liked_pred = self.model(user_id, movie_id)
return {
"rating_prediction": rating_pred.item(),
"liked_prediction": liked_pred.item()
}
步骤 3:初始化 Ray 服务器
# 初始化 Ray 和 Ray Serve
ray.init()
serve.start()
# 部署模型
model_deployment = ModelServeDeployment.bind(model)
serve.run(model_deployment)
现在应该能够在 localhost:8265 看到 ray 服务器
步骤 4:查询模型
最后就是测试 API 了。运行以下代码行时,应该可以看到一个响应,其中包含查询用户和电影的评分和喜欢预测
import requests
# 定义服务器地址(Ray Serve 默认为 http://127.0.0.1:8000)
url = "http://127.0.0.1:8000/ModelServeDeployment"
# 示例输入
data = {
"user_id": 123, # 替换为实际用户 ID
"movie_id": 456 # 替换为实际电影 ID
}
# 向模型服务器发送 POST 请求
response = requests.post(url, json=data)
# 打印模型的响应
print(response.json())
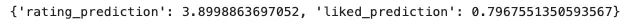
就是这样,我们刚刚训练并部署了一个多任务多标签模型!
https://avoid.overfit.cn/post/7918312b79b24f1bbac35db3caa0ad1d
作者:Cole Diamond